(11)Linux 进程以及进程控制块PCB
前言:章我们将带着大家深入理解 "进程" 的概念,"进程" 这个概念其实使我们一直在接触,只不过这个概念我们没有进行详细讲解罢了,本章我们就把 "进程" 好好地深入理解一番!引出进程的概念后,我们最后再讲解一下 PCB,针对什么是 PCB 以及为什么要有 PCB 等一系列问题进行讲解。
?进程的概念(Process)
什么是进程??
进程是一个运行起来的程序。?
什么是运行起来的程序呢,跑或没跑?跑起来的程序,和没跑起来的程序?我们不放首先来思考一个问题:
?思考:程序是文件吗?
是!文件在磁盘。一开始讲的冯诺依曼,磁盘就是外设,和内存与 CPU 打交道,它们之间有数据交互。你的程序最后要被 CPU 运行,所以要运行起来必须先从磁盘外设加载到内存中。因此,当可执行文件被加载到内存中时,该程序就成为了一个进程。
?先描述再组织
思考:操作系统中可能存在多个进程吗??
操作系统里面可能同时存在大量的进程!
既然如此,那操作系统要不要将所以后的进程管理起来呢?
当然要,不要不就乱套了?当前想调用哪个进程,想让哪个进程占用 CPU 资源,
想执行哪个资源,数据一大你不管怎么行?所以我们刚才再次讲解了操作系统管理的概念:
被管理对象的管理本质上是对数据的管理。那么 对进程的管理,本质上就是对进程数据的管理。
所以还是那句话 —— 我们需要 先描述再组织。
所以,当一个程序加载到内存时,操作系统做的不仅仅只是把代码和数据加入到内存,
还要管理进程,创建对应的数据结构。我们讲的是 Linux 操作系统,
Linux 操作系统的内核是 C 语言写的,所以我们管理进程,就要先描述再组织。
进程控制块(PCB)?
/* Process Ctrl Block */
struct task_struct {
进程的所有属性数据
};在操作系统中,我们把描述进程的结构体称为??(Process Ctrl Block) 。
在很多教材中,会把??称为 进程控制块。
想要管理就必须要 "先描述再组织" 。所以每个进程都要有? (task_struct)。
为什么我们的?task_struct 每个进程都要有呢?
因为这是为了管理进程而描述进程所设计的结构体类型,将来当有一个进程加载到内存时,
操作系统在内核中一定要为该进程创建 task_struct 结构体变量,并且要将该变量链入到全局的链表当中。要删掉一个进程,实际上就是遍历所有的链表结点,把对应进程的PCB和代码都释放掉,这就叫对链表做管理。最终你会发现,操作系统对进程的管理,最终变成了对链表的增删查改。
什么是进程?目前为止我们可以总结成:进程 = 可执行程序 + 该进程对应的内核数据结构?
系统接口
OS 为什么要给我们提供服务呢?因为计算机和 OS 设计出来就是为了给人提供服务的。
printf or cout??向显示器打印,显示器是硬件?
所谓的打印,本质就是将数据写到硬件。
你自己的 C 程序,有资格向硬件写入吗?你是没有资格这么做的。
操作系统不相信任何人的,不会直接暴露自己的任何数据结构,代码逻辑,其他数据相关的细节。
想做系统是通过 系统调用 的方式,对外提供接口服务的。
Linux 操作系统是用C语言写的,这里所谓的 "接口",本质就是C函数。
我们学习系统编程,本质上就是学习这里的系统接口。
?进程查看
通过指令查看进程?
我们先创建一个 mytest.c 文件,然后写上一个死循环,每隔1秒就打印一句话:?
 ?生成 mytest 可执行文件后,使用 ldd 和 file 去查看:
?生成 mytest 可执行文件后,使用 ldd 和 file 去查看:

对我们来说,既然它是 executable 那么就是可执行文件,它就是在磁盘上放着。
而我们使用的是云服务器,所以不是在你自己电脑的磁盘上,而是在云服务器的磁盘上放着。
接下来我们 ./mytest 去运行它,此时这个程序就变成了一个进程:

那么此时,在系统中我们可以使用? ps ?查看进程:
$ ps aux
$ ps ajx
/* 含义 */
1)ps a 显示现行终端机下的所有程序,包括其他用户的程序。
2)ps -A 显示所有程序。
3)ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
4)ps -e 此参数的效果和指定"A"参数相同。
5)ps e 列出程序时,显示每个程序所使用的环境变量。
6)ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
7)ps -H 显示树状结构,表示程序间的相互关系。
8)ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
9)ps s 采用程序信号的格式显示程序状况。
10)ps S 列出程序时,包括已中断的子程序资料。
11)ps -t <终端机编号> 指定终端机编号,并列出属于该终端机的程序的状况。
12)ps u 以用户为主的格式来显示程序状况。
13)ps x 显示所有程序,不以终端机来区分。
14)ps -l 显示详细PID信息?我们使用ps aux进行演示:
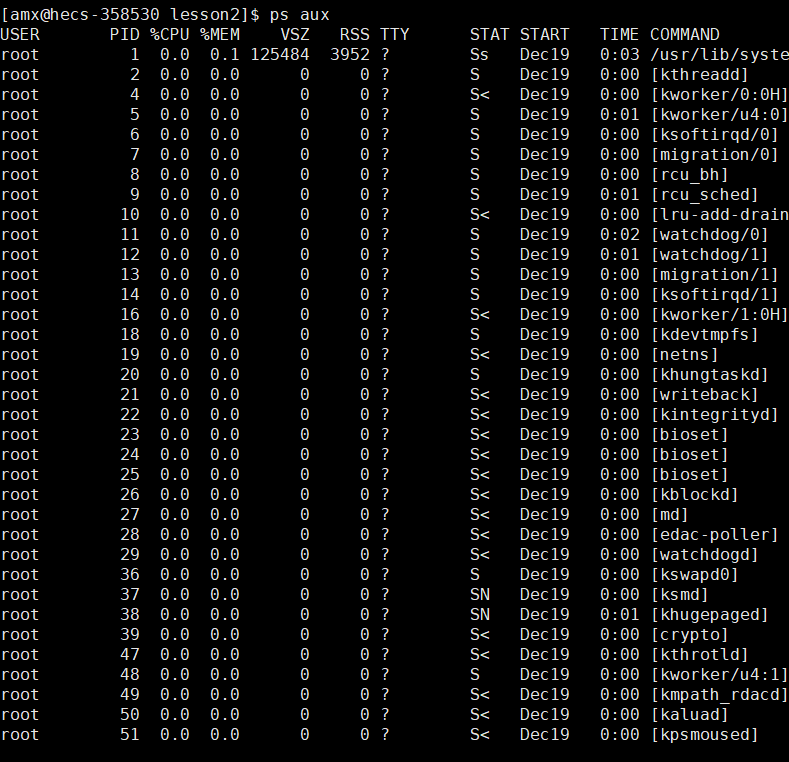
此时他就会将你系统中所有的进程显示出来,这些都是系统中所对应的相关启动进程。
我们刚才直接使用?ps aux??打出来的都是以行为单位,如何我想查看我们刚才的 mytest 进程呢?
