深入理解——快速排序
目录
💡基本思想
任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
💡基本框架
// 假设按照升序对array数组中[left, right)区间中的元素进行排序
void QuickSort(int* array, int left, int right)
{
if(right - left <= 1)
return;
// 按照基准值对array数组的 [left, right)区间中的元素进行划分
int div = partion(array, left, right);
// 划分成功后以div为边界形成了左右两部分 [left, div) 和 [div+1, right)
// 递归排[left, div)
QuickSort(array, left, div);
// 递归排[div+1, right)
QuickSort(array, div+1, right);
}这是快速排序递归实现的主框架,可以发现与二叉树的递归十分相似,在递归时可以想想二叉树的递归规则。
💡分割方法
?Hoare版本
这是Hoare于1962年提出的一种二叉树结构的交换排序方法
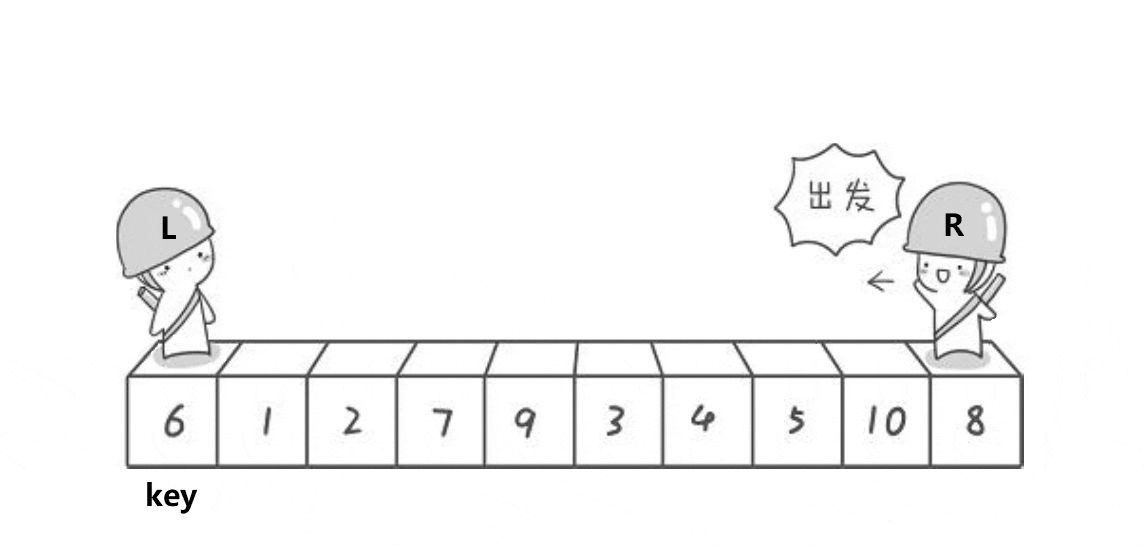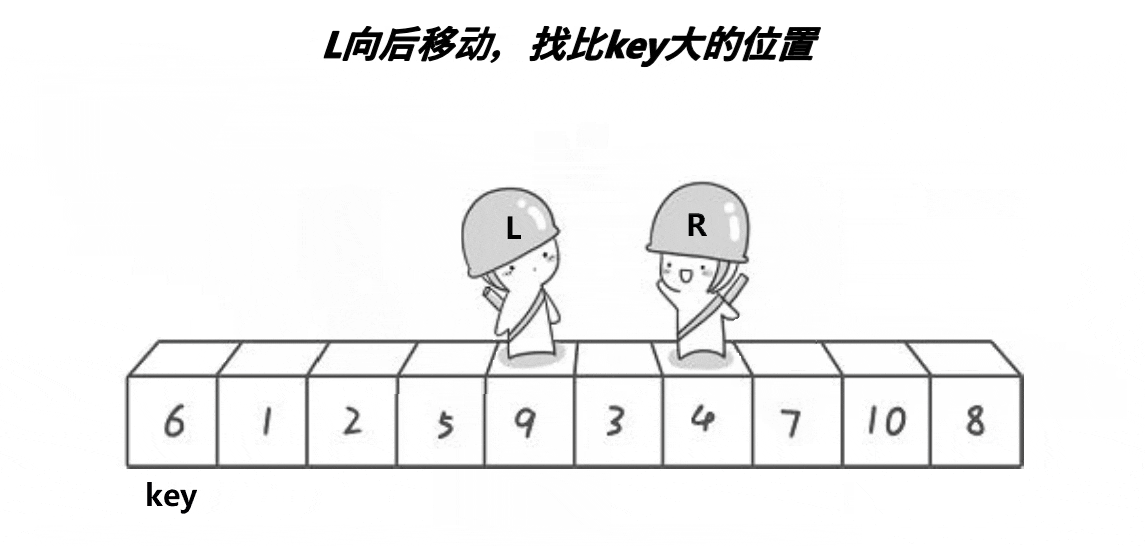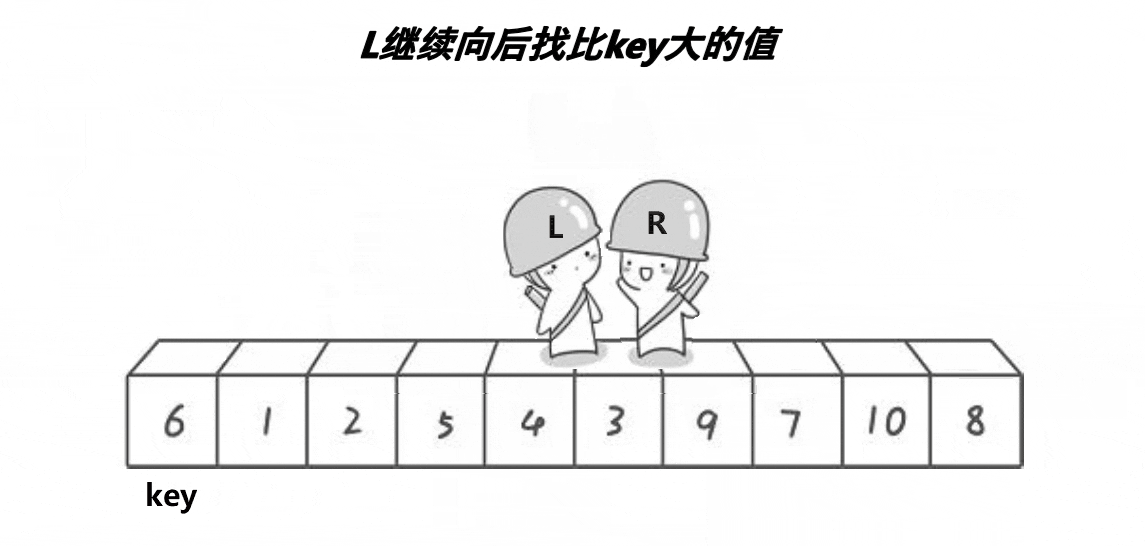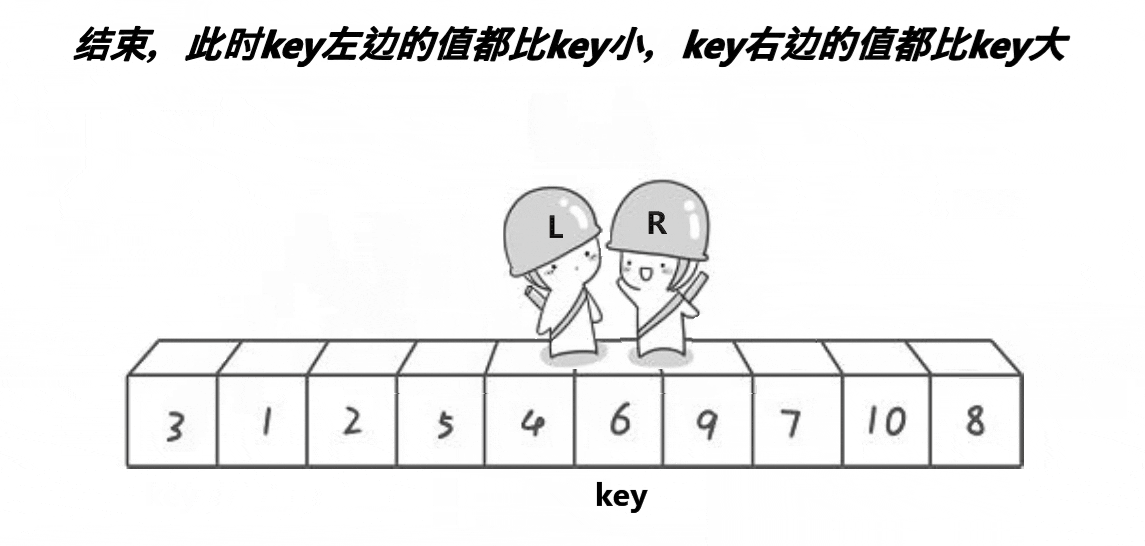
这个方法的思想就是R找比key小的数,L找比key大的数,然后将R和L对应的数交换,当R和L相遇时,将R和L对应的数与key交换,最终使得比key大的数都在key的右边,比key小的数都在key的左边。
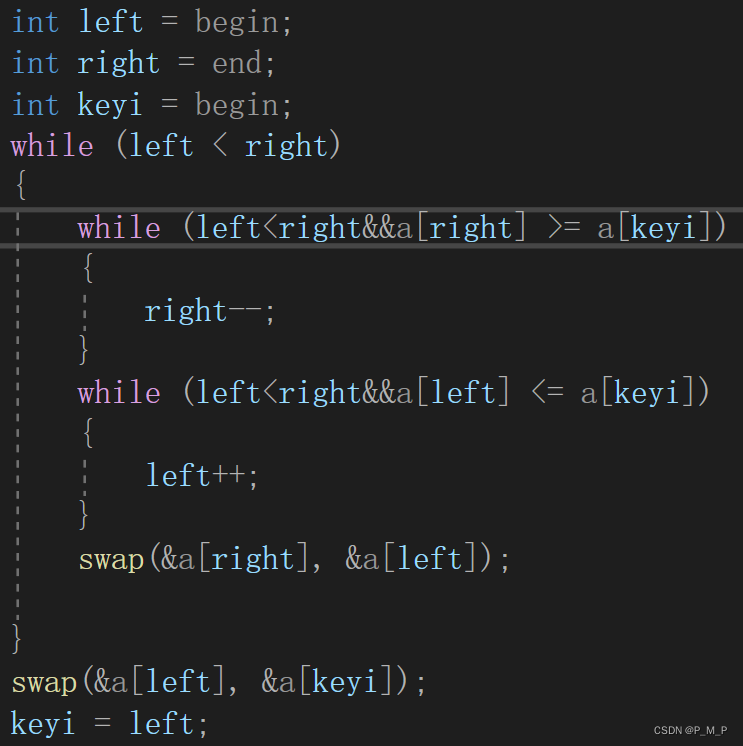
这里其实我们保存的时基准值的下标,记为keyi,这样做是为了方便交换,不然交换时只是与key这个临时变量发生了交换而没有影响到原来的数组里的数。
这里其实还有几个疑点:
- 当a[left],a[right]与a[keyi]相等时,怎么办?这里的处理方法其实就是不管它,直接继续原来的过程就可以了,最终两边排序时都会将这个数放到合理的位置。
