【python高级用法】进程
一个简单的进程
# -*- coding: utf-8 -*-
import multiprocessing
def foo(i):
print ('called function in process: %s' %i)
return
if __name__ == '__main__':
Process_jobs = []
for i in range(5):
p = multiprocessing.Process(target=foo, args=(i,))
Process_jobs.append(p)
p.start()
p.join()按照本节前面提到的步骤,创建进程对象首先需要引入multiprocessing模块:
import multiprocessing然后,我们在主程序中创建进程对象:
p = multiprocessing.Process(target=foo, args=(i,))最后,我们调用?start()?方法启动:
p.start()进程对象的时候需要分配一个函数,作为进程的执行任务,本例中,这个函数是?foo()?。我们可以用元组的形式给函数传递一些参数。最后,使用进程对象调用?join()?方法。
如果没有?join()?,主进程退出之后子进程会留在idle中,你必须手动杀死它们。
?进程命名
# 命名一个进程
import multiprocessing
import time
def foo():
name = multiprocessing.current_process().name
print("Starting %s \n" % name)
time.sleep(3)
print("Exiting %s \n" % name)
if __name__ == '__main__':
process_with_name = multiprocessing.Process(name='foo_process', target=foo)
process_with_name.daemon = True # 注意原代码有这一行,但是译者发现删掉这一行才能得到正确输出
process_with_default_name = multiprocessing.Process(target=foo)
process_with_name.start()
process_with_default_name.start()这个过程和命名线程很像。命名进程需要为进程对象提供?name?参数:
process_with_name = multiprocessing.Process(name='foo_process', target=foo)
在本例子中,进程的名字就是?foo_function?。如果子进程需要知道父进程的名字,可以使用以下声明:
name = multiprocessing.current_process().name
然后就能看见父进程的名字。
?后台使用进程
?如果需要处理比较巨大的任务,又不需要人为干预,将其作为后台进程执行是个非常常用的编程模型。此进程又可以和其他进程并发执行。通过Python的multiprocessing模块的后台进程选项,我们可以让进程在后台运行。
import multiprocessing
import time
def foo():
name = multiprocessing.current_process().name
print("Starting %s " % name)
time.sleep(3)
print("Exiting %s " % name)
if __name__ == '__main__':
background_process = multiprocessing.Process(name='background_process', target=foo)
background_process.daemon = True
NO_background_process = multiprocessing.Process(name='NO_background_process', target=foo)
NO_background_process.daemon = False
background_process.start()
NO_background_process.start()?
为了在后台运行进程,我们设置?daemon?参数为?True
background_process.daemon = True在非后台运行的进程会看到一个输出,后台运行的没有输出,后台运行进程在主进程结束之后会自动结束。
?进程杀死
我们可以使用?terminate()?方法立即杀死一个进程。另外,我们可以使用?is_alive()?方法来判断一个进程是否还存活。
我们创建了一个线程,然后用?is_alive()?方法监控它的声明周期。然后通过调用?terminate()?方法结束进程。
最后,我们通过读进程的?ExitCode?状态码(status code)验证进程已经结束,?ExitCode?可能的值如下:
- == 0: 没有错误正常退出
- > 0: 进程有错误,并以此状态码退出
- < 0: 进程被?
-1?*?的信号杀死并以此作为 ExitCode 退出
在我们的例子中,输出的?ExitCode?是?-15?。负数表示子进程被数字为15的信号杀死。
自定义一个进程子类?
?
实现一个自定义的进程子类,需要以下三步:
- 定义?
Process?的子类 - 覆盖?
__init__(self?[,args])?方法来添加额外的参数 - 覆盖?
run(self,?[.args])?方法来实现?Process?启动的时候执行的任务
创建?Porcess?子类之后,你可以创建它的实例并通过?start()?方法启动它,启动之后会运行?run()?方法。
# -*- coding: utf-8 -*-
# 自定义子类进程
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' % self.name)
return
if __name__ == '__main__':
jobs = []
for i in range(5):
p = MyProcess()
jobs.append(p)
p.start()
p.join()?
每一个继承了?Process?并重写了?run()?方法的子类都代表一个进程。此方法是进程的入口:
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' % self.name)
return在主程序中,我们创建了一些?MyProcess()?的子类。当?start()?方法被调用的时候进程开始执行:
p = MyProcess()
p.start()join()?命令可以让主进程等待其他进程结束最后退出。
进程间交换对象
并行应用常常需要在进程之间交换数据。Multiprocessing库有两个Communication Channel可以交换对象:队列(queue)和管道(pipe)。
我们可以通过队列数据结构来共享对象。
Queue?返回一个进程共享的队列,是线程安全的,也是进程安全的。任何可序列化的对象(Python通过?pickable?模块序列化对象)都可以通过它进行交换。
?
