【Hadoop】Hadoop简介
2023-12-13 07:32:20
Hadoop是什么
Hadoop是一个由Apache基金会所开发的开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在计算机集群上行大规模数据集的分布式处理。它设计成可以从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
- HDFS(Hadoop Distributed File System ):即Hadoop分布式文件系统,解决大规模数据的存储和高吞吐量访问。
- YARN(Yet Another Resource Negotiator):集群资源管理器,负责对集群中的资源进行统一管理和调度。
- MapReduce:MapReduce是一个编程模型和处理引擎,用于处理大规模数据集并执行并行计算
广义上说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。Hadoop生态圈是由一系列与Hadoop项目相关的开源软件组成的。这些工具和框架是为了提供更全面、灵活和强大的大数据处理解决方案。
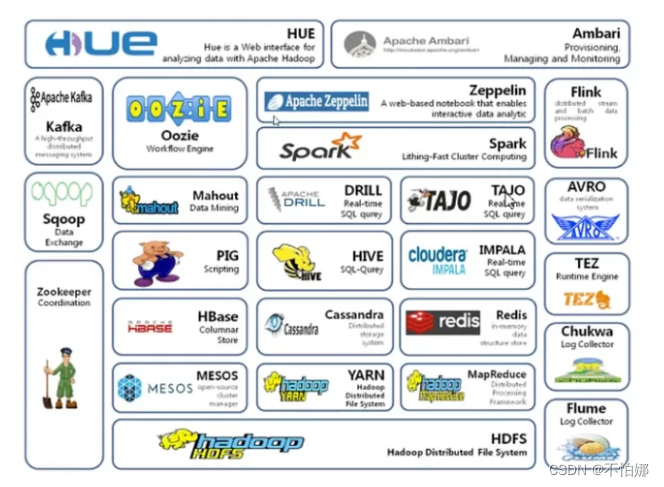
Hadoop解决了什么问题
Hadoop解决了处理大规模数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)时遇到的存储、计算、容错和成本等多个挑战,为企业提供了一种强大而灵活的大数据处理解决方案。
以下是Hadoop解决的一些主要问题:
- 大规模数据存储: Hadoop提供了分布式文件系统(HDFS),允许用户存储大量数据并且跨集群的多个节点。这解决了传统数据库无法轻松应对的数据存储容量问题。
- 分布式计算: Hadoop使用MapReduce编程模型,允许用户在整个数据集上执行并行计算。这使得处理大规模数据集变得更加高效,可以充分利用集群中的计算资源。
- 容错性: Hadoop通过在集群中的多个节点上存储数据的多个副本,提高了数据的容错性。如果某个节点或数据副本发生故障,系统仍然可以从其他可用的副本中获取数据。
- 横向扩展性: Hadoop的设计允许在需要时轻松地扩展集群规模,从而适应不断增长的数据量和计算需求。用户可以通过添加新的机器来增加集群的容量。
- 成本效益: Hadoop采用了经济实惠的硬件,并且可以在普通的计算机上运行。这种低成本的设计使得企业能够以相对较低的投资来构建大规模数据处理基础设施。
- 多样性数据处理: Hadoop生态圈中的各种工具和框架(如Hive、Pig、Spark等)使得用户能够以多种方式处理和分析不同类型的数据,包括结构化数据和非结构化数据。
- 实时数据处理: 虽然Hadoop最初是为批处理而设计的,但随着发展,引入了支持实时数据处理的工具和框架,如Apache Spark和Apache Flink。
Hadoop的优势/特性
考虑Hadoop的优势时就从Hadoop解决了哪些问题的角度来看。这个在上面刚刚介绍过。
简单来说,主要有下面几点:
- 高容错性:数据自动保存多个副本,副本丢失自动恢复
- 适合批量处理:移动计算而非数据,数据位置暴露给计算框架。这是一个重要的概念。也就是说计算的时候并不是将集群的数据都传输到一台机器上进行计算,因为移动数据会耗费大量的IO(磁盘IO、网络IO等等),而是在集群中的每个机器上分别计算,然后再将结果进行汇总。
- 适合大数据处理:TB,PB级的数据,百万规模以上的文件数量,10K+节点
- 流式文件访问:一次写入,可多次读取,确保数据的一致性
- 可构建在廉价机器上:通过多副本提高可靠性,有容错和恢复机制
Hadoop的局限和不足
- 复杂性: Hadoop编程模型(MapReduce)对于一些用户来说可能过于复杂。编写和调试MapReduce任务可能需要较高的技术水平,而且这种模型在处理一些复杂的数据处理场景时可能不够直观。
- 安全性: 初始版本的Hadoop在安全性方面的支持相对较弱,虽然后续版本已经加强了安全性特性,但在一些安全性要求较高的场景中仍可能存在挑战。
- 实时性: 初始版本的Hadoop主要专注于批处理处理大量数据,而不太适用于需要低延迟、实时性处理的场景。虽然后来的工具和框架(如Apache Spark)提供了更好的实时处理能力,但Hadoop本身的实时性仍然是一个挑战。
- Hadoop并不是所有问题的银弹。有些问题可能不适合MapReduce模型,也不适合存储在HDFS中
参考
https://cloud.tencent.com/developer/article/1887129
https://andr-robot.github.io/Hadoop%E5%9F%BA%E7%A1%80%E6%9E%B6%E6%9E%84%E5%8F%98%E5%8C%96/
文章来源:https://blog.csdn.net/m0_60511809/article/details/134899414
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!