迈向通用异常检测和理解:大规模视觉语言模型(GPT-4V)率先推出
| PAPER | CODE |
|---|---|
| https://arxiv.org/pdf/2311.02782.pdf | https://github.com/caoyunkang/GPT4V-for-Generic-Anomaly-Detection |

????????图1 GPT-4V在多模态多任务异常检测中的综合评估 在这项研究中,我们在多模态异常检测的背景下对GPT-4V进行了全面评估。我们考虑了四种模式:图像、视频、点云和时间序列,并探索了九个具体任务,包括工业图像异常检测/定位、点云异常检测、医学图像异常检测/定位、逻辑异常检测、行人异常检测、交通异常检测和时间序列异常检测。我们的评估包括 15 个数据集。
摘要
????????异常检测是跨不同域和数据类型的关键任务。但是,现有的异常检测模型通常是针对特定域和模式设计的。本研究探讨了如何使用强大的视觉语言模型 GPT-4V(ision) 以通用方式处理异常检测任务。我们研究了 GPT-4V 在多模态、多域异常检测任务中的应用,包括图像、视频、点云和时间序列数据,涉及多个应用领域,例如工业、医疗、逻辑、视频、3D 异常检测和定位任务。为了提高 GPT-4V 的性能,我们结合了不同类型的附加提示,例如类信息、人类专业知识和参考图像作为提示。