基础IO --- 下
目录
1.2.1. Boot Block && Block Group?
1. 理解文件系统中inode的概念
我们在基础IO --- 上 谈论的文件都是被打开的文件,而被打开的文件是在内存中!那么有没有没被打开的文件呢???答案是:有的!这种文件在磁盘上!而我们将这种文件称之为磁盘级别的文件!!!
根据冯诺依曼体系,被打开的文件是在内存中,而未打开的文件是在磁盘上!!!所以这两种文件所处的场景都不一样,因此不能将这两种文件混为一谈!!!
那么我们学习磁盘级别的文件,侧重点在哪里呢???
站在单个文件的角度来看:我们更关心的是,这个文件在哪里? 这个文件多大??这个文件的其他属性是什么等等其他话题!
而站在系统的角度来看:我们更关心的是,磁盘中一共有多少个文件?各自属性在哪里?如何快速找到?磁盘还可以存储多少个文件?如何快速的找到指定的文件等等其他话题!
那么如何对磁盘文件进行分门别类的存储,用来支持更好的存取!!
要了解这个话题,我们必须要对磁盘以及文件系统有一定的了解!!!
1.1. 了解磁盘
内存是一种掉电易失的存储介质,也称为随机访问存储器(Random Access Memory,RAM)。当计算机断电时,内存中的数据会被清空,因此内存中的数据是临时存储的,需要持续供电来维持数据的保存。
而磁盘则是一种永久性的存储介质,通常是通过磁性材料在磁盘上记录数据。即使断电,磁盘上的数据仍然可以被保留。因此,磁盘适用于长期存储和持久化存储,如操作系统、应用程序以及用户文件等。
1.1.1. 认识磁盘?
磁盘或类似的存储介质:
SSD(Solid State Drive,固态硬盘):与传统机械硬盘不同,SSD采用闪存芯片作为存储介质,具有更高的读写速度和更低的访问延迟。在外观形态上与传统机械硬盘相似,但工作原理不同。
U盘(USB Flash Drive):也被称为闪存盘,它是一种便携式存储设备,内部采用闪存芯片作为存储介质,通过USB接口与计算机进行连接和数据传输。
Flash卡:也被称为闪存卡或存储卡,是一种通用的可擦写存储介质,常见的有SD卡、MicroSD卡、CF卡等。它们通常用于相机、手机、平板电脑等设备中扩展存储空间或作为移动存储介质。
光盘:包括CD、DVD和Blu-ray Disc等,采用光学记录原理,通过激光读取信息。光盘通常用于存储音频、视频、软件安装等数据。
磁带:磁带是一种较为老旧但仍在某些特定领域使用的存储介质。磁带使用磁性材料作为记录介质,通过磁头读写数据。磁带主要用于大规模数据备份和存档,具有较大的存储容量。

1.1.2. 磁盘的物理结构
而我们在这里谈论磁盘的是机械硬盘,机械硬盘的内部结构如下

下面是机械硬盘的主要结构,具体如下:?
磁盘盘片(Platters):磁盘通常由多个金属或玻璃盘片组成,盘片表面涂有磁性材料。这些盘片一般通过中心轴垂直堆叠在一起。
磁头(Head):磁头是位于磁盘上方和下方的读写装置,用于读取和写入数据到磁盘盘片的表面。每个盘片都有一个磁头,用于在不同的磁道上读写数据。
柱面(Cylinder):表示数据存储介质上的一个圆柱面,由许多同心圆组成。同一磁盘的所有磁头对应的柱面被视为一个柱面组(cylinder group),称为柱面号(cylinder number)。
扇区(Sector):每个磁道被划分为多个等长的扇区。扇区是磁盘最小的物理存储单位,通常为512字节或4KB的大小。
磁道(Track):磁盘表面被划分为许多同心圆轨道,称为磁道。磁头可以在磁道之间移动,访问特定磁道上的数据。
磁道间隔(Inter-Track Spacing):相邻磁道之间有一些间隔,用于帮助磁头准确定位到特定磁道。
主轴(Spindle):磁盘盘片通过主轴固定在磁盘驱动器的中心。主轴可以旋转盘片,以使磁头能够在盘片的不同位置读取和写入数据。
控制器(Controller):磁盘驱动器中的控制器负责管理磁头的移动、磁盘的旋转和数据的读写等操作。控制器也处理与主机系统的通信,并负责磁盘的高级功能,如缓存和错误检测校正。
磁盘是一个外设并且是计算机中唯一的一个机械设备!!!因此这个磁盘设备非常的慢,这个慢是相对于CPU和内存而言的!!!我们也可以量化一下CPU、内存、磁盘处理数据的能力,如下:
CPU(中央处理器)处理数据的级别通常是以纳秒(10^-9秒)为单位。CPU是计算机的核心组件,具有非常高的处理速度,可以在纳秒级别内执行指令和操作。
内存的访问速度通常以微秒(10^-6秒)为单位。相对于CPU来说,内存的访问速度较慢一些,但仍然很快。内存是计算机中用于临时存储数据的地方,可以迅速地读取和写入数据。
磁盘的访问速度通常以毫秒(10^-3秒)或秒为单位,具体取决于磁盘的类型和性能。相对于CPU和内存来说,磁盘的读写速度较慢。这是因为磁盘是机械设备,需要进行旋转和磁头寻道等操作来读取和写入数据
因此,实际上,磁盘是一种很慢的设备,但操作系统(OS)会采取一些策略和技术来提高对磁盘的访问效率,以尽量减少延迟并提升整体性能!!!例如:
缓存:操作系统可以使用缓存技术将频繁访问的数据存储在内存中。通过缓存,可以减少对慢速磁盘的访问次数(减少IO次数),加快数据的读取速度。
提前读取(Pre-fetching):操作系统可以根据访问模式和预测算法,在磁盘读取数据时提前读取相邻的数据块到内存中。这样当需要访问这些数据时,可以直接从内存中读取而不用等待磁盘的旋转和寻道时间。
磁盘调度算法:操作系统可以采用不同的磁盘调度算法,如先来先服务(FCFS)、最短寻道时间优先(SSTF)、扫描(SCAN)等,来优化磁盘的读写顺序,减少寻道时间和延迟。
磁盘分区和文件系统:合理的磁盘分区和优化的文件系统可以提高读写效率和快速查找文件。常见的文件系统如NTFS、FAT32、ext4等都有针对性的优化策略,以提供更好的性能。
1.1.3. 简单了解磁盘如何读写数据的
我们知道,磁盘上的数据,是存于磁盘盘面上的,也就是说盘面上会存储数据,而我们知道计算机只认识二进制数据!!!存储的数据本质就是二进制数据!!!二进制数据本质上是一种两态的数据!!!那么磁盘中是如何定义这种两态的数据的呢? 而实际上,盘面中是存在着大量的小的磁性区域的!!!
而写入数据的本质是通过改变磁性区域的磁化方向,使该磁性区域磁化向上或向下来实现的!!
读取数据的过程,并不是说磁性区域N级向上代表为1,S级在上代表为0,而实际上是磁头会在磁道上移动,通过感测相邻磁性区域的磁性变化来解读存储的二进制数据。每次相邻的两个磁性区域改变时,磁头会将其解析为二进制的1,不变时磁头将其解析为二进制的0!!!简单来说,就是相邻的两个磁性区域的仓磁化方向相同为0,相异为1;?
总而言之,通过改变磁性区域的磁化方向,磁盘可以存储和读取二进制数据,计算机根据相邻磁性区域的磁性变化来解释和识别数据的不同状态。这种基于磁性的储存和读取机制是现代磁盘驱动器的基础。
1.1.4. 磁头和盘面没有物理上的接触
我们要知道,实际上,磁盘中的磁头和盘面是没有相互接触的(物理上的),因为盘面是高速旋转的,如果相互接触,那么极有可能由于磁头和盘面的相互摩擦导致盘面被刮花,盘面挂花也就意味着盘面的物理结构受到了破坏,那么可能导致数据丢失等其他问题!!!
磁盘的盘面是通过主轴旋转的,旋转速度通常在每分钟数千转到一万转之间(目前来看,市面上的磁盘主流还是7200转)。而磁头则悬浮在盘面上方,以纳米级的高度(通常是几十纳米)悬浮在盘面表面的空气或润滑膜中,利用气体动压或润滑膜来保持磁头的稳定悬浮。
通过这种非接触式的设计,磁头可以在盘面上方快速移动而不会直接接触到盘面,避免了因摩擦而导致的物理损坏和数据丢失的风险。这种设计还可以确保读写过程的可靠性和精度,因为任何磁头和盘面之间的直接接触都可能导致不可预测的结果。
因此,在正常的使用情况下,磁头和磁盘盘面之间不会有物理上的接触,以保护磁盘的完整性和数据的安全性。
1.1.5. 扇区的了解?
扇区(Sector)是磁盘存储数据的基本单位,一般扇区的大小是512字节,然而,近年来,随着技术的发展和容量需求的增加,一些磁盘驱动器也开始采用更大的扇区大小,如4KB(4096字节)。这种更大的扇区大小有助于提高磁盘的性能和容量利用效率,并且可以更好地支持现代文件系统和应用程序的需求。但需要注意的是,使用4KB扇区的磁盘通常需要与特定的操作系统和文件系统相兼容才能正常使用。
总体而言,512字节的扇区大小是常见且广泛采用的标准,而4KB扇区大小则是一种新兴趋势,尤其在较大容量的磁盘驱动器和高性能存储系统中使用。
1.1.6.?如何在物理上找到一个具体的扇区
在物理上,如何找到一个具体的扇区呢?分为三个过程:
1、确定在哪一个磁道 (柱面号 Cylinder Number) 上,柱面号表示磁头在磁道上的位置。它的范围通常从0开始,逐渐增加到磁盘上的最大柱面数。
2、确定在哪一个盘面上 (磁头号?Head Number) ,磁头号表示磁头在柱面中的位置。它的范围通常从0开始,逐渐增加到磁盘上的最大磁头数。
3、确定在哪一个扇区(扇区号 Sector Number),扇区号表示在给定柱面和磁头中的特定扇区位置。它的范围通常从1开始,逐渐增加到磁盘上的最大扇区数(通常是63或255)。
上面这种寻址方案:在物理上称之为CHS( Cylinder Head Sector )寻址方案!!!当我们有了CHS寻址方案,那么就可以找到任意一个扇区,即所有扇区我们就都能找到!!!
1.2.? 站在OS的角度看待磁盘
站在操作系统的角度,即在软件层面上,我们可以将磁盘抽象成一种线性结构!!!
即将一个磁盘抽象成一个大数组,数组的每一个元素代表一个扇区!访问一个特定的扇区,那么只要知道该扇区在该数组中对应的下标即可!而这种寻址方案:我们称之为 LBA (Logical Block Addressing)寻址方案,LBA又称为逻辑块寻址,操作系统使用的地址是通过LBA寻址方案得到某个具体扇区的地址,而最终,为了访问磁盘中具体的某个扇区,操作系统会将LBA地址转换为CHS(Cylinder-Head-Sector)方案地址,最终才能访问到磁盘中具体的某一个扇区!!!
将数据存储到磁盘等价于将数据存储到抽象出来的这个数组中,那么首先要找到磁盘特定扇区的位置等价于找到该数组特定的下标!!!那么对磁盘的管理就可以转化为对该数组的管理!!!
?我们将磁盘抽象为线性结构,如下:
可是磁盘太大了啊,那么抽象出来的这个数组就会非常大,那么就会导致管理成本太高!!!因此,为了降低管理成本, 我们采用分治的思想,即对这个抽象出来的大数组进行分区!!!如下:
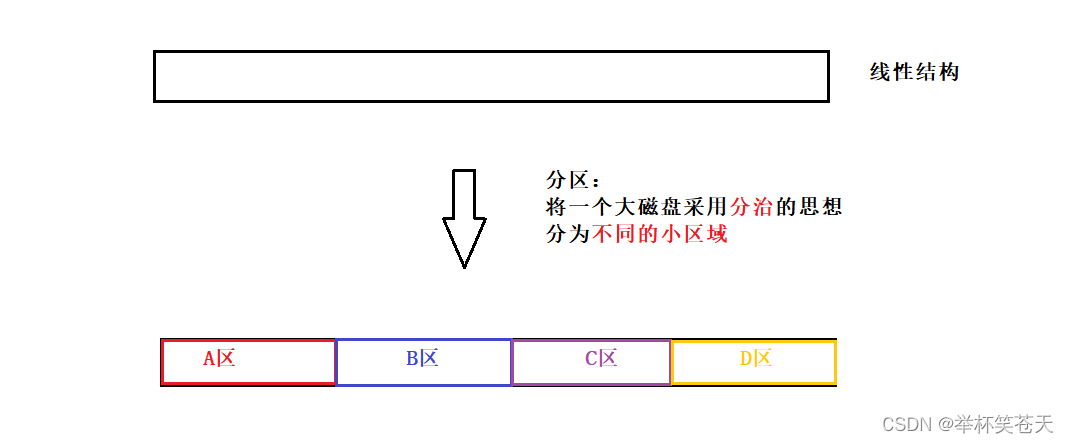
?那么此时对磁盘抽象出来的这个数组的管理就转化为对某一个小分区的管理!!!只要管理好某一个具体的分区,那么就可以通过这份管理经验管理好其他分区!!!那么整个磁盘也就可以管理好!!!
但是,我们分出的这个区域还是太大了,其管理成本依旧很高,因此我们将某一个具体的小分区在进行采用分治的思想,分为不同的小区域!!!
