强化学习在生成式预训练语言模型中的研究现状简单调研
1. 绪论
本文旨在深入探讨强化学习在生成式预训练语言模型中的应用,特别是在对齐优化、提示词优化和经验记忆增强提示词等方面的具体实践。通过对现有研究的综述,我们将揭示强化学习在提高生成式语言模型性能和人类对话交互的关键作用。虽然这些应用展示了巨大的潜力,但也将讨论现有方法的挑战和可能的未来发展方向。
在当今人工智能领域,生成式预训练语言模型的崛起成为自然语言处理和文本生成的一项重大突破。这一技术通过在大规模文本数据上进行预训练,使得模型能够学到语言的深层次结构和模式,从而具备出色的生成能力。生成式预训练模型的出现引领了自然语言处理的新潮流,但也伴随着一系列挑战,如模型的价值对齐、生成结果不可控、难以实现交互式学习与经验利用等问题。
强化学习,作为一种通过智能体与环境的交互来学习最优行为的方法,近年来在生成式预训练语言模型中得到了广泛关注。将强化学习引入生成式模型的训练过程,不仅可以提高模型生成结果的质量,还能够使模型更好地适应特定任务和领域。
本文的研究目的在于深入探讨强化学习在生成式预训练语言模型中的应用,着眼于理解其在不同阶段的作用机制和效果。通过对该结合应用的系统研究,我们旨在揭示强化学习如何优化模型性能、对齐人类价值观、以及优化和增强提示词等方面发挥的关键作用。
本文将围绕生成式预训练语言模型与强化学习的结合展开,结构安排如下:第二章将简要介绍生成式人工智能与预训练微调范式的基本概念,为读者提供理论基础和背景知识。第三章将详细阐述强化学习在生成式预训练语言模型中的应用,包括对齐优化、提示词优化、经验记忆增强等方面的研究与实践。
2. 生成式预训练语言模型介绍
生成式预训练语言模型作为人工智能领域的热点之一,其在自然语言生成和理解方面的表现引起了广泛关注。这些模型的背后通常是庞大的神经网络结构,其中使用了生成式人工智能和迁移学习的思想,为其在不同任务上的灵活性和性能提供了基础。
2.1 生成式人工智能
生成式人工智能是一种强调模型能够自主创造新内容和信息的人工智能范式。与传统的判别式人工智能不同,生成式人工智能不仅能够理解输入数据的特征,还可以生成具有相似特征的全新数据。这使得生成式人工智能在语言生成、图像创作、音乐合成等领域表现出色。其核心思想是通过学习数据的分布和模式,使模型能够生成与训练数据类似但又不完全相同的新样本,从而展现出一定的创造性和想象力。生成式人工智能的发展在许多应用中取得了显著成就,为人工智能的创新和进步提供了新的可能性。
2.2 迁移学习
大模型中常说的“预训练-微调”,其实是一种迁移学习下的范式,这一思想的核心在于将从一个领域中获得的知识应用到另一个相关领域,从而提升目标领域的学习性能。这种方法尤为重要,特别是在目标领域的数据相对稀缺或难以获取的情况下。通过利用先前在一个领域上获取的知识,模型能够更有效地适应新的任务或领域,为整体学习性能的改善提供了有力支持。这种迁移学习的范式为解决数据稀缺和难以获得的问题提供了一种实用而有效的方法。
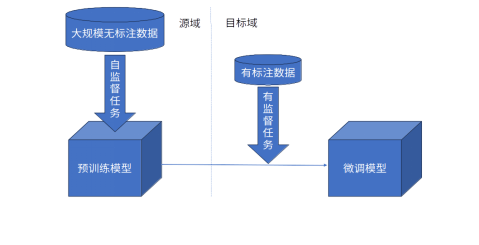
图2-1 预训练范式示意图
3.强化学习在生成式预训练语言模型中的应用
强化学习作为一种强调在特定环境中通过试错学习来最大化奖励的学习范式,在生成式预训练语言模型中展现出了强大的潜力。本节将深入研究强化学习在生成式预训练语言模型中的应用,从预训练、微调到推理等不同阶段,揭示强化学习在优化模型性能、对齐人类价值观以及优化提示词等方面的关键作用。通过对相关方法和技术的介绍,我们将从多个方面了解强化学习如何推动生成式预训练语言模型的发展,为生成式人工智能领域的未来带来更多可能性。
3.1对齐优化
