数据库面试题
数据库面试题
Mysql
Q:数据库索引有哪些?有什么作用以及优缺点?
普通索引
alter table table_name add index index_name (column)
MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
唯一索引
alter table table_name add unique (column)
索引列中的值必须是唯一的,但是允许为空值。
主键索引
alter table table_name add primary key (column)
是一种特殊的唯一索引,不允许有空值。
全文索引
alter table table_name add fulltext (column)
只能在char,varchar,text类型字段上使用全文索引。在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行。
索引加快数据库的检索速度
索引降低了插入、删除、修改等维护任务的速度
唯一索引可以确保每一行数据的唯一性
Q:什么是存储过程?有哪些优缺点?
存储过程是一个预编译的代码块,执行效率比较高
一个存储过程替代大量T_SQL语句 ,可以降低网络通信量,提高通信速率
可以一定程度上确保数据安全
Q:什么是事务?
事务(Transaction)是并发控制的基本单位。它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
它具有ACID四个特性,原子性,一致性,隔离性,持久性
原子性是指一个事务是一个不可分割的工作单位,其中的操作要么都做,要么全部做。
隔离性追求的是并发情形下事务之间不会相互干扰。
持久性事务一旦提交,他对数据库的改变就是永久的。
一致性依赖于应用层,也就是依赖于开发者.这里的一致性是指系统从一个正确的状态,迁移到另一个正确的状态.
Q:说一说三大范式。
属性不可分、主属性依赖、不传递函数依赖。
第一范式:关系模式R的所有属性都不能再分解为更基本的数据单位
第二范式: 满足第一范式,并且R的所有非主属性都完全依赖于R的任一候选关键属性
第三范式:满足第二范式,数据表中不存在非关键字段对任一候选关键字段的传递函数依赖。满足第三范式的数据库表应该不存在如下依赖关系: 关键字段 → 非关键字段 x → 非关键字段y。
Q: drop、truncate与delete的区别?