我们可以尝试使用 grep 抓一下:
$ ps aux | grep 'mytest'
?怎么这里有个grep呢?
这个指令是你写的吗?肯定不是
它们存在于/usr/bin/目录下
曾经我们执行的所有指令,今天要换种说法了——————进程。
本质上他们也是进程,所以我们看得见。
如果你不想见到 ?进程,你就把 grep 关键字屏蔽掉就行:
$ ps aux | grep 'mytest' | grep -v grep看到这里,你应该能发现了,其实没有什么神奇的,就相当于所有的指令是进程而已。
通过 proc 目录查看进程信息?
上面我们讲述了查看进程的第一种方式,即最常用的 ps aux 。
下面我们要来讲解第二种方式,在讲解之前我们先来探讨一下 "当前路径"
ls /![]()
?proc:内存文件系统,里面放的是当前系统实时的 进程信息。
既然如此,现在我们就用 ls /proc看一下我们的 process 进程信息:

乱七八糟的,蓝色标出的是目录……
此时我们要先引入一个新的概念:进程 pid??(process id)
进程 ID(pid)?
上面的这些蓝色的数字,实际上就是进程的 ?,这个我们讲完 proc之后会说。
每一个进程在系统中,都会存在一个惟一的标识符!
这就如同每个人都有身份证号一样,进程也需要标号的,所以每个进程都存在有一个?。
我们的 mytest 现在还在后台欢快的跑着呢,此时我们可以把所有的 title 列名称显示出来:
ps aux | head -1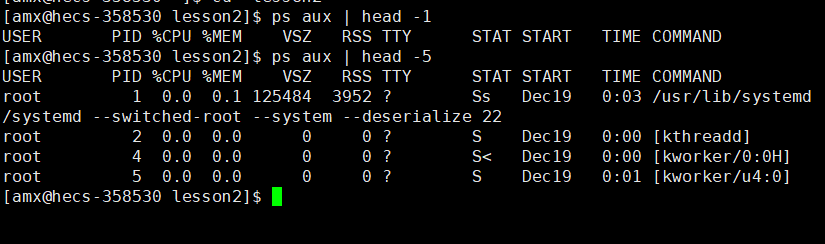
此时我们成功把属性提取出来了,我们使用 && 进行下一步操作
(逻辑与,前面指令成功再执行下面的指令)
ps aux | head -1 && ps aux | grep 'mytest' | grep -v grep