我们知道大语言模型 (Large Language Model, LLM)在经历预训练(Pre-Training)和有监督微调(Supervised Fine-Tuning, SFT)后,由于自监督预训练任务通常只是简单的词预测任务,因此仍然普遍存在忠实性、伦理道德、数据安全等多方面的缺陷,好似一个口无遮拦的模型。上述这些问题缺陷恰恰较难以用严格的数学形式进行描述定义,因为其通常是隐含在人类的价值观中的一种主观偏好。因此一个用于与人类交互的生成式预训练语言模型需要进行对齐 (Alignment),通俗地说,是将上游基础模型和人类意图价值这两块长短不一的板子给对齐了,得到一个更符合人类价值观和意图的大语言模型。
对齐的方法可以分为生成器优化对齐(generator improvement)和推理时附加对齐(inference-time add-on)1,主要区别在与前者是需要进行参数更新的,而后者作用于推理阶段故不用进行参数更新。
3.1.1 生成器优化对齐
生成器优化对齐中的生成器,指的是用于生成自然语言文本序列的模型,多数情况下都是预训练Transformer模型。而生成器优化对齐,指在训练阶段对模型进行参数微调对齐以达到优化生成结果、与人类对齐的目的。举例来说其实最常见的生成器优化方法就是有监督微调(Supervised Fine-Tuning, SFT)和人类反馈强化学习(Reinforcement Learning with Human Feedback, RLHF)。本小节将主要介绍基于人类反馈强化学习的对齐微调。
有监督微调依赖于有标签文本数据,数量和质量上存在限制,难以使模型高效学习到人类偏好。而ChatGPT发布之初能如此惊艳的一大功臣,就是基于人类反馈强化学习的微调对齐方法。
人类反馈强化学习的起源可以追溯到收录于NIPS 2017的Christiano等人所著的“Deep reinforcement learning from human preferences”2, 其中RLHF被用于利用人类反馈优化训练一个模拟环境中的火柴棒小人做后空翻。这篇文章很好地介绍了如何通过建模人类偏好让强化学习agent学习到如何做一个人类认为好的后空翻,为后来RLHF被用于大语言模型奠定了基础。
OpenAI在接连发布三代GPT后,发表了InstructGPT的论文3,公开了RLHF这项OpenAI的独门秘籍,下面就简单介绍一下这篇文章的RLHF方法。
文章在GPT3的基础模型上进行微调,微调分三步走,如下图:
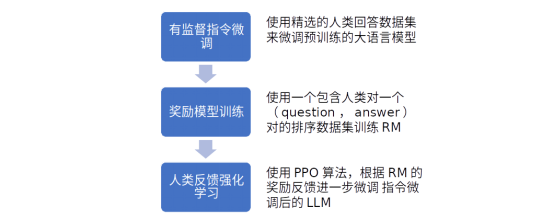
图3-1 InstructGPT中的人类反馈强化学习方法的三个主要步骤
其中第二步的奖励模型(Reward Model, RM)是一个从6B参数的SFT后的GPT模型开始进行梯度下降训练的,其最后的unembedding层被移除了。之所以不用175B参数的是因为不稳定,文章附件有介绍这一原因。
RM的训练数据收集很有巧思,因为他们并不是只给两个输出结果要求人类标签员去选一个好的,而是针对一个prompt生成K个结果,并要求标签员对这些结果从好到坏排序,那么这样一次排序任取其中两个结果排列组合可以产生
C
2
K
C_2^K
C2K?个comparison pair,形如
(
x
,
y
w
,
y
l
)
(x,y_w,y_l)
(x,yw?,yl?),其中是输入prompt,
y
w
y_w
yw?是比
y
l
y_l
yl?更好的一个输出结果(我猜下标w代表win,l代表lose)。
RM训练时的loss函数为:
l o s s ( θ ) = 1 C 2 K E ( x , y w , y l ) ~ D [ log ? ( σ ( r θ ( x , y l ) ) ) ] loss(\theta)=\frac{1}{C_2^K} E_{(x,y_w,y_l) \sim D} [\log{(\sigma(r_\theta(x,y_l)))}] loss(θ)=C2K?1?E(x,yw?,yl?)~D?[log(σ(rθ?(x,yl?)))]