如下:
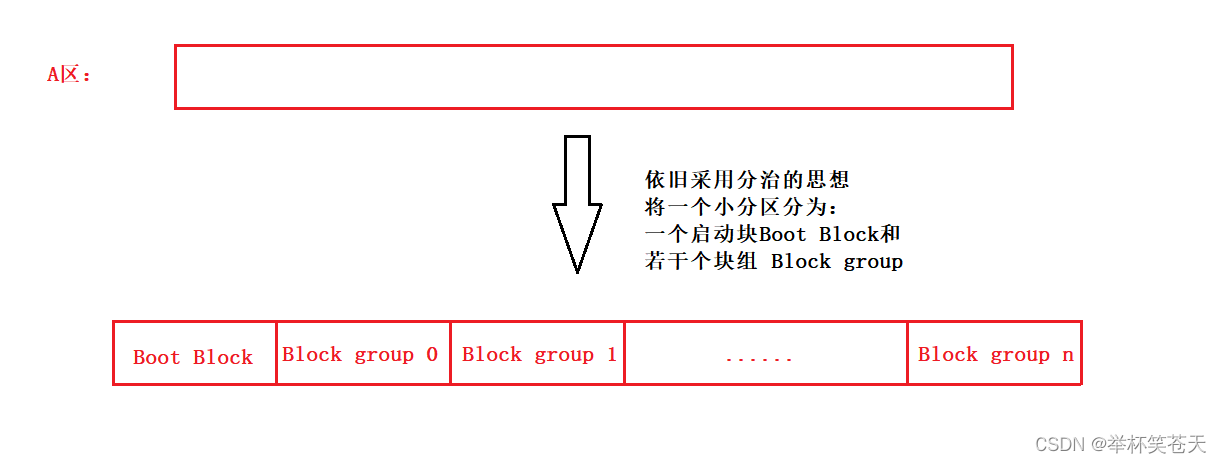
1.2.1. Boot Block && Block Group?
Boot Block(引导块/启动块):它是一个针对计算机引导过程设计的特殊区域,它位于存储设备的开头。它包含有关引导加载程序的信息,用于启动计算机并加载操作系统。
Block Group(块组):ext2文件系统根据分区的大小划分为多个Block Group,而每个Block Group都有着相同的组成结构,块组是文件系统的逻辑分割单元,用于组织和管理文件系统中的数据、元数据和其他相关信息。
而事实上,Block Group也会分为不同的区域组成,如图所示:
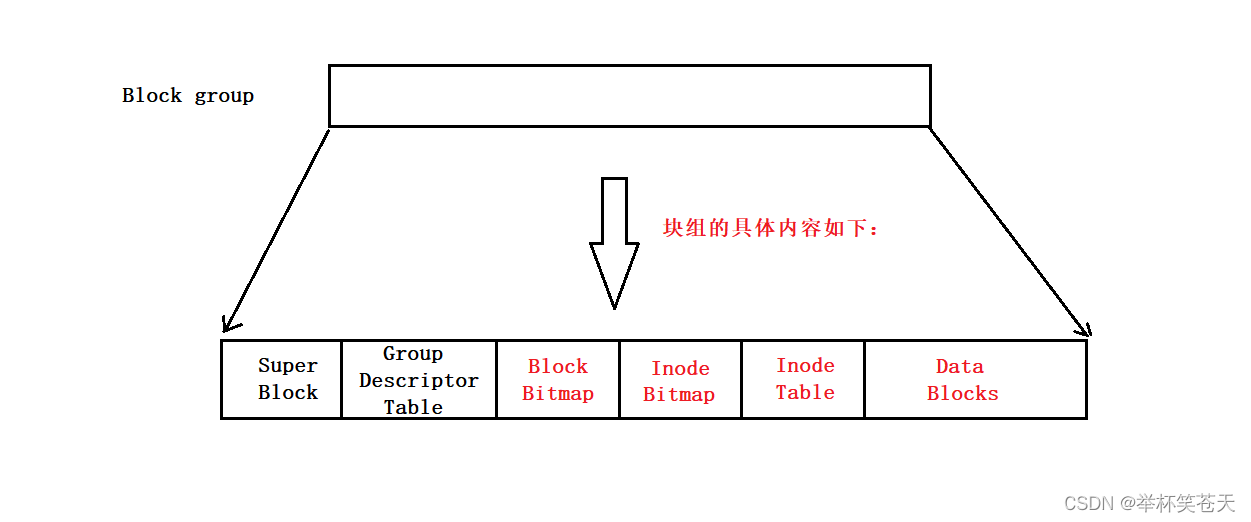
1.2.2. Super Block?
Super Block (超级块):
Super Block是 ext2 文件系统的一个重要组成部分。它包含了关于文件系统的关键信息和元数据!!!Super Block 在一般情况下,在多个块组中会有备份!!! 但并不是每一个块组都有!!!具体来说,Super Block 包含了以下信息:
- 文件系统的总块数 和 总 inode 数:用于计算文件系统的容量。
- 块大小和块组大小:文件系统中每个块(Block)的大小以及每个块组(Block Group)中的块数。
- 空闲块和空闲 inode 的数量:用于记录文件系统中当前可用的块和 inode 的数量。
- 文件系统的挂载时间和最近的检测时间:用于记录文件系统的挂载信息和检测时间。
- inode 表的起始块地址:指向存储 inode 的起始块。
- 特殊文件的 inode:指向根目录、lost+found 目录等特殊文件的 inode 号。
- 块组描述符表的起始位置:指向块组描述符表,其中存储了每个块组的元数据信息。
Super Block 的信息对于文件系统的正常运行和恢复非常重要。通过读取 Super Block ,操作系统和工具可以了解文件系统的结构、大小和状态,从而正确地访问和管理文件系统中的数据。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了!!!
1.2.3.?Group Descriptor Table
Group Descriptor Table(块组描述符表):
在 Linux 的 ext2 文件系统中,Group Descriptor Table(块组描述符表)是一个关键数据结构,用于跟踪文件系统中每个块组的信息。它位于文件系统的一定位置,是与超级块(Super Block)和 inode 表一起组成文件系统元数据的重要组成部分之一。
块组描述符表记录了文件系统中每个块组的元数据信息,包括块组的起始块地址、块位图(Block Bitmap)的块地址,inode 位图(Inode Bitmap)的块地址和 inode 表的起始块地址等。块组描述符表中的每个条目与文件系统的每个块组相对应,因此文件系统中块组的数量等于块组描述符表中的条目数。
块组描述符表的作用是为文件系统提供有关每个块组的信息,并支持文件系统的核心操作,如分配和释放块、分配和释放 inode 等。每个块组描述符表条目的内容取决于文件系统的配置,如块大小、inode 大小和块组大小等。
总之,块组描述符表是 ext2 文件系统中的重要元数据结构之一,提供了有关文件系统中每个块组的信息。这些信息对于文件系统的正常运行和管理非常重要。
我们知道,在Linux系统中,文件 = 文件内容 + 文件属性,而 Linux 在磁盘上存储文件的时候,是将文件内容 和 文件属性 进行分别存储的!!!
而Data Blocks 就是存放文件内容的地方,而Inode Table 是保存文件属性的地方!!!
1.2.4. Data Blocks?
Data Blocks:
虽然磁盘存储数据的基本单位是一个扇区 (512 byte) (硬件上的要求),但是OS (文件系统)和磁盘进行IO的基本单位是:4KB (8 * 512 byte) (软件上的要求);
有人就很好奇,为什么不以512字节为单位呢???
1、首先,较大的 IO 单位可以减少磁盘访问的次数 (减少IO次数)。磁盘的访问是相对较慢的操作,因此减少 IO 次数可以减少磁盘寻址和传输的时间。如果使用较小的 512 字节作为 IO 单位,那么对于相同的数据量,需要进行更多次的 IO 操作才能完成数据传输,这将导致系统的整体效率降低!!!
2、其次,使用固定的 IO 单位与硬件要求分离,使操作系统能够更好地适应不同硬件平台的变化。磁盘存储技术在不断发展,未来可能会出现更大的扇区大小或其他新的存储技术。如果操作系统和磁盘的 IO 单位以完全相同的大小绑定在一起,那么在硬件发生变化时,操作系统的源代码可能需要进行修改才能适应新的硬件要求。通过将 IO 单位设置为 4KB,操作系统与具体磁盘存储技术解耦,可以更容易地适应不同的硬件平台和存储技术变化。
一个数据块(Block) ,其默认大小为4KB,而多个4KB(扇区 * 8)大小的集合我们称之为Data Blocks,其保存的都是特定文件的内容!数据块是文件系统中用于存储文件数据的最小单位,它提供了碎片化存储空间和协调磁盘空间管理的功能。
注意:Data Block 的数量也是有限的,如果当文件系统中的Data Block已经用完时,如果尝试创建一个新文件并向其写入内容,将会导致写入失败。
1.2.5. Inode Table
Inode Table:
Inode Table(索引节点表)是文件系统中用于存储文件元数据的数据结构。每个文件和目录在文件系统中都有一个对应的索引节点(Inode),而 Inode Table 就是用来管理和存储所有这些索引节点(Inode)的表格。
索引节点(Inode)是文件系统中的一个重要概念,在 ext2 文件系统中,Inode的大小固定为128字节。它用于存储文件的元数据,包括文件的权限、所有者、文件类型、大小、时间戳等信息。具体而言,每个索引节点中包含了文件的唯一标识符(inode编号)、文件的访问权限、文件大小、链接数(文件被引用的次数)、文件的物理地址指向数据块等信息。
Inode Table将所有文件的索引节点(Inode)组织在一起,通常以数组或其他数据结构的形式进行存储。每个索引节点都有一个独特的索引节点号(inode 编号),通过该索引节点号可以在索引节点表中快速检索到对应的索引节点。
当文件系统需要读取或修改文件时,会先通过 Inode Table 找到对应的索引节点(Inode),并从索引节点(Inode)中获取文件的元数据和数据块的物理地址。通过这种方式,文件系统可以有效地管理和访问文件,包括创建、删除、读取和修改文件的操作。
需要注意的是,Inode Table的大小是固定的,它限制了文件系统中可以创建的最大文件数量。当Inode Table已满时,文件系统将无法再创建新文件,即使存储设备还有可用空间。
综上所述,Inode Table是文件系统中用于存储和管理文件索引节点(Inode)的一种数据结构,它包含了文件的元数据和用于定位文件数据的物理地址信息,帮助文件系统有效地管理和访问文件。
1.2.6. Block Bitmap
Block Bitmap(块位图)是文件系统中的一种数据结构,用于跟踪和管理文件系统中的数据块的使用情况。
在文件系统中,存储设备被划分为固定大小的数据块(block),这些数据块是文件系统进行数据存储和管理的最小单位。数据块位图(Block Bitmap)用于记录每个数据块的使用情况,它通常以位图的形式表示。
数据块位图中的每个位(bit)表示一个数据块的状态,通常用 0 或 1 表示,分别表示未使用或已使用。当一个数据块被分配给文件时,相应的位会被标记为1,表示该数据块已被占用。当一个文件被删除或移动时,相应的位会被标记为0,表示该数据块又变为空闲可用状态。
通过数据块位图,文件系统可以快速查找和管理可用的数据块。当需要为文件分配新的数据块时,文件系统会查找位图中的空闲位,找到一个未被使用的数据块并将其分配给文件。而当文件被删除时,文件系统会将相应的位标记为空闲,表示该数据块可以被后续文件再次使用。
数据块位图是文件系统的重要组成部分,它帮助文件系统有效地管理磁盘空间和数据块的分配。通过跟踪数据块的使用情况,文件系统可以优化磁盘空间的利用,并避免数据块的碎片化。同时,数据块位图也可以用于检测文件系统的完整性和一致性,以确保数据块被正确地分配和释放。
总之,数据块位图是文件系统中的一种数据结构,用于记录和管理数据块的使用情况。它帮助文件系统管理磁盘空间,优化数据块的分配,并确保文件系统的一致性和完整性。
1.2.7. Inode Bitmap
Inode Bitmap(索引节点位图)是文件系统中的一种数据结构,用于跟踪和管理使用中和空闲的 inode(索引节点)。
Inode Bitmap是一个位图(bitmap),用于表示文件系统中 Inode结构对象的分配情况。每个位对应一个 Inode 结构对象,如果该位为0,表示对应的 Inode 结构对象未被分配(未被使用);如果该位为1,表示对应的 Inode 结构对象已被分配(已被使用)。
通过索引节点位图,文件系统可以快速查找和管理可用的 Inode 结构对象。当需要分配新的 Inode 结构对象?给一个文件时,文件系统会查找位图中的空闲位,找到一个未被使用的 Inode结构对象?并将其分配给该文件。
索引节点位图是文件系统的重要组成部分,它帮助文件系统有效地管理 Inode结构对象?并避免 Inode结构对象碎片化。同样,索引节点位图也可以用于检测文件系统的完整性和一致性,以确保 Inode 结构对象?的正确分配和释放。
总之,索引节点位图是文件系统中一种用于记录和管理 Inode结构对象?状态的数据结构。通过它,文件系统可以快速地分配和释放?Inode结构对象,避免 Inode 结构对象的碎片化,并确保文件系统的一致性和完整性。
注意:
inode编号是由文件系统内部分配和管理的。通常情况下,文件系统会使用一个单独的数据结构(如Inode Table)来维护inode 编号和对应的 Inode结构对象之间的映射关系。通过这个映射关系,操作系统可以根据 inode编号 来找到对应的Inode结构对象,并读取或修改相应的属性和数据。
在文件系统中,每个文件都对应一个inode编号,可以通过该编号来唯一标识一个文件;站在操作系统的角度来看,文件是一个由 Inode 结构对象和数据块组成的实体。每个文件都有一个的 inode 编号,Inode结构对象中记录该文件的属性信息,如文件类型、访问权限、最近访问时间、最近修改时间等。数据块则用来存储文件的实际内容。
因此,在操作系统中,可以通过 inode编号 来查找和处理文件,如打开文件、读取文件、修改文件属性等。文件名只是一个用户友好的视觉标识,方便用户来记忆和使用文件,并且通过文件名可以方便地在文件系统中查找和定位文件的 Inode结构对象信息。
有了上面的这些信息,那么就能够让一个文件的信息可追溯,可管理!!!而我们将一个块组分割成上面的内容,并且写入相关的管理数据,当每一个块组都这么操作,那么整个分区都被写入了文件系统信息,而这个过程我们就称之为格式化!!!
1.2.8. inode与 block的关系
一个文件对应一个 Inode 结构对象 ,对应一个 inode 编号;那么一个文件只能有一个block吗???
答案是:不一定,因为一个block 只有4KB的大小,可是一个文件有时候可不仅仅只有4KB的大小!!!那么结论就是:一个文件是可以有多个block的;
那么问题来了,哪些 block 属于同一个文件呢? 要找某一个文件,那么只要找到该文件对应的 inode 编号,通过 inode 编号,就能找到该文件的 Inode 属性集合,可是,文件的内容呢,即 blcok 如何找到呢?
在一个文件的 Inode 属性节点中,通常会有一个blocks数组或指针,用于记录文件占用的数据块的编号。通过这个数组或者指针,就可以找到这个 Inode 结构对象与之关联的 block了!!!
我们知道一个block块的大小是4KB,那如果这个文件特别的大 ,那怎么办呢???
由于一个数据块的大小是有限的,无法存储大文件的全部内容,因此使用间接块的方式来解决这个问题。
间接块可以存放其他块的编号,形成一个链式的结构。文件系统通过遍历这个链式结构,就可以找到存储文件实际内容的数据块的编号。每个间接块中可以存储一定数量的块编号,依此类推,通过多级间接块的方式,就可以存储大量的数据。
举例来说,如果一个文件占用了10个数据块,那么前10个块的编号可能直接存放在Inode 结构对象的 blocks 数组中。如果一个文件占用了更多的数据块,多余的块的编号可能会存放在一个间接块中,而这个间接块的编号则会存放在 Inode 结构对象的 blocks 数组中。通过这种方式,文件系统可以构建一个链式结构,通过连续的寻址,找到存储文件实际内容的数据块。
简而言之,block 不一定存放的全是文件内容,还有可能存放的是其他块的编号!!!
