DS哈希查找—线性探测再散列
2023-12-18 10:01:45
Description
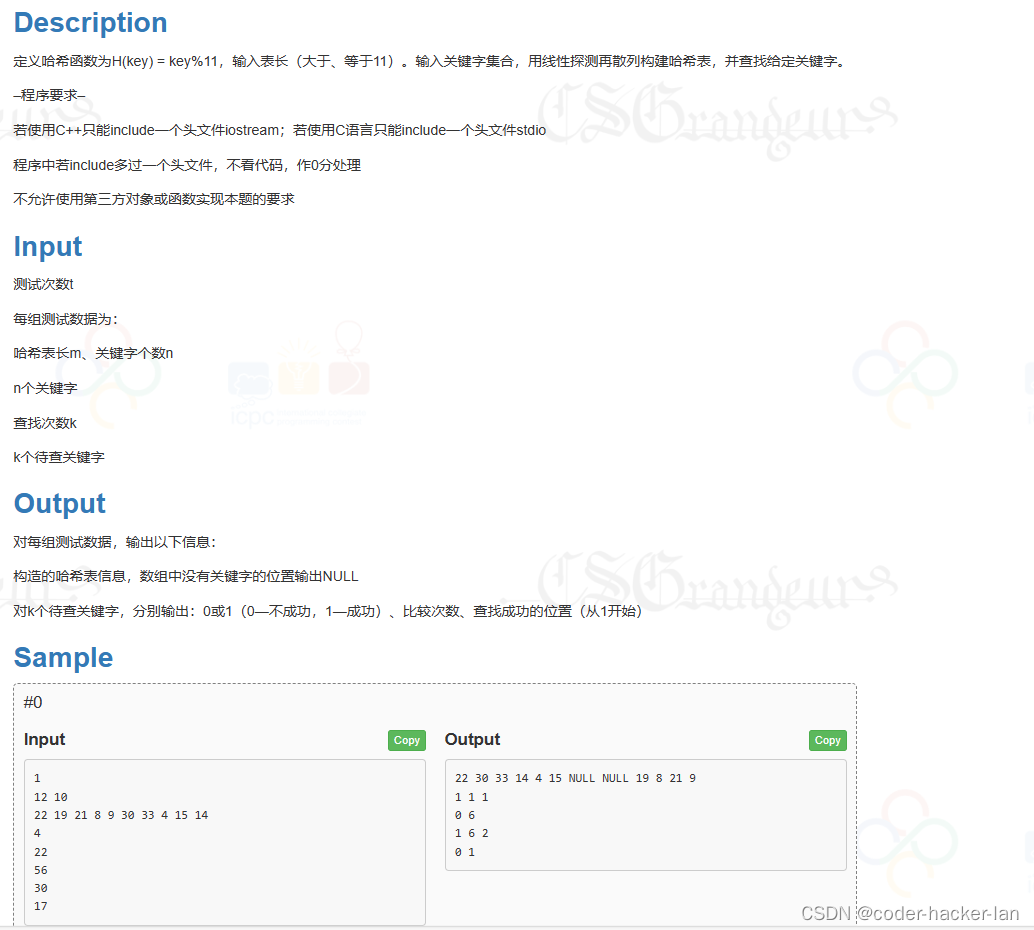
定义哈希函数为H(key) = key%11,输入表长(大于、等于11)。输入关键字集合,用线性探测再散列构建哈希表,并查找给定关键字。
–程序要求–
若使用C++只能include一个头文件iostream;若使用C语言只能include一个头文件stdio
程序中若include多过一个头文件,不看代码,作0分处理
不允许使用第三方对象或函数实现本题的要求
Input
测试次数t
每组测试数据为:
哈希表长m、关键字个数n
n个关键字
查找次数k
k个待查关键字
Output
对每组测试数据,输出以下信息:
构造的哈希表信息,数组中没有关键字的位置输出NULL
对k个待查关键字,分别输出:0或1(0—不成功,1—成功)、比较次数、查找成功的位置(从1开始)
Sample
#0
Input
Copy
1 12 10 22 19 21 8 9 30 33 4 15 14 4 22 56 30 17
Output
Copy
22 30 33 14 4 15 NULL NULL 19 8 21 9 1 1 1 0 6 1 6 2 0 1
哈希算法:
- 从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法)
- 对输入数据非常敏感,哪怕原始数据只修改了一个 Bit,最后得到的哈希值也大不相同;
- 散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小;
- 哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值。
简而言之:哈希算法不可逆,并且有两个不同的例如a,b的哈希值的散列值相等的概率很小、、
哈希表:
? ? ? ?哈希表也叫散列表,哈希表是一种数据结构,它提供了快速的插入操作和查找操作,无论哈希表总中有多少条数据,插入和查找的时间复杂度都是为O(1),因为哈希表的查找速度非常快,所以在很多程序中都有使用哈希表。
思路:
? ? ? ?本题给的数据会造成哈希的散列冲突,造成哈希冲突的时候就可以按顺序顺沿数组位置找空位,然后插入我们的值。
如:
H(key) = key%11

tips:这个表其实也可以理解为首尾相连的表:
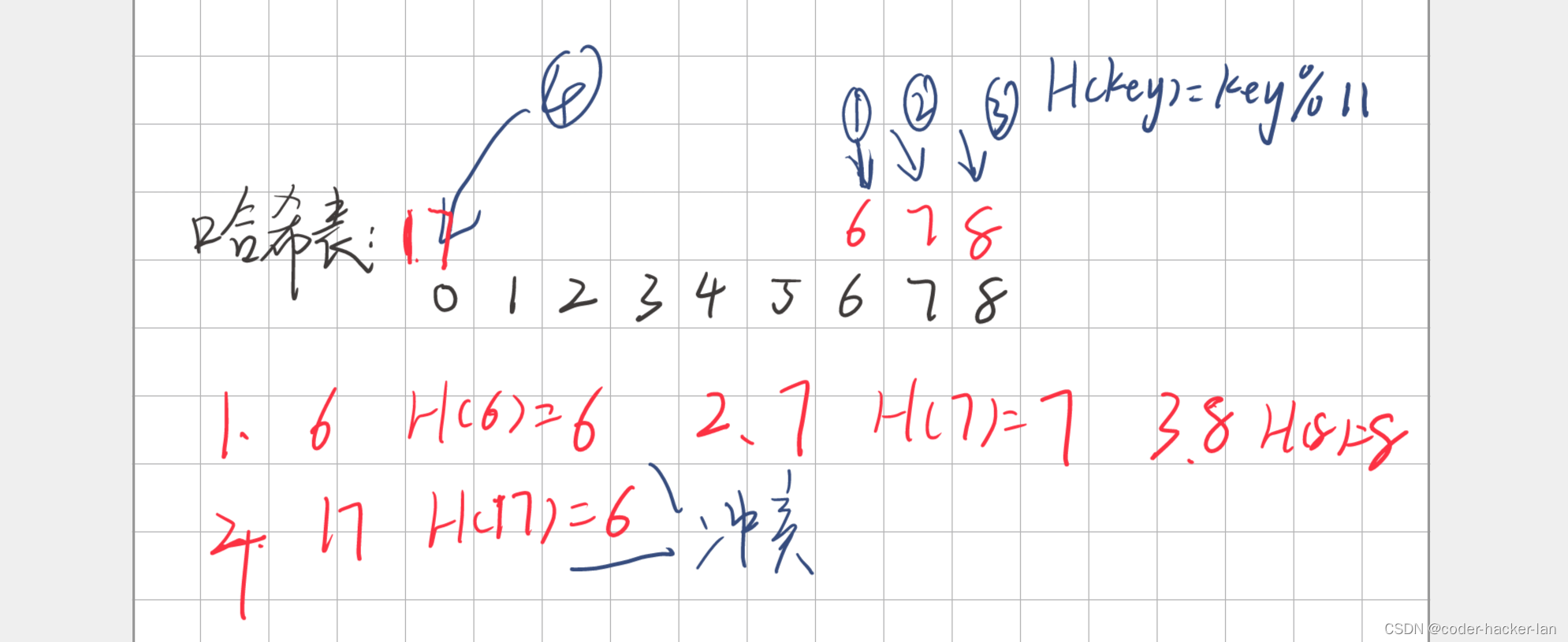
坑点:
? ? ? ? 好像没人告诉你要哈希的数一定比表长度小吧。如果多了的话,我表塞满了,我们靠循环找空位置的写法可能会导致卡在循环里出不来。写法如果是找不到就找下一个位置,直到找到空位为止,那就可能会死循环了!!!
? ? ? ?所以多余的部分你要不就不找了,要不就找的时候控制下循环,让查找次数不能超过表长
完整代码:
#include <iostream>
using namespace std;
const int maxn = 1e3 + 10;
int hashi[maxn];
int n, m;//n是表长,m是有多少个数将被哈希
int findnullindex(int num)
{