drop> truncate >delete
drop删除表结构
drop,truncate是ddl, 操作立即生效, 不走事务.
delete语句是dml,走事务
Drop table Tablename
Truncate table Tablename
Delete from Tablename where xxx
Q: 数据库的乐观锁和悲观锁是什么?
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。(事务)
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。(版本号、时间戳)
乐观锁适合读操作多的场景,悲观锁适合写操作多的场景。
Q: 什么是视图?以及视图的使用场景有哪些?
视图是一种虚拟的表,具有和物理表相同的功能。对视图的修改不影响基本表。视图面向对象。视图可以多表联合提供给用户查询。
Q:视图命令
创建:
CREATE VIEW table_Films AS
SELECT MemberId,FirstName, LastName FROM MemberDetails
WHERE MemberId IN
(SELECT MemberId FROM FavCategory WHERE CategoryId IN
(SELECT CategoryId FROM Category WHERE Category = ‘Horror’ ))
查看:
SELECT *
From table_Films
删除:
DROP VIEW table_Films
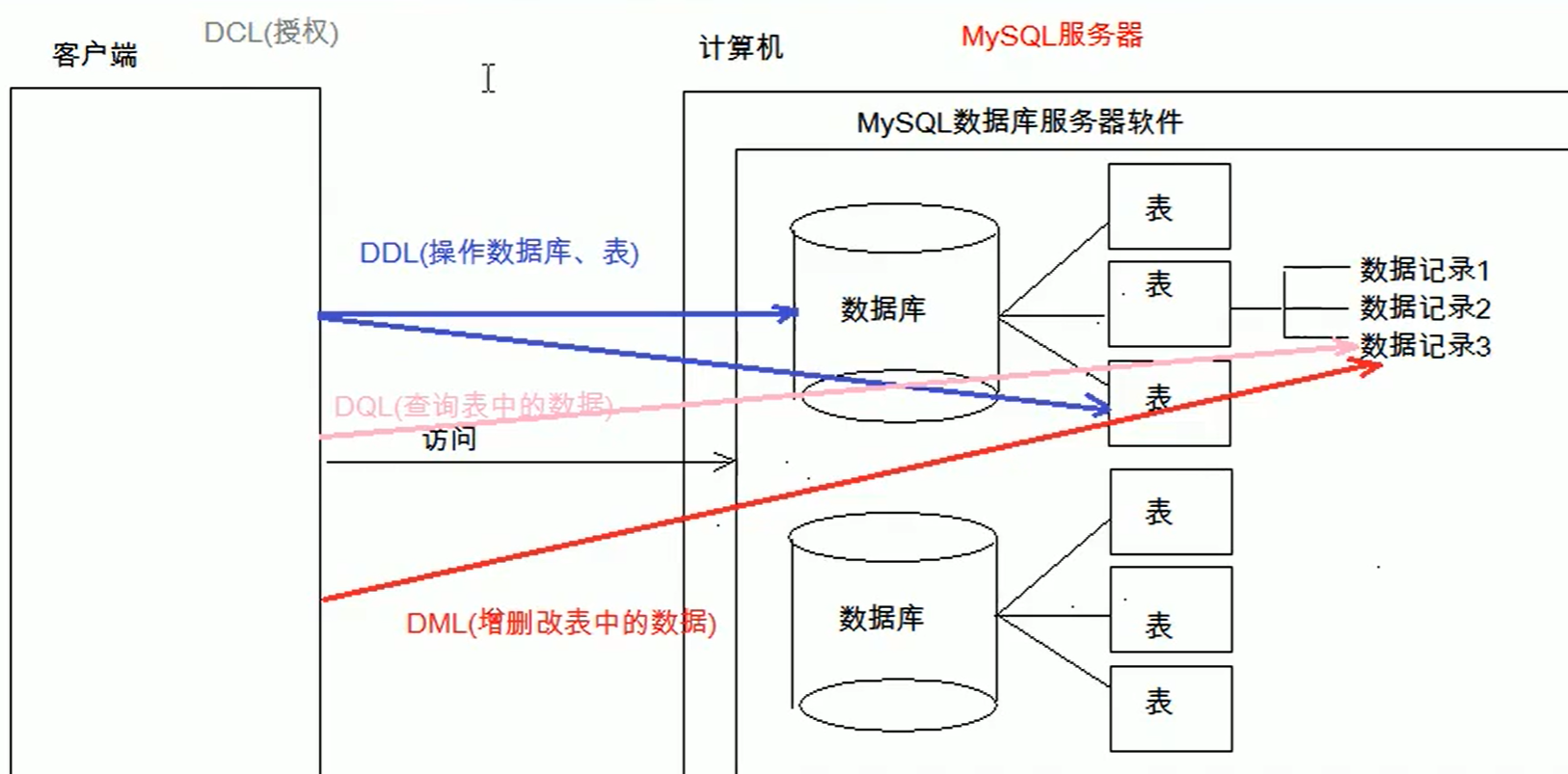
Q: DDL、DML、DQL、DCL之间的区别?

用户不能在包括GROUP BY子句的视图上执行任何DML操作
ps:
Q: 什么是级联?
级联删除:当我们没有对键加级联删除的时候,删除主键表中的数据(外键表有引用的数据)时,会报错,不能删除。但如果新建外键的时候设置了级联删除,那么当我们删除主键表的数据时,数据库就会自动帮我们把相关联的外键表数据删除掉。
级联更新:我们修改主键表中和外键表进行关联的字段,如果我们没有设置级联更新,那么会提示不能更新。但是如果设置了级联更新,那么外键表的数据会自动帮我们更新。
如果指定参照完整性的删除规则为“级联”,则当删除父表中的记录时,会自动删除子表中所有相关记录。
Q:事务?