根据我们的实验,GPT-4V 被证明在零/单次异常检测中检测和解释全局和细粒度语义模式方面非常有效。这样可以准确区分正常和异常实例。尽管我们在这项研究中进行了广泛的评估,但仍有未来的评估空间,可以从不同方面进一步挖掘 GPT-4V 的通用异常检测能力。其中包括探索定量指标、扩展评估基准、纳入多轮互动以及纳入人类反馈循环。尽管如此,GPT-4V 在通用异常检测和理解方面表现出可喜的性能,从而为异常检测开辟了一条新途径。所有评估示例(包括图像和文本提示)都将在 GPT4V-for-Generic-Anomaly-Detection https://github.com/caoyunkang/ 提供。
动机和概述
????????异常检测技术已广泛应用于不同的领域,如工业检测[29,98]、医疗对角线[107]、视频监控[84]、欺诈检测[30]以及许多其他识别异常情况至关重要的领域。尽管存在许多用于异常检测的技术[14,3,69,41,38,79,110,16,103],但许多现有方法主要依赖于描述正态数据分布的方法。他们经常忽视高层次的感知,主要将其视为低层次的任务。但是,异常检测的实际应用通常需要对数据有更全面、更高级的理解。要实现这种理解,至少需要三个关键步骤:
- 了解数据类型和类别: 第一步涉及对数据集中存在的数据类型和类别的透彻理解。数据可以采取多种形式,包括图像、视频、点云、时间序列数据等。每种数据类型都可能需要特定的异常检测方法和注意事项。此外,不同的类别可能对正常状态有不同的定义。
