【Hive】
2023-12-13 17:37:24
一、Hive是什么
- Hive是一款建立在Hadoop之上的开源数据仓库系统,将Hadoop文件中的结构化、半结构化数据文件映射成一张数据库表,同时提供了一种类SQL语言(HQL),用于访问和分析存在Hadoop中的大型数据集。
- Hive的核心是将HQL转换成MapReduce程序,然后将其提交到Hadoop集群执行。(用户只需要编写HQL而不需要编写MapReduce程序,减少了学习成本、开发成本。)
- Hive利用HDFS存储数据,利用MapReduce查询分析数据
- Hive能将数据文件映射成一张表,能将SQL编译成为MapReduce然后处理这个表
二、Hive的架构图
- hive能够写SQL的前提是针对一张表,而不是文件,因此要将文件和表之间的对应关系记录清楚。这个关系称为元数据信息
元数据信息记录:
- 表对应的什么文件(对应文件的位置)
- 表的每列对应文件的哪个字段,是什么类型(字段顺序,字段类型)
- 文件中各字段的分隔符是什么
Hive工作流程 :
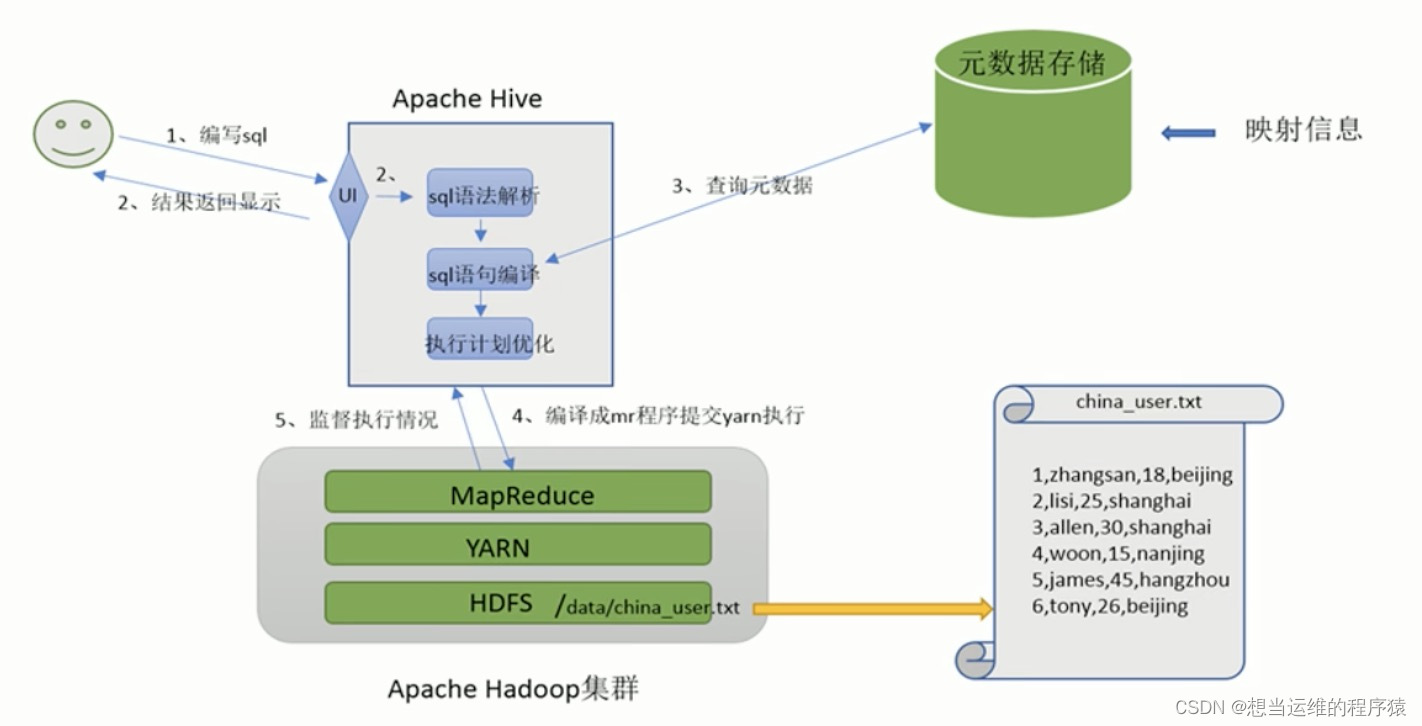
Hive架构图:
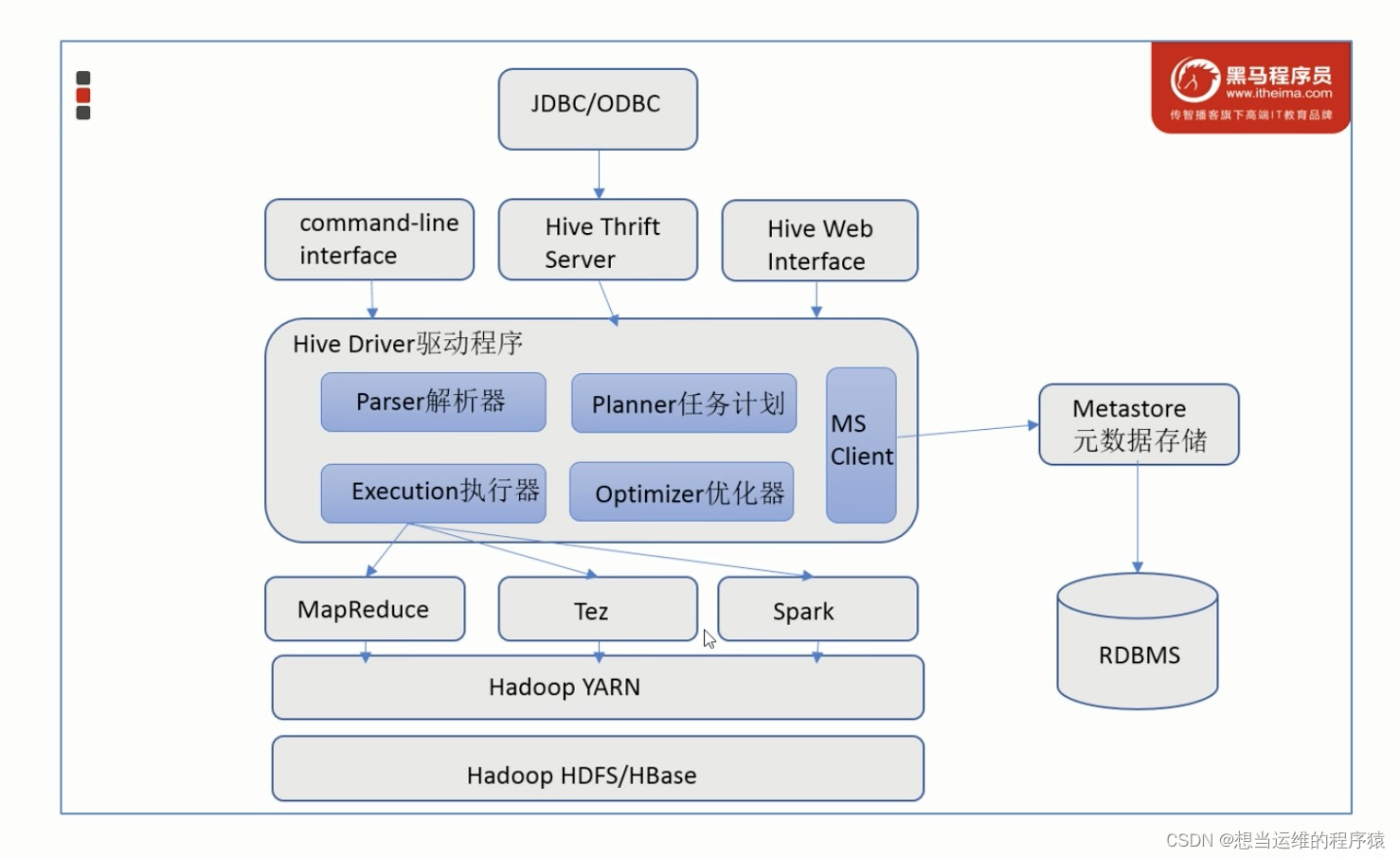