通过间接块的方式,文件系统可以支持存储大文件,充分利用磁盘空间并提高文件系统的效率。
综上所述,一个文件可以占用多个数据块,而文件系统使用间接块的方式来支持大文件的存储。通过建立链式结构,将数据块的编号存放在 Inode 结构对象的 blocks 数组中,文件系统可以寻址并找到存储文件实际内容的数据块。
为了更好地理解,我们简单列举一下 Inode 结构的属性:
注意:内核里的实现可能没有这么简单,可能会进行多次封装,在这里只是举例罢了。
struct inode
{
// 文件的大小
// 其他属性
// 文件的inode编号
int inode_number;
// 这个数组里面的内容就是
// 这个inode与之关联的block
int blocks[15];
};
1.2.9. inode 与 文件名的关系
在Linux下,文件名在操作系统层面没有意义(包括文件后缀),文件名是给用户使用的;在Linux中真正标识一个文件,是通过文件的inode编号,一般情况下一个文件一个inode编号 !!!

我们知道要找到一个磁盘文件,那么必须要先找到这个 inode 编号,才能在某个分区特定的block group中找到对应的 Inode 属性,即 struct inode ,才能找到这个 Inode 结构对象与之对应的数据块 block !!!
而在Linux下,struct inode 属性里面,是没有文件名这样的说法;那么OS怎么知道一个文件的 inode 编号呢???
为了说明这个问题,我们需要两个储备知识:
1、 一个目录下,是可以有很多文件的!但是这些文件是没有重复的文件名的!!!即在同一个目录下,没有相同文件名的文件!!!
2、 目录是文件吗???当然是文件!!!那么既然是文件,那么就必须得有自己的 Inode 结构对象 和 自己的 数据块 block 。
那么目录的 block 中存储的内容是什么呢?答案是: 目录文件的 block 存储的是 该目录下文件的文件名 和 inode编号 的映射关系!!
而在以前,我们学习Linux权限的时候说过,创建(删除)文件,是需要具有 w 权限的;当时我们是经过测试得出的结论,可是为什么呢??? 为什么在一个目录下创建文件,这个目录需要具有w权限呢???而现在我们有了上面的一些理解,我们就可以解释这个现象了(我们在这里以创建文件举例):
目录是文件吗?是的!既然是文件,那么必然有自己的 Inode 结构对象和 block,而我们说了,目录的 block 中的内容存储的是 其目录下的文件的文件名 和 inode编号的映射关系,那么你在这个目录下创建文件,本质上就是将你所创建的这个文件的文件名 和 文件系统所分配的 inode编号 关联起来并写入这个目录文件的 block 中,既然是写入,那么当然要有 w 权限咯!!!
换句话说,当我们使用 shell 命令创建文件时,实际上是通过在目录文件中添加新的文件名及其对应的 inode编号 来完成的,因此要求目录文件具有写权限。
同样,我们以前也说过,用 ls命令 显示一个目录下的文件信息(文件名 + 文件属性信息等等),是需要该目录具有r权限的!!!以前我不知道为什么,但现在我们也可以解释这个现象了!!!解释如下:
你要显示一个目录下文件的文件名以及文件的属性信息,先说文件名,而我们知道,inode 属性中是没有文件名的,只有该目录下的数据块 block 中有,因此,我们必须去读取目录的 block 中的数据,既然是读取,当然要求目录具有 r 权限咯!!!同样,当我们要显示文件的其他属性信息时,那么必须要知道文件的 inode 编号,可是谁才有这些文件的 inode编号 呢?答案是:目录文件的 block 里面有该目录下文件的 inode编号,因此还是要去读取目录文件的数据块 block,那么当然要求目录具有 r 权限咯!!!
1.3. 分析三个问题
有了上面的分析,我们就可以站在OS的角度,分析下面的三个问题:
1. 创建文件,操作系统做了什么

当我在 bash 调用命令 touch log.txt,操作系统层面做了什么呢???
1、首先,当我们创建一个文件时,其所在目录是确定的,操作系统会定位到该目录所属的块组 Block Group 。
2、然后,操作系统会去遍历该块组中的?Inode Bitmap,得到第一个为 0 的比特位所在的位置,而这个位置就可以充当所要创建 log.txt 的 inode 编号,这个 inode编号将成为被创建文件的唯一标识。
3、接下来,操作系统会将文件属性信息填充 struct inode 结构对象 (包括文件的权限、所有者、时间戳等信息),因为当前是空文件,因此可以暂时不分配数据块 block 给这个 Inode 结构对象。
4、与此同时,操作系统会将用户提供的文件名以及文件系统分配的 inode 编号关联起来,填充到该目录文件的数据块 block 中!
通过上述步骤,操作系统完成了文件的创建过程。此时,该文件的 Inode 结构对象已经创建并且其 inode编号与文件名相关联,文件内容尚未分配数据块。
需要注意的是,上述过程是简化的描述,实际上,还涉及到文件系统的一些细节实现,如磁盘空间分配策略、磁盘块的写入等。
2. 删除文件,操作系统做了什么
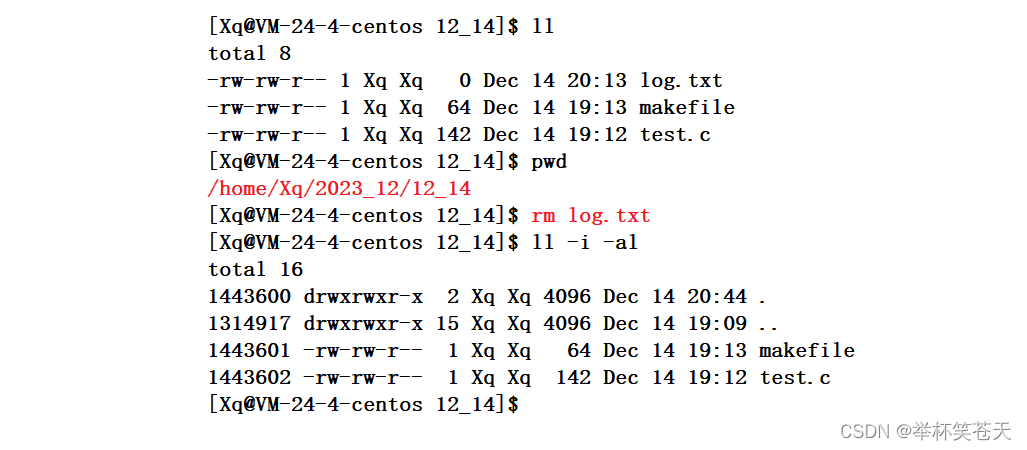
首先,我们可以确定一点,删除文件,用户必然会提供被删除文件的目录,以及被删除文件的文件名!!!
1、因此,当删除一个文件时,OS可以是确定这个被删除文件所在的目录!那么操作系统会定位到该目录所属的块组 Block Group 。
2、然后,操作系统遍历该块组的 Inode Table,找到该目录文件的 Inode 结构对象。每个目录文件都有一个 Inode 结构对象,其中记录着该目录文件的属性和数据块的索引。
3、接下来,操作系统根据目录文件的 Inode结构对象?去访问该目录文件的数据块 block,通过用户提供的文件名在数据块 block 中索引对应的 inode 编号,这个 inode 编号就是被删除文件的 inode 编号。
4、通过这个?inode 编号,找到对应的 Inode 结构对象,通过这个结构对象得到所对应数据块 block 的编号,在遍历当前块组的 Block Bitmap,将所对应的数据块的编号所在的位置由 1 置为 0,表示该 block 编号可用;
5、遍历当前块组的 Inode Bitmap,找到所要删除 inode编号的位置,在由OS遍历并将该位置上的位由 1 设置为 0 ,表示该 inode 编号可用。
6、最后,将该目录的 block 中的内容也就是这个被删除文件的 inode编号 和 文件名的映射关系给删除掉。
通过上述步骤,操作系统完成了文件的删除过程。
从上面我们也可以看出,删除文件并不一定意味着文件内容真正地从磁盘上被清除,而是将对应的inode编号 和 block 编号 标记为可用。
3. 打开文件,操作系统做了什么
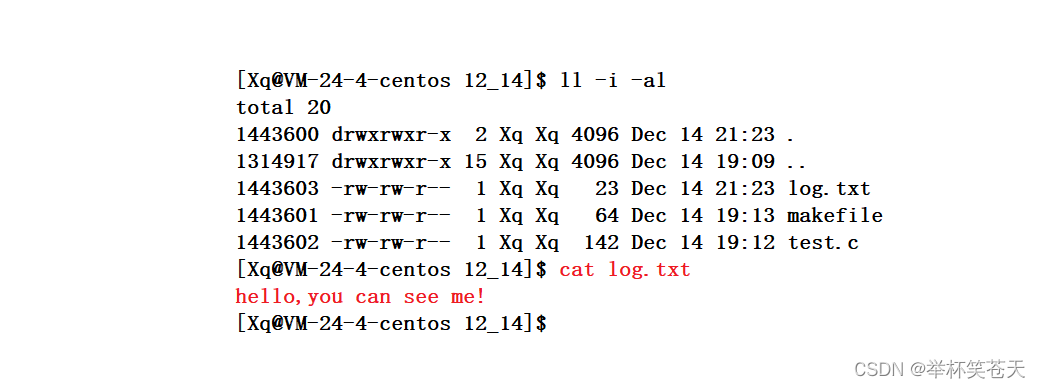
首先,我们可以确定一点,打开文件,用户必然会提供被打开文件的目录,以及被打开文件的文件名!!!
1、首先,当用户打开一个文件时,操作系统可以是确定这个被打开文件所在的目录!那么操作系统会定位到该目录所属的块组 Block Group 。
2、随后,操作系统通过遍历块组中的 Inode Table,找到该目录文件的 Inode 结构对象。
3、接下来,操作系统通过该结构对象找到该目录文件所对应的数据块 block 。
4、然后,操作系统根据用户提供的文件名,访问目录文件的 block 得到与该文件名关联的 inode 编号。
5、接着操作系统遍历该块组的 Inode Table,找到该文件的 Inode 结构对象。
6、最后,操作系统通过该结构对象找到该 inode编号与之对应的 block,这些数据块 block 存放的就是该文件的内容,OS通过读取这些内容并返回给上层用户;
通过上述步骤,操作系统完成了文件的打开过程,可以将文件的内容提供给用户进行读取或其他操作。
2. 认识软硬链接
2.1. 软链接
ln -s log.txt log_s ? ?
ln "表示链接(link)的意思,”-s" 参数表示创建软链接(symbolic link,也称为符号链接)。该命令的作用是在当前目录下创建一个名为 "log_s" 的新的符号链接(软链接)文件,指向名为 "log.txt" 的文件。
unlink log_s ?删除软链接文件 log_s? (当然也可以用 rm 命令)
[Xq@VM-24-4-centos 12_16]$ ll
total 8
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
-rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$ ln -s test.c log_s //创建软链接 log_s
[Xq@VM-24-4-centos 12_16]$ ll
total 8
lrwxrwxrwx 1 Xq Xq 6 Dec 15 13:10 log_s -> test.c
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
-rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$ unlink log_s //删除软链接log_s
[Xq@VM-24-4-centos 12_16]$ ll
total 8
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
-rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$那么软链接有什么应用场景呢?
[Xq@VM-24-4-centos 12_16]$ pwd
/home/Xq/2023_12/12_16
[Xq@VM-24-4-centos 12_16]$ ll
total 12
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
drwxrwxr-x 3 Xq Xq 4096 Dec 15 13:19 other
-rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$ tree other/
other/
`-- bin
`-- my_test
1 directory, 1 file
[Xq@VM-24-4-centos 12_16]$ ll other/bin/my_test
-rwxrwxr-x 1 Xq Xq 8360 Dec 15 13:19 other/bin/my_test
[Xq@VM-24-4-centos 12_16]$假如我要在当前目录下运行 other/bin/这个目录下的my_test这个可执行程序,我是不是要这样运行
[Xq@VM-24-4-centos 12_16]$ ./other/bin/my_test
cowsay hello
cowsay hello
cowsay hello
cowsay hello
cowsay hello
[Xq@VM-24-4-centos 12_16]$如果这个可执行程序所在的目录足够深,或者这个目录下有非常多的文件,那么这样操作是不是非常复杂???而如果我们有了软链接,那么我们就可以简化这个过程:
[Xq@VM-24-4-centos 12_16]$ ll
total 12
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
drwxrwxr-x 3 Xq Xq 4096 Dec 15 13:19 other
-rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$ ln -s ./other/bin/my_test myexe // 创建软链接
[Xq@VM-24-4-centos 12_16]$ ll
total 12
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
lrwxrwxrwx 1 Xq Xq 19 Dec 15 13:27 myexe -> ./other/bin/my_test
drwxrwxr-x 3 Xq Xq 4096 Dec 15 13:19 other
-rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$ ./myexe // 利用软链接在当前目录下调用这个可执行程序文件
cowsay hello
cowsay hello
cowsay hello
cowsay hello
cowsay hello
[Xq@VM-24-4-centos 12_16]$Linux下的软链接非常类似我们在Windows下的快捷方式!
2.2. 硬链接
ln ./other/bin/my_test my_exe_hard? ? ?
这个命令中,ln 表示链接(link)的意思。它可以用来创建硬链接(hard link),该命令的作用是在当前目录下创建一个名为 my_exe_hard?的 新硬链接文件,指向路径为 ./other/bin/my_test 的文件!!
[Xq@VM-24-4-centos 12_16]$ ln ./other/bin/my_test my_exe_hard //创建硬链接文件
[Xq@VM-24-4-centos 12_16]$ ll
total 24
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
lrwxrwxrwx 1 Xq Xq 19 Dec 15 13:27 myexe -> ./other/bin/my_test
-rwxrwxr-x 2 Xq Xq 8360 Dec 15 13:19 my_exe_hard
drwxrwxr-x 3 Xq Xq 4096 Dec 15 13:19 other
-rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$ ./my_exe_hard // 在当前目录下指向硬链接文件
cowsay hello
cowsay hello
cowsay hello
cowsay hello
cowsay hello
[Xq@VM-24-4-centos 12_16]$可以看到,硬链接也有快捷方式的作用;那它和软链接有什么区别呢?
