使用yolov8和moviepy自动截取视频中人出现的片段
前言
这么长时间没写博客,其实主要是忙于一个行为实时检测大型项目的开发,最近闲下来就写这篇当年末总结了。这篇文章的起因还是某个业务需求,要求分析视频中有人的部分,没人的部分需要去掉,同时行为检测的数据集如果要自己采集打标,也需要这个步骤。
分析
不想看分析的直接跳到代码复制 ^_^
1.拿到这个问题,我首先就丢给了gpt和一众大语言模型去解决,因为真的不想动手干这种杂活,懒惰之神上身了。
然后我一开始的指令是这样的:
给了我一个空壳子:
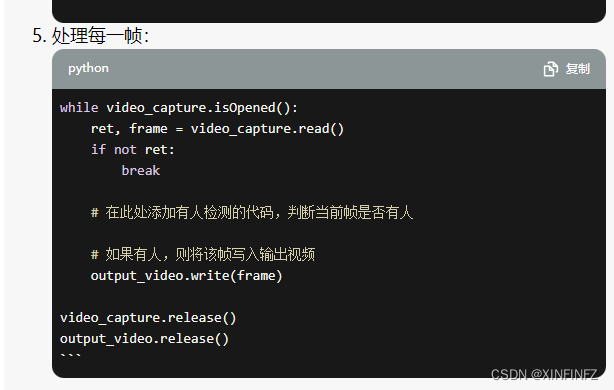
然后我觉得这种简单的需求,cv2应该可以搞定吧,就指导它使用haar级联检测器去检测:
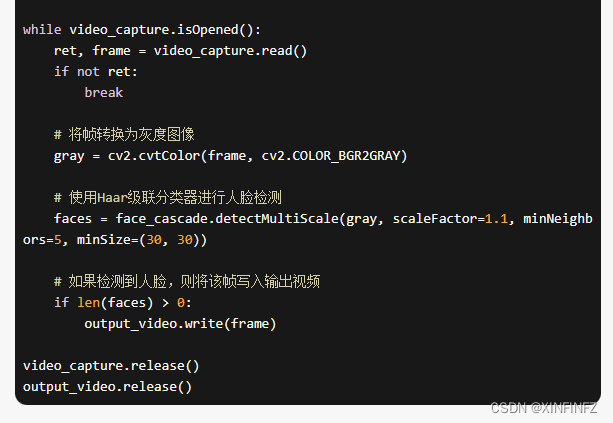
在改掉基本的逻辑错误后,我发现,它能检测出人脸的就没几帧!而且这样保存后出来的视频,是几秒钟不同时间的人物动作拼凑,根本达不到要求,这时我才明白我需要的是连贯的人体动作片段,而非抽帧。
2.如何让语言模型理解到底你要干什么:
经过几次尝试,我发现这些语言模型压根不知道我说的片段是什么意思。
于是我使用英文循序渐进的提问,先假设我有两个片段截取:
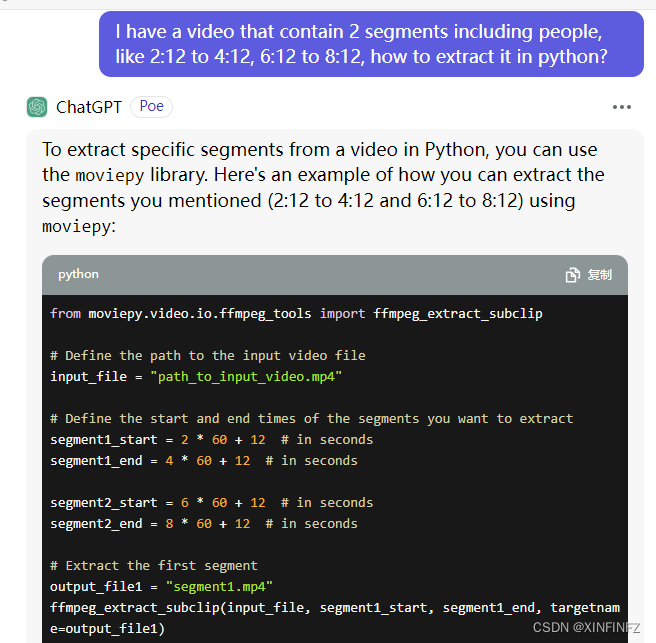
告诉它,我这个视频中有两个segments(片段),要把它截取下来,它用moivepy完成了任务。于是,就可以跟它说我有一个模型来检测人物,我其实并不知道有几个片段,也不知道有几个时间点,请结合上面的moviepy来完成。
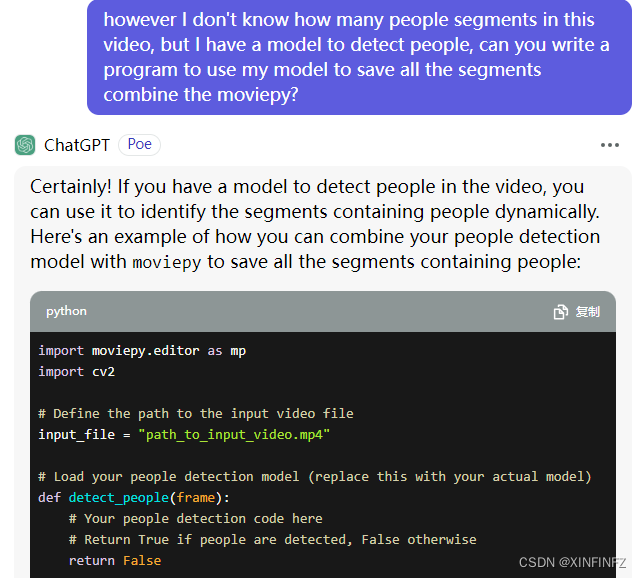
于是它完美给出了整个框架和逻辑,除了人体检测部分需要我自己实现。
3.实现人体检测
鉴于之前已经用cv2尝试过简单的图像处理,各种方法都不是很满意,那就直接上目标检测模型好了,同时因为需要连贯的人体检测,不能说我这一帧检测到,下一帧突然消失,所以要加上目标跟踪,那最轻松的方法就是使用yolov8直接一行实现:
results = model.track(frame, persist=True, classes=0,verbose=False)
后面的参数persist表示后一帧要对前一帧产生的结果进行预测,classes=0表示只预测people这一类,其他不是我们需要关心的,verbose=False纯粹是因为yolo输出的打印太烦了,我不关心,直接关掉。
然后查阅可知results.boxes.shape返回的是预测出的目标向量的形状,那么第一维度为0时表示没有预测到,基于这个就可以实现判断。
代码
from ultralytics import YOLO
import moviepy.editor as mp
import cv2
model = YOLO('yolov8n.pt')
# 定义输入片段
input_file = "input.mp4"
# 定义相关片段变量
segment_start = None
segment_end = None
