Exploiting Temporal Context for Tiny Object Detection(WACV2023)

文章目录
hh
Abstract
在监视应用中,微小、低分辨率物体的检测仍然是一项具有挑战性的任务。大多数深度学习目标检测方法依赖于从静止图像中提取的外观特征,难以准确检测微小物体。
在本文中,作者通过利用静态摄像机记录的视频序列中可用的时间上下文,解决了实时监控应用中微小物体检测的问题。
作者提出了一个基于YOLOv5的时空深度学习模型,该模型通过一次处理帧序列来利用时间上下文。此外,提出了一种使用帧差作为显式运动信息的双流架构,进一步提高了对大小为4 × 4像素的运动物体的检测。
作者的方法在准确性和推理速度上超过了以前在公共WPAFB WAMI数据集上的工作,也超过了以前在嵌入式NVIDIA Jet- son Nano部署上的工作。作者得出结论,在深度学习目标检测器中添加时间上下文是一种有效的方法,可以大大提高静态视频中微小运动物体的检测。
Introduction
在本文中,我们的目标是通过允许深度学习目标检测模型利用时间信息来结合深度学习和MOD(移动目标检测)方法的优点。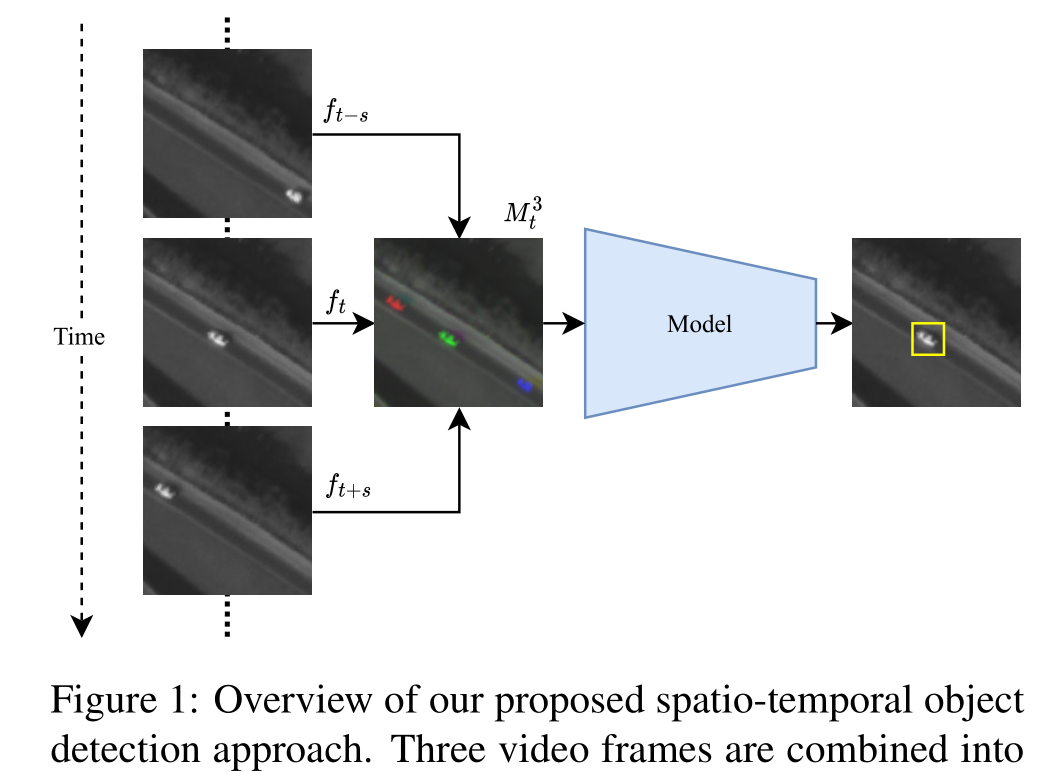
作者提出的时空目标检测方法概述。三个视频帧被组合成一个3通道图像。深度学习对象检测器通过利用时间上下文来检测对象。
在实时YOLOv5检测器的基础上,我们提出了单流和双流时空检测器,它们不需要像光流模块[56]、长短期记忆(LSTM)层[11]或跟踪器模块[4]那样在模型架构中添加计算成本高昂的组件。与MOD方法相反,我们的方法也允许检测静止物体。
Contribution
?介绍了一种基于YOLOv5的时空检测器。该模型利用时间上下文来提高对微小运动物体的检测,而不会降低对静止物体的检测性能。
?提出了一种利用帧差提取显式运动信息的双流结构,进一步增强了对运动物体的检测。
?实验在公共WPAFB WAMI以及自己记录的行人检测数据集上进行。所提出的方法优于先前的工作,在小于4 × 4像素的微小物体上表现出令人印象深刻的性能。
?在嵌入式NVIDIA Jet- son Nano平台上,评估了各种模型架构尺寸,并显示其在准确性和推理时间方面优于先前的工作。
Related Work
非深度学习MOD算法已被广泛应用于广域运动图像(WAMI)数据中的微小目标检测。这些方法通常基于帧差[20]或背景减法[29]。帧差技术计算帧之间逐像素的强度差,以突出显示移动的物体。背景减法将当前帧与创建的背景模型进行比较,以检测差异。使用10张连续图像序列的中值图像被发现是一种准确的去除背景噪声的方法[36]。然而,计算昂贵的技术,如图匹配[47]被用来检测和跟踪运动的物体。这些方法的缺点是需要精确的帧配准以及对噪声和视差影响的敏感性。此外,这些方法无法检测静止物体[40]。