2.3. 软链接和硬链接的区别
[Xq@VM-24-4-centos 12_16]$ ll -il
total 8
1443607 -rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
1443608 -rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$
[Xq@VM-24-4-centos 12_16]$ ln -s test.c test_s // 创建软链接 test_s
[Xq@VM-24-4-centos 12_16]$ ll -il
total 8
1443607 -rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
1443608 -rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
1443609 lrwxrwxrwx 1 Xq Xq 6 Dec 15 13:39 test_s -> test.c
[Xq@VM-24-4-centos 12_16]$
[Xq@VM-24-4-centos 12_16]$ ln test.c hard // 创建硬链接 hard
[Xq@VM-24-4-centos 12_16]$ ll -il
total 12
1443608 -rw-rw-r-- 2 Xq Xq 189 Dec 15 13:08 hard
1443607 -rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
1443608 -rw-rw-r-- 2 Xq Xq 189 Dec 15 13:08 test.c
1443609 lrwxrwxrwx 1 Xq Xq 6 Dec 15 13:39 test_s -> test.c
[Xq@VM-24-4-centos 12_16]$如图所示:?
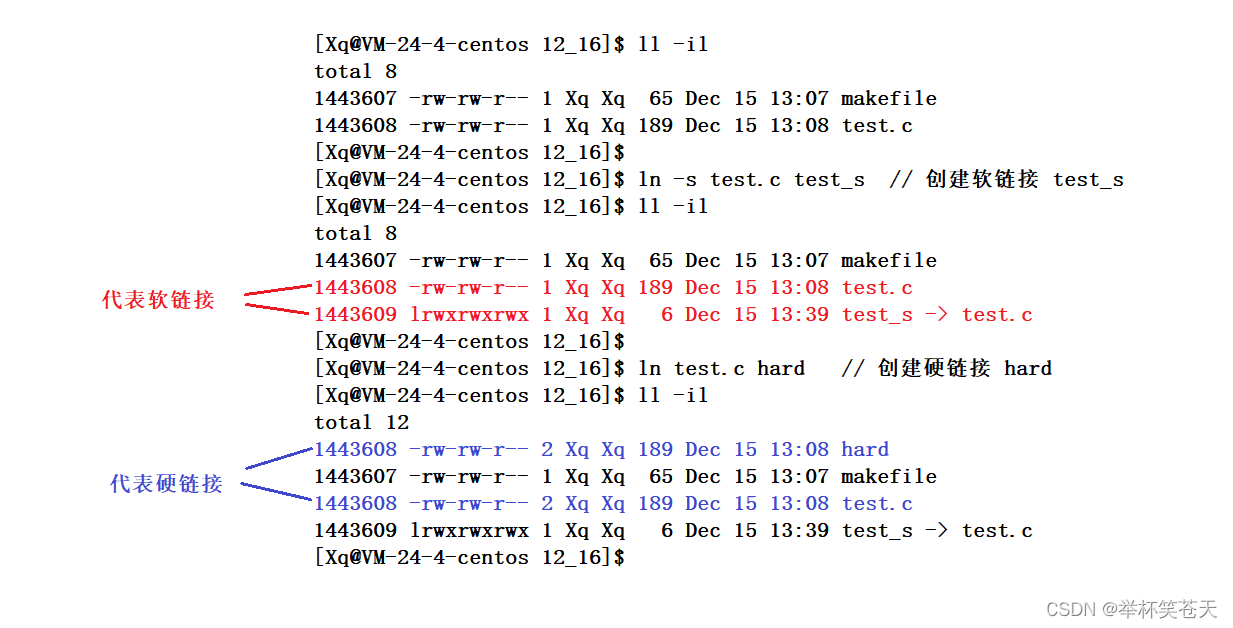
软链接是具有自己独立的 inode编号 的,软链接是一个独立文件;有自己的 Inode 属性,也有自己的数据块(保存的是指向文件的所在路径 + 文件名);
硬链接本质上根本就不是一个独立的文件,而是文件系统中对同一文件的多个命名入口;由于硬链接自己没有独立的 inode编号,因此创建硬链接,本质是在特定目录下的 block中填写一对文件名 和 inode编号的映射关系(即特定inode编号多了一个映射的文件名);
综上所述:软硬链接最本质的区别就是 是否具有独立的 inode 编号(inode编号可以映射到 Inode属性);

这些框起来的数字代表什么呢? 现在我们就知道了,这个数字叫做硬链接数(即有多少个文件名和这个 inode 编有映射关系)?;那么请问这个硬链接数保存在哪呢? ---> 保存在 Inode 结构变量中,即可以这样理解:
struct inode{
//文件的所有属性
//数据
int inode_number;
int blocks[N];
int ret; //硬链接数
...
};
因此创建文件的本质是: 这个文件inode编号所映射的Inode属性中的硬连接数加一,删除文件的本质是: ?这个文件inode编号所映射的Inode属性中的硬连接数减1,当硬连接数等于0时,才会去真正删除这个文件!!!这种方式基于引用计数(reference counting),维护着每个文件的硬链接数量。只有当硬链接数为0时,文件系统才会清理并删除文件。这种方式能够确保文件不会被意外删除,只有当没有任何硬链接引用它时,才会被真正删除。
有了上面的理解,我们就可以解释一个现象了:
为什么我创建一个目录,它的默认硬连接数是2?,如下:
[Xq@VM-24-4-centos 12_16]$ ll -i
total 8
1443607 -rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
1443608 -rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$ mkdir bin/
[Xq@VM-24-4-centos 12_16]$ ll -i
total 12
1443609 drwxrwxr-x 2 Xq Xq 4096 Dec 15 14:49 bin // 硬链接为2
1443607 -rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
1443608 -rw-rw-r-- 1 Xq Xq 189 Dec 15 13:08 test.c
[Xq@VM-24-4-centos 12_16]$答案是:每个目录下都会有这个 . 目录,如下所示:
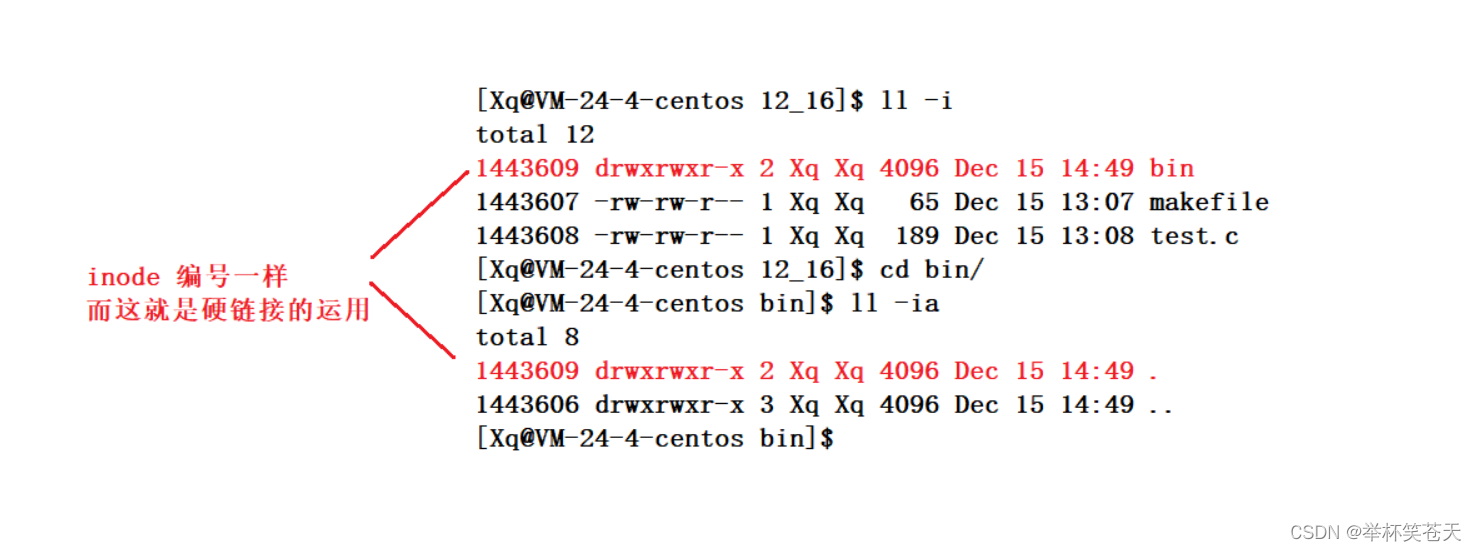
. 我们之前学过,叫做当前目录,它为什么叫做当前目录呢,那是因为这个目录的inode 编号和 bin目录的 inode编号 一样,因此它们指向一个目录;这就是硬链接的常见的应用场景;
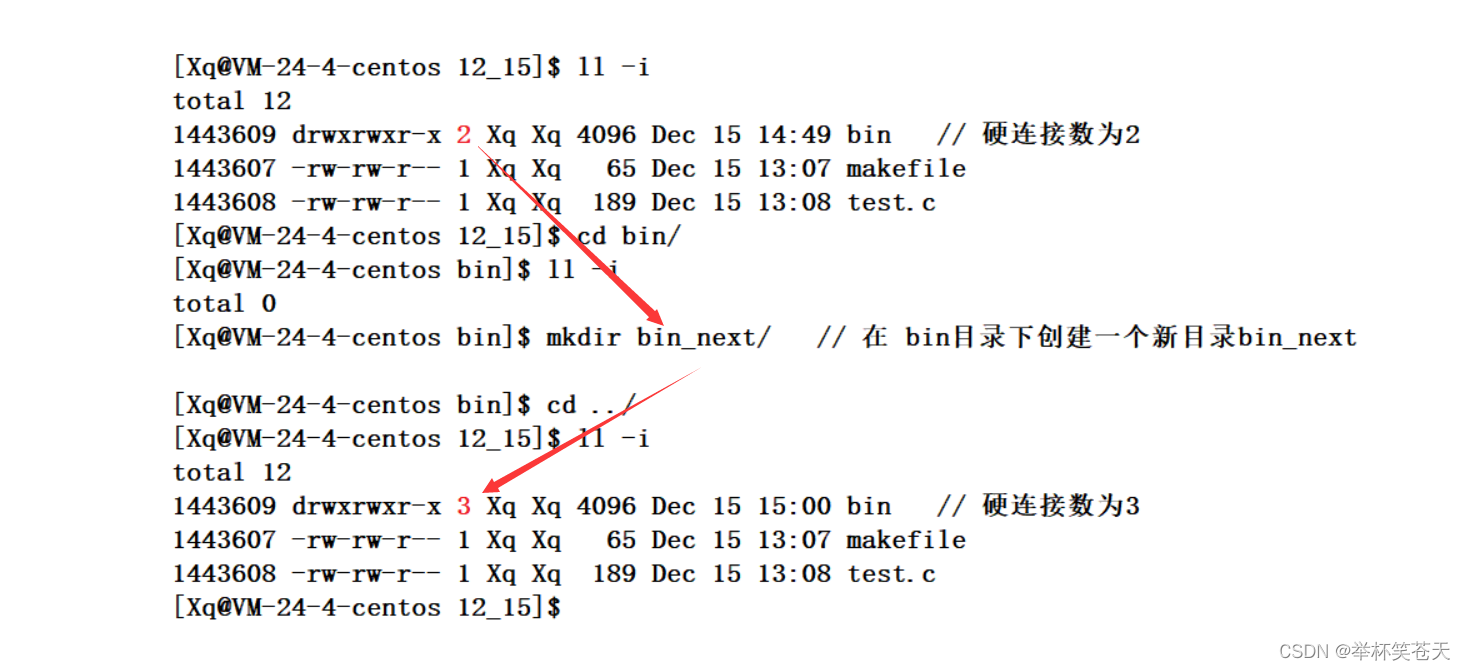
?为什么,在bin目录下创建一个新目录后,此时bin目录的硬连接数变为3了呢?答案是:
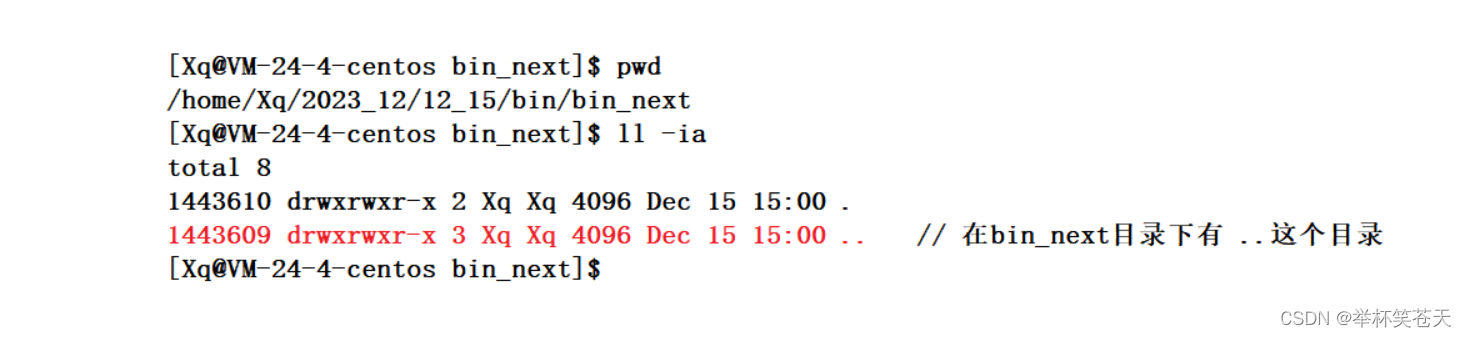
.. 这个我们知道,它代表着当前目录的上级路径,那么在这里就是bin所在的目录了,故bin的硬连接数为3;?
2.4. ACM时间?
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: fd01h/64769d Inode: 920992 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:13:50.890756209 +0800
Modify: 2023-07-31 16:13:50.890756209 +0800
Change: 2023-07-31 16:13:50.890756209 +0800
Birth: -Access: 文件最近被访问的时间
Modiefy:最后一次修改文件内容的时间
Change:最后一次修改文件属性的时间
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 7 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920992 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:16:42.631007790 +0800
Modify: 2023-07-31 16:16:40.873005223 +0800
Change: 2023-07-31 16:16:40.873005223 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ cat test.c // 访问文件
cowsay
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 7 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920992 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:16:42.631007790 +0800
Modify: 2023-07-31 16:16:40.873005223 +0800
Change: 2023-07-31 16:16:40.873005223 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ echo "i am a supercow" > test.c // 修改文件内容
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 16 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920992 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:18:22.631153513 +0800
Modify: 2023-07-31 16:18:21.313151596 +0800
Change: 2023-07-31 16:18:21.313151596 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$
但是为什么我有时候访问文件的时候,Access时间没有立即刷新?有时候又立即刷新了呢?那是因为在较新的Linux内核中,Access时间不会被立即刷新,而是有一定的时间间隔,OS才会自动进行更新Access时间;这样可以一定程度上防止用户和磁盘的频繁交互导致Linxu系统效率降低;
Change:最后一次修改文件属性的时间
[Xq@VM-24-4-centos Tmp]$ ll
total 4
-rw-rw-r-- 1 Xq Xq 10 Jul 31 16:21 test.c
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 10 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920992 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:21:54.648460680 +0800
Modify: 2023-07-31 16:21:52.770457971 +0800
Change: 2023-07-31 16:21:52.770457971 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ chmod u+x test.c //修改文件属性
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 10 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920992 Links: 1
Access: (0764/-rwxrw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:21:54.648460680 +0800
Modify: 2023-07-31 16:21:52.770457971 +0800
Change: 2023-07-31 16:24:29.633683738 +0800 //只有Change时间改变了
Birth: -
[Xq@VM-24-4-centos Tmp]$ ?Modify:最后一次修改文件内容的时间
[Xq@VM-24-4-centos Tmp]$ clear
[Xq@VM-24-4-centos Tmp]$ ll
total 4
-rw-rw-r-- 1 Xq Xq 5 Jul 31 16:21 test.c
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 5 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920992 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:21:18.632408669 +0800
Modify: 2023-07-31 16:21:18.571408581 +0800
Change: 2023-07-31 16:21:18.571408581 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ echo "haha" >> test.c //修改文件内容
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 10 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920992 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:21:54.648460680 +0800
Modify: 2023-07-31 16:21:52.770457971 +0800
Change: 2023-07-31 16:21:52.770457971 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ 修改文件内容,Modify时间确实更改了,但是令人感到奇怪的是为什么Change也改变了呢?
