如何选择出最适合的backbone模型?图像分类模型性能大摸底
到2023年图像分类backbone模型已经拓展到了几十个系列,而有的新算法还在采样vgg、resnet做backbone,比如2022年提出的GDIP-YOLO还在用VGG16做IA参数预测,那是在浪费计算资源并限制了模型性能的提升,应该将目光放到现在的最新模型中。为此博主对现行的各种模型的性能进行一个摸底统计,具体范围包括:
PP-HGNet 系列、ResNet 系列、ResNeXt 系列、Res2Net 系列、SENet 系列、DPN 系列、DenseNet 系列、HRNet 系列、Inception 系列、EfficientNet 系列、ResNeXt101_wsl 系列、ResNeSt 系列、RegNet 系列、RepVGG 系列、MixNet 系列、ReXNet 系列、HarDNet 系列、DLA 系列、RedNet 系列、ConvNeXt 系列、VAN 系列、PeleeNet 系列、CSPNet 系列、PP-LCNet & PP-LCNetV2 系列、ViT 系列、DeiT 系列、SwinTransformer 系列、Twins 系列、CSWinTransformer 系列、PVTV2 系列 、LeViT 系列、TNT 系列、MobileViT 系列模型。具体信息参考mageNet1k/model_list.md
以PaddleClas所支持的模型为基准对现行图像分类模型进行进行一个摸底,具体分为移动端模型、桌面端模型、服务器级模型。以在imagenet数据集上的精度为准,精度在80%附近的只考虑移动端模型,精度在85%附近考虑服务器级模型,精度超过85%的都归纳为大型模型。这里不区分是否知识蒸馏、是否在外部数据集上进行预训练。
通过以下分析,发现中低端flop训练与部署环境应该考虑ReXNet与EfficientNet等系列模型,高flop训练与部署环境应该考虑CSWinTransformer、SwinTransformer等模型。同时,通过分析也发现了经典的移动端模型在逐步被一些新结构所颠覆,如ReXNet。

1、移动端模型
移动端在模型这里特指flop个mem都比较小的模型,也就是针对移动端部署对conv架构进行了局部修改的轻量化结构。常见的模型结构有mobilenet系列(v1、v2、v3,Vit)、GhostNet系列、ShuffleNet系列、PP-LCNet系列。具体的入选标准为flop低于2G,模型参数量低于40M。ImageNet acc大于75%的模型,故此将一些性能强悍的特殊模型纳入范围,如EfficientNet系列等模型。
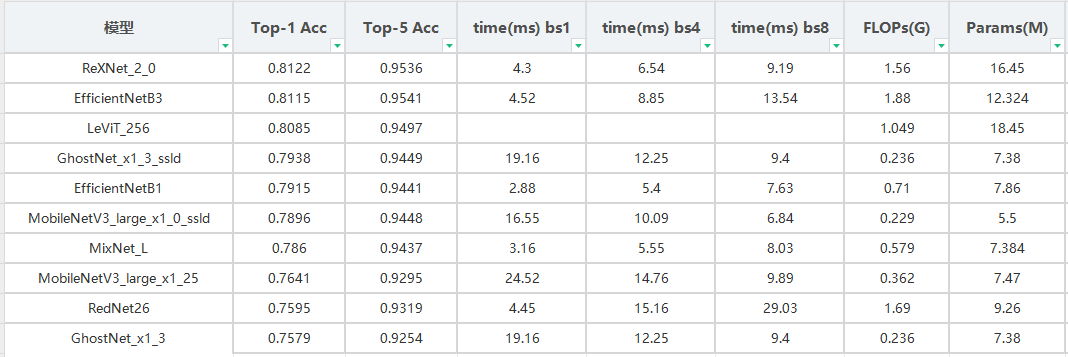
调研结果表示,ReXNet_2_0、EfficientNetB2属于最具性价比的移动端模型。同时通过对比发现,对原有模型进行知识蒸馏相比与其原来的模型基本上都有2~4个点的精度提升,例如:GhostNet_x1_3_ssld提升4个点。以上信息还表明轻量化模型还有ReXNet、LeViT、EfficientNet系列。此外,以上表格没有统计到MobilerVit系列模型,MobilerVit系列模型,在与ReXNet系列相比,MobilerVit系列模型还是不够强

