MybatisPlus进阶,UUID VS SnowFlake(雪花算法)

目录
2.4在spring boot启动类中添加@MapperScan注解,扫描Mapper文件夹:
一、什么是MybatisPlus
为什么要学MybatisPlus?
简化开发:MyBatis-Plus 在 MyBatis 的基础上进行了扩展,提供了更加方便的编程方式和更高效的操作数据库的能力,可以极大地简化开发流程,减少样板代码的编写。
提升开发效率:MyBatis-Plus 提供了许多功能强大且易于使用的特性,如通用 CRUD 操作、分页查询、逻辑删除、条件构造器、自动填充等,这些功能可以大幅度提升开发效率,减少重复劳动。
提供更好的性能:MyBatis-Plus 对 MyBatis 进行了优化和增强,通过一些技术手段提升了 SQL 的执行性能和数据库访问效率,从而提供更好的性能表现。
社区活跃:MyBatis-Plus 作为一个开源框架,有庞大且活跃的社区支持,开发者可以在社区中获取到官方文档、教程、示例代码等资源,并可以与其他开发者交流和分享经验。
兼容性良好:MyBatis-Plus 与 MyBatis 完全兼容,可以无缝集成到已有的 MyBatis 项目中,也可以方便地与其他技术栈进行整合,如 Spring、Spring Boot 等。
特性:
无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
二、快速入门
简介 | MyBatis-Plus (baomidou.com)![]() https://baomidou.com/pages/24112f/
https://baomidou.com/pages/24112f/
2.1快速初始化一个空的spring boot 项目
上一篇博客中已说明
2.2配置依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--mybatis-plus插件-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.2</version>
</dependency>
<!-- 因为生成器中是根据free marker模板生成的-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>若有报错点击刷新maven,点击clean
2.3配置(连接数据库)
在application.yml配置文件中添加MySQL数据库的相关配置:
数据库名称,密码根据自己的来
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://127.0.0.1:3306/bookshop
mybatis-plus:
# 别名
type-aliases-package: com.lya.springbootmybatisplus.pojo
# 驼峰
configuration:
map-underscore-to-camel-case: true
MySQLGenerator(生成器类)这里更改自己的数据库连接
package com.lya.springbootmybatisplus.config;
import com.baomidou.mybatisplus.generator.FastAutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.OutputFile;
import com.baomidou.mybatisplus.generator.config.rules.DateType;
import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
import lombok.extern.slf4j.Slf4j;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
@Slf4j
public class MySQLGenerator {
private final static String URL = "jdbc:mysql://localhost:3306/bookshop";
private final static String USERNAME = "root";
private final static String PASSWORD = "123456";
private final static DataSourceConfig.Builder DATA_SOURCE_CONFIG =
new DataSourceConfig.Builder(URL, USERNAME, PASSWORD);
public static void main(String[] args) {
FastAutoGenerator.create(DATA_SOURCE_CONFIG)
.globalConfig(
(scanner, builder) ->
builder.author(scanner.apply("请输入作者名称?"))
.outputDir(System.getProperty("user.dir") + "\\src\\main\\java")
.commentDate("yyyy-MM-dd")
.dateType(DateType.TIME_PACK)
)
.packageConfig((builder) ->
builder.parent("com.lya.springbootmybatisplus")
.entity("pojo")
.service("service")
.serviceImpl("service.impl")
.mapper("mapper")
.xml("mapper.xml")
.pathInfo(Collections.singletonMap(OutputFile.xml, System.getProperty("user.dir") + "\\src\\main\\resources\\mapper"))
)
.injectionConfig((builder) ->
builder.beforeOutputFile(
(a, b) -> log.warn("tableInfo: " + a.getEntityName())
)
)
.strategyConfig((scanner, builder) ->
builder.addInclude(getTables(scanner.apply("请输入表名,多个英文逗号分隔?所有输入 all")))
.addTablePrefix("tb_", "t_", "lay_", "meeting_", "sys_")
.entityBuilder()
.enableChainModel()
.enableLombok()
.enableTableFieldAnnotation()
.controllerBuilder()
.enableRestStyle()
.enableHyphenStyle()
.build()
)
.templateEngine(new FreemarkerTemplateEngine())
.execute();
}
protected static List<String> getTables(String tables) {
return "all".equals(tables) ? Collections.emptyList() : Arrays.asList(tables.split(","));
}
}运行这个类,就生成了mapper,servers,相关的增删改查
2.4在spring boot启动类中添加@MapperScan注解,扫描Mapper文件夹:
SpringbootMybatisplusApplication?
