CMU15-445-Spring-2023-Project #1 - 前置知识(lec01-06)
Lecture #01_ Relational Model & Relational Algebra
Databases
数据库是相互关联的数据的有组织集合,对现实世界的某些方面进行建模。区别于DBMS(MySQL、Oracle)。
Flat File Strawman
数据库以CSV文件的形式存储,并由DBMS管理。

Database Management System
DBMS是允许应用程序在数据库中存储和分析信息的软件。
数据模型(data model)是描述数据库中数据的概念集合。e.g. relational、NoSQL、vectors。
模式(schema)是对基于数据模型的特定数据集合的描述。
Relational Model
关系模型定义了一种基于关系的数据库抽象,以避免维护开销。

relation是一组无序集合,允许重复元素出现,等价于table。
tuple(domain)代表relation中的一组属性,带有n条属性的relation叫做n-ary relation。
relation中primary key唯一标识一个元组。
foreign key指定一个关系中的属性必须映射到另一个关系中的元组。
Data Manipulation Languages (DMLs)

Relational Algebra
关系代数是一组基本操作,用于检索和操作关系中的元组。
- Select

- Projection

- Union

- Intersection

- Difference

- Product

- Join:根据共有的属性中的相同值进行连接,并去除重复列。

Lecture #02_ Modern SQL
Relational Languages
关系代数基于集合set(无序、无重复)。SQL基于包bag(无序,允许重复)。
SQL History

Joins
合并一个或多个表中的列,生成一个新表。用于表达涉及跨多个表的数据的查询。

Aggregates
- aggregation function

- DISTINCT keyword
- GROUP BY

- HAVING

String Operations
SQL标准规定字符串区分大小写,且只允许单引号。
LIKE keyword:“%”匹配任意字串,包含空;“_”匹配任意单个字符。
“||”:将两个或多个字符串连接成一个字符串。
Date and Time
操作DATE和TIME属性。
Output Redirection

列数和type需要一致,列名不需要。
Output Control
- ORDER BY

- LIMIT

Nested Queries


Window Functions
ROW_NUMBER():当前行的编号。在窗口函数排序前计算。
RANK():当前行的顺序位置。在窗口函数排序后计算。
OVER clause:指定计算窗口函数时如何将tuple分组。 使用 PARTITION BY 指定分组。使用 GROUP BY 排序。

Common Table Expressions
临时表,其作用域仅限于单个查询。

在 WITH 后添加 RECURSIVE 关键字,可以让 CTE 引用自身。

Lecture #03_ Database Storage (Part I)
Storage
关注面向磁盘的DMS,即数据库存储在非易失磁盘上。
DBMS需要关注如何将在非易失磁盘与易失memory之间移动数据。由于从磁盘获取数据的速度非常慢,DBMS将重点关注隐藏磁盘的延迟,而不是对寄存器和高速缓存进行优化。
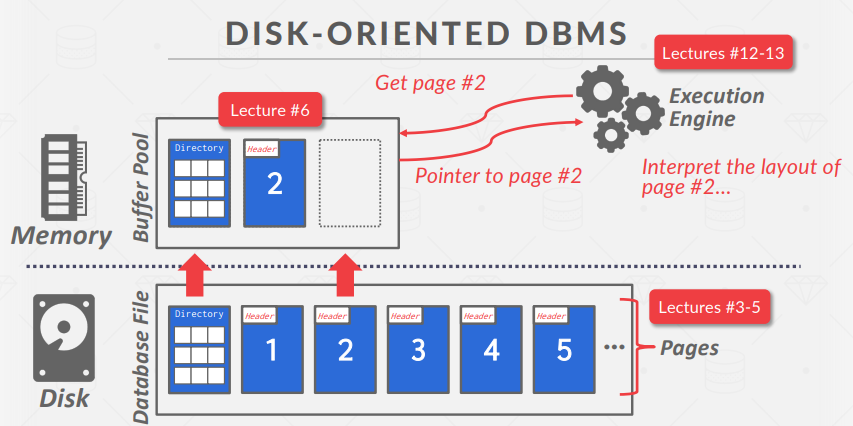
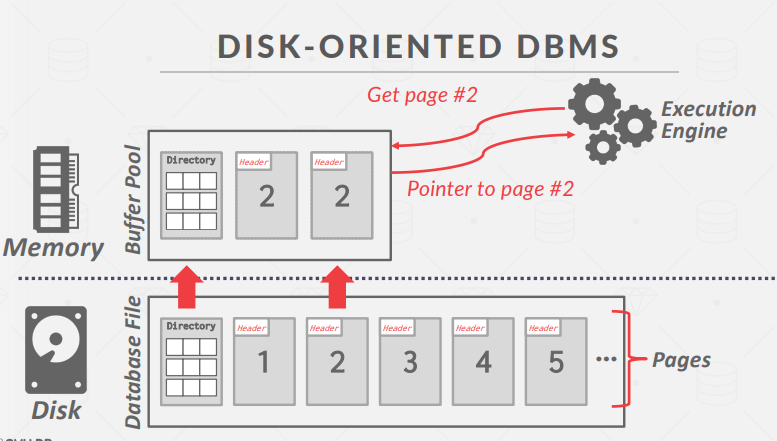
Disk-Oriented DBMS Overview
数据库全部在磁盘上,数据库文件中的数据按页组织,第一页是目录页。
要对数据进行操作,DBMS需要将数据带入内存。为此,数据库管理系统需要一个**缓冲池(buffer pool)**来管理数据在磁盘和内存之间的移动。DBMS还有一个执行引擎来执行查询。执行引擎会向缓冲池请求一个特定页面,缓冲池会负责将该页面带入内存,并向执行引擎提供一个指向内存中该页面的指针。缓冲池管理器将确保在执行引擎对内存中的该部分进行操作时,页面仍然存在。
DBMS vs. OS
实现虚拟内存的一种方法是使用 mmap (memory mapping)将文件内容映射到进程的地址空间,这样操作系统就可以负责在磁盘和内存之间来回移动页面。但是如果 mmap 遇到页面错误,进程就会被阻塞。