import multiprocessing
import random
import time
class Producer(multiprocessing.Process):
def __init__(self, queue):
multiprocessing.Process.__init__(self)
self.queue = queue
def run(self):
for i in range(10):
item = random.randint(0, 256)
self.queue.put(item)
print("Process Producer : item %d appended to queue %s" % (item, self.name))
time.sleep(1)
print("The size of queue is %s" % self.queue.qsize())
class Consumer(multiprocessing.Process):
def __init__(self, queue):
multiprocessing.Process.__init__(self)
self.queue = queue
def run(self):
while True:
if self.queue.empty():
print("the queue is empty")
break
else:
time.sleep(2)
item = self.queue.get()
print('Process Consumer : item %d popped from by %s \n' % (item, self.name))
time.sleep(1)
if __name__ == '__main__':
queue = multiprocessing.Queue()
process_producer = Producer(queue)
process_consumer = Consumer(queue)
process_producer.start()
process_consumer.start()
process_producer.join()
process_consumer.join()我们使用?multiprocessing?类在主程序中创建了?Queue?的实例:
if __name__ == '__main__':
queue = multiprocessing.Queue()然后我们创建了两个进程,生产者和消费者,?Queue?对象作为一个属性。
process_producer = Producer(queue)
process_consumer = Consumer(queue)生产者类负责使用?put()?方法放入10个item:
for i in range(10):
item = random.randint(0, 256)
self.queue.put(item)消费者进程负责使用?get()?方法从队列中移除item,并且确认队列是否为空,如果为空,就执行?break?跳出?while?循环:
def run(self):
while True:
if self.queue.empty():
print("the queue is empty")
break
else:
time.sleep(2)
item = self.queue.get()
print('Process Consumer : item %d popped from by %s \n' % (item, self.name))
time.sleep(1)?
队列还有一个?JoinableQueue?子类,它有以下两个额外的方法:
task_done(): 此方法意味着之前入队的一个任务已经完成,比如,?get()?方法从队列取回item之后调用。所以此方法只能被队列的消费者调用。join(): 此方法将进程阻塞,直到队列中的item全部被取出并执行。
(?Microndgt?注:因为使用队列进行通信是一个单向的,不确定的过程,所以你不知道什么时候队列的元素被取出来了,所以使用task_done来表示队列里的一个任务已经完成。
这个方法一般和join一起使用,当队列的所有任务都处理之后,也就是说put到队列的每个任务都调用了task_done方法后,join才会完成阻塞。)
?进程间同步
?
多个进程可以协同工作来完成一项任务。通常需要共享数据。所以在多进程之间保持数据的一致性就很重要了。需要共享数据协同的进程必须以适当的策略来读写数据。相关的同步原语和线程的库很类似。
进程的同步原语如下:
- Lock: 这个对象可以有两种装填:锁住的(locked)和没锁住的(unlocked)。一个Lock对象有两个方法,?
acquire()?和?release()?,来控制共享数据的读写权限。 - Event: 实现了进程间的简单通讯,一个进程发事件的信号,另一个进程等待事件的信号。?
Event?对象有两个方法,?set()?和?clear()?,来管理自己内部的变量。 - Condition: 此对象用来同步部分工作流程,在并行的进程中,有两个基本的方法:?
wait()?用来等待进程,?notify_all()?用来通知所有等待此条件的进程。 - Semaphore: 用来共享资源,例如,支持固定数量的共享连接。
- Rlock: 递归锁对象。其用途和方法同?
Threading?模块一样。 - Barrier: 将程序分成几个阶段,适用于有些进程必须在某些特定进程之后执行。处于障碍(Barrier)之后的代码不能同处于障碍之前的代码并行。
下面的代码展示了如何使用?barrier()?函数来同步两个进程。我们有4个进程,进程1和进程2由barrier语句管理,进程3和进程4没有同步策略。
?