package com.lya.springbootmybatisplus;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@MapperScan("com.lya.springbootmybatisplus.mapper")
@SpringBootApplication
public class SpringbootMybatisplusApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootMybatisplusApplication.class, args);
}
}
2.5添加测试类,进行功能测试:
package com.lya.springbootmybatisplus.controller;
import com.lya.springbootmybatisplus.service.IBookService;
import com.lya.springbootmybatisplus.service.impl.BookServiceImpl;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* <p>
* �鱾��?�� 前端控制器
* </p>
*
* @author lixiao
* @since 2023-12-16
*/
@RestController
@RequestMapping("/book")
public class BookController {
@Autowired
private IBookService bookService;
@RequestMapping("/list")
public Object list(){
return bookService.list();
}
}
效果:

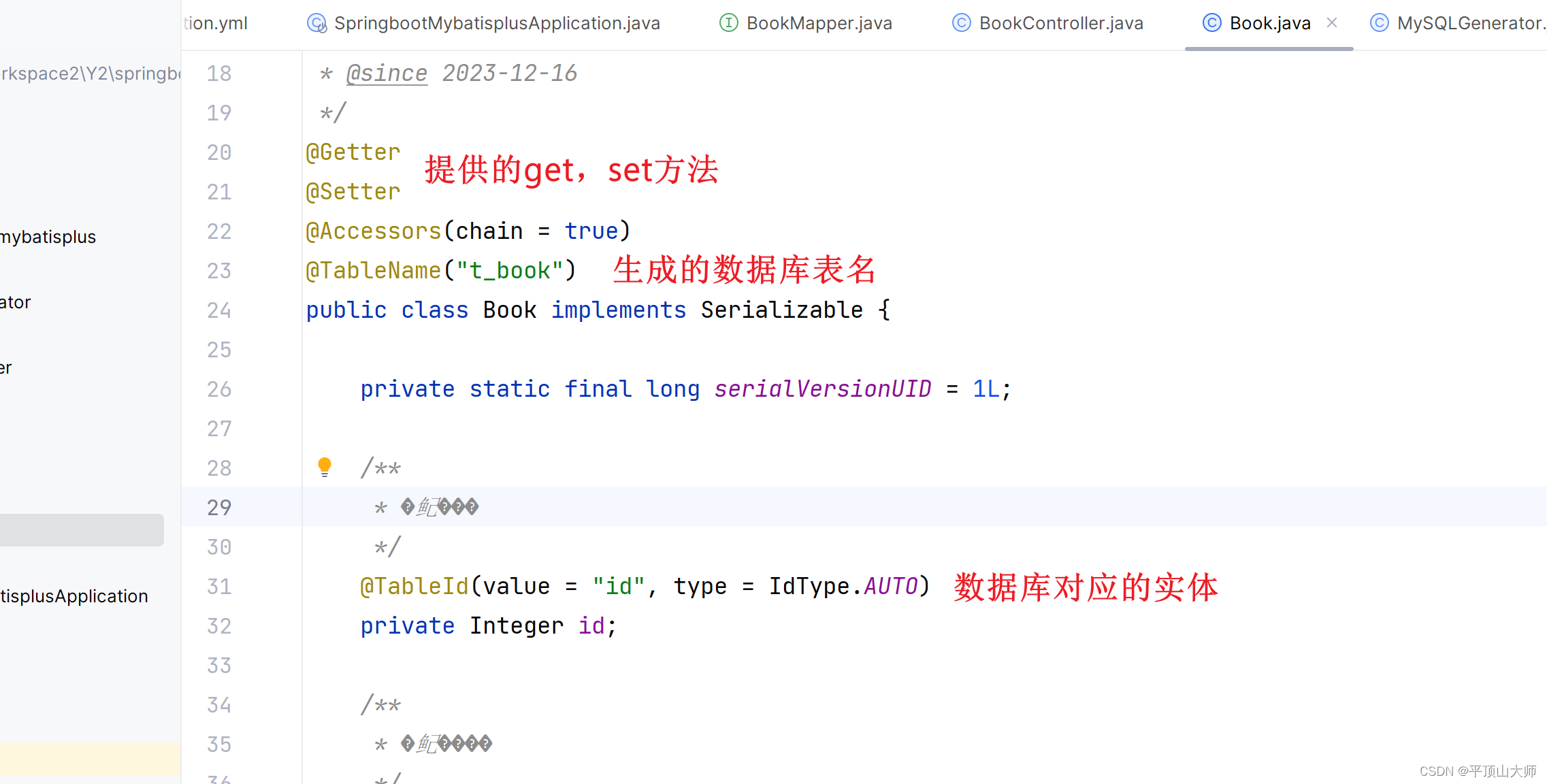
分析实体:
id这里:AUTO是自动增长的
雪花id依赖:
<dependency> <groupId>com.github.yitter</groupId> <artifactId>yitter-idgenerator</artifactId> <version>1.0.6</version> </dependency>
使用雪花id
YitIdHelper.nextId();

-
@TableId注解属性
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 主键字段名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
@TableId注解type属性IdType主键生成策略介绍:
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert 前自行 set 主键值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) |
注:@TableField字段注解(非主键),其中fill字段自动填充策略,具体策略如下:
| 值 | 描述 |
|---|---|
| DEFAULT | 默认不处理 |
| INSERT | 插入时填充字段 |
| UPDATE | 更新时填充字段 |
| INSERT_UPDATE | 插入和更新时填充字段 |
注解则是指定该属性在对应情况下必有值,如果无值则入库会是null。
-
2.6自定义实现类 MyMetaObjectHandler
@Slf4j
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("开始新增操作自动填充 ....");