- 为什么当R与L相遇时,它们所对应的数一定比a[keyi]小?要得到这个结论,必须要R先开始走,当R和L相遇时,有两种情况,一是L动的时候遇见R,此时R由于先走且一直在找比基准值小的数,所以当R停下时,R对应的数一定是小于等于基准值,L找比基准值大的数,一直没有找到,遇见R就停下来;二是R动的时候遇见L,R没有找到比key小的,所以一直走,又因为L一直在找比基准值大的数,所以当L停下时,L对应的数一定大于基准值,因此,只要R先走,R和L相遇时,对应的数一定比a[keyi]小。
?挖坑法
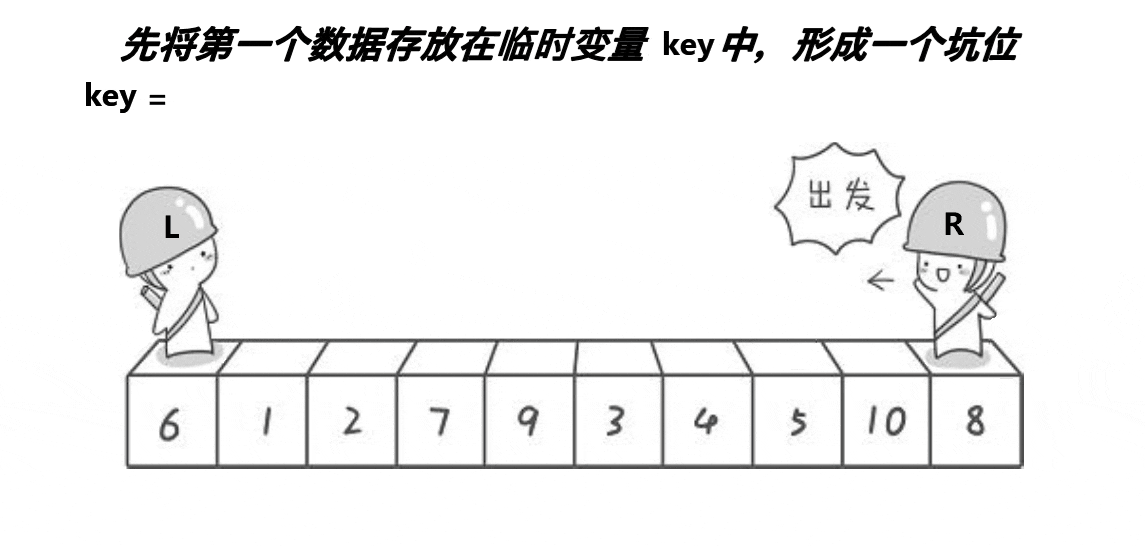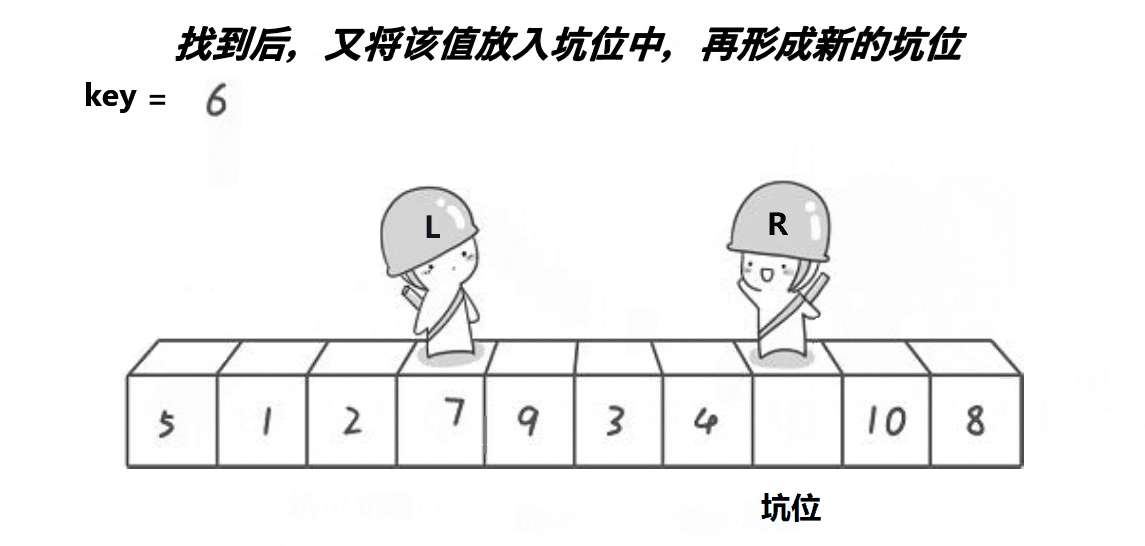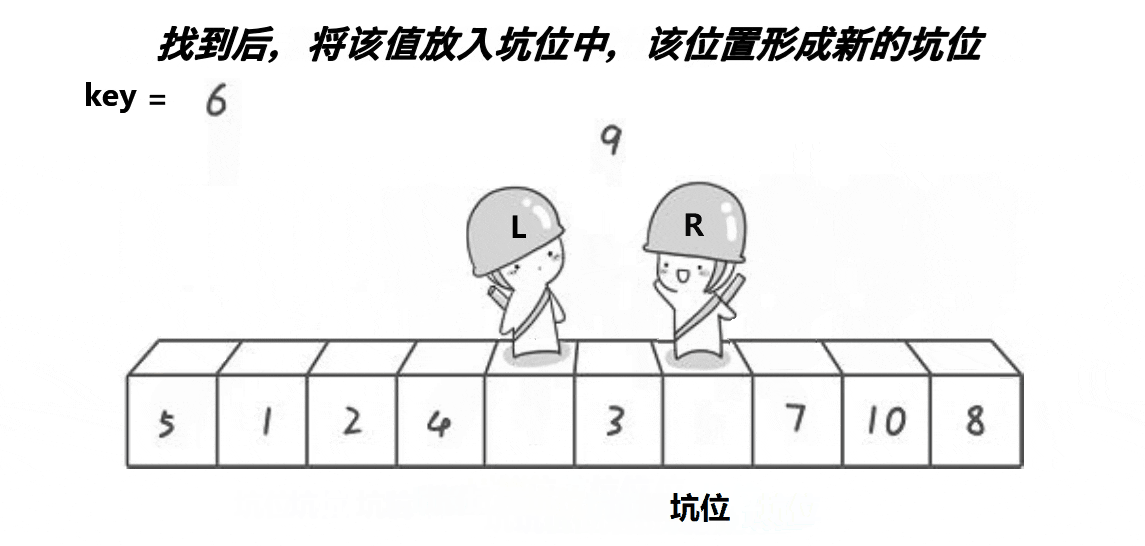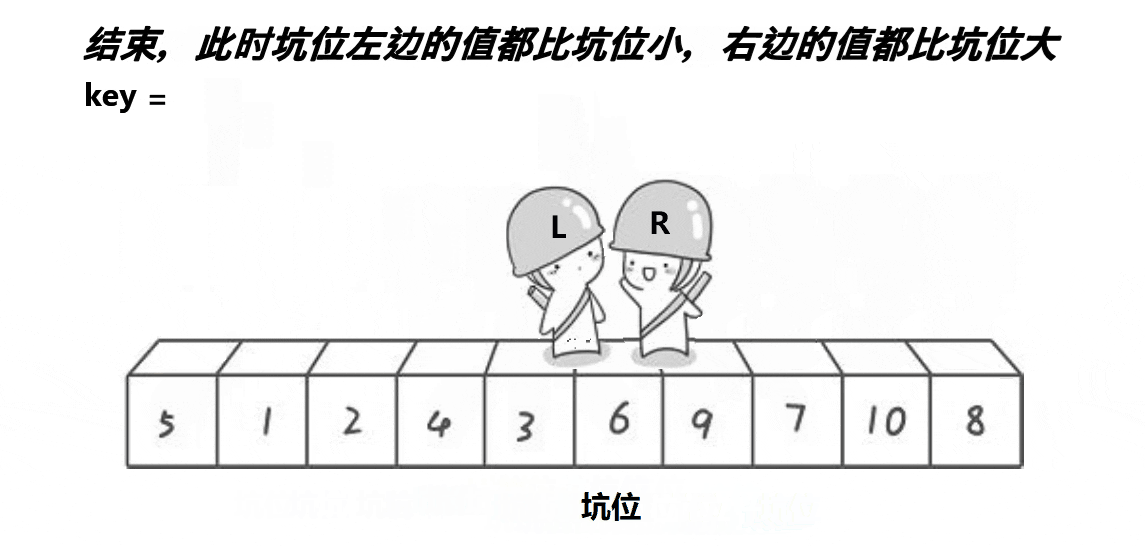
所谓挖坑法,就是第一次将基准值的位置设为坑(hole),然后R找比key小的数,填入到坑中,并使R对应的位置成为新的坑,然后L找比key大的数,填入到坑中,并使L对应的