int key = num % 11;//这个就是哈希函数获得的值
int cnt = 0;//cnt我是用来表示查找次数的,如果我们表每个位置都遍历一遍没有位置,说明没有空位
while (1)
{
if (cnt > n)//如果查找次数大于表长,那就说明没有空位
{ //原因是如果要哈希的数多于表长,塞满了哪里还塞得下
return -1;
}
if (hashi[key] != -1)//说明这个位置有数了,所以得继续往下找
{
key++;
}
else
{
return key;//查找到了空位,返回空位下标
}
key = key % n;//每次都取余一下,这样就不会超过表长了
cnt++;//查找次数+1
}
}
void insert(int num)
{
int index = findnullindex(num);//查找可以插入的空位
if (index != -1)//如果有空位就在index这个位置插入num
{
hashi[index] = num;
}
}
int main()
{
int t;
cin >> t;
while (t--)
{
cin >> n >> m;
for (int i = 0; i <= n; i++)
{
hashi[i] = -1;//首先初始化哈希表都为-1
}
for (int i = 1; i <= m; i++)
{
int num;
cin >> num;
insert(num);//输入要哈希的数,然后将他插入进表里
}
for (int i = 0; i < n; i++)
{
if (hashi[i] != -1)
{
cout << hashi[i] << " ";
}
else
{
cout << "NULL ";
}
}
cout << endl;
int t;
cin >> t;
while (t--)
{
int num;
cin >> num;
int key = num % 11;
int cnt = 1;//这里的cnt是计算查找次数的
while (hashi[key] != -1 && hashi[key] != num)//如果key所在为-1,说明没有这个数
{ //key这个位置有数也可能是冲突值,得往之后的位置查找一遍
if (cnt >= n)//这个意思说明查找完所有位置都没找到
{
key = n;//因为我表长n,下标为0-n-1,所以n这个位置是-1,肯定不会被更改
break; //所以我用来当作没找到
}
key++;
cnt++;//如果找到了cnt刚好也可以记查找次数
key = key % n;
}
if (hashi[key] == -1)//key所在的值为-1说明就是没找到
{
cout << "0 " << cnt << endl;
}
else
{
cout << "1 " << cnt << " " << key + 1 << endl;
}
}
}
return 0;
}
文章来源:https://blog.csdn.net/weixin_74790320/article/details/135053420
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!