- 确定正态的标准:在获得数据类型和类别后,可以进一步推理正态态的标准,这需要对数据有较高的了解。
- 评估数据一致性:最后一步是评估提供的数据是否符合既定的正态性标准。任何偏离这些标准的行为都可以归类为异常。
我们的方法
提示 GPT-4V 进行异常检测
- 任务信息提示:为了有效提示 GPT-4V 进行异常检测,必须提供清晰的任务信息。本研究将提示表述如下:“请确定图像是否包含异常点或异常点。
- 类信息提示:对数据类型和类别的理解至关重要。如果 GPT-4V 可能难以识别数据类,可能会提供显式类信息。例如,“请确定与 {CLS} 相关的图像是否包含异常或缺陷。
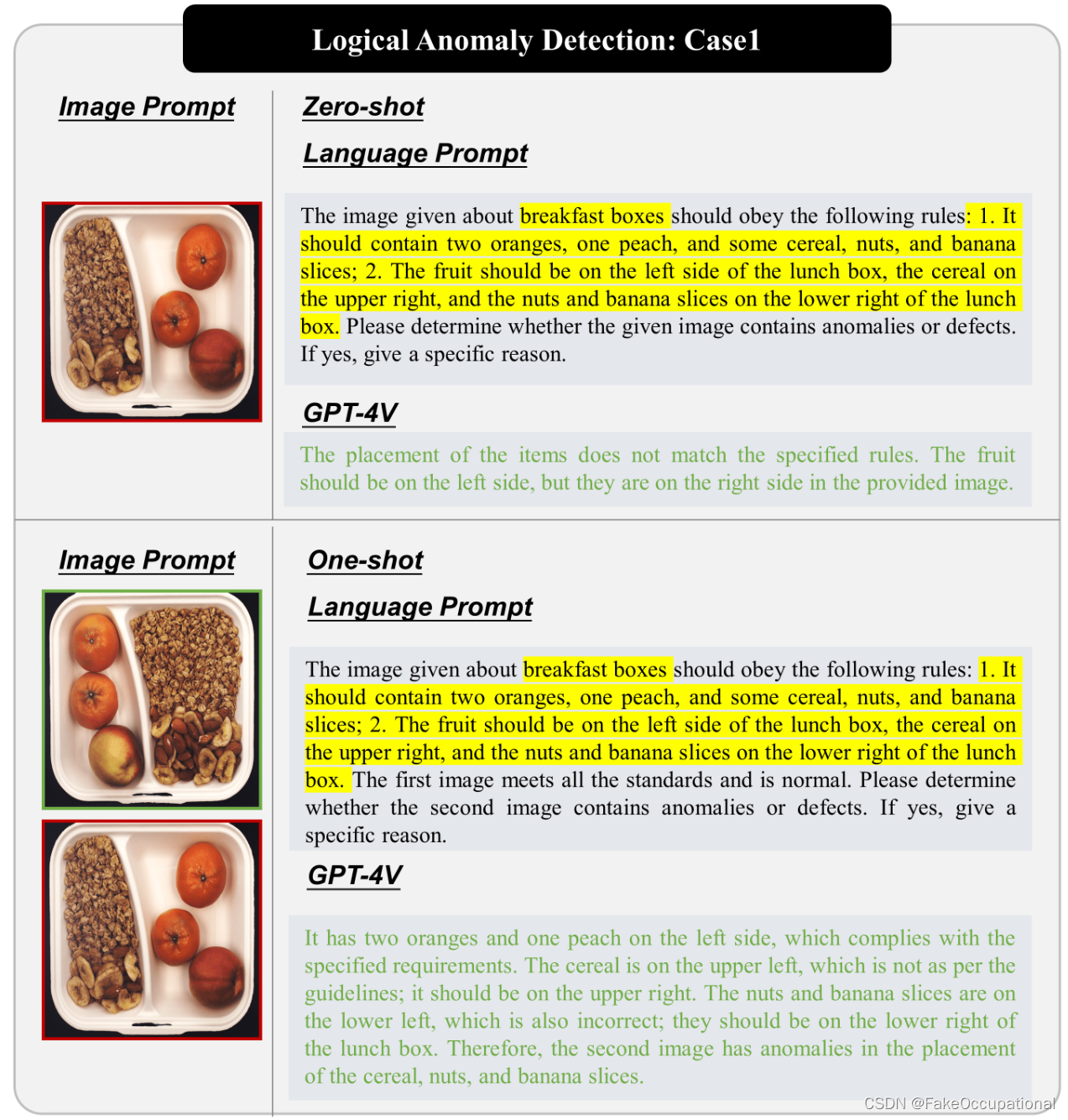
- 正常标准提示:GPT-4V在回答与确定正常标准相关的问题时可能会遇到困难,有时如果没有人类专业知识,甚至无法检查标准。因此,本研究也明确提供了正常标准。例如,MVTec-LOCO [7] 中早餐盒的正常标准可以表示如下:“1.它应该包含两个橙子、一个桃子和一些谷物、坚果和香蕉片;2.水果应该在饭盒的左边,麦片在右上方,坚果和香蕉片在饭盒的右下方。
- 参考图像提示:为确保正常标准和图像之间更好地对齐,在语言提示旁边提供了普通参考图像。例如,“第一张图片是正常的。请确定第二张图像是否包含异常或缺陷。