原因是因为,当我们在修改文件内容的时候也有可能会修改文件属性,例如可能会更改文件的大小属性;
[Xq@VM-24-4-centos Tmp]$ ll
total 8
-rw-rw-r-- 1 Xq Xq 58 Jul 31 16:44 makefile
-rw-rw-r-- 1 Xq Xq 67 Jul 31 16:44 test.c
[Xq@VM-24-4-centos Tmp]$ make //第一次可以make
gcc -o test test.c
[Xq@VM-24-4-centos Tmp]$ make //第二次不能make了呢
make: `test' is up to date.
[Xq@VM-24-4-centos Tmp]$ vim test.c //修改test.c的内容
[Xq@VM-24-4-centos Tmp]$ make //又能make了
gcc -o test test.c
[Xq@VM-24-4-centos Tmp]$ make //又不能make了
make: `test' is up to date.
[Xq@VM-24-4-centos Tmp]$ 为什么会出现这种现象呢??我们的gcc是如何判定这个源文件是最新的呢?
[Xq@VM-24-4-centos Tmp]$ stat test.c //源文件的ACM
File: ‘test.c’
Size: 87 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920993 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:44:43.309440972 +0800
Modify: 2023-07-31 16:44:41.890438945 +0800
Change: 2023-07-31 16:44:41.890438945 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ stat test //可执行程序的ACM
File: ‘test’
Size: 8360 Blocks: 24 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920991 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:44:43.642441448 +0800
Modify: 2023-07-31 16:44:43.339441015 +0800
Change: 2023-07-31 16:44:43.339441015 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ 此时这个可执行文件的Modify时间较源文件的Modify更新/相等,gcc认为此时就没有必要再去编译了,因为源文件的内容已经编译完了,没有新的改变。
[Xq@VM-24-4-centos Tmp]$ vim test.c //修改源文件的内容
[Xq@VM-24-4-centos Tmp]$ ls
makefile test test.c
[Xq@VM-24-4-centos Tmp]$ stat test.c //源文件的ACM
File: ‘test.c’
Size: 127 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920993 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:50:54.634968344 +0800
Modify: 2023-07-31 16:50:53.673966987 +0800
Change: 2023-07-31 16:50:53.673966987 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ stat test //可执行文件的ACM
File: ‘test’
Size: 8360 Blocks: 24 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920991 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:44:43.642441448 +0800
Modify: 2023-07-31 16:44:43.339441015 +0800
Change: 2023-07-31 16:44:43.339441015 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ make //此时我们发现可以make了
gcc -o test test.c
[Xq@VM-24-4-centos Tmp]$ 当这个源文件的 Modify 时间比可执行程序?Modify 时间更新的时候,gcc认为此时就有必要对这个源文件重新编译了,此时就可以make了。
[Xq@VM-24-4-centos Tmp]$ ll
total 20
-rw-rw-r-- 1 Xq Xq 58 Jul 31 16:44 makefile
-rwxrwxr-x 1 Xq Xq 8360 Jul 31 16:51 test
-rw-rw-r-- 1 Xq Xq 127 Jul 31 16:50 test.c
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 127 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920993 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:50:54.634968344 +0800
Modify: 2023-07-31 16:50:53.673966987 +0800
Change: 2023-07-31 16:50:53.673966987 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ stat test
File: ‘test’
Size: 8360 Blocks: 24 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920991 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 16:51:06.631985283 +0800
Modify: 2023-07-31 16:51:06.480985070 +0800
Change: 2023-07-31 16:51:06.480985070 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ make
make: `test' is up to date.
//当一个文件存在的情况,touch代表更新这个文件的ACM时间
[Xq@VM-24-4-centos Tmp]$ touch test.c
[Xq@VM-24-4-centos Tmp]$ stat test.c
File: ‘test.c’
Size: 127 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 920993 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1001/ Xq) Gid: ( 1001/ Xq)
Access: 2023-07-31 17:00:29.631773689 +0800
Modify: 2023-07-31 17:00:28.348771906 +0800
Change: 2023-07-31 17:00:28.348771906 +0800
Birth: -
[Xq@VM-24-4-centos Tmp]$ make //此时既可以make了
gcc -o test test.c
[Xq@VM-24-4-centos Tmp]$makefile和gcc会根据ACM时间,来判定源文件和可执行文件谁更新,从而指导操作系统哪些源文件需要被重新编译。
3. 认识并制作动静态库
动态库(Dynamic Library)和静态库(Static Library)是两种不同的库文件形式,它们有以下区别:
1. 静态库:
? ?1.?静态库是在编译时将库文件的代码和数据复制到目标程序中。
? ?2. 静态库以静态链接的方式与目标程序进行链接,链接时将库中需要的代码复制到目标程序中,生成一个包含所有代码的可执行文件。
? ?3.?静态库的优点是易于使用,在编译时已经包含了所有需要的代码,程序执行时不依赖外部库文件。
? ?4.?缺点是会增加最终可执行文件的大小,并且当静态库更新时,需要重新编译使用该库的程序。2. 动态库:
? ?1.?动态库是在进程运行时被加载和链接的库文件。
? ?2.?动态库以动态链接的方式与目标程序进行链接,进程在运行时会动态加载并链接所需的库文件。
? ?3.?动态库的优点是节省内存空间,多个进程可以共享同一个动态库的实例,减少重复代码的加载。
? ?4.?缺点是需要依赖外部的库文件,如果所需的动态库不可用或版本不匹配,进程可能无法正常执行。选择使用静态库还是动态库通常取决于具体的需求和场景。静态库适合于独立运行、较小的应用程序以及需要确保库的版本和稳定性的情况。动态库适合于共享使用、大型应用程序以及允许更新和替换库的情况。
3.1. 认识动静态库
首先有一个问题,我们之前写C/C++的可执行程序,有使用过库吗???
答案:是的,我们使用过库,如何证明呢?
[Xq@VM-24-4-centos 12_15]$ ll
total 20
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
-rwxrwxr-x 1 Xq Xq 8360 Dec 15 15:32 my_test
-rw-rw-r-- 1 Xq Xq 200 Dec 15 15:32 test.c
[Xq@VM-24-4-centos 12_15]$ ldd my_test //ldd显式可执行程序依赖的动态库
linux-vdso.so.1 => (0x00007fffd70fb000)
libc.so.6 => /lib64/libc.so.6 (0x00007f891a7e6000) // C标准库
/lib64/ld-linux-x86-64.so.2 (0x00007f891abb4000)
[Xq@VM-24-4-centos 12_15]$ ll /lib64/libc.so.6
lrwxrwxrwx 1 root root 12 Jul 25 2022 /lib64/libc.so.6 -> libc-2.17.so // 一个软链接
[Xq@VM-24-4-centos 12_15]$ ll /lib64/libc-2.17.so
-rwxr-xr-x 1 root root 2156592 May 19 2022 /lib64/libc-2.17.so //动态库本质上是一个文件
[Xq@VM-24-4-centos 12_15]$ 一般库分为两种:动态库和?静态库
在Linux中,如果是动态库:库文件是以 .so 作为后缀的;
如果是静态库:库文件是以 .a 作为后缀的;动静态库就是一个正常的磁盘文件
库文件的命名规则:lib为库文件的前缀,.a(.so)为静(动)态库的后缀,前缀和后缀之间是库的真实名字。例如这个C标准库?libc-2.17.so ,当去掉lib前缀,去掉动态库的后缀 .so,剩下的就是它的真实名字即?c-2.17;
静态链接和动态链接;
在Linux上,例如C语言,当gcc编译C的源程序的时候,默认情况下,是使用的动态链接,即链接的是C标准的动态库!而如果要采取静态链接的方法,需要加上选项 -static,告诉gcc编译器链接C标准的静态库;如下:
[Xq@VM-24-4-centos 8_1]$ ll
total 8
-rw-rw-r-- 1 Xq Xq 59 Aug 1 18:53 makefile
-rw-rw-r-- 1 Xq Xq 66 Aug 1 18:50 test.c
[Xq@VM-24-4-centos 8_1]$ make
gcc -o test test.c
[Xq@VM-24-4-centos 8_1]$ ll
total 20
-rw-rw-r-- 1 Xq Xq 59 Aug 1 18:53 makefile
-rwxrwxr-x 1 Xq Xq 8360 Aug 1 18:57 test
-rw-rw-r-- 1 Xq Xq 66 Aug 1 18:50 test.c
[Xq@VM-24-4-centos 8_1]$ gcc test.c -o test_static -static // 采取静态链接
[Xq@VM-24-4-centos 8_1]$ ll
total 864
-rw-rw-r-- 1 Xq Xq 59 Aug 1 18:53 makefile
-rwxrwxr-x 1 Xq Xq 8360 Aug 1 18:57 test
-rw-rw-r-- 1 Xq Xq 66 Aug 1 18:50 test.c
-rwxrwxr-x 1 Xq Xq 861288 Aug 1 18:58 test_static
[Xq@VM-24-4-centos 8_1]$ ldd test
linux-vdso.so.1 => (0x00007ffceb2af000)
libc.so.6 => /lib64/libc.so.6 (0x00007f7184b8a000)
/lib64/ld-linux-x86-64.so.2 (0x00007f7184f58000)
[Xq@VM-24-4-centos 8_1]$ file test //共享库
test: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=be7ec904ebefa05706bd6f184f141636f998daaa, not stripped
[Xq@VM-24-4-centos 8_1]$ ldd test_static
not a dynamic executable
[Xq@VM-24-4-centos 8_1]$ file test_static
test_static: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, for GNU/Linux 2.6.32, BuildID[sha1]=55ed29bbb2416686059f3d457ca0367ea6e946bc, not stripped
[Xq@VM-24-4-centos 8_1]$如果没有安装静态库,可以采取如下命令安装C/C++的静态库:
sudo yum install -y glibc-static //C的静态库
sudo yum install -y libstdc++-static //CC的静态库3.2.?静态库的制作
[Xq@VM-24-4-centos lib]$ pwd
/home/Xq/2023_12/12_15/lib
[Xq@VM-24-4-centos lib]$ ll
total 20
-rw-rw-r-- 1 Xq Xq 63 Dec 15 18:51 add.c
-rw-rw-r-- 1 Xq Xq 374 Dec 15 18:54 makefile
-rw-rw-r-- 1 Xq Xq 62 Dec 15 18:58 my_add.h
-rw-rw-r-- 1 Xq Xq 62 Dec 15 17:13 my_sub.h
-rw-rw-r-- 1 Xq Xq 63 Dec 15 18:51 sub.c
[Xq@VM-24-4-centos lib]$ 目标:在lib这个目录下,生成 libmy-math.a 这个静态库!
3.2.1. add.c 文件
#include "my_add.h"
int add(int x, int y)
{
return x + y;
}3.2.2. my_add.h 文件
#pragma once
#include <stdio.h>
extern int add(int x,int y);3.2.3. sub.c?文件
#include "my_sub.h"
int sub(int x,int y)
{
return x - y;
}3.2.4. my_sub.h?文件
#pragma once
#include <stdio.h>
extern int sub(int x,int y);
3.2.5. makefile文件的实现
libmy-math.a:add.o sub.o
ar -rc $@ $^ # ar 是一个归档工具, r --- replace c --- creat,没有就创建,有了就替换
%.o:%.c
gcc -c $< # 将上面所有的源文件一个一个的编写生成 .o 文件
.PHONY:output
output:
mkdir ./output
# my_lib 是 库文件所在的目录
mkdir ./output/my_lib
cp libmy-math.a ./output/my_lib # 将库文件拷贝到 my_lib 中
# my_include 是头文件所在的目录
mkdir ./output/my_include
cp *.h ./output/my_include # 将头文件拷贝到 my_include 中
.PHONY:install
install:
# 头文件gcc的搜索路径: /usr/include
cp ./output/my_include/*.h /usr/include -f
# 库文件的搜索路径是 /lib64
cp ./output/my_lib/libmy-math.a /lib64/ -f
.PHONY:clean
clean:
rm -rf output *.o libmy-math.a%是一个通配符,%.o 可以把当前路径的所有.o文件展开
汇编形成的 .o 叫做可重定向目标文件
%.o:%.c
gcc -c $<:
<的作用就是 将上面的%.c展开后的源文件一个一个的进行编译生成目标文件
*代表通配符 :
rm *.o 代表将当前目录下所有.o文件删除
生成静态库:
ar -rc $@ $$^
ar 是 gnu归档工具,rc表示(replace and create) //没有就创建,有了就替代
查看静态库中的目录列表:
ar -tv ?libmy-math.a
t:列出静态库中的文件
v:verbose 详细信息
测试:
[Xq@VM-24-4-centos lib]$ ll
total 20
-rw-rw-r-- 1 Xq Xq 63 Dec 15 18:51 add.c
-rw-rw-r-- 1 Xq Xq 374 Dec 15 18:54 makefile
-rw-rw-r-- 1 Xq Xq 62 Dec 15 18:58 my_add.h
-rw-rw-r-- 1 Xq Xq 62 Dec 15 17:13 my_sub.h
-rw-rw-r-- 1 Xq Xq 63 Dec 15 18:51 sub.c
[Xq@VM-24-4-centos lib]$
[Xq@VM-24-4-centos lib]$ make //生成对应的.o文件,并将其归档生成库文件本身
gcc -c add.c
gcc -c sub.c
ar -rc libmy-math.a add.o sub.o
[Xq@VM-24-4-centos lib]$ ll
total 32
-rw-rw-r-- 1 Xq Xq 63 Dec 15 18:51 add.c
-rw-rw-r-- 1 Xq Xq 1240 Dec 15 19:03 add.o
-rw-rw-r-- 1 Xq Xq 2688 Dec 15 19:03 libmy-math.a
-rw-rw-r-- 1 Xq Xq 374 Dec 15 18:54 makefile
-rw-rw-r-- 1 Xq Xq 62 Dec 15 18:58 my_add.h
-rw-rw-r-- 1 Xq Xq 62 Dec 15 17:13 my_sub.h
-rw-rw-r-- 1 Xq Xq 63 Dec 15 18:51 sub.c
-rw-rw-r-- 1 Xq Xq 1240 Dec 15 19:03 sub.o
[Xq@VM-24-4-centos lib]$
[Xq@VM-24-4-centos lib]$ make output // 打包到output这个目录
mkdir ./output
mkdir ./output/my_lib
cp libmy-math.a ./output/my_lib
mkdir ./output/my_include
cp *.h ./output/my_include
[Xq@VM-24-4-centos lib]$ ll
total 36
-rw-rw-r-- 1 Xq Xq 63 Dec 15 18:51 add.c
-rw-rw-r-- 1 Xq Xq 1240 Dec 15 19:03 add.o
-rw-rw-r-- 1 Xq Xq 2688 Dec 15 19:03 libmy-math.a
-rw-rw-r-- 1 Xq Xq 374 Dec 15 18:54 makefile
-rw-rw-r-- 1 Xq Xq 62 Dec 15 18:58 my_add.h
-rw-rw-r-- 1 Xq Xq 62 Dec 15 17:13 my_sub.h
drwxrwxr-x 4 Xq Xq 4096 Dec 15 19:04 output
-rw-rw-r-- 1 Xq Xq 63 Dec 15 18:51 sub.c
-rw-rw-r-- 1 Xq Xq 1240 Dec 15 19:03 sub.o
[Xq@VM-24-4-centos lib]$
[Xq@VM-24-4-centos lib]$ tree output/
output/
|-- my_include
| |-- my_add.h
| `-- my_sub.h
`-- my_lib
`-- libmy-math.a
2 directories, 3 files
[Xq@VM-24-4-centos lib]$
[Xq@VM-24-4-centos lib]$ ar -tv ./output/my_lib/libmy-math.a // 查看静态库的内容
rw-rw-r-- 1001/1001 1240 Dec 15 19:03 2023 sub.o
rw-rw-r-- 1001/1001 1240 Dec 15 19:03 2023 add.o
[Xq@VM-24-4-centos lib]$什么的现象符合我们的预期 。
//如果没有ar命令,那么需要我们手动安装:
sudo yum install -y binutils-aarch64-linux-gnu //ar命令安装静态库本质是就是将所有的 .o 文件进行打包,打包后生成的文件称之为库文件,但一个库不仅包含库文件本身,还包含头文件,说明文档等等,而我们在这里将库文件和头文件分别保存到output/my_lib和output/my_include中。
3.3. 静态库的使用
现在我们自己的静态库制作完成,那么如何使用呢?