segments = []
# 用moviepy打开视频源
video = mp.VideoFileClip(input_file)
# 循环
for idx, frame in enumerate(video.iter_frames()):
people_detected = False
# 默认读取RGB,需转换成BGR输入
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
#推理
results = model.track(frame, persist=True, classes=0,verbose=False)
#对结果进行判断
for r in results:
if r.boxes.shape[0] != 0:
people_detected = True
if people_detected and segment_start is None:
# 开始新的片段
segment_start = idx / video.fps
elif not people_detected and segment_start is not None:
# 结束当前片段
segment_end = idx / video.fps
if (segment_end - segment_start) > 1:
segments.append((segment_start, segment_end))
print((segment_start, segment_end))
segment_start = None
segment_end = None
# 如果一个片段直到结尾,就截取到结束
if segment_start is not None:
segment_end = video.duration
segments.append((segment_start, segment_end))
# 提取片段并写入本地文件
for i, (segment_start, segment_end) in enumerate(segments):
segment_name = f"segment{i+1}.mp4"
segment = video.subclip(segment_start, segment_end)
segment.write_videofile(segment_name)
#关闭视频源
video.reader.close()
这里if (segment_end - segment_start) > 1可以去掉,我加上是为了去掉太短的人物片段,可能是因为模型误报和不稳定导致的,如果想要更准也可以把yolov8n换成yolov8s或者x,模型越大效果越好。
跑出来结果如下:
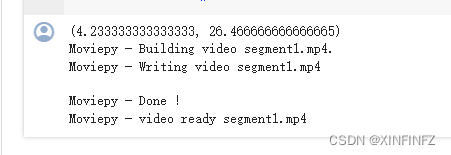
有几个片段就会生成几个,segment1,segment2…以此类推。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!