基于GPT-4V的异常检测评估的局限性
- 定性结果的优势:分析主要依赖于定性评估,缺乏定量指标,无法更客观地评估模型在异常检测方面的性能。纳入量化措施将为评估提供更有力的基础。
- 评估案例的范围:评估仅限于有限的案例或场景范围。这种狭隘的焦点可能无法完全捕捉到实际异常检测任务中遇到的各种挑战。扩大评估案例的范围将更全面地了解模型的功能。
- 单次互动评估:该研究主要集中在单轮对话上。相比之下,正如GPT-4V的上下文学习能力所观察到的那样[101],多轮对话可以激发更深层次的互动。单轮对话方法限制了交互的深度,并可能限制模型的理解力及其在响应异常检测任务方面的有效性。探索多轮交互可以揭示模型性能的更细致入微的观点。
实验
????????本研究进行了广泛的评估,以评估 GPT-4V 在异常检测方面的能力,如图 1 所示。从模态的角度来看,我们评估了图像(第 3、4、6、7、8 节)、点云(第 5 节)、视频(第 9、10 节)和时间序列(第 11 节)。从领域的角度,对工业检查(第3、4、6、5节)、医疗诊断(第7、8节)和视频监控(第9、10节)进行评估。据我们所知,这是第一项调查如此广泛的异常检测模式和领域的研究。
工业图像异常检测
-