#include "my_add.h"
#include "my_sub.h"
int main()
{
int left = 10;
int right = 20;
int ret1 = add(left,right);
int ret2 = sub(left,right);
printf("ret1 = %d\n",ret1);
printf("ret2 = %d\n",ret2);
return 0;
}
?现象如下:
[Xq@VM-24-4-centos 12_15]$ gcc -o my_test test.c
test.c:1:20: fatal error: my_add.h: No such file or directory
#include <my_add.h>
^
compilation terminated.
//错误原因: 编译器只会默认在当前目录下找这两个头文件
[Xq@VM-24-4-centos 12_15]$
------------------------------------------------------
//因此需要加上选项 -I 告诉编译器这个库的头文件所在路径
[Xq@VM-24-4-centos 12_15]$ gcc -o my_test test.c -I ./lib/output/my_include/
/tmp/cc9FF66o.o: In function `main':
test.c:(.text+0x21): undefined reference to `add'
test.c:(.text+0x33): undefined reference to `sub'
collect2: error: ld returned 1 exit status
// 但是又发生了链接错误,因为编译器找不到add和sub的实现
// 需要我们显式声明库文件所在的路径
[Xq@VM-24-4-centos 12_15]$
------------------------------------------------------
//因此我们需要告诉gcc,我们的库所在的路径
[Xq@VM-24-4-centos 12_15]$ gcc -o my_test test.c -I ./lib/output/my_include/ -L ./lib/output/my_lib/
/tmp/ccH46v2n.o: In function `main':
test.c:(.text+0x21): undefined reference to `add'
test.c:(.text+0x33): undefined reference to `sub'
collect2: error: ld returned 1 exit status
// 但是很不幸,依然报了链接错误,因为编译器不知道链接
// 哪一个库(有可能这个路径下不止一个库),因此我们要明确库的真实名字
[Xq@VM-24-4-centos 12_15]$
------------------------------------------------------
[Xq@VM-24-4-centos 12_15]$ gcc -o my_test test.c -I ./lib/output/my_include/ -L ./lib/output/my_lib/ -l libmy-math.a
/usr/bin/ld: cannot find -llibmy-math.a
collect2: error: ld returned 1 exit status
//依然报错,gcc不认识这个库的名字,因为库的真实名字是 去掉lib前缀和 .a-(.so-)后缀
[Xq@VM-24-4-centos 12_15]$
------------------------------------------------------
// 要带上库的真实名字
[Xq@VM-24-4-centos 12_15]$ gcc -o my_test test.c -I ./lib/output/my_include/ -L ./lib/output/my_lib/ -l my-math
// 编译成功
[Xq@VM-24-4-centos 12_15]$ ll
total 24
drwxrwxr-x 3 Xq Xq 4096 Dec 15 19:04 lib
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
-rwxrwxr-x 1 Xq Xq 8472 Dec 15 19:09 my_test
-rw-rw-r-- 1 Xq Xq 231 Dec 15 18:55 test.c
[Xq@VM-24-4-centos 12_15]$ ./my_test
ret1 = 30
ret2 = -10
[Xq@VM-24-4-centos 12_15]
解释:
-I(这里是大写的 i) :?指明的是头文件搜索路径
-L :指定库文件搜索路径
-l :在特定搜索路径下,使用哪一个库,即明确库的真实名字!
但是有个问题,我们之前写过的代码,也用了库(eg:C/C++标准库),为什么就没有指明这些选项呢?
这是因为,之前的库在系统的默认路径下: eg:/lib64/,/usr/lib/,/usr/include/等,编译器是可以识别这些路径的,换句话说,如果我不想带这些选项,我是不是可以把对应的库和头文件拷贝到默认路径下;这样是可以的,但是会带来污染问题,尽量不要这样做;上面的过程,也就是一般软件的安装过程;
但是我们在这里测试一下,将我们的头文件拷贝到gcc编译器的默认搜索路径即 /usr/include/下,将库文件拷贝到库文件的默认搜索路径即 /lib64/ 或者 usr/lib64/;如下:
[Xq@VM-24-4-centos lib]$ sudo make install
[sudo] password for Xq:
cp ./output/my_include/*.h /usr/include -f // 拷贝头文件
cp ./output/my_lib/libmy-math.a /lib64/ -f // 拷贝库文件
// 上面这个过程就是软件安装的过程// 上面这个过程就是软件安装的过程
[Xq@VM-24-4-centos 12_15]$ ll /lib64/libmy-math.a
-rw-r--r-- 1 root root 2688 Dec 15 19:13 /lib64/libmy-math.a
[Xq@VM-24-4-centos 12_15]$ ll /usr/include/my_add.h
-rw-r--r-- 1 root root 62 Dec 15 19:13 /usr/include/my_add.h
[Xq@VM-24-4-centos 12_15]$ ll /usr/include/my_sub.h
-rw-r--r-- 1 root root 62 Dec 15 19:13 /usr/include/my_sub.h
[Xq@VM-24-4-centos 12_15]$
// 可以看到,我们成功将库文件和头文件拷贝到了特定目录下
[Xq@VM-24-4-centos 12_15]$ ll
total 12
drwxrwxr-x 3 Xq Xq 4096 Dec 15 19:04 lib
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
-rw-rw-r-- 1 Xq Xq 231 Dec 15 19:16 test.
[Xq@VM-24-4-centos 12_15]$ gcc test.c -o my_test
/tmp/ccWtBaL4.o: In function `main':
test.c:(.text+0x21): undefined reference to `add'
test.c:(.text+0x33): undefined reference to `sub'
collect2: error: ld returned 1 exit status
[Xq@VM-24-4-centos 12_15]$
可是为什么报错了呢???
注意,我们自己写的库是第三方库,该库既不是语言提供的,也不是OS自带的,而是用户自己实现的!因此,当我们将库文件拷贝到系统的默认搜索路径后,编译器并不知道要连接这个库,因此需要我们指明库文件的名字!!!如下:
[Xq@VM-24-4-centos 12_15]$ gcc test.c -o my_test -l my-math // 指明库的真实名字
// 编译成功
[Xq@VM-24-4-centos 12_15]$ ll
total 24
drwxrwxr-x 3 Xq Xq 4096 Dec 15 19:04 lib
-rw-rw-r-- 1 Xq Xq 65 Dec 15 13:07 makefile
-rwxrwxr-x 1 Xq Xq 8472 Dec 15 19:44 my_test
-rw-rw-r-- 1 Xq Xq 231 Dec 15 19:16 test.c
[Xq@VM-24-4-centos 12_15]$ ./my_test
ret1 = 30
ret2 = -10
[Xq@VM-24-4-centos 12_15]$我们在这里是做测试演示这个结果,实际上,我们最好不要将我们写的库拷贝到头文件或者库文件的默认搜索路径,因为这会带来命名污染等其他问题。
3.4. 动态库的制作
shared: 表示生成共享库格式。
fPIC:编译器生成位置无关代码,用于编译动态链接库,确保生成的动态库可以在内存中的任何位置加载和执行,而不会与其他库或代码发生冲突。
3.4.1. add.c 文件
#include "my_add.h"
int add(int x, int y)
{
return x + y;
}3.4.2. my_add.h?文件
#pragma once
#include <stdio.h>
extern int add(int x,int y);3.4.3. sub.c 文件
#include "my_sub.h"
int sub(int x,int y)
{
return x - y;
}3.4.4. my_sub.h?文件
#pragma once
#include <stdio.h>
extern int sub(int x,int y);3.4.5. Makefile 文件的实现?
libmy-math.so:sub.o add.o
gcc -shared -o $@ $^ # -shared就是告诉gcc编译器,我要生产动态库
%.o:%.c
gcc -fPIC -c $< # -fPIC 每一个.o 文件的生成都需要 -fPIC 生成位置无关码
.PHONY:output
output:
mkdir output
mkdir ./output/my_include # 将所有头文件拷贝到 my_include 目录下
cp ./*.h ./output/my_include
mkdir ./output/my_lib # 将库文件拷贝到 my_lib 目录下
cp libmy-math.so ./output/my_lib
.PHONY:install
install:
# 将头文件安装到头文件的默认搜索路径 /usr/include/目录下
cp ./output/my_include/*.h /usr/include/
# 将库文件安装到库文件的默认搜索路径 /lib64/
cp ./output/my_lib/libmy-math.so /lib64/
.PHONY:clean
clean:
rm -rf libmy-math.so *.o output
测试如下:
[Xq@VM-24-4-centos lib]$ ll
total 20
-rw-rw-r-- 1 Xq Xq 63 Dec 16 16:40 add.c
-rw-rw-r-- 1 Xq Xq 388 Dec 16 16:50 Makefile
-rw-rw-r-- 1 Xq Xq 62 Dec 16 16:41 my_add.h
-rw-rw-r-- 1 Xq Xq 62 Dec 16 16:41 my_sub.h
-rw-rw-r-- 1 Xq Xq 63 Dec 16 16:40 sub.c
[Xq@VM-24-4-centos lib]$ make // 生成库文件
gcc -fPIC -c sub.c
gcc -fPIC -c add.c
gcc -shared -o libmy-math.so sub.o add.o
[Xq@VM-24-4-centos lib]$ ll
total 36
-rw-rw-r-- 1 Xq Xq 63 Dec 16 16:40 add.c
-rw-rw-r-- 1 Xq Xq 1240 Dec 16 16:54 add.o
-rwxrwxr-x 1 Xq Xq 7936 Dec 16 16:54 libmy-math.so
-rw-rw-r-- 1 Xq Xq 388 Dec 16 16:50 Makefile
-rw-rw-r-- 1 Xq Xq 62 Dec 16 16:41 my_add.h
-rw-rw-r-- 1 Xq Xq 62 Dec 16 16:41 my_sub.h
-rw-rw-r-- 1 Xq Xq 63 Dec 16 16:40 sub.c
-rw-rw-r-- 1 Xq Xq 1240 Dec 16 16:54 sub.o
[Xq@VM-24-4-centos lib]$ make output // 打包
mkdir output
mkdir ./output/my_include
cp ./*.h ./output/my_include
mkdir ./output/my_lib
cp libmy-math.so ./output/my_lib
[Xq@VM-24-4-centos lib]$ ll
total 40
-rw-rw-r-- 1 Xq Xq 63 Dec 16 16:40 add.c
-rw-rw-r-- 1 Xq Xq 1240 Dec 16 16:54 add.o
-rwxrwxr-x 1 Xq Xq 7936 Dec 16 16:54 libmy-math.so
-rw-rw-r-- 1 Xq Xq 388 Dec 16 16:50 Makefile
-rw-rw-r-- 1 Xq Xq 62 Dec 16 16:41 my_add.h
-rw-rw-r-- 1 Xq Xq 62 Dec 16 16:41 my_sub.h
drwxrwxr-x 4 Xq Xq 4096 Dec 16 16:54 output
-rw-rw-r-- 1 Xq Xq 63 Dec 16 16:40 sub.c
-rw-rw-r-- 1 Xq Xq 1240 Dec 16 16:54 sub.o
[Xq@VM-24-4-centos lib]$ tree output/
output/
|-- my_include
| |-- my_add.h
| `-- my_sub.h
`-- my_lib
`-- libmy-math.so
2 directories, 3 files
[Xq@VM-24-4-centos lib]$符合预期,动态库的制作成功!!
3.5. 动态库的使用
此时我这个test.c想用 ./lib/output 下的方法,那么如何使用呢,即如何使用动态库?
[Xq@VM-24-4-centos 12_16]$ ll
total 4
drwxrwxr-x 3 Xq Xq 4096 Dec 16 16:54 lib
-rw-rw-r-- 1 Xq Xq 0 Dec 16 16:39 test.c
[Xq@VM-24-4-centos 12_16]$ tree
.
|-- lib
| |-- add.c
| |-- add.o
| |-- libmy-math.so
| |-- Makefile
| |-- my_add.h
| |-- my_sub.h
| |-- output
| | |-- my_include
| | | |-- my_add.h
| | | `-- my_sub.h
| | `-- my_lib
| | `-- libmy-math.so
| |-- sub.c
| `-- sub.o
`-- test.c
4 directories, 12 files
[Xq@VM-24-4-centos 12_16]$ 3.5.1. test.c
#include "my_add.h"
#include "my_sub.h"
int main()
{
int left = 10;
int right = 20;
int ret1 = add(left,right);
int ret2 = sub(left,right);
printf("ret1 = %d\n",ret1);
printf("ret2 = %d\n",ret2);
return 0;
}
3.5.2. 使用动态库?
