即时战略游戏的AI策略思考
想起来第一次玩RTS游戏,就是框住一大群兵进攻,看他们把对面消灭干净……我接触的第一款游戏是《傲世三国》那会儿是小学,后来高中接触了魔兽地图编辑器,我发现自己喜欢直接看属性而省去争论和试验的步骤——我喜欢能一眼看透的感觉。
这篇博客都是务虚的,没啥干货,全是不算成熟的想法和思考。
【本篇将以“单位”来统一对实体、兵力、对象、算子等的称呼】
一、策略的描述
研究生的课题是“人机结合的智能体构建方法”,于是我回忆起了这些东西,但好像真的没认真考虑过什么是策略,怎么才能取胜(我不喜欢枯燥的练习游戏水平)。
我先是用极限法想到:是不是即时战略的兵极端抽象后就是下棋那种回合制,一种局面仅有固定的策略和解法(比如中国象棋的残局)?
还一个问题,涉及博弈论和社会关系计算的,我如何制作一个可以模拟这些过程、看到质点如何成为如此策略的平台工具?
1.行为建模
1)有限状态机
petri网络和基于有限状态机的规则推理
2)行为树
ROS机器人的操作系统中常常使用行为树
2.驱动方式
这部分我采用魔兽地图编辑器的思路来描述。
魔兽地图编辑器(以下简称WE)?,每个触发分为3个东西【事件、条件、动作】

1)时间驱动
这个是某个仿真引擎中的虚函数,它的两个触发条件就是时间和事件。
2)事件驱动
这个是最常用的,比如”任意单位被攻击“,然后条件是”被攻击的单位拥有技能【反击螺旋】“,最后动作是”随机数触发,如果触发了,选定范围形成单位组,对单位组施加伤害,被攻击的单位播放旋转动画“。
3)连锁反应的推理驱动
这个也就是经由其他触发器来引发这个触发启动的。
二、游戏和平台的构建
大战略,战役,战术小队,单兵技术……
钢铁雄心、骑马与砍杀(大地图与战场的分割,指挥下令)、魔兽争霸……在不同层面有不同的战斗表现方式,但是面面俱到的话玩家不可能学的过来而挫败。
一种战术是如何描述的?策略是如何描述和执行的?
1.环境交互
研究庙算平台后,我对这个平台做出了一些自己粗略的印象(编写规则式ai):
赋予算子反应(行动),然后再检查条件,再赋予行动。
基础的行动就是我们可以执行的指令,行动序列就是要产出的东西。
2.强化学习
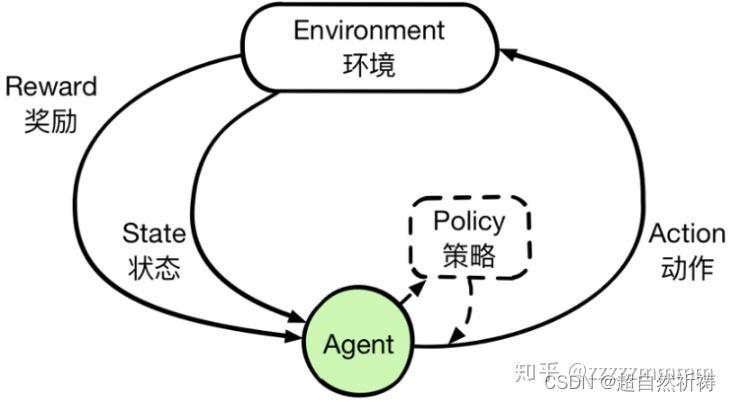
智能体(Agent)
强化学习的本体,作为学习者或者决策者。
{
? 策略(Policy)策略是从状态到动作的一个映射,智能体根据策略来选取动作。
? 价值函数 (Value Function)用价值函数来评估当前状态的好坏程度。
? 模型(Model)智能体对环境的建模,即对环境的动力学进行建模。
????????{状态转移概率、奖励函数}
}
环境
强化学习智能体以外的一切,主要由状态集合组成。
状态(环境、智能体、信息)
一个表示环境的数据,状态集则是环境中所有可能的状态。
动作
智能体可以做出的动作,动作集则是智能体可以做出的所有动作。
奖励
智能体在执行一个动作后,获得的正/负反馈信号,奖励集则是智能体可以获得的所有反馈信息。
目标
智能体自动寻找在连续时间序列里的最优策略,而最优策略通常指最大化长期累积奖励。
因此,强化学习实际上是智能体在与环境进行交互的过程中,学会最佳决策序列。
序列决策
按时间顺序进行一系列决策,是一种动态的决策方式,可用于随机性或不确定性动态系统最优化。 马尔可夫决策问题就属于序列决策问题。
另起一个,智能体分类
1、根据智能体的学习内容,我们可以把智能体分为如下三类:
- 基于策略(policy based)的智能体?直接学习策略,不需要学习价值函数。
- 基于价值(value based)的智能体?学习价值函数,通过价值函数隐式地得到策略。
- 演员-评论家(Actor Critic)的智能体?是基于策略和基于价值的结合,既学习策略,也学习价值函数。
2、根据智能体是否需要对环境动力学进行建模,可以把智能体分为如下两类:
- 基于模型(model based)的智能体?通过对环境进行建模,以此来学习策略或价值函数。
- 不于模型(model free)的智能体?不需要对环境建模,通过学习价值函数和策略函数进行决策。
3.炼丹(深度学习拟合)
对于可以清楚描述的数学问题不需要炼丹,对于尚不清楚的只能炼丹让ai帮我们试。
三、从玩家角度入手