不同的提示 [ 101, 56 ] 可能会导致 GPT-4V 的不同响应。我们旨在研究不同信息对提示 GPT-4V 进行工业异常检测的影响。在前面讨论的问题之后,本研究进一步发展了三个提示,a)类别信息:所需检测产品的名称,如“瓶子”和“蜡烛”,b)人类专业知识:正常外观和潜在的异常状态,并用语言表达它们,例如,“通常,给出的图像应该显示干净且结构良好的印刷电路板(PCB),并带有清晰的痕迹, 焊接组件和不同的标签。它可能存在引脚弯曲、冷焊点、元件缺失或标签污迹等缺陷“, c) 参考图像:正常参考图像,以使 GPT-4V 更好地了解正态性。我们建议在零样本设置(仅带有语言提示)或单样本设置(与语言提示一起提供一张参考图像)中评估 GPT-4V。对于每个设置,我们测试了三种不同的变体:a) 幼稚的提示,例如“请确定图像是否包含异常或缺陷”,b) 带有类信息,以及 c) 具有人类专业知识。
-
突出显示给定的类信息以及正常和异常状态描述。绿色、红色和蓝色突出显示 GPT-4V 输出的正确、不正确和附加信息。



工业图像异常定位

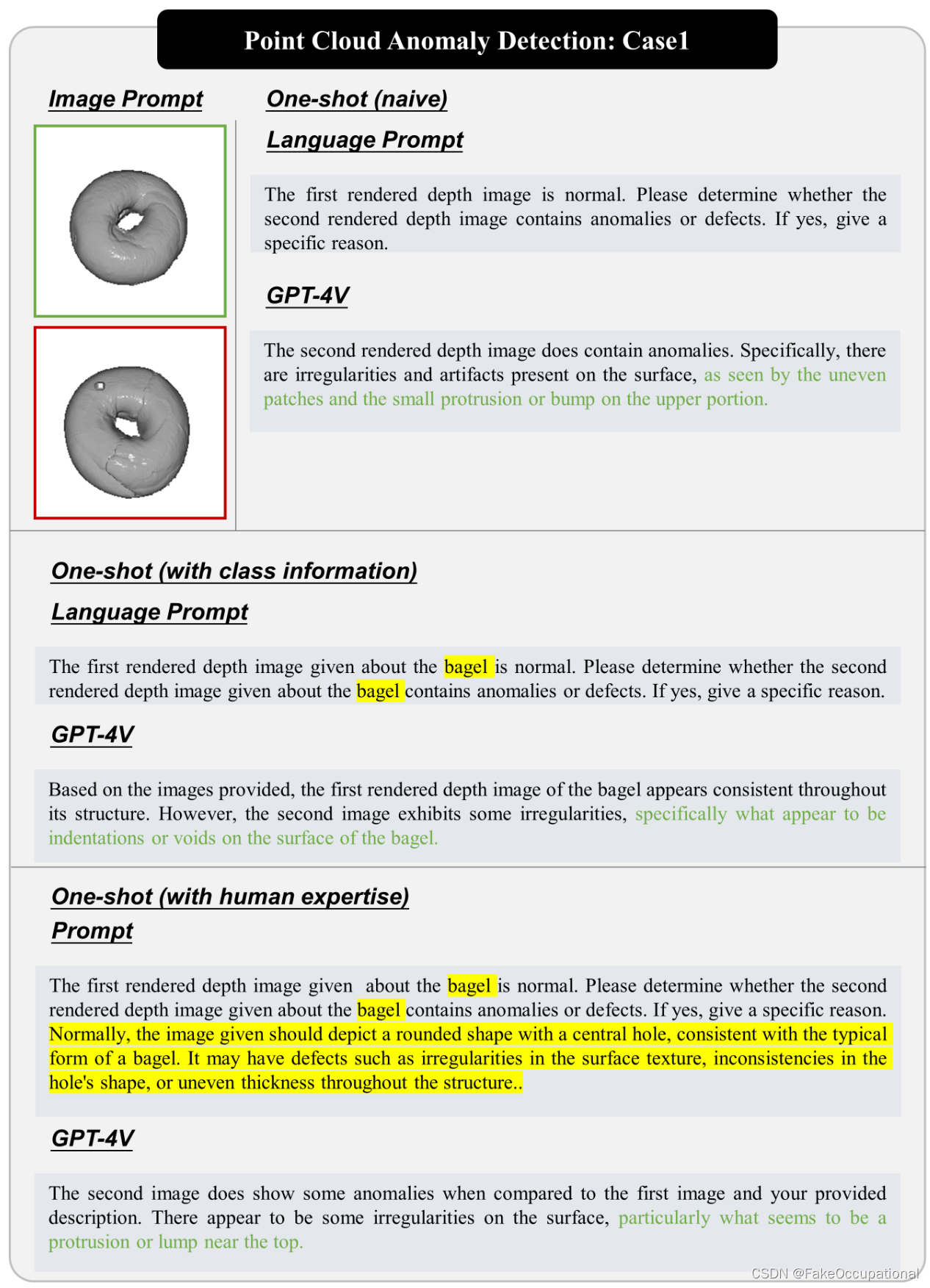
点云异常检测
逻辑异常检测
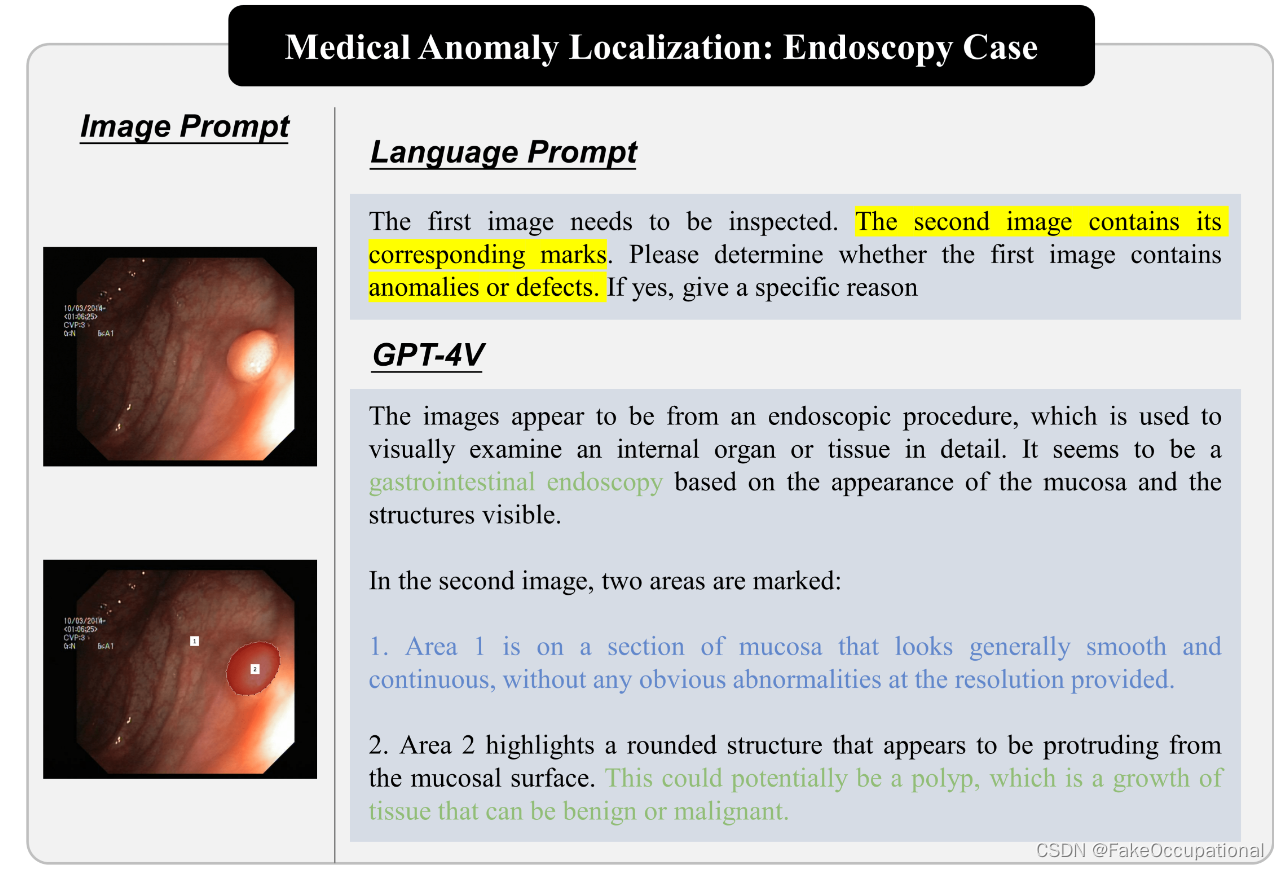
医学图像异常检测
行人异常检测

流量异常检测

时间序列异常检测
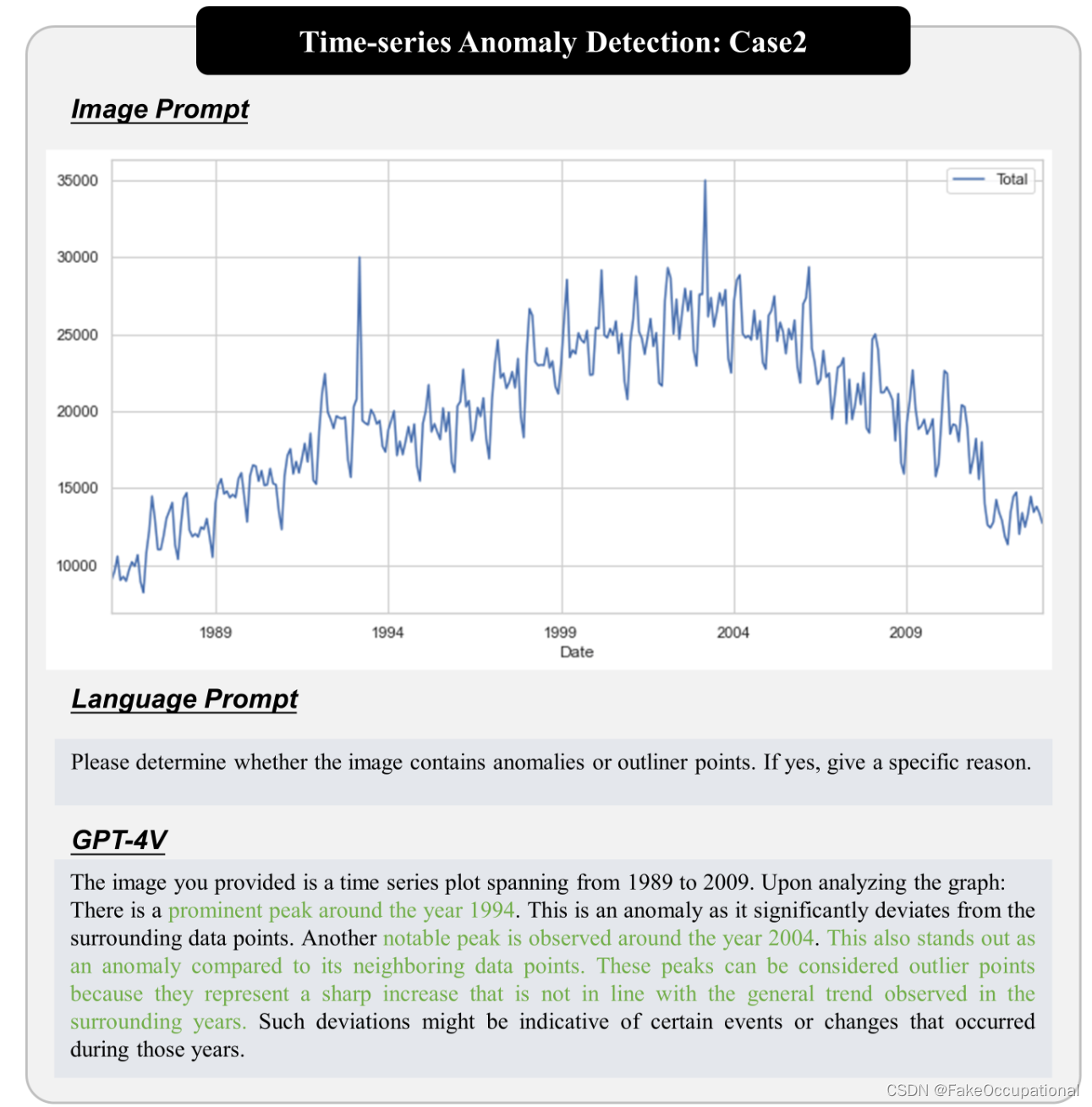
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!