其中
r
θ
(
x
,
y
)
r_\theta(x,y)
rθ?(x,y)是奖励模型的标量输出,
D
D
D是整个人类comparison pair数据集,KaTeX parse error: Expected '}', got 'EOF' at end of input: …y_w,y_l) \sim D表示从数据分布
D
D
D中采样一个提示词输入
x
x
x及其对应的一好一坏两个生成结果
y
w
y_w
yw?和
y
l
y_l
yl?,并计算期望。
简而言之,奖励模型的训练采用了对比学习的思想,希望RM扩大正样本和负样本间的得分差异,且希望让正样本得分高于负样本。
第三步的强化学习阶段非常关键,其混合了PPO梯度和预训练梯度,并将这种混合梯度训练的模型称为PPO-ptx, 具体来说RL训练时的混合目标函数为:
o b j e c t i v e ( ? ) = E ( x , y ) ~ D π ? R L [ r θ ( x , y ) ? β log ? ( π ? R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x ~ D p r e t r a i n [ l o g ( π ? R L ( x ) ) ] objective(\phi)=E_{(x,y)\sim D_{\pi_{\phi}^{RL}}} [r_\theta(x,y)-\beta \log (\pi_{\phi}^{RL} (y | x) / \pi^{SFT} (y | x))] + \gamma E_{x \sim D_{pretrain}} [log (\pi_{\phi}^{RL} (x))] objective(?)=E(x,y)~Dπ?RL???[rθ?(x,y)?βlog(π?RL?(y∣x)/πSFT(y∣x))]+γEx~Dpretrain??[log(π?RL?(x))]
其中
π
?
R
L
\pi_{\phi}^{RL}
π?RL?是要学习的RL策略,
π
S
F
T
\pi^{SFT}
πSFT是有监督微调过的模型,
D
p
r
e
t
r
a
i
n
D_{pretrain}
Dpretrain?是预训练数据集分布,
β
\beta
β是KL散度奖励系数,
γ
\gamma
γ是预训练损失系数。
简而言之,该目标函数希望RL模型可以最大化来自RM的奖励,最小化RL策略和SFT模型的KL散度(即希望RL策略不偏离SFT模型,从而提高稳定性和鲁棒性),并且最后还将预训练梯度也纳入考虑,希望提高稳定性和训练效率。
3.1.2 推理时附加对齐
了解完大家最熟悉的基于RLHF的微调对齐,这里介绍一个作用于推理阶段,不用更新模型参数的对齐方式:语言模型受控解码,由Google Research的Mudgal1等人发表。
这篇论文提出了一种名为受控解码(Controlled Decoding,简称CD)的新型off-policy强化学习方法,用于控制语言模型的自回归生成过程,使其朝向高奖励结果的推理路径进行推理。CD通过一个名为前缀评分器(prefix scorer)的价值函数来解决离策略强化学习问题,该前缀评分器在推理阶段用于引导生成过程朝向更高奖励结果。文章中强化学习的应用概括如下:
问题建模:作者将控制语言模型生成过程的问题建模为一个离策略强化学习问题。在这个问题中,目标是学习一个解码策略(decoding policy),使得在给定上下文(prompt)的情况下,生成的文本序列能够获得更高的奖励(reward)。
价值函数设计:作者提出了一个名为前缀评分器(prefix scorer)的价值函数,用于预测从当前部分解码的响应继续解码时的预期奖励。这个前缀评分器可以在离策略数据上进行训练,从而避免了在线策略学习中的样本效率问题。
推理策略:在推理阶段,作者提出了两种使用前缀评分器的策略。一种是逐个标记(token-wise)采样,另一种是分块(block-wise)采样和重排。这两种策略都可以在不改变训练时的模型结构的情况下,实现对生成过程的有效控制。
多目标优化:作者展示了如何通过调整前缀评分器的权重,实现在多个奖励目标之间的权衡。这使得CD方法可以解决多目标强化学习问题,而无需增加额外的复杂性。
3.2 提示词优化
提示词 (prompt)往往是一段自然语言文本序列,在研究中其还有连续形式,即一个多维向量。提示词用于输入到生成式预训练语言模型并引导其生成结果。经验表明,经验和研究表明,不同提示词输入到生成式预训练语言模型中会导致显著的输出结果差异。下面介绍利用强化学习对提示词进行最优搜索和增强的相关研究。
3.2.1 提示词优化搜索
文本形式的提示词由于其离散性质,其优化非常困难。针对提示词优化搜索的研究中,相关研究可根据提示词的连续或离散而分别划分为软提示 (Soft Prompt, Continuous Prompt)和硬提示 (Hard Prompt, or Discrete Prompt)。其中软提示需要访问语言模型的梯度,而算梯度需要很高的计算成本 (有时梯度甚至并不可用),且软提示的优化结果不具有普适性,即一个模型上优化的提示词无法在别的模型上适用。此外由于软提示本身是多维向量的数学形式,天然难以被人类阅读和理解。针对上述软提示缺点,硬提示作为离散文本形式,以无需访问模型梯度、易于人类理解、普适性高等优点被人们关注和研究。
然而,硬提示由于其离散性质,其优化相比连续性的软提示具有更大的困难。有研究为了解决这一困难,将离散文本提示优化问题建模为强化学习问题4。其目标是在不需要访问预训练语言模型梯度的情况下优化提示词。代理通过策略来逐步选择提示的每个词,并最大化根据输出结果计算的奖励。该研究使用了soft Q-Learning (SQL)方法的on-policy组件。其目标是最大化奖励,即
max
?