PP-LCNet系列模型是paddle团队提出的模型,其认为推理速度也是极为重要的一环,故将其与其他轻量级网络的性能进行对比。同时,也告诉我们低flop的模型,推理速度未必快。
| Model | Params(M) | FLOPs(M) | Top-1 Acc(%) | Top-5 Acc(%) | Latency(ms) |
|---|---|---|---|---|---|
| MobileNetV2_x0_25 | 1.5 | 34 | 53.21 | 76.52 | 2.47 |
| MobileNetV3_small_x0_35 | 1.7 | 15 | 53.03 | 76.37 | 3.02 |
| ShuffleNetV2_x0_33 | 0.6 | 24 | 53.73 | 77.05 | 4.30 |
| PPLCNet_x0_25 | 1.5 | 18 | 51.86 | 75.65 | 1.74 |
| MobileNetV2_x0_5 | 2.0 | 99 | 65.03 | 85.72 | 2.85 |
| MobileNetV3_large_x0_35 | 2.1 | 41 | 64.32 | 85.46 | 3.68 |
| ShuffleNetV2_x0_5 | 1.4 | 43 | 60.32 | 82.26 | 4.65 |
| PPLCNet_x0_5 | 1.9 | 47 | 63.14 | 84.66 | 2.05 |
| MobileNetV1_x1_0 | 4.3 | 578 | 70.99 | 89.68 | 3.38 |
| MobileNetV2_x1_0 | 3.5 | 327 | 72.15 | 90.65 | 4.26 |
| MobileNetV3_small_x1_25 | 3.6 | 100 | 70.67 | 89.51 | 3.95 |
| PPLCNet_x1_0 | 3.0 | 161 | 71.32 | 90.03 | 2.46 |
| PPLCNetV2_base | 6.6 | 604 | 77.04 | 93.27 | 4.32 |
| PPLCNetV2_base_ssld | 6.6 | 604 | 80.07 | 94.87 | 4.32 |
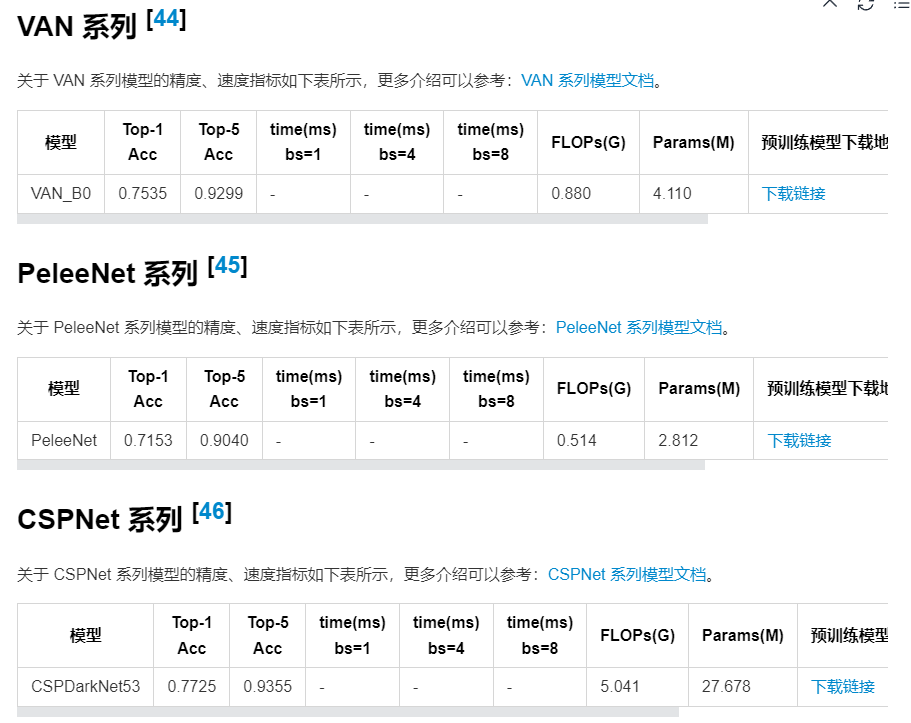
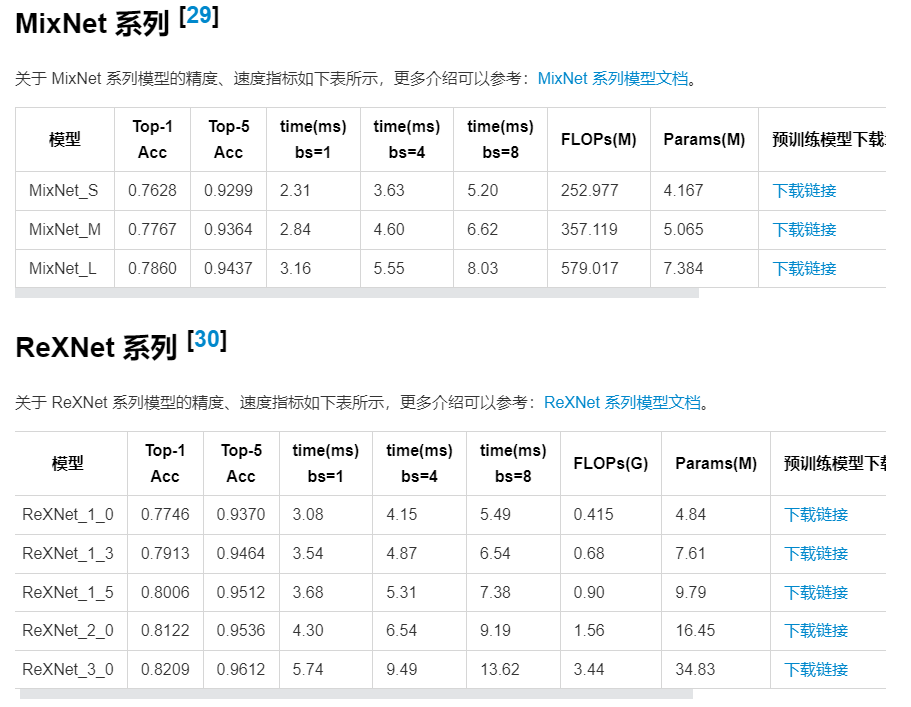
此外还有VAN、PeleeNet、CSPNet模型在设计上也算是轻量化模型,但是效果不如以上的好。
2、桌面级模型
桌面级模型在这里特指flop大于1g且低于4g,参数量低于60M的模型,也就是可以在普通的消费级GPU上进行自由训练的模型。同时,同类型的模型只列出最高精度的模型。
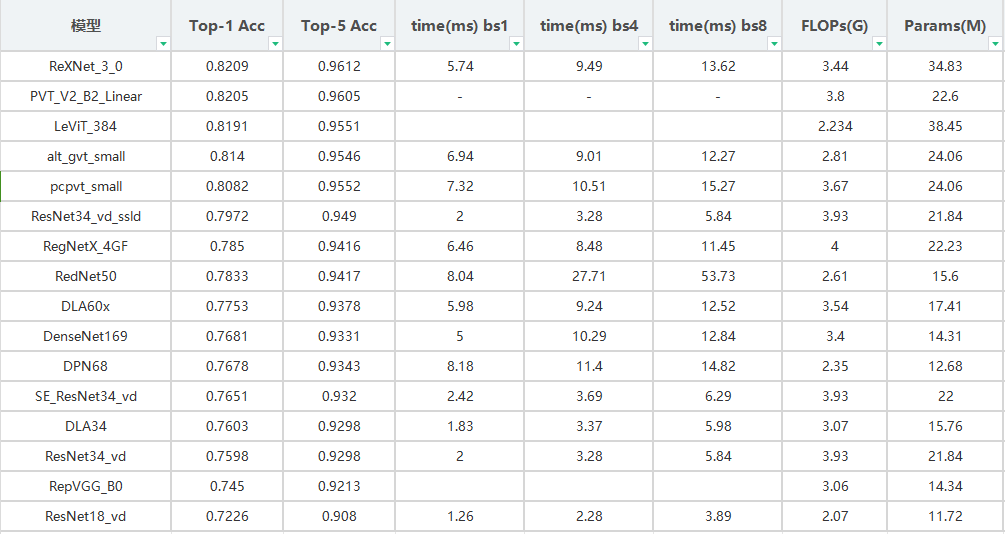
在上表中EfficientNet没有模型入选,这是因为其模型的siez跨度刚好不在范围内。在上表中,最佳模型任然是ReXNet