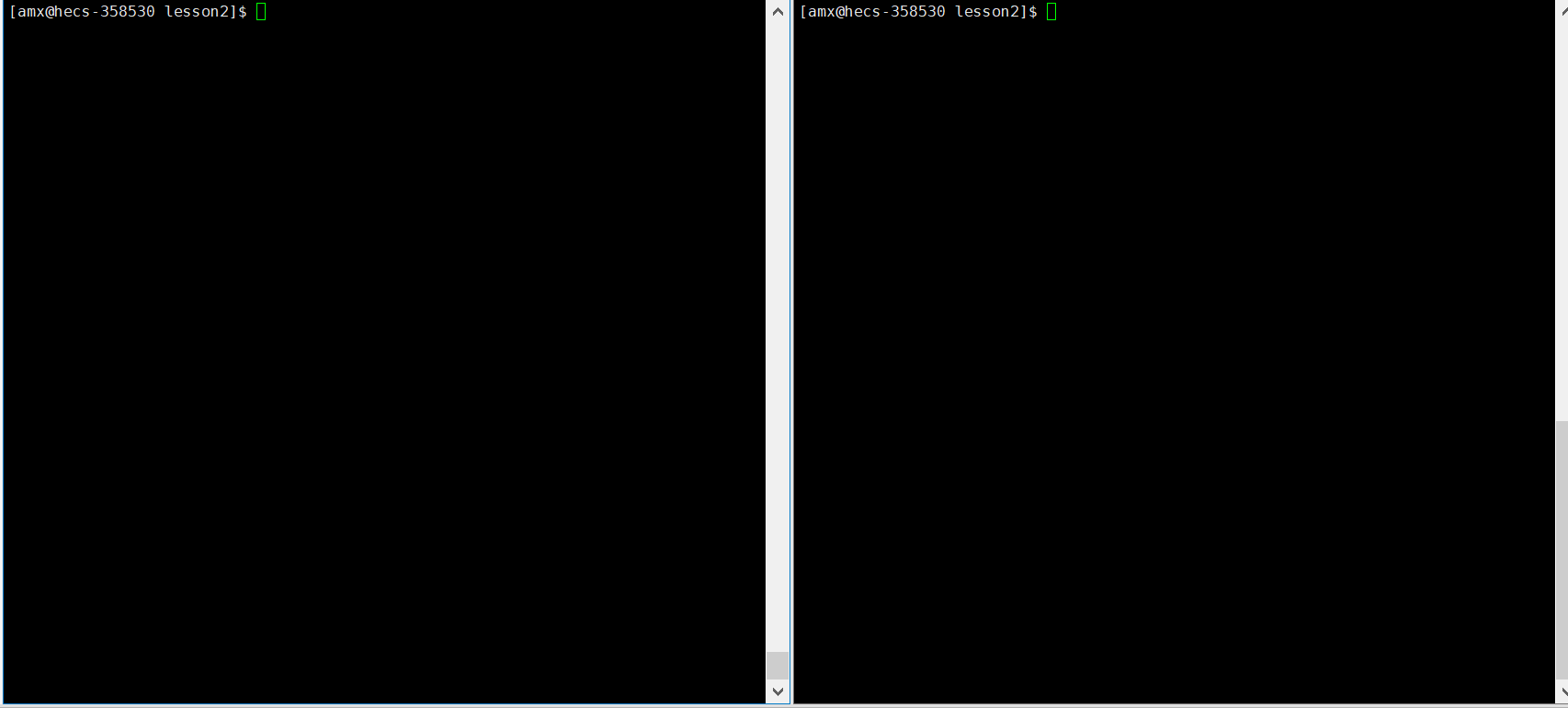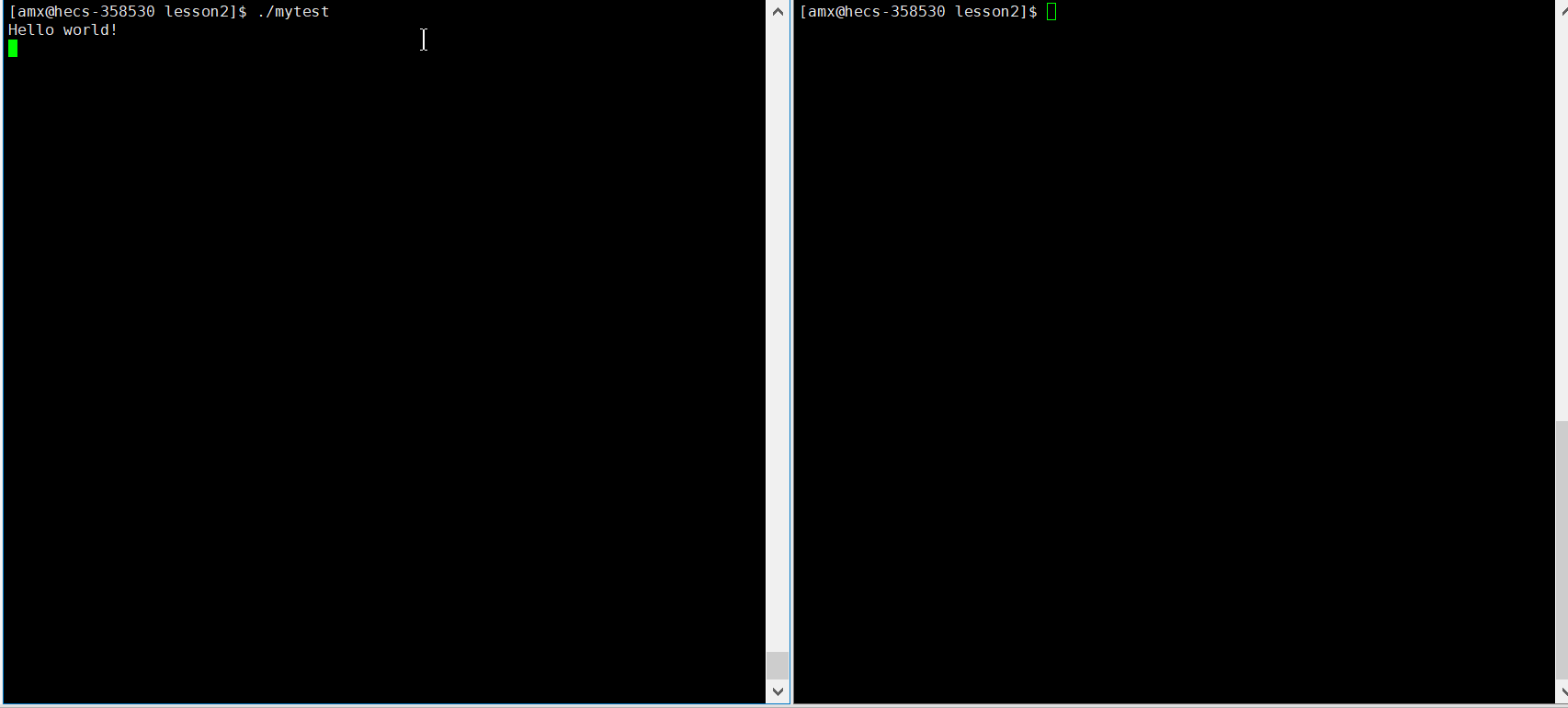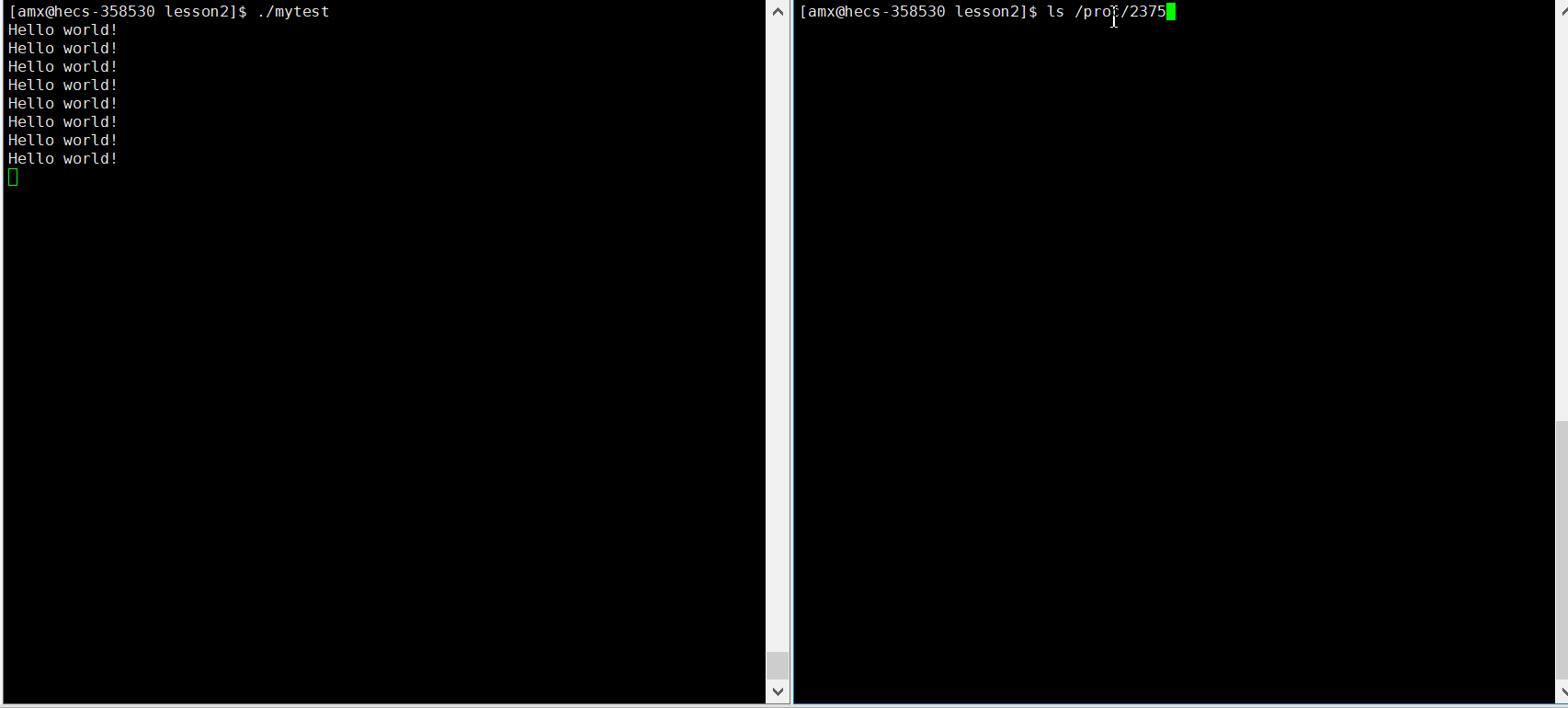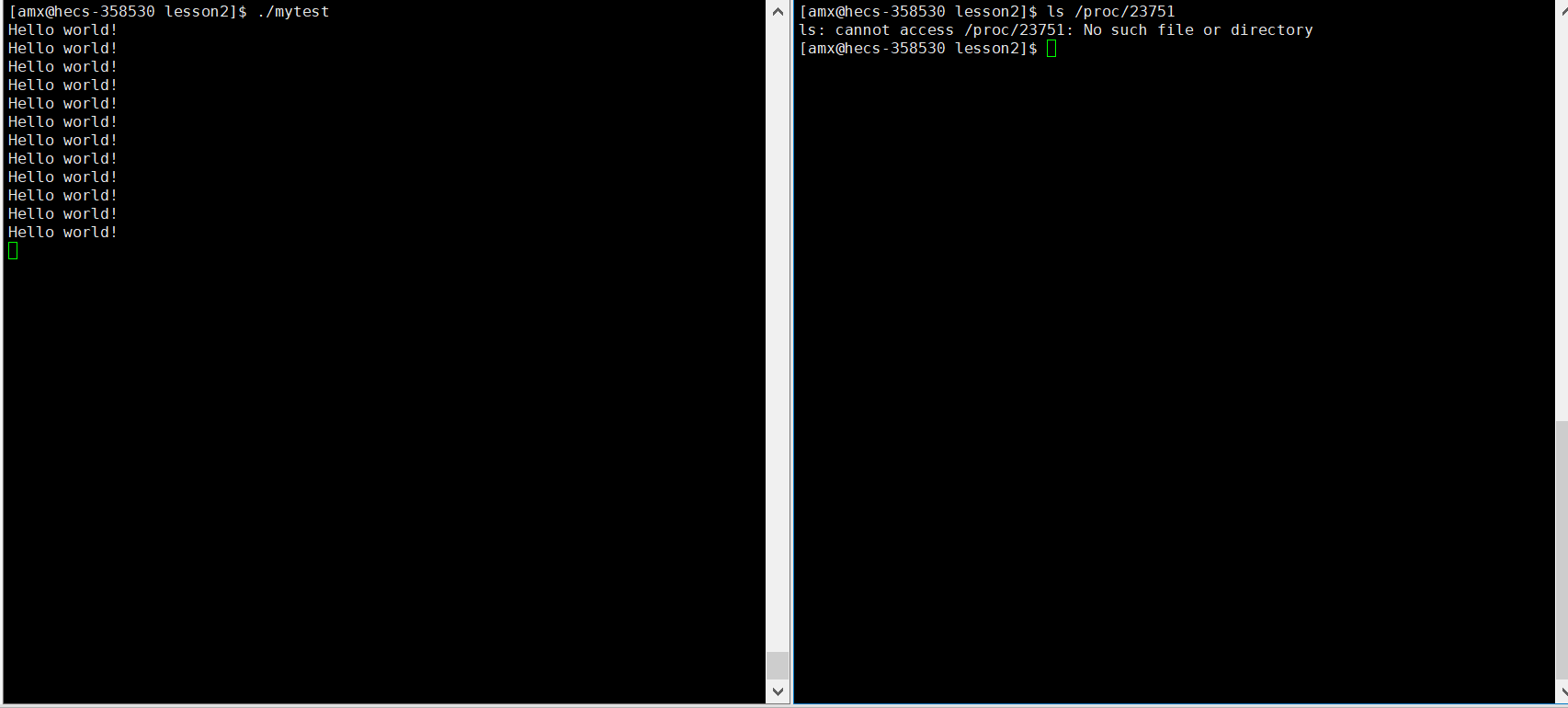
这就是当前进程的?,刚才我们说了:? proc 里保存的是内存当中实时的进程信息。那我们在 ? proc目录下找到这个 23751 ,发现这个 23751 目录确实存在!?
ls /proc/找到的pid
既然是实时的,那我们把正在跑的 mytest 进程 ctrl+ c?干掉。
看看这个文件夹是否还健在:
我们再用同样的指令去查,那 23751 目录下的内容应当是不复存在的:
?
事实也确实如此:进程是实时的。
我们再次运行,再用23751来找一下:
发现还是没有?
