pandas.DataFrame() 数据自动写入Excel
2024-01-08 20:34:25
DataFrame 表格数据格式 ;
to_excel 写入Excel数据;
read_excel 阅读 Excel数据函数
import pandas as pd
#df2 = pd.DataFrame({'neme': ['zhangsan', 'lisi', 3]})
df1 = pd.DataFrame({'One': [1, 2, 3],'name': ['zhangsan', 'lisi', 3]})#One是列明,123是列下面值
df1.to_excel('excel2.xlsx', sheet_name='Sheet1', index=False) # index false为不写入索引;excel1.xlsx有直接写入,没有先创建excel1.xlsx
print('df1\n',df1)
sheet1 =pd.read_excel('excel2.xlsx', sheet_name='Sheet1')
print('sheet1\n',sheet1)
这里有一个问题,当自动创建excel1.xlsx,并且刚开始只有一列one;再想再后面加一列name,
跑完代码,发现name这列,在excel1.xlsx的sheet1中看不到,代码中打印可能看到name这列。
直到我删除excel1.xlsx文件,并且把excel1.xlsx改成excel2.xlsx 再跑代码,才能看到后加的列
name。
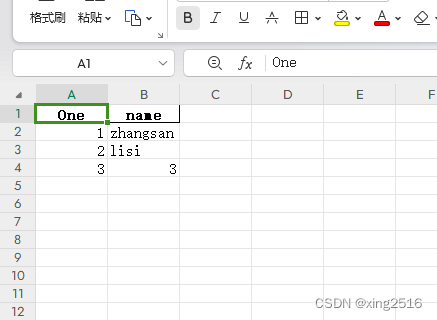
打印显示:
df1
One name
0 1 zhangsan
1 2 lisi
2 3 3
sheet1
One name
0 1 zhangsan
1 2 lisi
2 3 3
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
print('df***\n',df)
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print(df)
# '''
# df***
# Name Age
# 0 Alex 10
# 1 Bob 12
# 2 Clarke 13
# Name Age
# rank1 Tom 28
# rank2 Jack 34
# rank3 Steve 29
# rank4 Ricky 42
# '''
文章来源:https://blog.csdn.net/xing2516/article/details/135388135
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!