位置成为新的坑,再重复进行这个过程,当R和L相遇时,此时它们所对应的位置一定是一个坑,然后再将key填入到坑中,此时key左边的数一定比它小,key右边的数一定比他大。
这个方法相较于hoare的方法更加好理解,但是性能上并没有太大的变化。
//挖坑法
int PartSort(int* a, int begin, int end)
{
int midi = GetMidi(a, begin, end);
swap(&a[begin], &a[midi]);
int key = a[begin];
int hole = begin;
while (begin < end)
{
//右边找小,填到左边的坑
while (begin < end && a[end] >= key)
{
end--;
}
a[hole] = a[end];
hole = end;
//左边找大,填到右边的坑
while (begin < end && a[begin] <= key)
{
begin++;
}
a[hole] = a[begin];
hole = begin;
}
a[hole] = key;
return hole;
}?前后指针法
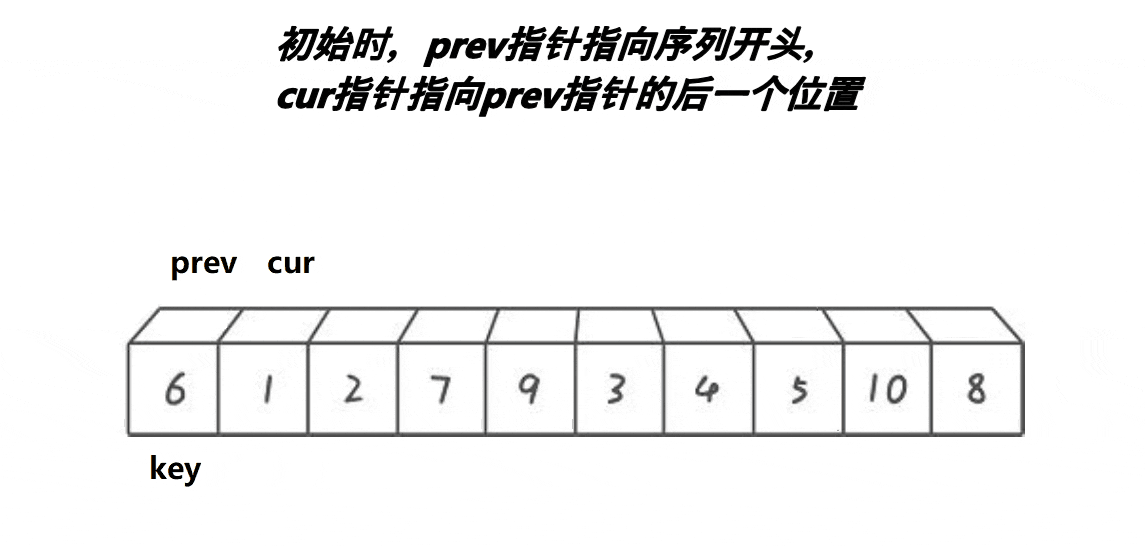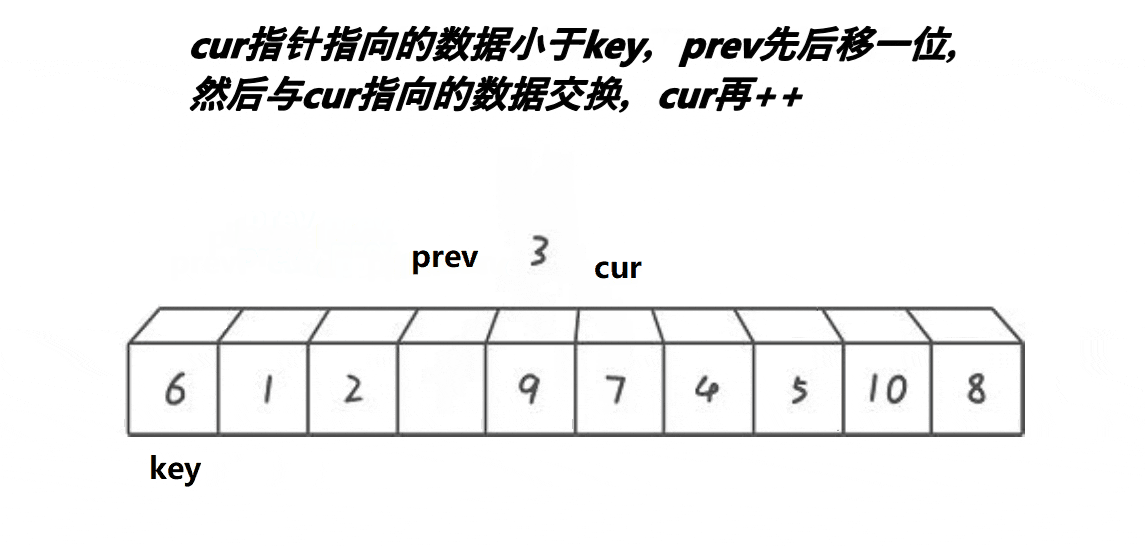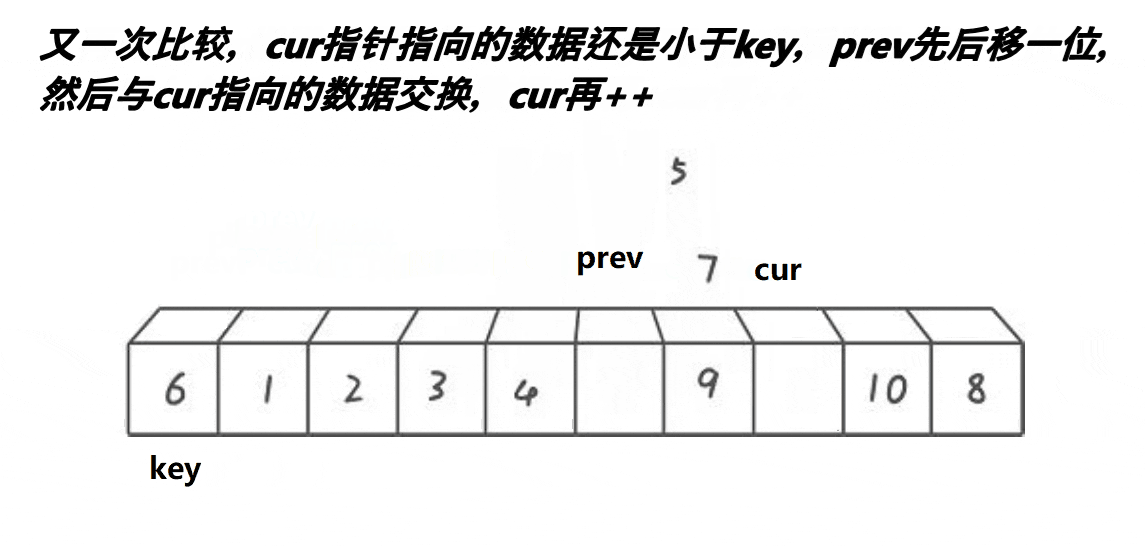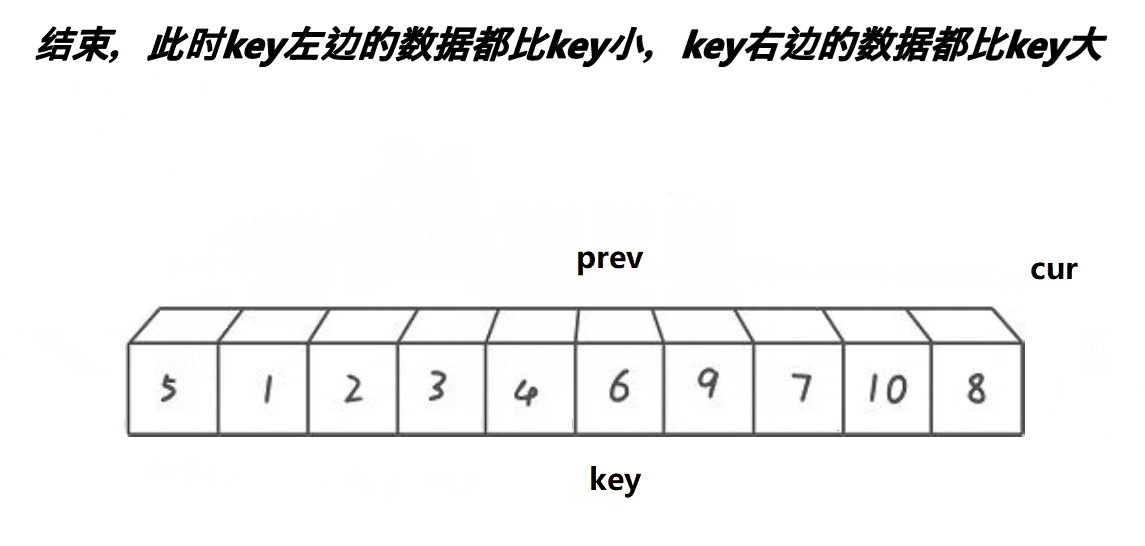
这个方法就是
- cur遇到比key大的数,cur++;
- cur遇到比key小的数,prev++,交换cur与prev位置的值,cur++。
- 当cur超出数组边界时,将prev位置的值与key位置的值交换。
int PartSort(int* a, int begin, int end)
{
int midi = GetMidi(a, begin, end);
swap(&a[begin], &a[midi]);
int keyi = begin;
int prev = begin;
int cur = begin + 1;
while (cur <= end)
{
if (a[cur] < a[keyi] && ++prev != cur)//自身交换减少了