为了利用视频数据中的时间上下文,视频目标检测(VOD)方法通常使用特征聚合来组合来自多个帧的目标特征。FFAVOD[30]通过使用1 × 1卷积神经网络(CNN)层合并目标帧周围序列帧的特征来实现特征聚合。FGFA[56]使用光流矢量扭曲采样帧,使其与目标帧重叠。在MEGA[12]中,通过从完整的80个视频序列中采样帧来使用全局视频上下文。这些方法被发现可以提高ImageNet-VID[37]数据集的性能,模型能够更好地处理运动模糊、罕见物体姿势和遮挡等挑战。然而,之前的研究发现,这些方法不能很好地转化为TOD数据集,由于TOD数据集的小尺寸,很难将多个帧的目标特征关联起来[4]。
因此,为TOD应用设计的时空模型通常采用不同的技术。Cluster- Net[21]通过叠加5个灰度帧,用两阶段CNN模型通过粗到精的方法对其进行处理,生成一个对象热图。第一阶段的目标是在输入图像中找到预期运动物体的一般区域。这些区域由第二个CNN进一步处理以定位单个物体。该方法在WPAFB 2009 WAMI数据集上的表现优于以往的MOD方法[1],显示了时空方法在TOD应用中的潜力。Track- Net[17]在运动应用中使用类似的基于热图的方法来进行击球位置。它使用三张RGB图像的堆栈,这些图像由二维CNN网络处理,以检测快速移动的小物体。使用反卷积网络生成目标位置热图。T-RexNet[7]是一个用于嵌入式应用的时空TOD模型。它通过显式帧差提取三帧的运动信息,突出显示模型的帧差。在此之后,它使用两个CNN流来处理外观和运动数据。
受时空TOD方法的启发,我们通过多帧输入将时间背景引入到YOLOv5目标检测器中。我们的方法使用标准的目标检测模型架构实现时空目标检测,并且不需要基于热图的输出或计算昂贵的特征聚合模块。
Methods
YOLOv5 Overview
该模型使用CSP- Darknet53骨干网[44,3]和PANet[25]架构来提供多尺度检测。主干和头部结构都由跨级部分[44]C3模块组成。通过调整C3模块中的通道数量(宽度)和网络中此类模块的数量(深度),可以扩展该架构以平衡推理速度和检测精度。我们采用了YOLOv5x架构,因为它具有很高的检测精度。
T-YOLOv5: Exploit Temporal Context
为了将时间背景引入到模型中,通过从视频序列中连续采样三帧,使用多帧模型输入。对于每个当前帧ft,两个额外的支持帧ft - s, ft +s与时间帧移位s进行采样。由视频边界引起的边缘情况通过复制当前帧ft来处理。通过从每帧中提取单个灰度通道并将其堆叠,将三帧预处理成一个3通道图像m3t。最终输入图像的三个通道定义为: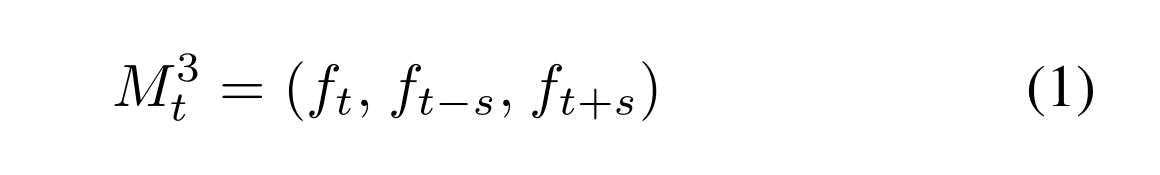
通过将时序帧嵌入到输入图像的通道中,可以利用三通道RGB图像的标准二维CNN模型架构。该模型被训练为输出相对于中间帧f定位的边界框检测,并且不需要标记额外的支持帧。我们的方法将颜色信息交换为时间上下文,我们认为这对于微小物体检测是值得的。
在训练过程中,为了提高数据集的多样性,我们应用了数据增强技术。在此基础上,我们提出了一种时序数据增强技术(Temporal Data Augmentation),将针对静态图像的传统增强方法适应到时空检测领域。
通过时序数据增强技术,对采样的所有输入帧均等应用相同的增强策略,确保采样帧之间的绝对差异保持不变。对于那些需要结合其他数据样本进行增强的方法(例如MixUp[52]和Mosaic[3]),我们将随机选取具有相同时间偏移量的序列,并将其与原始序列相结合。