因为重开了嘛!我们在用指令去查看新的?:
ps aux | head -1 && ps aux | grep 'mytest' | grep -v grep
?这次又变成了:23763
我们进去查看下进程属性:

?这里面的东西很多,目前想搞懂里面都是做什么的还为时尚早,我们先 -al 看看细节:
$ ls /proc/23763 -al我们重点去关注 exe 和 cwd:
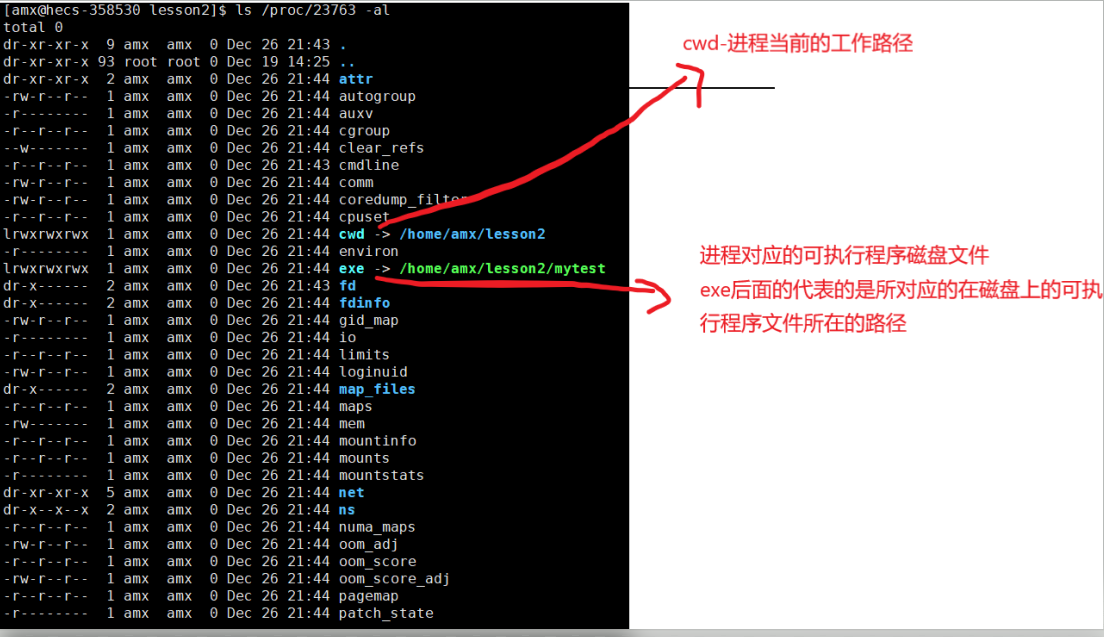
- exe:指出进程对应的可执行程序的磁盘文件
- cwd:指出进程当前的工作路径
?下面我们先终止进程,修改一下 mytest.c 文件的内容,给它加一个文件操作:
#include <stdio.h>
#include <unistd.h>
int main(void) {
FILE* fp = fopen("log.txt", "w"); // 若不存在就创建之
