长尾问题之LDAM
2023-12-15 12:45:06
做法&代码&公式
step1: 全连接层的权重W和特征向量X都归一化,相乘 W * X = P (得到各个类别的概率)
# 定义权重,初始化
weight = nn.Parameter(torch.FloatTensor(num_classes, num_features))
weight.data.uniform_(-1, 1).renorm_(2, 1, 1e-5).mul_(1e5)
# 归一化W,X ; W * X = P
Z = F.linear(F.normalize(x), F.normalize(self.weight))step2: 损失参数计算及设置
计算 margin
其中nj是对应类别j的数量,C是一个超参常数。代码里C是最多样本类别的0.5倍
以此类推,类别1,类别2 的分别margin
,
代码部分
s = 30 # 设置缩放系数 s=30
num_class_list=[13000,450,4231,8000 ... ] # 各个类别样本数量
max_m = 0.5
m_list = 1.0 / np.sqrt(np.sqrt(num_class_list))
m_list = m_list * (max_m / np.max(m_list)) # ignore是0影响计算re-weight
epoch∈(0~160)时为
betas = [0, 0.9999]
re_weights = (1.0 - betas[0]) / (1.0 - np.power(betas[0], num_class_list))
re_weights = re_weights / np.sum(per_cls_weights) * num_class)epoch∈(160~maxepoch)时为:
betas = [0, 0.9999]
re_weights = (1.0 - betas[1]) / (1.0 - np.power(betas[1], num_class_list))
re_weights = re_weights / np.sum(re_weights) * num_class)step4:计算损失
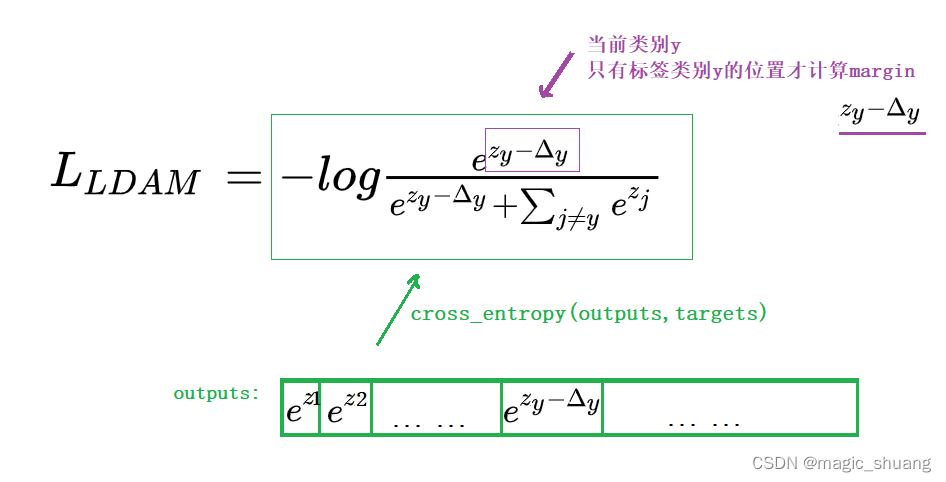
# index: 哪些位置是y_true
x_m = Z - m_list
outputs = torch.where(index, x_m, Z)
F.cross_entropy(s * outputs, targets, weight=re_weight)参考:https://github.com/zhangyongshun/BagofTricks-LT/blob/main/documents/trick_gallery.md
MMPretrain实现 不要积分的,免费的
https://download.csdn.net/download/magic_shuang/88632302
mmpretrain/models/heads/ldam_head.py
mmpretrain/models/losses/ldam_loss.py
文章来源:https://blog.csdn.net/magic_shuang/article/details/135012677
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!