- Metastore元数据服务: 通常用mysql/derby等(关系型数据库)来存储表和文件的映射关系。Metastore服务用来管理metadata元数据,外部只能通过Metastore服务访问元数据的数据库。
- Driver驱动程序: Hive的核心,包括语法解析器、计划编译器、优化器、执行器
- 执行引擎: Hive不处理数据 ,而是由执行引擎处理,目前Hive支持MapReduece、Tez、Spark三种执行引擎。(Hive可以将SQL转换成MapReduce或Tez或Spark,默认是MapReduce)
三、Hive数据模型
Hive从数据模型上看与MySQL很相似,也有库、表、字段。
但是Hive只适合用来做海量数据的离线分析,Hive一般用于数仓,MySQL一般用于业务系统。
| Hive | MySQL | |
|---|---|---|
| 定位 | 数据仓库 | 数据库 |
| 使用场景 | 离线数据分析 | 业务数据事务处理 |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Local FS |
| 执行引擎 | MR、Tez、Spark | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 常见操作 | 导入数据、查询 | 增删改查 |
- Hive中的数据可以在粒度级别上分成3类
Table 表
Partition 分区
Bucket 分桶 - 底层存储:
数据库存储:itcast数据库对应的存储路径是/user/hive/warehouse/itcast.db
表存储:itcast数据库下t_user表对应的存储路径/user/hive/warehouse/itcast.db/t_user
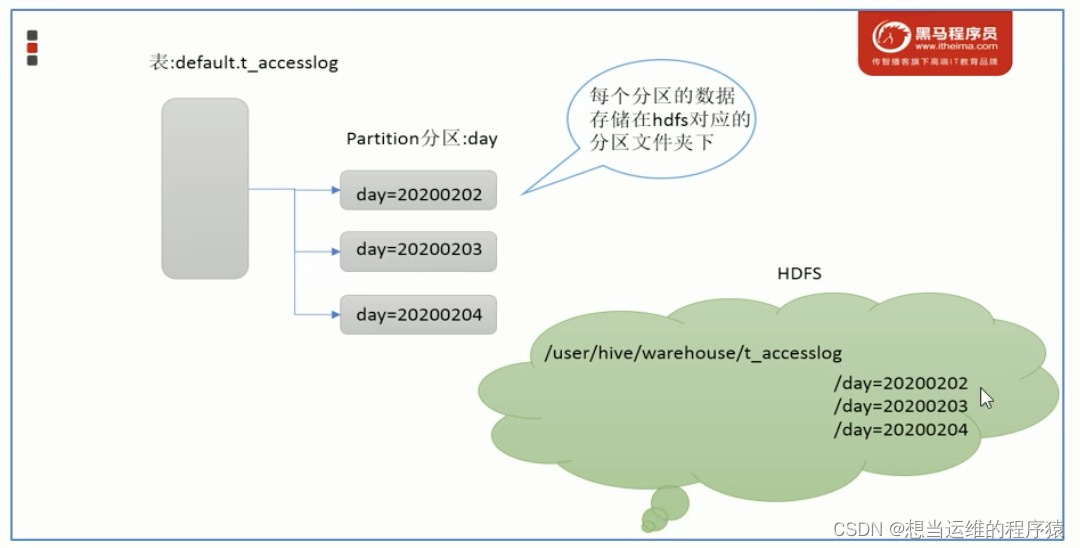
partitions分区:分区是指根据分区列(例如“日期day”)的值将表划分为不同分区,一个文件夹表示一个分区,分区列=分区值
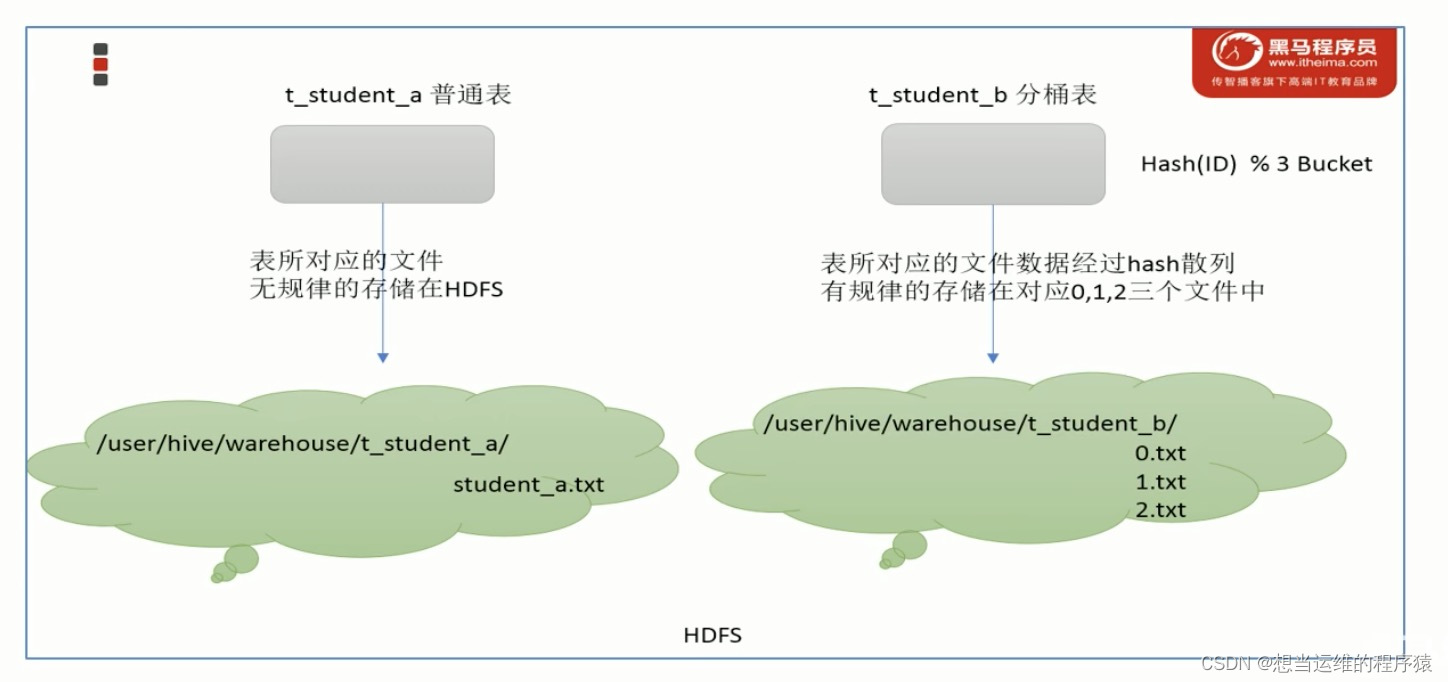
Buckets分桶:分区是指根据表中字段(例如“编号ID”)的值,经过Hash计算规则将文件划分成指定的若干个小文件
三、Hive的各个组件
文章来源:https://blog.csdn.net/qq_33218097/article/details/134973865
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!