while (1) {
printf("Hello world!\n");
sleep(1);
}
}
?
成功运行,此时我们 ls 就能发现当前路径下多出一个 log.txt 文件,这就是我们自己创建的:?
 ?
?
fopen 后面如果不带路径,那么会默认在当前路径。
所谓的当前路径,其本质!也浮现出来了 —— 当前进程所在的路径
进程会自己维护,进程会知道自己的工作路径在哪里。
,当前路径,这些东西在哪里呢?
进程的内部属性!在进程的进程控制块??(task_struct) 结构体中!
获取 pid(getpid 函数)
下面我们介绍下获取 ?的函数 —— getpid()?
想要查看进程?,一定是这个进程得运行起来。
$ man 2 getpid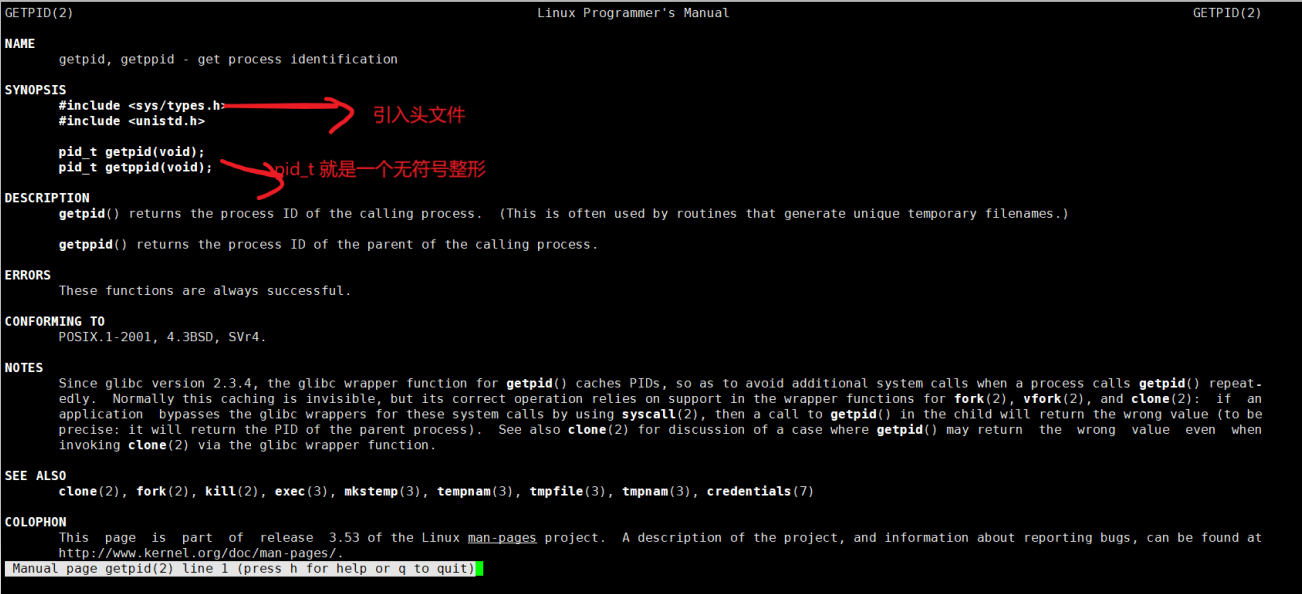
?我们修改一下刚才的 mytest.c 代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void) {