我想到了如下几个东西。
1.术语
- 快攻:牺牲经济和科技的发展,尽可能在初期就全力建造部队击败对手;为了加快速度,经常需要把产兵建筑偷偷造在对手的基地附近,还可以派出部分甚至所有农民来协助进攻。
- Timing一波:预测对手的兵力薄弱期,通过固定的运营策略,在这些时间点集结出尽可能强大的兵力发动总攻,并且往往伴随着关键科技的恰巧升级完成。
- 压制:派出部队前压,占对手的一些便宜或者把对手压在家里无法开矿,而自己则趁机扩张。
- 骚扰:派出高机动单位、空中单位或者运输局运载部队,尽量避开敌方主力而去击杀对方的农民,从而打击他的经济。
- 控图:处于均势时,在战线上四处游走,进行充分的侦查,了解敌方主力位置和构成,等待时机进攻或者骚扰。
- 偷经济:认为敌方不会细致侦查时,偷偷在较远的位置开出分矿,铤而走险来获得经济优势。
- 偷科技:牺牲兵力或者经济,从而提早研发关键科技,来获得进攻Timing的提前
- 大后期:前中期侧重于防守和扩张,并构筑大量防守建筑来稳定战线,最终在良好的经济和科技支撑下,造出大量高级部队来蚕食消灭对手。这样一局比赛往往要很久,比如“城市化”战术甚至有打过7个多小时的...
- 换家:在正面对抗能力不如对手时,充分发挥游击战的思想,避开敌方部队的锋芒,在对方进攻时绕到他家中进行互拆,这个战术最能体现出星际2的复杂性和选手的应变能力。
以上战术的术语来自:AlphaStar的游戏——星际争霸2 AI综述_星际 op ai-CSDN博客
2.熟练的玩家
打王者荣耀多了就会发现,即使是moba也可以看成是“回合制”,由于对英雄的操控已经十分熟悉,影响较大的因素(除非超常的反应)是技能cd和自己在打团时的位置了。抛开发育和补兵之类的,只聚焦于团战,那就是一个策略游戏了。
除此之外,我看到一篇sky对魔兽争霸3的评价,在熟悉游戏后,只要游戏没有更新,打法和策略都会趋向于固定的几种。这个就很像我理解中的机器学习搜索出的博弈论中的纳什均衡。
3.boss怪的套路、脚本外挂
想到这个是因为想起了《只狼》这种游戏的boss,一般都是有固定套路的,boss只要能动起来,别太机制就行。
星际争霸2因为谷歌的DeepMind与暴雪开源了人工智能研究环境of星际争霸2,这样才诞生出的第一个战胜职业玩家的AI——AlphaStar。
我想搞点事情,但是没找到合适的开源项目,我的想法是【如果改变了属性和游戏规则,比如虽然都是黑白棋,但是”围棋“和”五子棋“规则下训练出的AI一定不一样】
嗯……我觉得我可以试着单独做一个rts游戏(交互层和显示层分离,专门提供给机器学习;自定义技能和行为组合;以及自驱动的智能体单位) ,但是策略加入多了就变成了slg游戏,如何做好过渡……又是一个问题。
四、如何让玩家更好的操控局面
有一个基础想法作为公理:身经百战的高排名大神玩家的总结一定是有价值的,因为事实证明小白玩家是打不过大神玩家的。(人肉机器学习)
1.把人嵌入到过程中
我先想到的还是“下令”,这是最基础的想法,编写程序从汇编写到最后,也就到了一个函数执行、命令行执行脚本的状态。我有理由相信这就是人机交互的最稳固形式。
从游戏来说,骑马与砍杀中就有梗“f1,f3”,就是下令“全体士兵,冲锋!”。在古代战争电影中也是将帅下令来进行战争活动。
把人带入过程,这么想来,回合制是最方便的方式。但是由于实际的反应速度和局面信息差而不可能是真正的回合制,只能接近于这种“理想状态”。
2.行动的构建
从基础的行动单元(移动、攻击),到一些基础指令的组合扩展(走A),再到复杂的技能操作组成的连招(比如魔兽世界的宏)——这些是计策之外的东西。
计策,回到最开始,就是一个残局的求解。从残局逆推,以我的粗略见解,一整局的斗争行为,无非是扩充了局面的形成过程以及其中的博弈行为。涉及了很多东西,发育-出装-技巧-团战等。
五、游戏之外
科技是第一生产力,降本增效靠的不是单纯的压榨人(加班),应该是优化人力结构(安排对的人到对的事)的这种小幅提升,以及根本的基础实现方式(置换反应制铝变成电解反应、电子管到晶体管)的大幅度突破。
这些东西怎么从游戏这个模拟的世界的镜子来让我们自己看清楚当下最该做什么呢?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!