this.strictInsertFill(metaObject, "createdate", LocalDateTime.class, LocalDateTime.now());
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("开始更新操作自动填充 ....");
this.strictUpdateFill(metaObject, "createdate", LocalDateTime.class, LocalDateTime.now());
}
}

三.UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。优点:
性能非常高:本地生成,没有网络消耗。
缺点:
没有排序,无法保证趋势递增。
UUID往往使用字符串存储,查询的效率比较低。
不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
MySQL官方有明确的建议主键要尽量越短越好[4],36个字符长度的UUID不符合要求。
对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
四.SnowFlake(雪花算法)
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:41-bit的时间可以表示(1L<<41)/(1000L360024*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
核心思想:
使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生4096个ID),最后还有一个符号位,永远是0,。
优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
可以根据自身业务特性分配bit位,非常灵活。
缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
?
下面重点讲一下 UUID 和雪花算法的区别:
结构不同:
- UUID 是一个 128 位的标识符,通常表示为 32 个十六进制数字,以连字符分隔成 5 组。
- 雪花算法生成的 ID 是一个 64 位整数,由时间戳、机器ID、数据中心ID和序列号组成。
唯一性不同:
- UUID 使用 MAC 地址、时间戳和随机数等信息生成标识符,因此理论上保证了全局唯一性。
- 雪花算法通过结合时间戳、机器ID和序列号生成 ID,可以保证在分布式系统中生成的 ID 具有较高的唯一性。
可读性不同:
- UUID 的标识符通常比较长且包含特殊字符,可读性较差。
- 雪花算法生成的 ID 通常是一个数值,可读性较好。
分布式支持不同:
- UUID 在分布式环境中生成时可能存在重复的风险,需要进行一些额外的处理来保证唯一性。
- 雪花算法通过使用机器ID和数据中心ID来区分不同的节点,可以在分布式环境中生成唯一的 ID。
总结:
1.MybatisPlus可以节省大量时间,所有的CRUD代码都可以自动化完成,MyBatis-Plus是一个MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。使用测试工具Apifox
2.UUID 和雪花算法的区别:
- UUID 使用 MAC 地址、时间戳和随机数等信息生成标识符,因此理论上保证了全局唯一性。
- 雪花算法通过结合时间戳、机器ID和序列号生成 ID,可以保证在分布式系统中生成的 ID 具有较高的唯一性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!