while (1) {
printf("Hello world! , pid: %d\n",getpid());
sleep(1);
}
}运行结果如下:
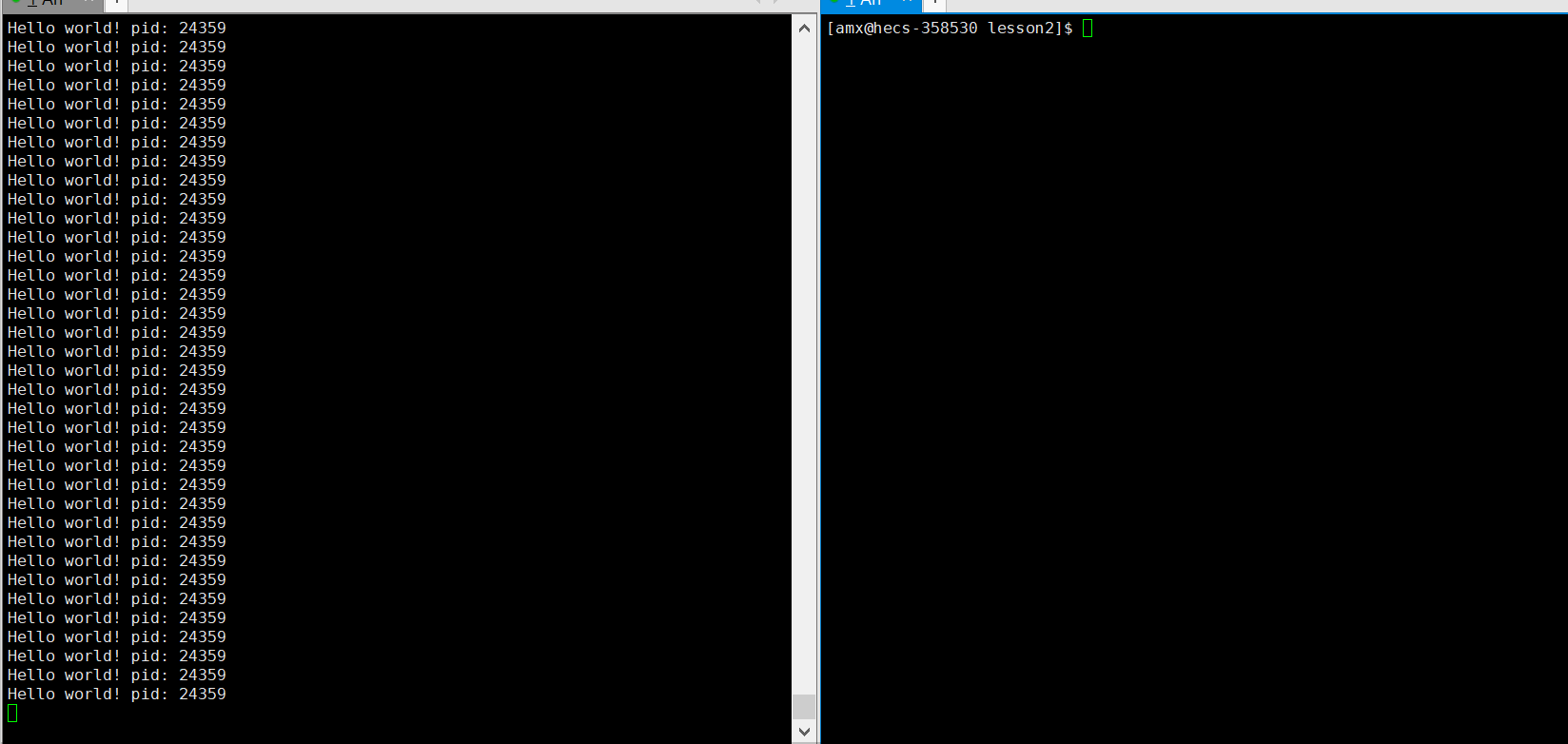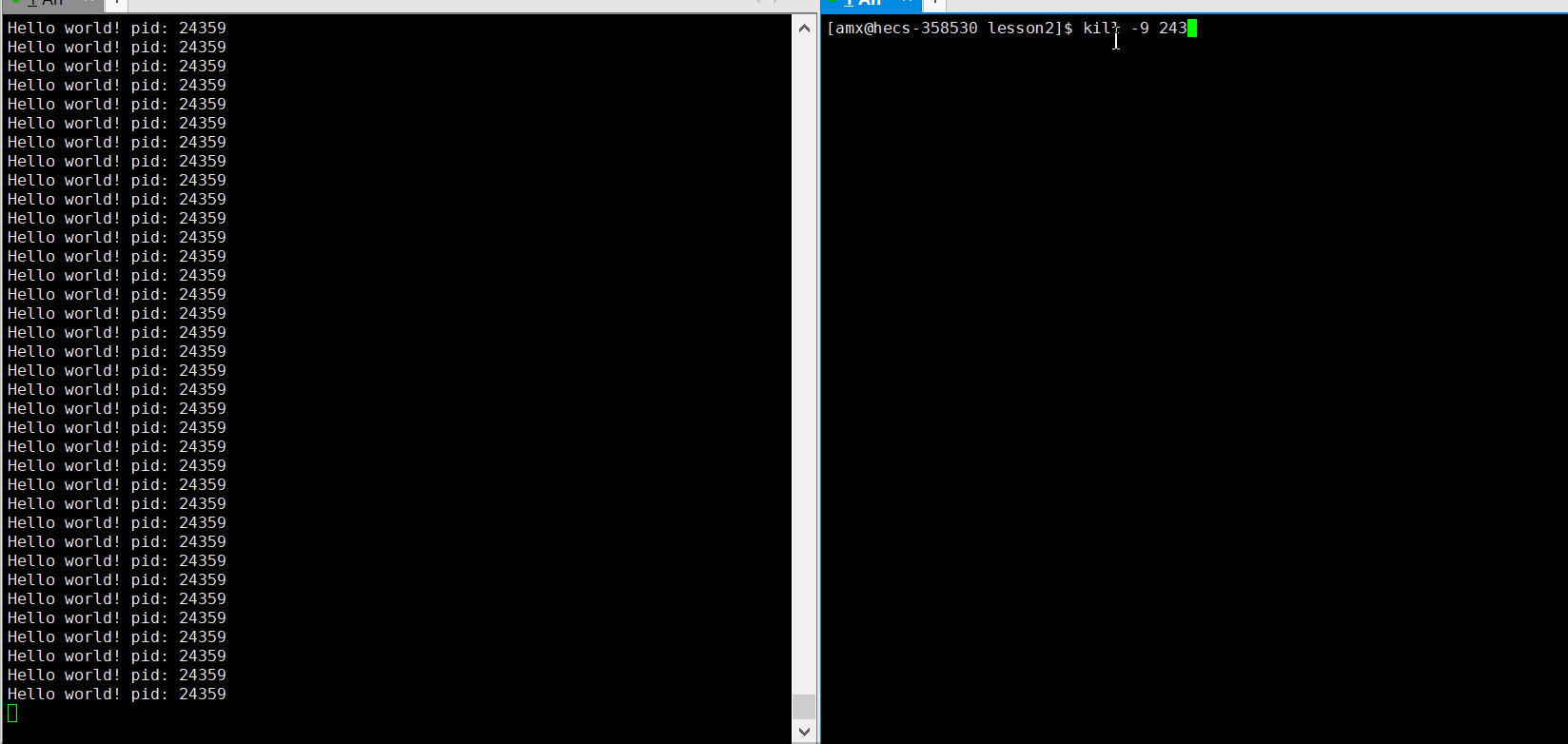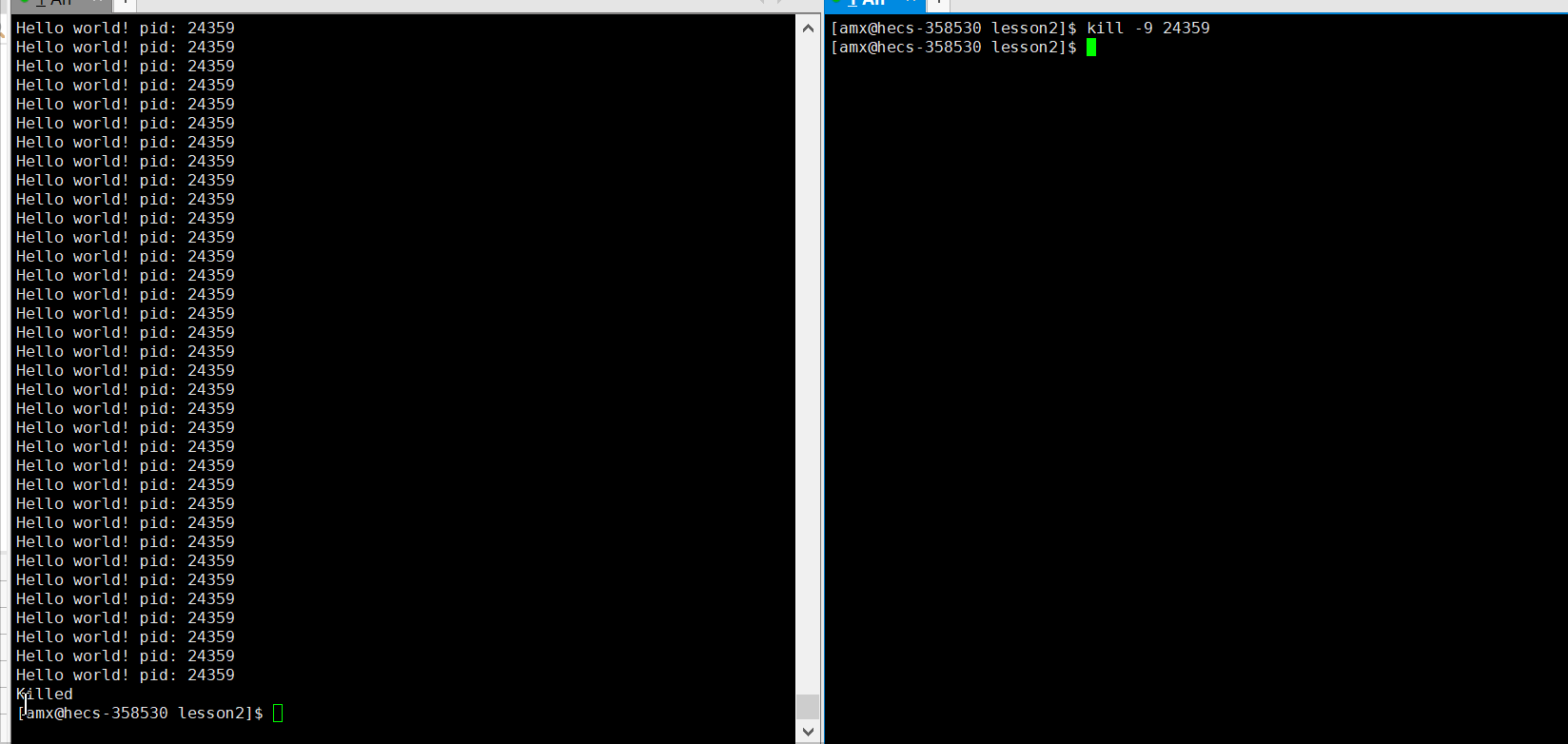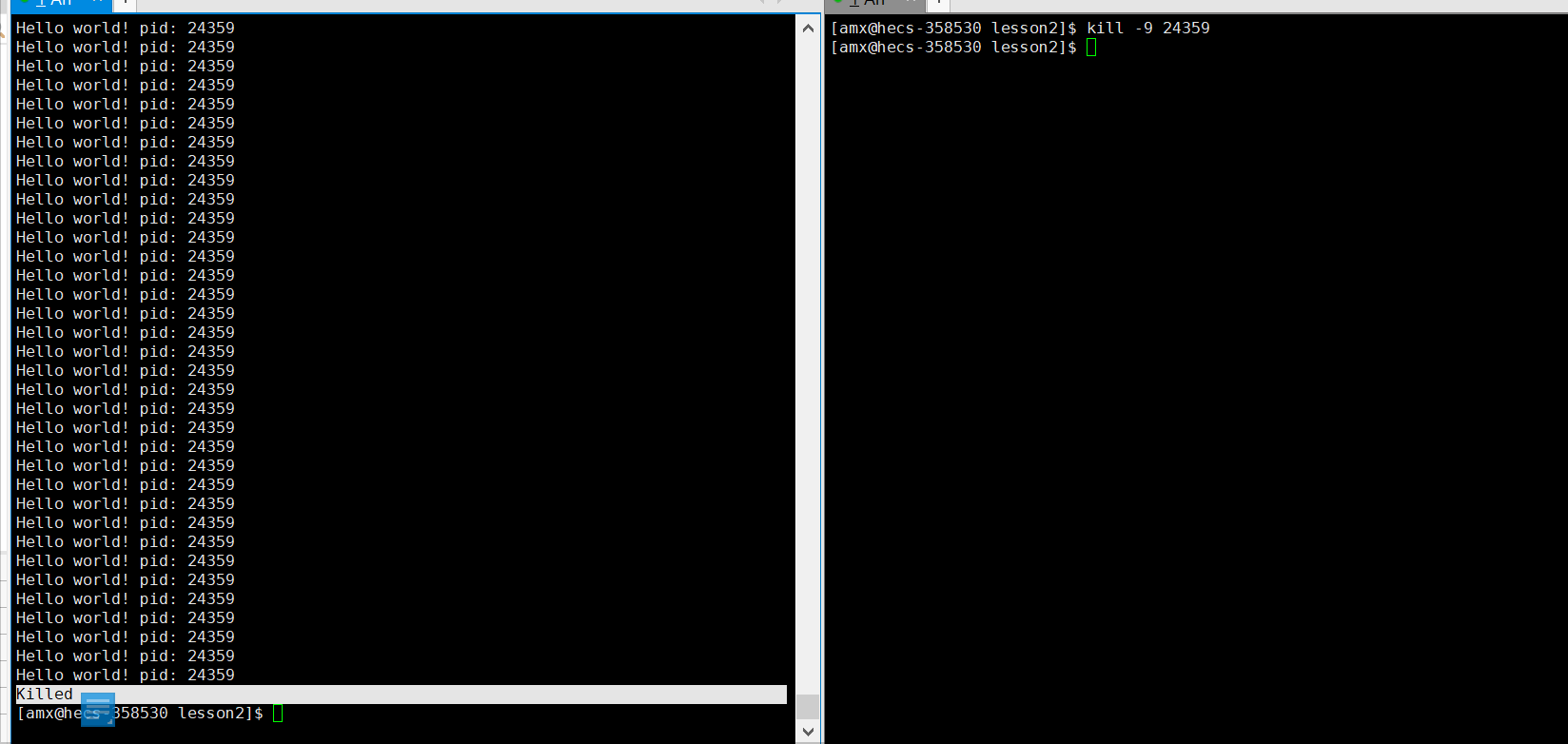
启动后,我们发现我们的 mytest 可执行程序的??为 24359。
是否果真如此?我们还是用 ps aux 验证一下看看:
ps aux | head -1 && ps aux | grep 'mytest' | grep -v grep
杀进程(kill -9)?