事务具有以下4个属性,简称为ACID。
原子性(Atomicity) :事务是一个不可分割的工作单位,事务中的操作要么都成功,要么都失败;
一致性(Consistency) :事务前后,数据库的完整性约束没有被破坏;
如A给B转账,不论转账的事务操作是否成功,其两者的存款总额不变。
隔离性(Isolation) :多个线程并发访问数据库时,数据库为每一个线程开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离;
持久性(Durability) :一个事务一旦被提交,它对数据库中数据的改变就是永久性的,即使数据库发生故障也不应该对其有任何影响。
操作(单独开启):
start transaction; 开启事务
COMMIT;提交事务
ROLLBACK; 事务回滚
**脏读:**事务A、B交替执行,事务A读取到事务B未提交的数据。
**不可重复读:**在事务A范围内,两个相同的查询,读取同一条记录,却返回了不同的数据。
幻读:事务A查询一个范围的结果集,另一个并发事务B往这个范围中插入/删除了数据,并静悄悄地提交,然后事务A再次查询相同的范围,两次读取得到的结果集不一样了。
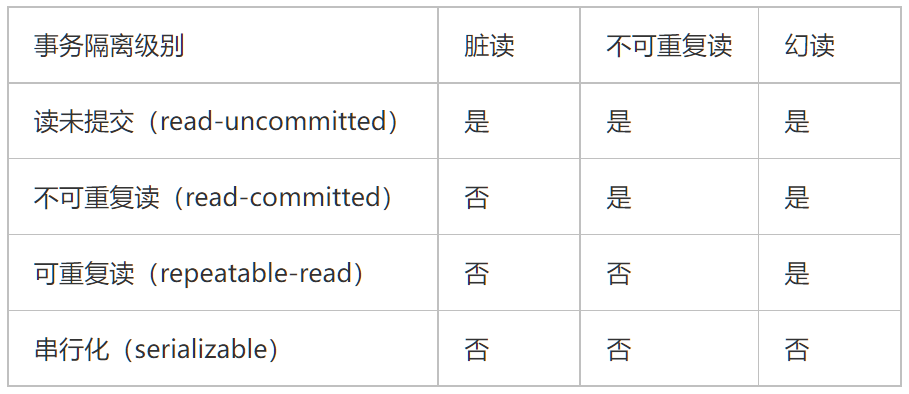
mysql默认的事务隔离级别为可重复读
MVCC是一种多版本并发控制机制,用于实现隔离。MVCC是通过保存数据在某个时间点的快照来实现该机制。
Q:sql多表查询优化
建立索引。把数据量最大的表放到最外层,建立子表的查询路径。
Q: NOSQL优点
1、模糊查询下,nosql可以提供倒排索引来实现快速搜索,即将记录中的某些列做分词,记录和id的映射关系。
关系型数据库只有后模糊匹配才能使用到索引。
Redis
概要:
redis主从模式,集群模式,持久化,哨兵模式,redis数据类型
Redis 是一个基于内存的高性能key-value数据库。
参考链接:https://zhuanlan.zhihu.com/p/93515595
1、Redis的数据结构有哪些,以及实现场景?
todo
Redis的数据结构有五种:
**string 😗*存储简单的 key-value 类型,value 不仅可以是 String,也可以是数字。
用得比较多的是string的自减/自增操作。原子性。
Hash : 不能重复集合,分为大key、小key、小key的value.
**List 😗*有序集合,插入list中的值只需key。双端链表实现。应用:消息队列.
**Set 😗*无序不能重复的集合。Redis 集合提供了求交集、并集、差集等操作。
应用:统计商品在一分钟内被多少不同用户浏览过。
Redis 其他功能使用场景:
订阅-发布系统:
你可以设定对某一个 key 值进行消息发布及消息订阅,当一个 key 值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。
事务:Redis提供非严格的 ACID 的事务,只提供了基本的命令打包执行的功能。
2、说说你对Redis的了解
Redis是一款基于键值对的NoSQL数据库,Redis中拥有string(字符串),hash(哈希)、list(列表)、set(集合)等多种数据结构,redis将数据写进内存的性能很快,不仅如此,如遇到系统崩溃,内存中的数据不会丢失;redis访问速度快、支持的数据类型丰富,很适合用来储存热点数据、 而且适用业务广。如:分布式锁,消息队列
3、说说缓存穿透、缓存击穿、缓存雪崩的区别
一打一、多打一、多打多
缓存穿透是指大量请求访问一个本身不存在的数据(如id=-1)。
缓存击穿是指一份数据缓存时间到期,大量的访问请求并发访问数据库。
缓存雪崩指的是缓存中数据大批量到过期时间,查询直接访问到数据库。
4、Redis集群模式
主从复制
复制是高可用Redis的基础,哨兵和集群都是在复制基础上实现高可用的。
主从刚连接时全量同步,后增量同步。slave在任何时候都可以发起全量同步。首先尝试进行增量同步,如不成功则全量同步。
优点:避免单点故障,读写分离,读操作的负载均衡,简单的故障恢复。
缺点:无法自动故障恢复;写操作无法负载均衡;存储能力受到单机的限制。
哨兵模式
复制的基础上,哨兵实现了自动化的故障恢复。
缺点:写操作无法负载均衡;存储能力受到单机的限制。
哨兵模式的作用:
通过发送命令,让 Redis 服务器返回监控其运行状态,包括主服务器和从服务器;
