Redis缓存穿透,缓存击穿,缓存雪崩
2024-01-02 10:16:35
文章目录
Redis缓存穿透,缓存击穿,缓存雪崩

1. 缓存穿透
查询一个不存在的数据,mysql中查询不到也不会写入缓存,导致每次请求都要查mysql
例:get请求 api/products/getById/1001

1.1 解决方案1:缓存空数据
查询返回的数据为空,仍把这个数据进行缓存{key:1, value: null}
优点:实现简单
缺点:消耗内存可能会发生不一致情况
1.2 解决方案2:使用布隆过滤器

优点:内存占用少
缺点:实现负责,存在误判
1.2.1 布隆过滤器介绍
bitmap(位图):是一个以(bit)为单位的数组,数组中每个单元只能存储二进制数0或1
作用:检索一个元素是否存在一个集合中
实现:
1) 存储数据:id为1的数据,通过多个hash函数获取hash值,根据hash计算数组对应位置改为1
2) 查询数据:使用相同hash函数获取hash值,判断对应位置是否都为1
使用Guava或者Redisson实现布隆过滤器
误判率:数组越小,误判率越大,数组越大误判率越小,但是同时带来更多的内存消耗。
2. 缓存击穿
给某个key设置了过期时间,当key过期时候,对这个key有大量的并发请求进来,瞬间把mysql压垮

2.1 解决方案1:互斥锁
互斥锁,数据强一致,性能差
2.2 解决方案2:逻辑过期
高可用,性能优,不能保证数据绝对一致。
实现:{“id”:“1”,“title”:“xx项目”,“expire”:156414365},请求时候先检查逻辑过期时间,如果过期,就加互斥锁,生成新的线程来处理写缓存逻辑过期时间重置问题,当前线程返回过期数据;如果加互斥锁失败,就直接返回过期数据。
3. 缓存雪崩
同一时间大量的缓存key同时过期或者Redis服务宕机,导致大量的请求到达mysql,给mysql带来巨大压力
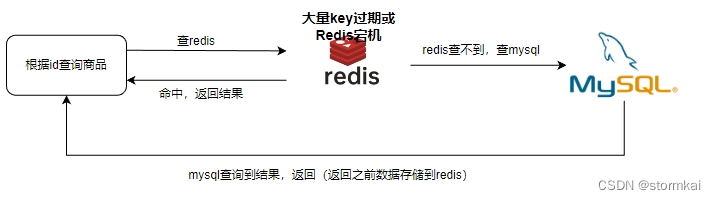
3.1 解决方案
- 利用Redis集群提高服务的可用性 哨兵模式、分片集群模式
- 给业务添加多级缓存 Guava或Caffeine
- 给缓存业务添加降级限流策略 nginx或SpringCloud Gateway
- 给不同的key的TTL添加随机值
文章来源:https://blog.csdn.net/stormkai/article/details/135331429
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!