{
swap(&a[prev], &a[cur]);
}
cur++;
}
swap(&a[keyi], &a[prev]);
keyi = prev;
return prev;
}💡优化方法
?三数取中法
所谓三数取中法,其实取的是三个数中的中位数,将这个数作为基准值,能够避免某些极端情况的出现(比如数组已经接近有序)。
?注:这是针对基数选取进行的优化,另外还有随机数法选数,在这里就不过多介绍了。

int GetMidi(int* a, int begin, int end)
{
int midi = (begin + end) / 2;
//取中位数
if (a[begin] <= a[midi])
{
if (a[midi] <= a[end])
{
return midi;
}
else
{
if (a[begin] <= a[end])
return end;
else
return begin;
}
}
else //midi begin
{
if (a[begin] >= a[end])
{
if (a[midi] >= end)
{
return midi;
}
else
return end;
}
else
return begin;
}
}?小区间内使用插入排序
在递归到较小区间时,如果仍然使用快速排序,会造成时间上的浪费,假如这个区间内有7个数,那就要递归7次才能得到这个7个数的有序序列。
if(end-begin+1 <= 10)
{//某个区间内的小规模排序直接插入排序
//进行插入排序
InsertSort(arr,end-begin+1);
return;
}
💡非递归实现快速排序
非递归实现方法其实与递归的方法类似,但是需要借助栈这个数据结构(避免其他方法造成栈溢出)。
每次将要排序的区间的起始位置入栈,然后排序时再取栈顶的前两个元素作为一个排序区间进行快速排序,然后依次对key的左区间、右区间进行这样的操作,最终得到有序序列。
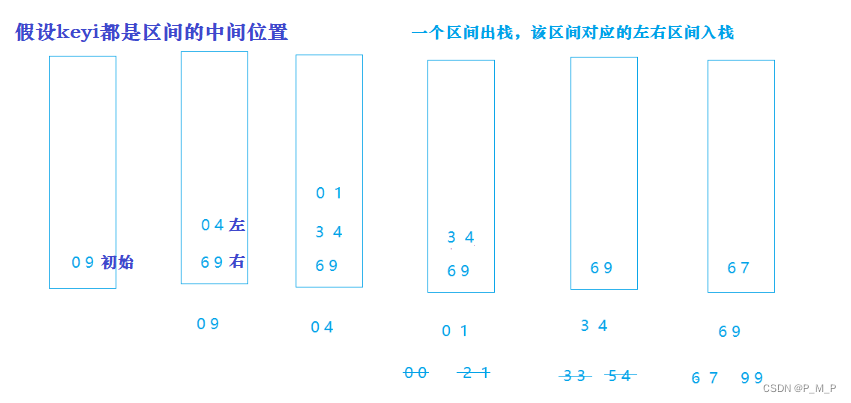
void QuickSortNonR(int* a, int begin, int end)
{
ST s;
STInit(&s);
STPush(&s, end);
STPush(&s, begin);
while (!STEmpty(&s))
{
int left = STTop(&s);
STPop(&s);
int right = STTop(&s);
STPop(&s);
int keyi = PartSort(a, left, right);
// [left, keyi-1] keyi [keyi+1, right]
if (left < keyi - 1)
{
STPush(&s, keyi - 1);
STPush(&s, left);
}
if (keyi + 1 < right)
{
STPush(&s, right);
STPush(&s, keyi + 1);
}
}
STDestroy(&s);
}💡性能分析
- 时间复杂度:最差O(N^2),最好O(NlogN),平均O(NlogN)
- 空间复杂度:O(logN),因为递归时创建的栈帧(申请的空间)没有销毁,递归的深度为logN
- 稳定性:不稳定
- 特点:数据越乱排序越快
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!