θ
R
(
y
L
M
(
z
^
,
x
)
)
,
z
~
∏
t
=
1
T
π
θ
(
z
t
∣
z
<
t
)
\max_{\theta}R(\bold{y}_{LM}(\bold{\hat{z},\bold{x}})), \bold{z} \sim \prod_{t=1}^T \pi_{\bold{\theta}}(z_t | \bold{z}_{<t})
θmax?R(yLM?(z^,x)),z~t=1∏T?πθ?(zt?∣z<t?)
其中
y
L
M
(
z
^
,
x
)
\bold{y}_{LM}(\bold{\hat{z},\bold{x}})
yLM?(z^,x)是预语言模型以
x
\bold{x}
x为输入,以
z
^
\bold{\hat{z}}
z^为提示词时,预语言模型的输出结果。而
R
(
y
)
R(\bold{y})
R(y)是奖励函数,文章中针对不同的下游自然语言处理任务有不同的
R
(
y
)
R(\bold{y})
R(y)。例如对于文本分类 (text classification)任务,文章中的奖励函数为:
R ( x , c ) = λ 1 1 ? C o r r e c t λ 2 C o r r e c t G A P z ( c ) R(\bold{x},c)=\lambda_1^{1-Correct}\lambda_2^{Correct} GAP_{\bold{z}}(c) R(x,c)=λ11?Correct?λ2Correct?GAPz?(c)
对于无监督文本风格迁移,其奖励函数为:
R ( x , y , s ) = C o n t e n t ( x , y ) + S t y l e ( y , s ) R(\bold{x},\bold{y},s)=Content(\bold{x},\bold{y})+Style(\bold{y},s) R(x,y,s)=Content(x,y)+Style(y,s)
此外,为了训练效率和稳定性,该研究还对不同的下游任务特定的奖励函数进行了统一处理,即提出z-score的奖励函数后处理:
z ? s c o r e ( z , x ) = R x ( z ) ? m e a n z ′ ∈ Z ( x ) R x ( Z ′ ) s t d e v z ′ ∈ Z ( x ) R x ( Z ′ ) z-score(\bold{z},\bold{x})=\frac{R_{\bold{x}}(\bold{z})-mean_{z'\in Z(\bold{x})}R_{\bold{x}}(\bold{Z'})}{stdev_{z'\in Z(\bold{x})}R_{\bold{x}}(\bold{Z'})} z?score(z,x)=stdevz′∈Z(x)?Rx?(Z′)Rx?(z)?meanz′∈Z(x)?Rx?(Z′)?