对于时序Mosaic增强(Temporal Mosaic Augmentation),我们会额外随机抽取三个序列,并按通道进行Mosaic拼接。这些Mosaic图像会进一步接受数据增强操作,其中相同的增强方式会被应用于每个Mosaic图像上。最后,将增强后的结果图像合并,从而将时序信息整合进模型的输入中,以提升模型处理连续帧序列的能力及泛化性能。
T-YOLOv5(Temporal YOLOv5)适用于静态摄像头监控应用的原因在于其能够有效地利用时序信息处理连续的视频帧。在静态摄像头场景下,背景相对稳定不变,只有目标物体在移动,这使得相邻帧之间运动物体的位置变化非常明显。通过分析连续帧之间的差异,T-YOLOv5模型可以聚焦于这些由于位置改变而产生的显著性变化,并从中提取出时序特征,进而更准确地检测到移动物体,无论是快速移动还是缓慢移动的物体,甚至是短暂静止后重新移动的物体。
此外,因为该模型不需要预先计算复杂的光流场或者显式的运动特征,而是直接对原始视频帧进行处理,所以在资源有限、实时性要求高的应用场景如安防监控中,具有很好的实用性。它不仅能减少额外计算开销,还能够适应各种光照和环境条件的变化,提高对复杂监控场景中动静态物体检测的鲁棒性和准确性。
T2-YOLOv5: Two-Stream Approach
使用帧序列输入允许我们的模型使用运动信息来检测对象。为了进一步增强这种能力,我们在模型中添加了第二个流,该流的任务是生成仅运动的特征,遵循T-RexNet[7]提出的方法。额外的流允许模型的一部分专门化以从仅运动的图像中提取特征。通过计算输入帧的绝对差来生成图像,提取的运动特征随后与主流的外观特征相结合,后者处理原始输入帧。第二流的输入图像m2t是关键帧和支撑帧之间的2通道绝对帧差: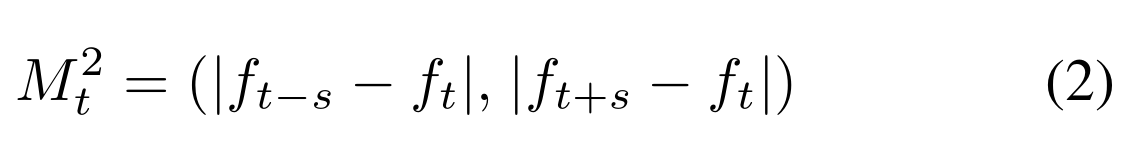
如图所示,第二流使用了YOLOv5s模型骨架,以避免大量的计算开销。由于YOLOv5在三种不同的特征映射尺度上预测边界框,来自运动流的特征与主流的特征在每个尺度上使用连接块组合在一起,这允许所有检测输出头使用仅运动的特征。

T2-YOLOv5架构。通过帧差提取的显式运动信息由第二运动流处理。提取的特征在P3 ~ P5三个检测尺度上进行组合。
Conclusion
这项工作表明,包含时间上下文是一种有效的技术,可以提高深度学习目标检测器的微小目标检测性能。作者提出了一个基于YOLOv5的时空网络,用于空中监视和人员检测应用,该方法通过使用三个时间灰度通道作为模型输入,使检测器能够利用时间上下文。此外,作者提出了一种双流网络,仅利用帧差提取的运动信息来增强对微小运动物体的检测。
作者的方法被证明优于之前在WPAFB 2009数据集上的工作。此外,在静止图像YOLOv5基线的基础上,对微小运动目标的检测得到了改善,而对静止目标的检测性能没有下降。作者的方法可扩展到各种网络架构大小,在准确性和推理速度方面超过适合嵌入式应用的竞争检测器。此外,静止图像基线在作者记录的行人检测数据集上被超越,显示了作者方法的通用性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!