File Storage
DBMS 的最基本形式是将数据库存储为磁盘上的文件。操作系统对这些文件的内容一无所知。只有 DBMS 知道如何破译它们的内容,因为这些内容是以 DBMS 特有的方式编码的。 DBMS 的存储管理器负责管理数据库的文件。它将文件表示为页面集合。它还会跟踪哪些数据已被读取和写入页面,以及这些页面中还有多少可用空间。
Database Pages
DBMS 在一个或多个文件中以固定大小的数据块(称为页)组织数据库。页面可以包含不同类型的数据(tuple、index等)。大多数系统不会在页面中混合这些类型的数据。
每个页面都有一个唯一的标识符。如果数据库是一个单独的文件,那么页面 ID 可以只是文件偏移量。大多数数据库管理系统都有一个间接层,将页面 ID 映射到文件路径和偏移量。
大多数 DBMS 使用固定大小的页面,以避免支持可变大小页面所需的工程开销。
存储设备保证以原子方式写入硬件页的大小。如果硬件页面为 4 KB,而系统尝试向磁盘写入 4 KB,那么要么 4 KB 全部写入,要么全部不写入。
Database Heap
堆文件是一个无序的页面集合,其中的tuples以随机顺序存储。可以在磁盘上找到 DBMS 需要的页面位置。
DBMS 在给定页面 ID 的情况下找到磁盘上的页面的方法:
- Linked List:页眉页持有指向空闲页列表和数据页列表的指针。但是,如果 DBMS 要查找特定页面,则必须对数据页列表进行顺序扫描,直到找到要查找的页面。
- Page Directionary:DBMS 维护特殊页面,跟踪数据页面的位置以及每个页面上的可用空间。
Page Layout