[Xq@VM-24-4-centos 12_16]$ ll
total 8
drwxrwxr-x 3 Xq Xq 4096 Dec 16 18:15 lib
-rw-rw-r-- 1 Xq Xq 230 Dec 16 17:01 test.c
[Xq@VM-24-4-centos 12_16]$ gcc -o my_test test.c
test.c:1:20: fatal error: my_add.h: No such file or directory
#include "my_add.h"
^
compilation terminated.
# 编译报错, gcc 在库文件的默认搜索路径/usr/include找不到所需要的头文件
# 因此我们需要 -I 指源代码所依赖的头文件的路径
[Xq@VM-24-4-centos 12_16]$ gcc -o my_test test.c -I ./lib/output/my_include/
/tmp/ccNz26Vr.o: In function `main':
test.c:(.text+0x21): undefined reference to `add'
test.c:(.text+0x33): undefined reference to `sub'
collect2: error: ld returned 1 exit status
# 链接错误, 在库文件的默认搜索路径找不到我们所依赖的库,即找不到对应方法的实现
# 故我们需要 -L 指明源代码所依赖的库文件的路径
[Xq@VM-24-4-centos 12_16]$ gcc -o my_test test.c -I ./lib/output/my_include/ -L ./lib/output/my_lib/
/tmp/ccErAZ1P.o: In function `main':
test.c:(.text+0x21): undefined reference to `add'
test.c:(.text+0x33): undefined reference to `sub'
collect2: error: ld returned 1 exit status
# 仍然报了链接错误,原因,我们指明的库文件所在的路径下不止一个库
# 因此我们需要用 -l 指明库的真实名字(去掉lib前缀,去掉动态库的.so后缀)
[Xq@VM-24-4-centos 12_16]$ gcc -o my_test test.c -I ./lib/output/my_include/ -L ./lib/output/my_lib/ -l my-math
# 编译链接成功,生成了可执行程序my_test
[Xq@VM-24-4-centos 12_16]$ ll
total 20
drwxrwxr-x 3 Xq Xq 4096 Dec 16 18:15 lib
-rwxrwxr-x 1 Xq Xq 8432 Dec 16 18:17 my_test
-rw-rw-r-- 1 Xq Xq 230 Dec 16 17:01 test.c
[Xq@VM-24-4-centos 12_16]$可以看到,我们通过让该C源代码编译后,链接我们自己实现的动态库生成了我们的可执行程序,可是这个可执行程序可以运行吗???现象如下:
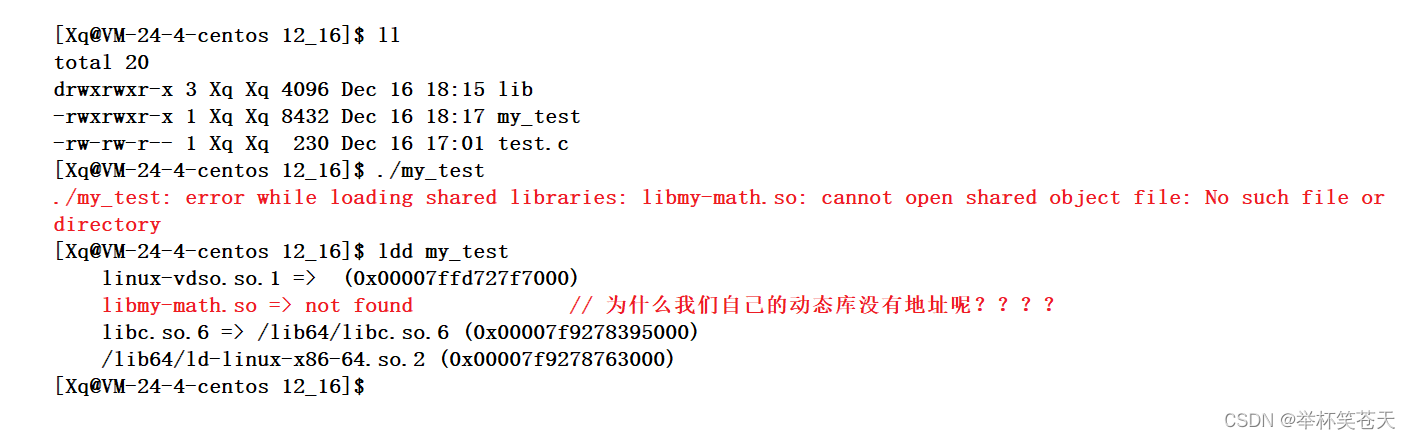
什么情况,为什么这个当可执行程序变为进程后,运行失败了呢??? 从现象来看,我们的动态库是没有地址的,也就是说,当可执行程序变为进程后,找不到我们实现的动态库的地址!!!可是,我们不是在形成可执行程序的时候,指明了我的动态库所在的路径吗???为什么进程运行的时候找不到呢???
?
3.5.3. 动态库的加载
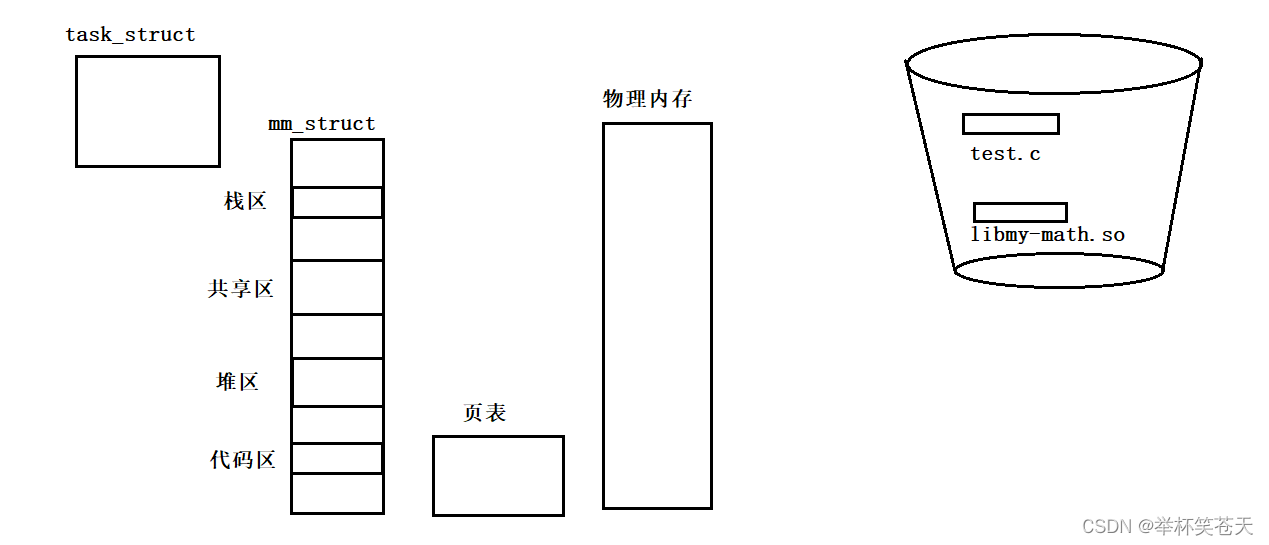
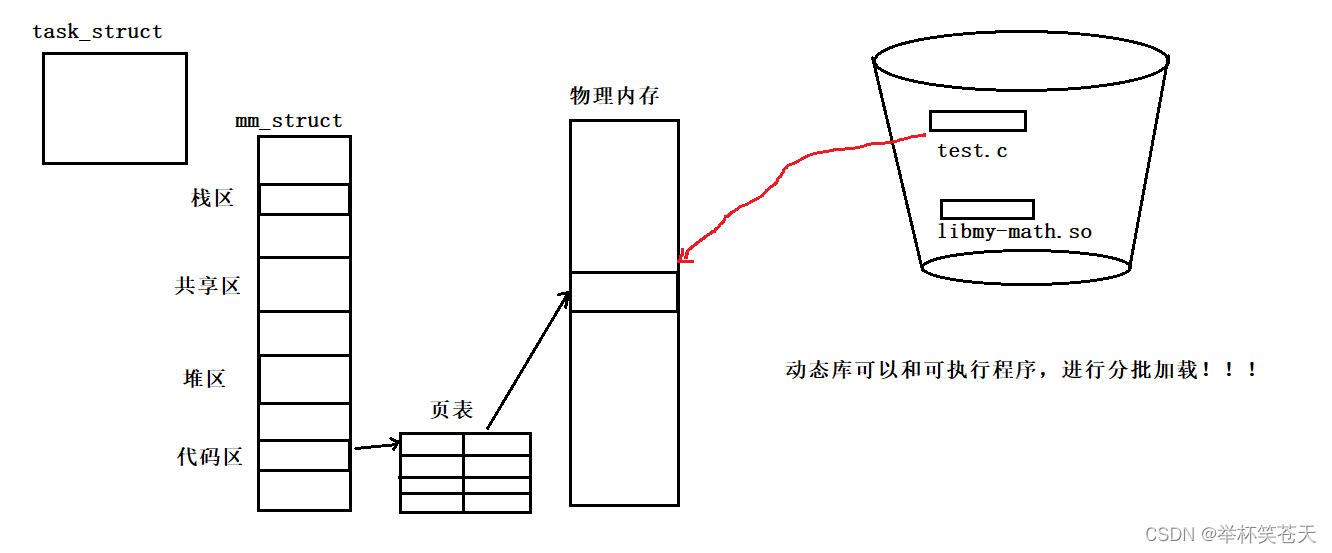
可执行程序本质上是磁盘上的一个二进制文件,而动态库本质上也是磁盘上的一个二进制文件!!即动态库是一个独立的库文件!!!!动态链接的时候,动态库和可执行程序,是进行分批加载的!!!也就是说,会先将 test.c 的代码加载到物理内存中,如图所示:
?
当 test.c 需要调用动态库的方法的时候,此时再将动态库加载到物理内存中!!!
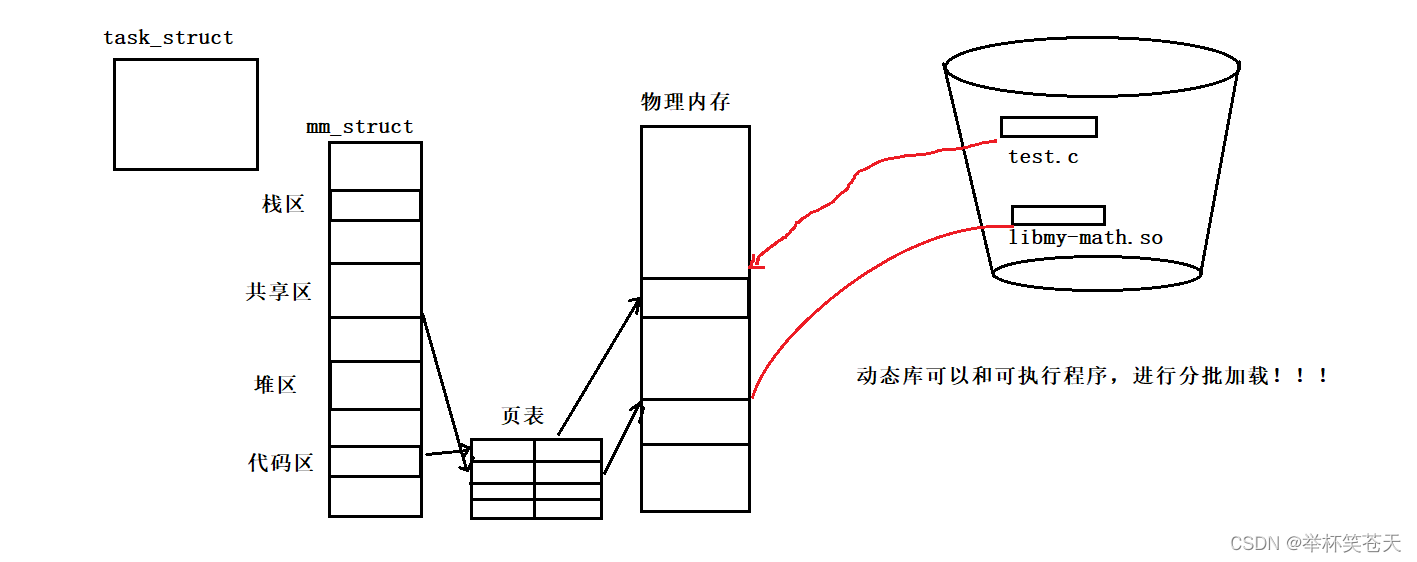
此时当 test.c 要用动态库的实现,那么只需要通过地址跳转,跳到共享区对应的代码实现即可!!!