其中
R
x
(
z
)
R_{\bold{x}}(\bold{z})
Rx?(z)是
R
(
y
L
M
)
R(\bold{y}_{LM})
R(yLM?)的缩写,stdev表示样本标准差。
对于带参数
θ
\bold{\theta}
θ的策略网络,作者通过将一个简单的下游任务特定的MLP层插入到冻结参数的用于生成提示词的预训练语言模型中进行实现,更具体地,是插入到LLM的输出头前。这使得该方法具有很好的普适性和的易用性,无需额外构建大型的策略网络。
上述这项研究中的提示词优化范式还可以应用到其他领域,显示出了提示词优化范式的应用广泛性。有研究5将基于策略梯度强化学习的离散提示词优化范式应用到了分子信息学领域,基于生成式预训练Transformer (GPT)模型生成具有预期性质的药物分子的分子式SMILES字符串。不同于前文的离散提示词优化范式,此研究的提示词优化其实是需要访问梯度的。其奖励函数的设计特定于数据集类型,目标函数和策略梯度基于经典策略梯度方法,并无改动。
该研究考虑以一种名为SMILES的字符串作为药物分子的分子式表达,将具有空间结构等复杂形态的药物分子以计算机可以处理的字符串形式表示,进而可以利用语言建模任务在大量药物分子的SMILES字符串上进行预训练,解决了药物分子的分子式生成问题。
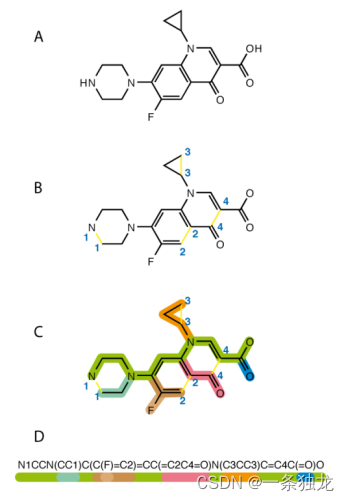
图3-2环丙沙星的 SMILES表示过程(最下方为SMILES字符串)5
而为了生成更符合特定性质,例如抗癌的药物性质的分子式,该研究利用离散提示词优化来控制药物分子式预训练模型的输入提示词,使得生成的分子式更贴合预期性质,如图3-3。
针对生成结果,该研究利用了药物分子的领域相关指标进行评估,包括Validity, Novelty, Diversity, QED, SAS. 分别评估生成分子式的有效性 (要符合基本的理化规则)、新颖性 (和已有的药物至少不能重复)、多样性、类药性 (在一定理化参数空间的化合物成为类药物 ,即drug-like)、分子易合成性 (根据分子结构复杂性计算是否难以在现实合成)。
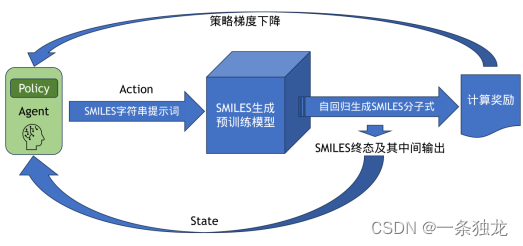
图3-3 基于策略梯度强化学习的药物分子GPT的提示优化与分子式生成过程
3.2.2 经验记忆增强提示词
人类可以利用过往的经验和记忆中进行学习,现有LLMs在部署后,受限于参数更新带来的计算量,从而较难从交互中有效通过参数更新来学习新的经验。为了实现有效地交互式学习,常见的方法是用RL对模型进行微调,但微调需要大量计算,难以部署和长期实现交互式学习。也有方法无需进行微调,而是利用LLMs上下文学习能力直接将历史经验嵌入到提示词。这种方法需要微调才能利用经验,且受LLMs输入长度限制。
基于上述背景,有研究6考虑利用强化学习方法进行提示词记忆增强。该研究提出了强化学习与经验记忆(RLEM)的方法。该方法通过强化学习的过程更新外部持久化的经验记忆,而不是调整LLM的参数。在LLM交互时,利用观测到的状态去检索存储在经验记忆中的若干经验,即一组观察值Ox、动作Ax和对应的Q值估计Qx . LLM再根据本次交互的观测 、上次交互得到的反馈以及检索到的经验决定接下来在环境中的动作,并与环境交互后得到相应奖励反馈。如此,本次交互产生一个新的元组并存储到经验记忆中,有些类似Replay Buffer。
4. 参考文献
Mudgal S, Lee J, Ganapathy H, et al. Controlled Decoding from Language Models[J]. arXiv preprint arXiv:2310.17022, 2023. ?? ??
Christiano P F, Leike J, Brown T, et al. Deep reinforcement learning from human preferences[J]. Advances in neural information processing systems, 2017, 30. ??
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback, 2022[J]. URL https://arxiv. org/abs/2203.02155, 2022, 13. ??
Deng M, Wang J, Hsieh C P, et al. Rlprompt: Optimizing discrete text prompts with reinforcement learning[J]. arXiv preprint arXiv:2205.12548, 2022. ??
Mazuz E, Shtar G, Shapira B, et al. Molecule generation using transformers and policy gradient reinforcement learning[J]. Scientific Reports, 2023, 13(1): 8799. ?? ??
Zhang D, Chen L, Zhang S, et al. Large Language Model Is Semi-Parametric Reinforcement Learning Agent[J]. arXiv preprint arXiv:2306.07929, 2023. ??
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!