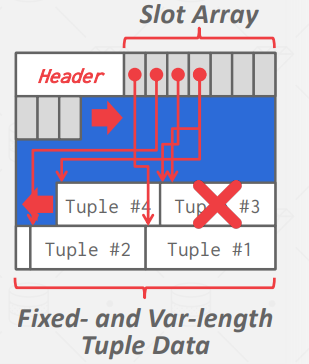
Tuple Layout

非规范化元组数据(Denormalized Tuple Data):如果两个表有关联,DBMS就可以 "预连接 "它们,这样这两个表就会出现在同一个页面上。这使得读取更快,因为数据库管理系统只需加载一个页面,而不是两个独立的页面。不过,由于数据库管理系统需要为每个元组提供更多空间,因此更新成本会更高。
Lecture #04_ Database Storage (Part II)
Log-Structured Storage
page layout如果是slotted page的话,会有一些问题:tuple的删除;读取一个tuple需要读取整个block;tuple的更新可能需要花费大量时间切换block。
log structure DBMS不存储tuple,只存储log。
- log包含元组的唯一标识符、操作类型(PUT/DELETE)以及元组的内容;
- 倒序扫描读取记录,同时可以使用索引跳转到日志中的特定位置;
- 由于写入是顺序的,所以速度很快;
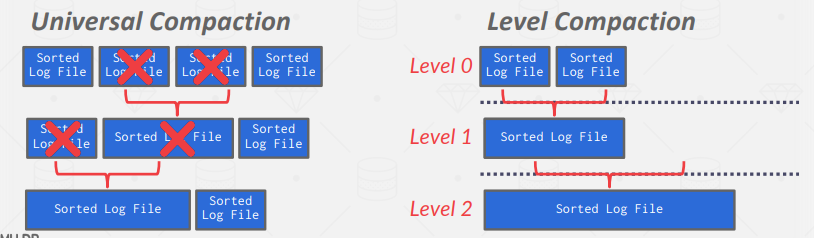
- 可以定期压缩日志,方法是在多个页面中只记录每个元组的最新变化;
- 压缩后,由于每个元组只有一个,不再需要排序,因此DBMS可以按 id 排序,以加快查找速度。这些表称为排序字符串表(Sorted String Tables,SSTables);
- 缺点是压缩成本较高,还会导致写入放大(重复写入相同的数据);

Data Representation
有五种高级数据类型可以存储在元组中:
- Integers
- Examples: INTEGER, BIGINT, SMALLINT, TINYINT.
- Variable Precision Numbers
- Examples: FLOAT, REAL.
- Fixed-Point Precision Numbers
- Examples: NUMERIC, DECIMAL.
- Variable-Length Data
- Examples: VARCHAR, VARBINARY, TEXT, BLOB.
- Dates and Times
- Examples: TIME, DATE, TIMESTAMP.
System Catalogs
为了让 DBMS 能够破译元组的内容,它需要维护一个内部目录,告诉它有关数据库的元数据:
- 表和列,以及这些表上的任何索引;
- 数据库用户及其权限;