当哨兵监测到 master 宕机,会自动将 slave 切换成 master ,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机;
我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
故障切换的过程:
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行 failover 操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
Cluster集群模式
集群模式,实现了 Redis 的分布式存储。
本身没有使用一致性hash算法,而是使用slots插槽。
slots:
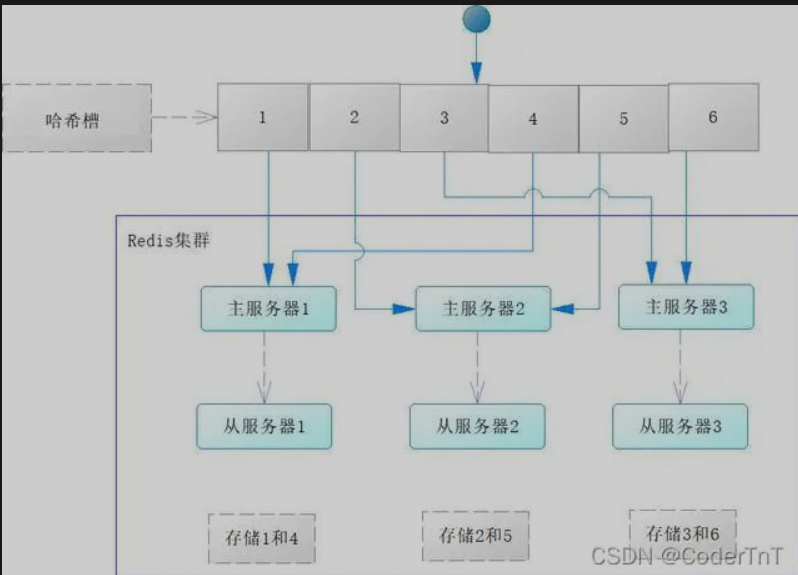
图中有整数1~6的图形为一个哈希槽,哈希槽中的数字决定了数据将发送到哪台主Redis服务器进行存储。每台主服务器会配置1台到多台从Redis服务器,从服务器会同步主服务器的数据。
Redis 集群有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽。这种结构很容易添加或者删除节点。
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是 cluster,可以理解为是一个集群管理的插件。
集群的特点:
所有的 redis 节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的 fail 是通过集群中超过半数的节点检测失效时才生效。
客户端与 Redis 节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
5、Redis过期键删除策略
定时删除
在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来立即执行对键的删除操作。
优点:对内存非常友好
缺点:对CPU时间非常不友好
惰性删除
放任过期键不管,每次从键空间中获取键时,检查该键是否过期,如果过期,就删除该键,如果没有过期,就返回该键。
优点:对CPU时间非常友好
缺点:对内存非常不友好
定期删除
每隔一段时间,程序对数据库进行一次检查,删除里面的过期键,至于要删除哪些数据库的哪些过期键,则由算法决定。
定期删除策略是定时删除策略和惰性删除策略的一种整合折中方案。
6、Redis持久化机制
Redis 的数据全部在内存里,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证 Redis 的数据不会因为故障而丢失,这种机制就是 Redis 的持久化机制,Redis 的持久化机制有两种:
RDB快照
RDB快照是某个时间点的一次全量数据备份,是二进制文件,在存储上非常紧凑,一般是靠bgsave命令来生成rdb快照。
save命令:会阻塞当前服务器,直到RDB完成为止,如果数据量大的话会造成长时间的阻塞,线上环境一般禁止使用。
bgsave命令:就是background save,执行bgsave命令时Redis主进程会fork一个子进程来完成RDB的过程,完成后自动结束(COW)。Redis主进程阻塞时间只有fork阶段的那一下。相对于save,阻塞时间很短。
优点:
1、RDB文件小,恢复速度快,非常适合定时备份,用于灾难恢复.
缺点:
1、RDB无法做到实时持久化,若在两次bgsave间宕机,则会丢失区间(分钟级)的增量数据,不适用于实时性要求较高的场景
2、RDB的cow机制中,fork子进程属于重量级操作,并且会阻塞redis主进程
3、存在老版本的Redis不兼容新版本RDB格式文件的问题
AOF日志
AOF日志是持续增量的备份,是基于写命令存储的可读的文本文件。AOF日志会在持续运行中持续增大,由于Redis重启过程需要优先加载AOF日志进行指令重放以恢复数据,恢复时间会无比漫长。所以需要定期进行AOF重写,对AOF日志进行瘦身。目前AOF是Redis持久化的主流方式。
优点:
1、AOF只是追加写日志文件,对服务器性能影响较小,速度比RDB要快,消耗的内存较少
缺点:
1、AOF方式生成的日志文件太大,需要不断AOF重写,进行瘦身。即使瘦身,由于文件是文本文件,文件体积较大(相比于RDB的二进制文件)。
2、AOF重演命令式的恢复数据,速度显然比RDB要慢。
Redis 4.0 混合持久化
将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!