3、服务器级模型
这里为flop高与参数量正常的模型,只统计在ImageNet精度高于80%(如vgg、resnet等模型精度不达标不在此表中),Flop大于4的模型。同类型的模型,除非top1 精度大于85%,否则每类模型只保留最高精度模型。
从下图中可以看出,最具性价比的模型是CSWinTransformer_large_224与PVT_V2_B5,其中LeViT_384为乱入的模型。使用这类模型进行训练,batchsize和image size都不能设置的太大。
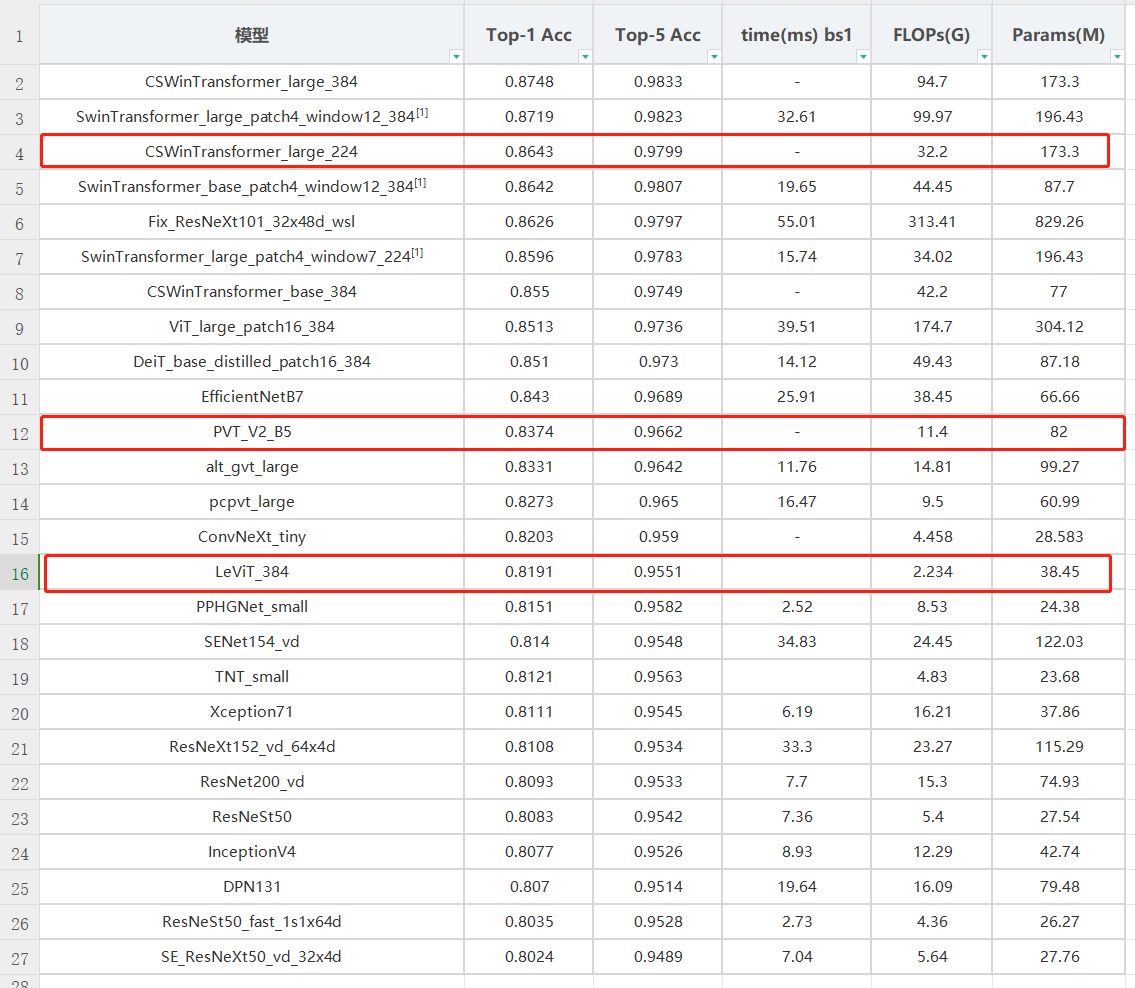
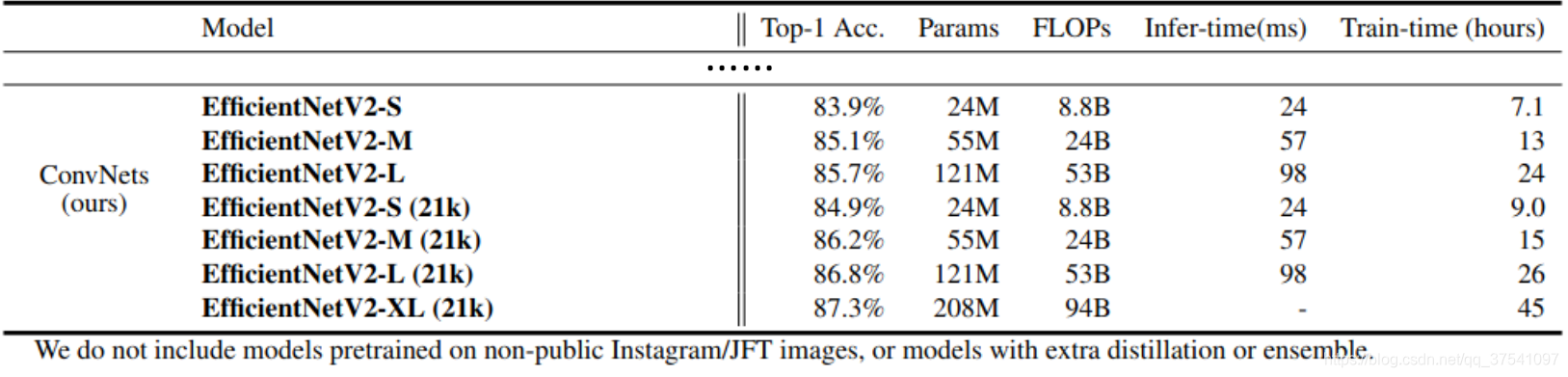
在PaddleClas中没有EfficientNetV2,在与上表中相比,EfficientNetV2-M在acc 85%的档次也是非常具备性价比的模型。
针对一些模型,PaddleClas提供了蒸馏后的权重,这里给出其精度信息,可以发现这类模型虽然精度高于80%,但是并不比前面未蒸馏过的模型占据优势。

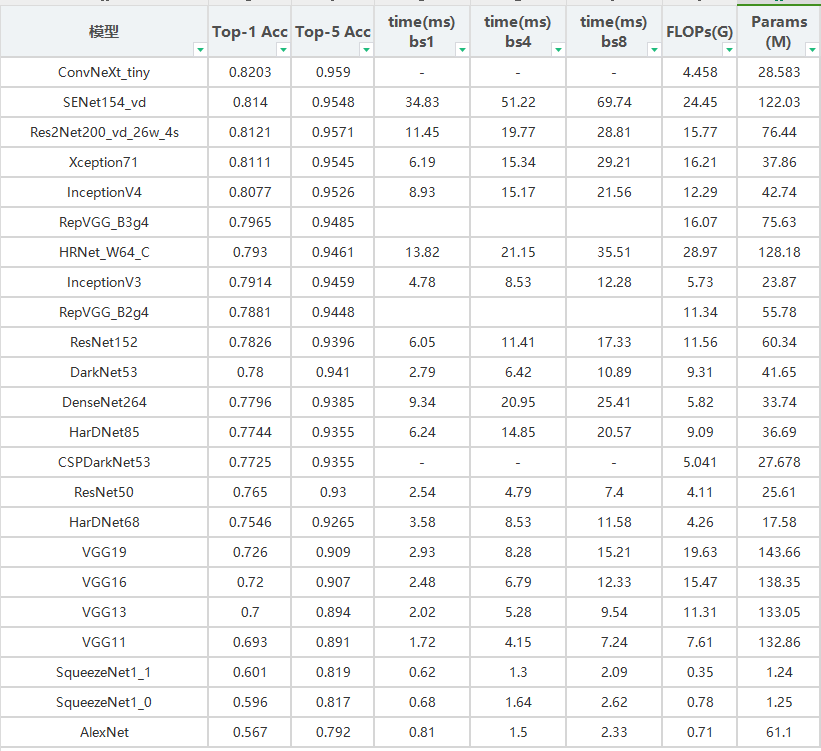
4、常见模型
在上述统计中,如vgg、resnet、densenet、inception、cspdarknet、repvgg等经典模型没有上榜,这里进行一个补充。从以上统计中,也可以发现经典的模型范式已经跟不上新技术的发展了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!