- 有关表格及其包含内容的统计信息(如属性的最大值);
Lecture #05_ Storage Models & Compression
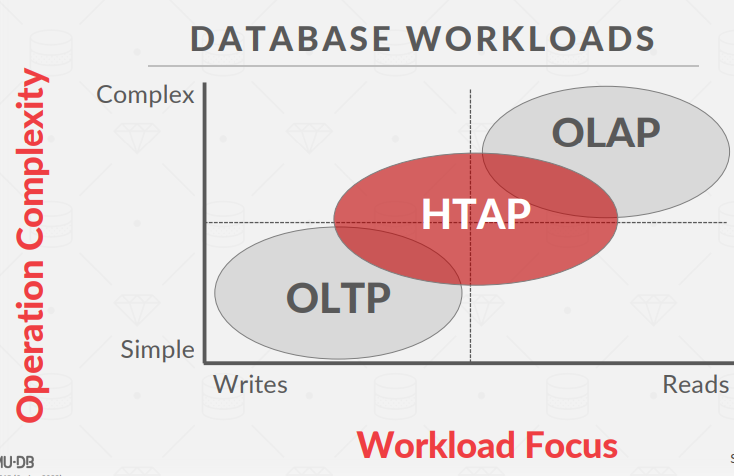
Database Workloads
- OLTP: Online Transaction Processing
- 特点是快速、短时间操作和查询,一次只对单个实体进行操作。写入次数通常多于读取次数。
- OLAP: Online Analytical Processing
- 对数据库的大部分数据进行长时间运行的复杂查询和读取。数据库系统通常要从 OLTP 侧收集的现有数据中分析和提取新数据。
- HTAP: Hybrid Transaction + Analytical Processing
- 同时出现在一个实例。
Storage Models
- N-Ary Storage Model (NSM)——行存储,OLTP
- 将单个tuple的所有属性连续存储在一个页面中;
- 优点是修改操作快,缺点是在扫描表的大部分内容时效率较低;
- Decomposition Storage Model (DSM) ——列存储,OLAP
- 在数据块中连续存储所有元组的单个属性(列);
- 适合有许多只读查询的 OLAP,这些查询会对表的一个属性子集执行大量扫描,减少了I/O浪费;
- 点查询、插入、更新和删除速度较慢;
- 将tuple重新组合
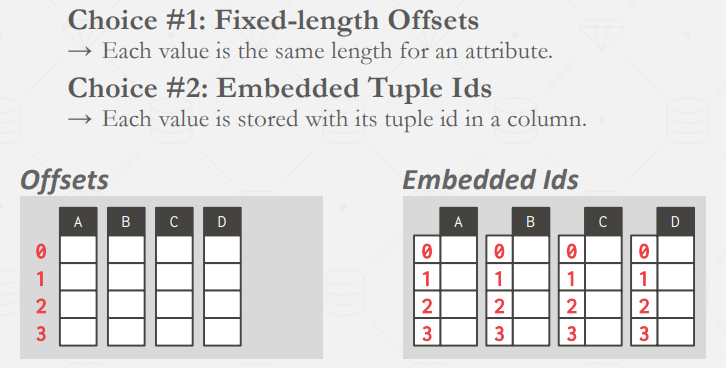
- 最常用的方法是固定长度偏移。在这种情况下,给定列中的值将与处于相同偏移量的另一列中的值属于同一个元组。因此,列中的每个值都必须具有相同的长度。
- 使用tuple id。DBMS会为列中的每个属性存储一个元组 id(例如主键)。然后,系统还会存储一个映射,告诉它如何跳转到具有该 id 的每个属性。这种方法的存储开销很大,因为它需要为每个属性条目存储一个元组 id。
Database Compression
磁盘I/O一般是主要的限制因素,通过数据压缩,DBMS能够获取更多的tuple,但是也会在压缩和解压缩上消耗时间。
现实世界中的数据一般具有以下特点:
- 某个属性是偏态分布的;
- 单个tuple属性之间强相关;
基于此,数据库压缩需要达成以下目标:
- 产生定长数据,除了存储在不同数据池中的可变长度数据;
- late materialization:允许 DBMS 在查询执行过程中尽可能推迟解压缩;
- 无损压缩,任何类型的有损压缩都必须在应用层面进行;
压缩粒度:

Naive Compression
通常会选择压缩率较低的算法,以换取更快的压缩/解压缩速度。
MySQL InnoDB 就是一个使用Naive Compression的例子。DBMS 会压缩磁盘页面,将其填充为 2KB 的幂次,然后将其存储到缓冲池中。但是,每次 DBMS 尝试读取/修改数据时,缓冲池中的压缩数据都必须首先解压缩。
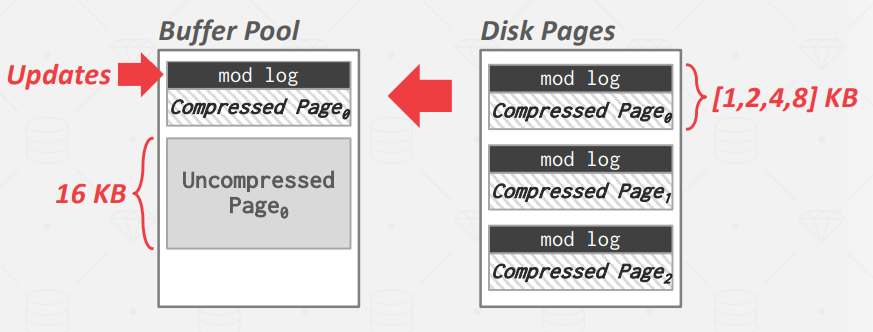
为了避免每次都要将整张表压缩和解压缩,MySQL 会把表分解成更小的块。
没有考虑数据的高层含义或语义。算法既不考虑数据结构,也不考虑query如何访问数据,从而无法利用延迟实体化(late materialization),因为 DBMS 无法判断何时可以延迟数据的解压缩。
Columnar Compression
- Run-Length Encoding (RLE)
- 将单列中相同值数据压缩为:value、offset、length;
- 应事先对列进行排序,这样可以对重复属性进行聚类,从而提高压缩率。请注意,RLE 的有效性在很大程度上取决于基础数据特征(如每种数据中属性的数量和频率);
- Bit-Packing Encoding
- 当一个属性的所有值都小于该值声明的最大size时,就用较少的位来存储它们;
- 类似位域;
- Mostly Encoding
- Bit-Packing Encoding变体,用offset-value表保存超出声明的最大size的值;
- Bitmap Encoding
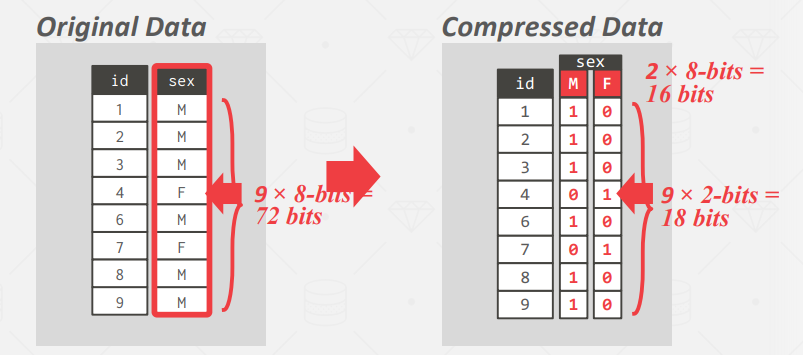
- 位图通常被分割成块,以避免分配大块的连续内存;
- 只有在值的基数或者说种类较低时有效;
- Delta Encoding
- 记录同一列中相邻值之间的差值。基准值可以在线存储,也可以存储在单独的查找表中;
- 还可以对存储的差值使用 RLE,以获得更好的压缩率;
- Incremental Encoding
- 通过这种方式记录常用前缀或后缀、长度,从而避免重复。这种编码方式最适用于有序数据;
- Dictionary Compression(most common)
- 用较小的code替换频繁的value。然后,数据库管理系统只存储这些代码和将这些代码映射到其原始值的数据结构(即字典)。字典压缩方案需要支持快速编码/解码以及范围查询;
Lecture #06_ Buffer Pools
Introduction
DBMS 负责管理内存和从磁盘来回移动数据。由于大部分数据不能直接在磁盘上操作,因此任何数据库都必须能够高效地将以文件形式存在的数据从磁盘移动到内存中,以便使用。从执行引擎的角度来看,理想的情况是所有数据都 "看起来 "在内存中。它不必担心数据是如何获取到内存中的。
分为空间控制(让经常一起使用的page在物理位置上也靠近)和时间控制(目的是最大限度地减少从磁盘读取数据的停顿次数)
Locks vs. Latches
Locks是用于保护数据库内容(例如元组、表或数据库本身)不受其他事务影响的高级别逻辑原语。事务将在其整个持续时间内持有锁。数据库系统可以向用户展示正在运行查询时持有的锁。锁需要能够回滚更改。
Latches是用于数据库管理系统(DBMS)内部数据结构的临界区的低级别保护原语(例如哈希表或内存区域)。latch仅在执行特定操作的持续时间内被持有,并且不需要具备回滚更改的能力。它们更精细地用于内部,由DBMS使用以确保对其自身结构的安全并发访问。
Buffer Pool
缓冲池是从磁盘读取页面的内存缓存。
缓冲池的内存区域是由固定大小的页面组成的数组。当DBMS请求一个页面时,该页面就会从磁盘复制到缓冲池的一个frame中。请求页面时,数据库系统可以先搜索缓冲池。只有在找不到页面时,系统才会从磁盘获取页面副本。脏页面会被缓冲,不会立即写回。(对应UnpinPage脏标记置true不立即写回磁盘)