import multiprocessing
from multiprocessing import Barrier, Lock, Process
from time import time
from datetime import datetime
def test_with_barrier(synchronizer, serializer):
name = multiprocessing.current_process().name
synchronizer.wait()
now = time()
with serializer:
print("process %s ----> %s" % (name, datetime.fromtimestamp(now)))
def test_without_barrier():
name = multiprocessing.current_process().name
now = time()
print("process %s ----> %s" % (name, datetime.fromtimestamp(now)))
if __name__ == '__main__':
synchronizer = Barrier(2)
serializer = Lock()
Process(name='p1 - test_with_barrier', target=test_with_barrier, args=(synchronizer,serializer)).start()
Process(name='p2 - test_with_barrier', target=test_with_barrier, args=(synchronizer,serializer)).start()
Process(name='p3 - test_without_barrier', target=test_without_barrier).start()
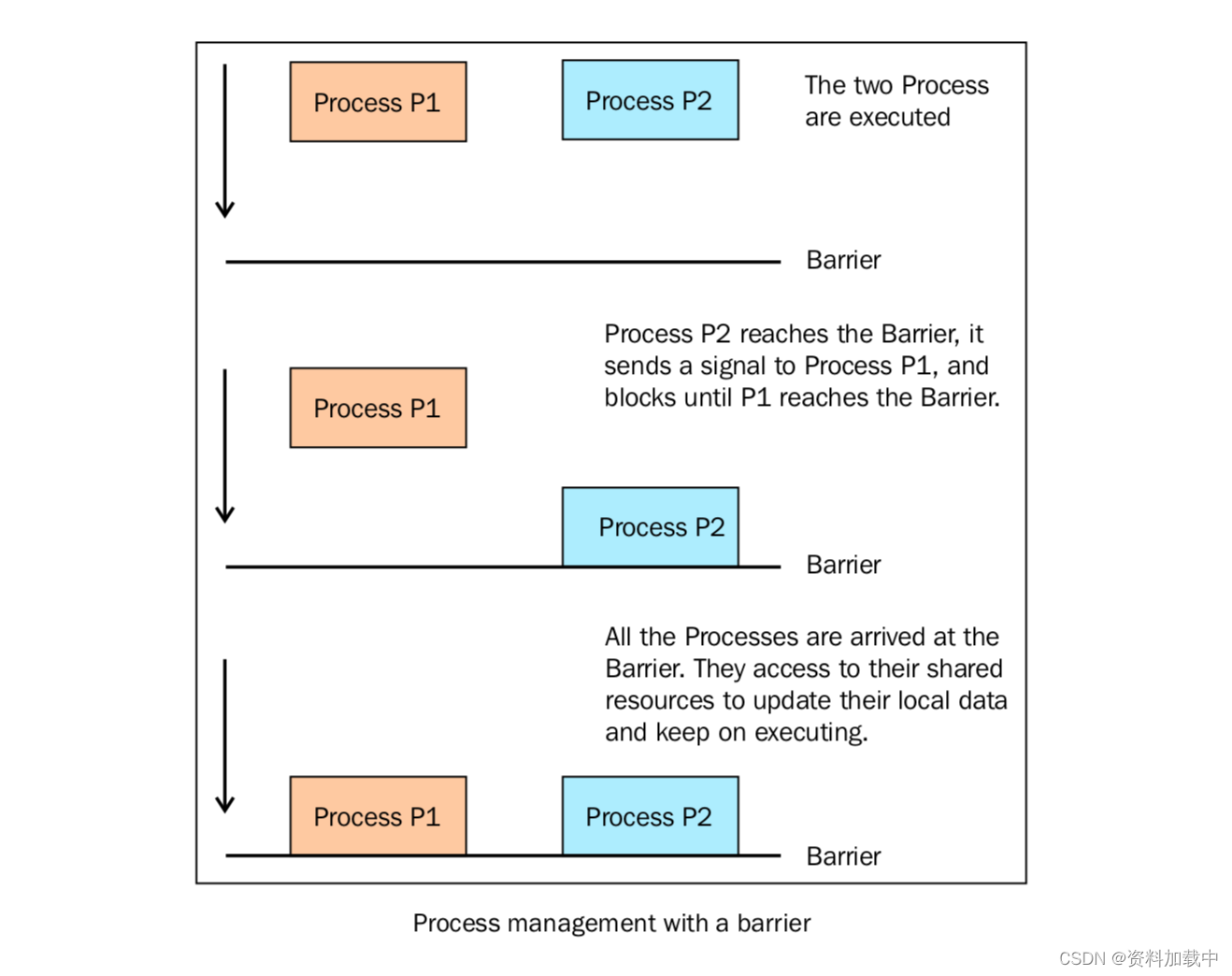
Process(name='p4 - test_without_barrier', target=test_without_barrier).start()?下面这幅图表示了barrier如何同步两个进程:
?进程池
?
多进程库提供了?Pool?类来实现简单的多进程任务。?Pool?类有以下方法:
apply(): 直到得到结果之前一直阻塞。apply_async(): 这是?apply()?方法的一个变体,返回的是一个result对象。这是一个异步的操作,在所有的子类执行之前不会锁住主进程。map(): 这是内置的?map()?函数的并行版本。在得到结果之前一直阻塞,此方法将可迭代的数据的每一个元素作为进程池的一个任务来执行。map_async(): 这是?map()?方法的一个变体,返回一个result对象。如果指定了回调函数,回调函数应该是callable的,并且只接受一个参数。当result准备好时会自动调用回调函数(除非调用失败)。回调函数应该立即完成,否则,持有result的进程将被阻塞。
?下面的例子展示了如果通过进程池来执行一个并行应用。我们创建了有4个进程的进程池,然后使用?map()?方法进行一个简单的计算。
?
import multiprocessing
def function_square(data):
result = data*data
return result
if __name__ == '__main__':
inputs = list(range(100))
pool = multiprocessing.Pool(processes=4)
pool_outputs = pool.map(function_square, inputs)
pool.close()
pool.join()
print ('Pool :', pool_outputs)进程和线程比较
- 地址空间和其它资源(如打开文件):进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
- 通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
- 在多线程OS中,进程不是一个可执行的实体。
还可以类比为火车和车厢:
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到该趟火车的所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-”互斥锁(mutex)”
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量(semaphore)”
参考链接:
第三章 基于进程的并行 — python-parallel-programming-cookbook-cn 1.0 文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!