我们再来回忆一下我们是如何杀掉一个进程的……???
这是我们之前讲的,在 Linux 命令行中的热键,遇到问题解决不了可以用它来中止。
所谓的??就是用来杀进程的。除此之外,你也可以选择在另一个终端中使用? kill? 命令:
$ kill -9 [pid] # 给这个进程发送9号信号当前你只需要知道可以通过 kill -9 命令杀掉进程就行了,至于这个 ?号信号,我们会放在后面的信号章节去讲!比如我们现在想杀掉刚才运行的, 打出进程?
的?mytest 进程,其?
?为? 24359:
父进程 ID(ppid)
![]() ? (parent process id) 其实就是父进程 id。
? (parent process id) 其实就是父进程 id。
![]() 可以通过 getpid() 函数获取,其实
可以通过 getpid() 函数获取,其实 ? 也有与之对应的函数,那就是 getppid() 。
我们还是从 mytest.c 下手,刚才我们加入了 getpid, 现在我们再给句子后面加入 getppid。
我们再次清楚那个男人 —— man 手册出来:
代码:mytest.c?
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void) {
while (1) {
printf("Hello world! , pid: %d, ppid: %d\n",getpid(), getppid());
sleep(1);
}
}代码运行结果:
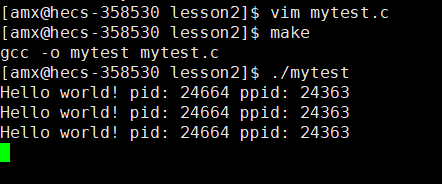
我们从中得知,其 pid=24664 ppid=24363
我们还是验证一下,这里要看?,刚才的 ps aux 是显示不到的,这里介绍一下 ?ps ajx?:
ps ajx | head -1 && ps ajx | grep 'mytest' | grep -v grep
?ps ajx??就能把??和?
?同时显示出来了。
我们刚才发觉到??在每次启动都会重新分配,但是好像这里的?
?似乎恒定不变啊。
? 思考:我的父进程为什么不变?是谁呢?
ps axj | head -1 && ps axj | grep 24363?
我们的父进程竟然是一个叫????的东西!这个现象,我们可以推导出一个假设:
几乎我们在命令行上所执行的所有指令包括你自己定义的 cmd,都是? 进程的子进程。
使用 fork() 创建子进程?
fork()
?fork 函数是用来创建子进程的, 它有两个返回值。父进程返回子进程的 ,给子进程返回 0。
代码演示:我们来看看会发生什么:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void) {
pid_t id = fork();
printf("Hello, World!\n");
sleep(1);
}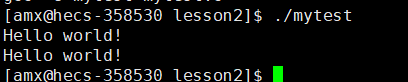
?打印两Hello world!
现在我们再来验证一下返回值的问题,我们把 id 给打印出来:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void) {
pid_t id = fork();
printf("Hello, World! id: %d\n", id);
sleep(1);
}父进程返回pid,子进程返回0
?
打印了两次 printf ……
刚才已经很离谱了,现在我们再看一个离谱的东西 ——
C 语言上 if 和 else if 可以同时执行吗?C语言中,有没有可能两个以上的死循环同时运行?
不可能,绝对不可能。但是马上你就能看到这一神奇现象:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void) {
pid_t id = fork();
/* id: 0 子进程, >0 父进程 */
if (id == 0) {
// child
while (1) {
printf("我是子进程,我的pid: %d,我的父进程是 %d\n", getpid(), getppid());
sleep(1);
}
} else {
// parent
while (1) {
printf("我是父进程,我的pid: %d,我的父进程是 %d\n", getpid(), getppid());
sleep(1);
}
}
}?运行结果如下:

我们发现,这两块代码是可以同时执行的。?
原因:fork 之后,父进程和子进程会共享代码,一般都会执行后续的代码。这也是为什么刚才的 printf 会打印两次的原因。fork 之后,父进程和子进程返回值不同,所以可以通过不同的返回值去判断,让父子执行不同的代码块。
问题:为什么 fork 会返回两次??
fork 函数,OS syscall call,fork 之后,OS 做了什么?是不是系统多了一个进程?
- task_struct + 进程代码和数据
- task_struct + 子进程的代码和数据
子进程的 task_struct 对象内部的数据基本是从父进程继承下来的。
子进程执行代码,计算数据的,子进程的代码从哪里来呢?
和父进程执行同样的代码,fork 之后,父子进程代码共享,而数据要各自独立!
父进程代码共享,让不同的返回值,让不同的进程执行不同的代码。
?
总结:我们在系统调用后,fork 本质是系统多了一个子进程,也就多了一个 task_struct,该进程控制块会几乎继承父进程,代码父子进程共享,但数据是各自私有的。
fork 的时候是要执行很多创建代码的逻辑的,最终 fork 会有两个返回值,一定是它曾经返回了2,次,因此一定会调用,return pid。
调用一个函数,当这个函数准备 return 的之后,那么这个函数的核心功能完成了吗?
当我们函数准备执行 return 的时候,函数的核心功能已经完成:
① 子进程已经被创建了
② 将子进程放入运行队列
最后,return 是代码吗?是的!所以当我们走到 return 时父进程有了,子进程也已经在运行队列了,fork 后代码共享,父子进程当然会执行后续被共享的 return 代码。因此,父进程执行一次 return,子进程执行一次 return,最后就是两个返回值了。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!