猿人学19题(原比赛平台)
2023-12-16 16:50:23
这道题给我搞得有点懵了,我现在还没发现他到底要考察什么,这边我直接协商我的sessionid请求是直接就成功的。😂
依旧是分析请求方式,抓包到返回数据的位置
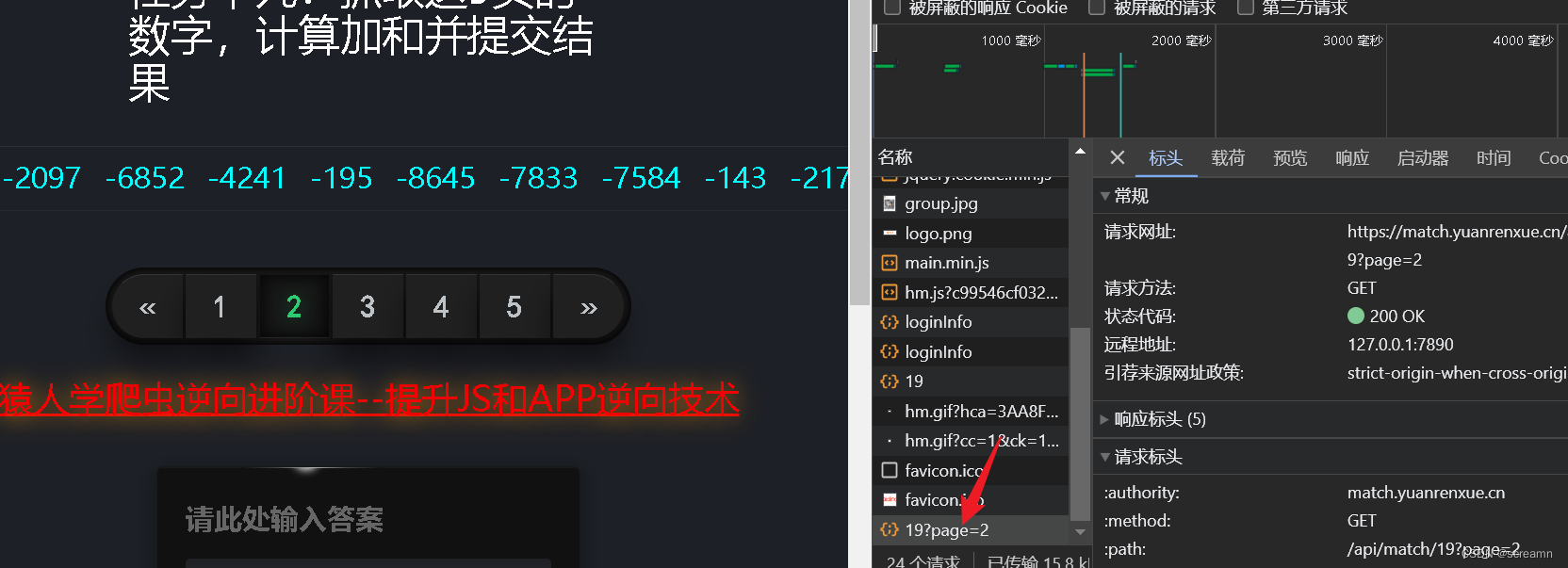
现在可以知道这些数据是ajax返回的,请求的参数是page,直接携带页数即可,你只需要填上自己的sessionid,就可以成功访问了。
代码:
import requests
cookies = {
"sessionid": "自己的sessionid",
}
url = "https://match.yuanrenxue.cn/api/match/19"
sum = 0
for i in range(1,6):
params = {
"page": f"{i}"
}
response = requests.get(url, cookies=cookies, params=params)
data = response.json()['data']
for i in data:
sum+=i['value']
print(sum)如果各位有知道考察内容是什么的,也告诉我一下😂。
文章来源:https://blog.csdn.net/screamn/article/details/135033535
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!