甚至,这时候,如果其他进程也想用这个动态库的实现,那么此时只需要将物理内存的动态库代码与这些进程的页表构建映射关系即可,那么此时就可以让动态库只被加载一次, 就可以让多个进程共享该库的代码!!!如图所示:;
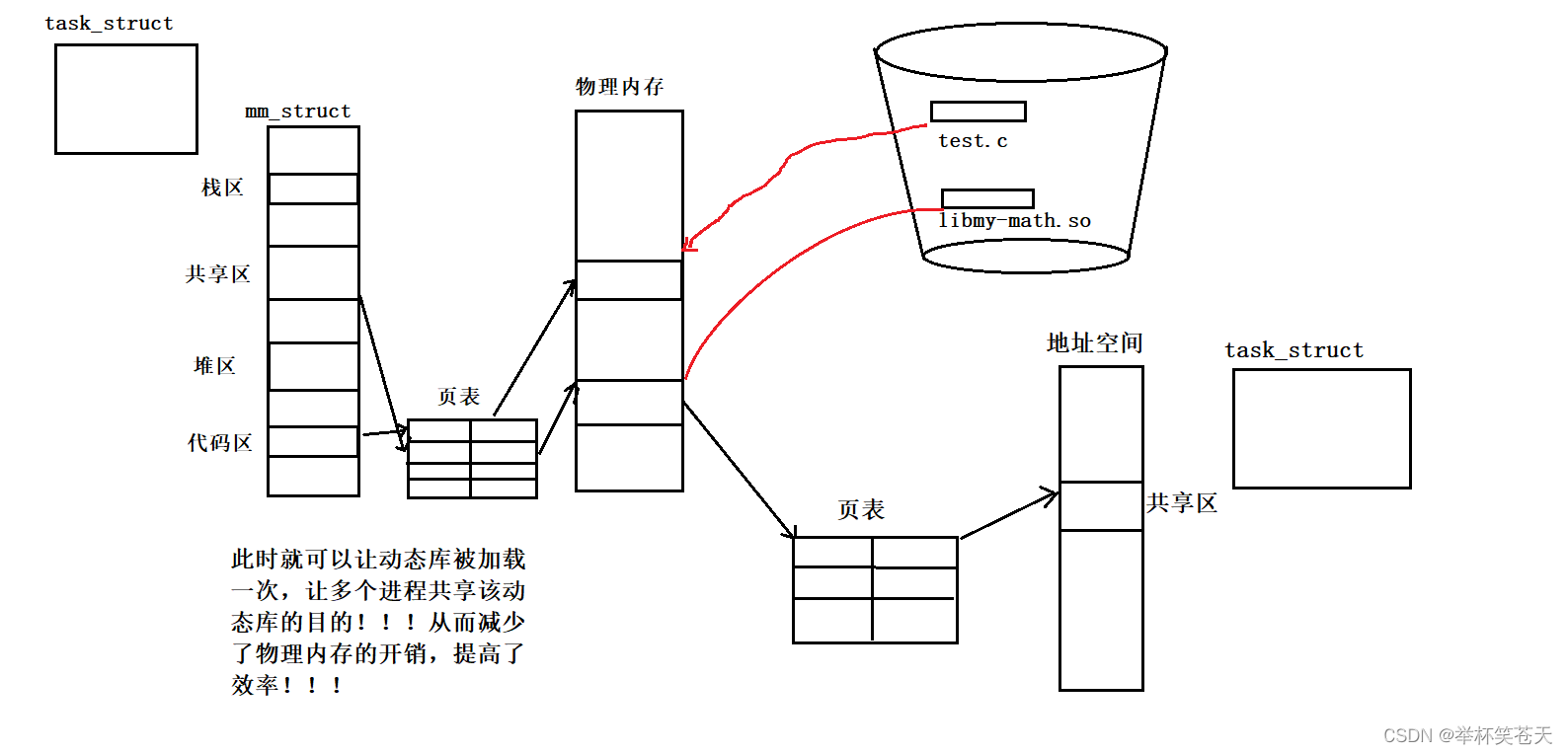
可是,你说了这么多,我们看到的现象是运行失败了啊,为什么呢?首先,我们知道,要加载动态库首先得要知道动态库在哪里,可是,我不是告诉了动态库的的路径吗???
答案是:我们只是告诉了 gcc 编译器我们的动态库的路径,却没有告诉加载器动态库所在的路径啊!!!当我这个进程运行起来,且要使用动态库的方法的时候,需要将该动态库加载到物理内存,而加载这个动作是需要加载器帮助的,并且加载动态库的前提是需要知道动态库所在的路径,可是我们只是将动态库的路径告诉了 gcc 编译器,加载器不知道啊!!! 故加载动态库失败,因此进程运行时找不到动态库的实现,那么报错就合乎情理了,因此,在上面的现象中我们也可以看出,当找不到动态库的时候,就会报类似于 """ cannot open shared object file: No such file or directory "的错误 ;
OK,你说动态库有这样的问题,那为什么静态库没有这种问题呢???
答案是:静态库在编译链接形成可执行程序后,就已将将静态库的实现一并链接到了这个可执行程序中,它将完全独立于静态库的存在,并不依赖于静态库文件的加载和链接。
由于静态库已经包含在可执行程序中,所以可执行程序在运行时不需要加载外部的静态库文件。这使得静态库没有动态库的路径查找和加载的问题。即使静态库文件在运行时被删除或不可用,生成的可执行程序依然可以正常运行,因为它已经包含了所需的静态库的实现。
静态库的优势在于它的便携性和可独立性,在分发可执行程序时不需要担心共享库版本的兼容性问题,但也因此导致了更大的可执行程序体积,且如果多个可执行程序共用了该静态库,可能导致内存中存在着大量的重复的代码,造成空间浪费!!!
好了,你说了这么多,我该如何解决动态库加载和路径查找的问题呢???我们在这里提供三种方法,用于解决动态库的加载和路径查找的问题:
方法一:将动态库文件拷贝到系统库文件的默认搜索路径下
例如: /lib64/或者 /usr/lib/,但不推荐这种做法,太过于粗糙,带来了命名污染问题,甚至是版本不兼容等问题。
方法二:设置LD_LIBRARY_PATH环境变量
LD_LIBRARY_PATH 是一个环境变量,它用于指定动态链接器查找共享库(动态库)时的路径。因此我们的做法就是:将我们实现的动态库所在的路径添加到这个环境变量中,如下:
[Xq@VM-24-4-centos 12_16]$ ll
total 20
drwxrwxr-x 3 Xq Xq 4096 Dec 16 18:15 lib
-rwxrwxr-x 1 Xq Xq 8432 Dec 16 18:17 my_test
-rw-rw-r-- 1 Xq Xq 230 Dec 16 17:01 test.c
[Xq@VM-24-4-centos 12_16]$ ./my_test
./my_test: error while loading shared libraries: libmy-math.so: cannot open shared object file: No such file or directory
// 找不到动态库所在的路径
[Xq@VM-24-4-centos 12_16]$ ldd my_test
linux-vdso.so.1 => (0x00007ffc6b5bc000)
libmy-math.so => not found
libc.so.6 => /lib64/libc.so.6 (0x00007f71bf792000)
/lib64/ld-linux-x86-64.so.2 (0x00007f71bfb60000)
// 查看LD_LIBRARY_PATH 环境变量的内容
[Xq@VM-24-4-centos 12_16]$ echo $LD_LIBRARY_PATH
:/home/Xq/.VimForCpp/vim/bundle/YCM.so/el7.x86_64
[Xq@VM-24-4-centos 12_16]$ tree lib/
lib/
|-- add.c
|-- add.o
|-- libmy-math.so
|-- Makefile
|-- my_add.h
|-- my_sub.h
|-- output
| |-- my_include
| | |-- my_add.h
| | `-- my_sub.h
| `-- my_lib
| `-- libmy-math.so
|-- sub.c
`-- sub.o
3 directories, 11 files
// 导环境变量,将动态库所在的路径添加到LD_LIBRARY_PATH环境变量中
[Xq@VM-24-4-centos 12_16]$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/2023_12/12_16/lib/output/my_lib/
// 添加成功
[Xq@VM-24-4-centos 12_16]$ echo $LD_LIBRARY_PATH
:/home/Xq/.VimForCpp/vim/bundle/YCM.so/el7.x86_64:/home/Xq/2023_12/12_16/lib/output/my_lib/
[Xq@VM-24-4-centos 12_16]$ ldd my_test
linux-vdso.so.1 => (0x00007fff485d3000)
// 此时这个动态库就找到了
libmy-math.so => /home/Xq/2023_12/12_16/lib/output/my_lib/libmy-math.so (0x00007f55bf5d3000)
libc.so.6 => /lib64/libc.so.6 (0x00007f55bf205000)
/lib64/ld-linux-x86-64.so.2 (0x00007f55bf7d5000)
// 可执行程序运行成功
[Xq@VM-24-4-centos 12_16]$ ./my_test
ret1 = 30
ret2 = -10
[Xq@VM-24-4-centos 12_16]$但需要注意的是,我们现在设置的这个环境变量只是内存级别的环境变量,当这个shell关闭后,这个环境变量就会消失!如果想让这个环境变量永久有效,那么需要更改配置文件,?~/.bash_profile 或者 ?~/.bashrc。
方法三:添加配置文件
在 /etc/ld.so.conf.d/ 目录下有一系列的配置文件,在大多数 Linux 系统中,动态链接器使用这些配置文件来指定需要搜索的动态库的路径。
每个配置文件以一行表示一个目录路径,动态链接器将按照配置文件的顺序依次搜索这些路径,以寻找共享库文件。可以在这些配置文件中添加额外的路径,使动态链接器能够找到非默认搜索路径下的动态库。
要注意的是,在修改或创建新的配置文件后,一般需要使用 ldconfig 命令来重新加载动态库配置,以使新的配置文件生效,即刷新动态库缓存;如下:
[Xq@VM-24-4-centos 12_16]$ ll
total 20
drwxrwxr-x 3 Xq Xq 4096 Dec 16 18:15 lib
-rwxrwxr-x 1 Xq Xq 8432 Dec 16 18:17 my_test
-rw-rw-r-- 1 Xq Xq 230 Dec 16 17:01 test.c
[Xq@VM-24-4-centos 12_16]$ ldd my_test
linux-vdso.so.1 => (0x00007fffe85c0000)
libmy-math.so => not found
libc.so.6 => /lib64/libc.so.6 (0x00007fb27425c000)
/lib64/ld-linux-x86-64.so.2 (0x00007fb27462a000)
// LD_LIBRARY_PATH这个环境变量是没有这个动态库的路径的
[Xq@VM-24-4-centos 12_16]$ echo $LD_LIBRARY_PATH
:/home/Xq/.VimForCpp/vim/bundle/YCM.so/el7.x86_64
[Xq@VM-24-4-centos 12_16]$ ll /home/Xq/2023_12/12_16/lib/output/my_lib/
total 8
-rwxrwxr-x 1 Xq Xq 7936 Dec 16 18:15 libmy-math.so
// 在/etc/ld.so.conf.d这个目录下新建一个配置文件
[Xq@VM-24-4-centos 12_16]$ sudo touch /etc/ld.so.conf.d/Xq.conf
// 将我这个动态库的绝对路径写入这个配置文件Xq.conf即可
[Xq@VM-24-4-centos 12_16]$ sudo vim /etc/ld.so.conf.d/Xq.conf
// 写入成功
[Xq@VM-24-4-centos 12_16]$ cat /etc/ld.so.conf.d/Xq.conf
/home/Xq/2023_12/12_16/lib/output/my_lib/
// 刷新动态库缓存,让Xq.conf这个新的配置文件生效
[Xq@VM-24-4-centos 12_16]$ sudo ldconfig
[Xq@VM-24-4-centos 12_16]$ ldd my_test
linux-vdso.so.1 => (0x00007ffd9fb81000)
// 此时这个动态库就有路径了
libmy-math.so => /home/Xq/2023_12/12_16/lib/output/my_lib/libmy-math.so (0x00007f85550d4000)
libc.so.6 => /lib64/libc.so.6 (0x00007f8554d06000)
/lib64/ld-linux-x86-64.so.2 (0x00007f85552d6000)
// 运行成功
[Xq@VM-24-4-centos 12_16]$ ./my_test
ret1 = 30
ret2 = -10
[Xq@VM-24-4-centos 12_16]$注意,只有这个配置文件存在,那么这个动态库的路径就可以找到,也就是说,即使这次将shell关闭,重新打开一个shell,也不会影响动态链接器找到这个动态库的路径!!!
方法四:利用软链接
软链接(Symbolic link,也称为符号链接或软链接)是一个指向目标文件或目录的特殊文件。它包含了指向目标文件或目录的路径信息。
软链接这种方法同样不推荐使用,但是在这里主要是看看软链接如何使用的,如下:
[Xq@VM-24-4-centos 12_16]$ ll
total 20
drwxrwxr-x 3 Xq Xq 4096 Dec 16 18:15 lib
-rwxrwxr-x 1 Xq Xq 8432 Dec 16 18:17 my_test
-rw-rw-r-- 1 Xq Xq 230 Dec 16 17:01 test.c
[Xq@VM-24-4-centos 12_16]$ ldd my_test
linux-vdso.so.1 => (0x00007fff74990000)
libmy-math.so => not found
libc.so.6 => /lib64/libc.so.6 (0x00007f1ae7d99000)
/lib64/ld-linux-x86-64.so.2 (0x00007f1ae8167000)
// 在库文件的默认搜索路径 /lib64/ 下创建软链接 libmy-math.so,
[Xq@VM-24-4-centos 12_16]$ sudo ln -s /home/Xq/2023_12/12_16/lib/output/my_lib/libmy-math.so /lib64/libmy-math.so
[sudo] password for Xq:
// 创建成功
[Xq@VM-24-4-centos 12_16]$ ll /lib64/libmy-math.so
lrwxrwxrwx 1 root root 54 Dec 16 20:46 /lib64/libmy-math.so -> /home/Xq/2023_12/12_16/lib/output/my_lib/libmy-math.so
// 此时 加载器就可以找到该动态库的地址了
[Xq@VM-24-4-centos 12_16]$ ldd my_test
linux-vdso.so.1 => (0x00007ffe08bb2000)
libmy-math.so => /lib64/libmy-math.so (0x00007fb6bd6bf000)
libc.so.6 => /lib64/libc.so.6 (0x00007fb6bd2f1000)
/lib64/ld-linux-x86-64.so.2 (0x00007fb6bd8c1000)
// 运行成功
[Xq@VM-24-4-centos 12_16]$ ./my_test
ret1 = 30
ret2 = -10
[Xq@VM-24-4-centos 12_16]$至此,我们提供了四种方案解决动态库加载和路径查找的问题!!!
补充:
动态链接器(Dynamic Linker)也被称为加载器(Loader)。
动态链接器是操作系统的一部分,负责在进程运行时将动态库加载到内存中,并将进程与这些库进行链接。它的主要任务是解析和处理程序中对动态库的引用,将动态库的代码和数据加载到合适的内存地址,并完成地址重定位、符号解析等操作,以实现动态链接的过程。
加载器(Loader)是一个更广泛的术语,涵盖了动态链接器和其他类型的加载器。加载器的主要目标是从存储介质(如硬盘)中将可执行文件加载到内存中,并执行它们。因此,加载器还包括操作系统中负责加载可执行文件的静态链接器、装载器(Loader)、执行器(Executor)等。而动态链接器是加载器的一个特定类型,用于处理动态链接的情况。
总的来说,动态链接器是加载器的一个子集,其在程序运行时负责加载动态库并进行链接。加载器是一个更广义的术语,包括了动态链接器在内,负责将可执行文件加载到内存并执行。
a. 如果我们只有静态库,没办法,gcc只能针对该库进行静态链接;
b. 如果动静态库同时存在,gcc 默认链接的就是动态库;
c. 如果动静态库同时存在,我非要链接静态库呢 ?那么就需要带上 -static 选项,告诉 gcc 编译器,编译时采用静态链接,因此 -static 的意义:摒弃默认优先链接动态库的原则,而直接链接静态库的方案!!!我们在C/C++中,为什么有时候写代码的时候,有时候在 .h 放上声明,在 .c/.cpp 放上实现?为什么要这么设计呢?
一方面是方便维护,但最主要的是为了方便我们制作库;但如果是开源的,那么可以将实现和声明放在一起;
库的存在一方面是方便使用,可以大大减少我们开发的周期,提高软件自身的质量;另一方面是私密,安全,不想暴露源文件的实现细节!!!? ? ? ? ? ? ?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!