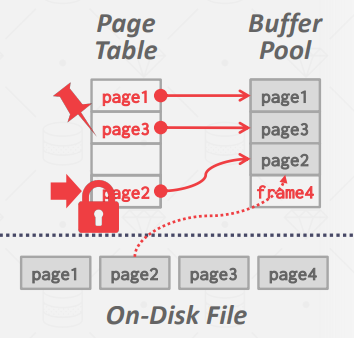
页表(page table)是一个内存哈希表,用于跟踪当前内存中的页面。它将page id 映射到缓冲池中的frame位置。由于缓冲池中页面的顺序并不一定反映磁盘上的顺序,因此这个额外的间接层可以识别缓冲池中的页面位置。
每当线程修改页面时,都会设置 dirty-flag。这表明存储管理器必须将页面写回磁盘。
引用计数器(pincount)跟踪当前访问该页面(读取或修改)的线程数。线程必须在访问页面前递增计数器。如果页面的引用计数大于零,则存储管理程序不允许从内存中删除该页面。钉住不会阻止其他事务同时访问页面。
数据库中的内存根据两种策略分配给缓冲池:
- 全局策略。DBMS 为使正在执行的整个工作负载受益而应做出决策。 它考虑所有活动事务,以找到分配内存的最佳决策;
- 局部策略。它所做的决策会使单个查询或事务运行得更快,即使这对整个工作负载不利。本地策略为特定事务分配frame,而不考虑并发事务的行为。
Buffer Pool Optimizations
- Multiple Buffer Pools
- 维护多个缓冲池(即每个数据库缓冲池、每个页面类型缓冲池)。然后,每个缓冲池可采用为其内部存储的数据量身定制的本地策略。这种方法有助于减少锁存争用,并提高本地性;
- page选择缓冲池的方法:
- object ids:映射的方式;
- hashing:DBMS 对页面 ID 进行散列,以选择访问哪个缓冲池;
- Pre-fetching
- DBMS 还可以根据query计划预先抓取页面来进行优化。然后,在处理第一组页面的同时,将第二组页面预先抓取到缓冲池中。缓冲池管理器也可以预取树形索引数据结构中的叶子page。
- Scan Sharing (Synchronized Scans)
- 允许多个查询附加到扫描表的单个游标上。如果一个查询开始扫描,而已有一个查询正在进行扫描,那么 DBMS 就会将第二个查询的游标附加到已有的游标上。DBMS 会跟踪第二个查询与第一个查询的连接位置,以便在到达数据结构末尾时完成扫描。
- Buffer Pool Bypass
- 顺序扫描操作不会将获取的页面存储在缓冲池中,以避免开销。如果操作需要读取磁盘上连续的大量页面序列,这种方法非常有效。缓冲池旁路还可用于临时数据(排序、连接)。
OS Page Cache
大多数磁盘操作都是通过OS API进行的。OS一般会维护自己的文件系统缓存。
大多数 DBMS 使用直接 I/O 来绕过OS的缓存,以避免冗余的页面副本和管理不同的驱逐策略。
Postgres 是一个使用OS页面缓存的数据库系统实例。
Buffer Replacement Policies
当 DBMS 需要释放一个frame,为新页面腾出空间时,它必须决定从缓冲池中驱逐某个页面。
- Least Recently Used (LRU)
- 最近最少使用替换策略;
- 使用队列,以便进行排序,并通过减少驱逐时的排序时间来提高效率;
- CLOCK
- 每个页面都有一个ref bit。当一个页面被访问时,将其设置为 1;
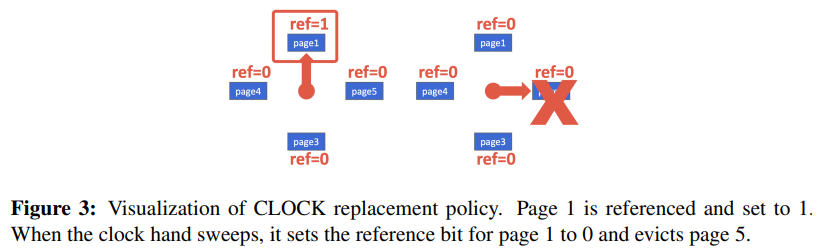
缺点:由于顺序扫描会快速读取许多页面,缓冲池会被填满,其他查询的页面会被驱逐,因为它们的时间戳会更早。在这种情况下,最新的时间戳并不能准确反映我们实际要驱逐的页面。
solution:
- LRU-K
- 按查询进行本地化。DBMS 根据每个事务/查询选择要驱逐的页面。这样可以最大限度地减少每次查询对缓冲池的污染。
- 优先级提示。允许事务在查询执行过程中根据每个页面的上下文告诉缓冲池页面是否重要。
对于脏页面,最快的方法是丢弃缓冲池中任何不脏的页面;较慢的方法是将脏页面写回磁盘,以确保其更改被持久化。
一种方法是通过后台写入,数据库管理系统可以定期浏览页表,并将脏页写入磁盘。当一个脏页面被安全写入后,数据库管理系统可以驱逐该页面,或者直接取消脏标记。
Other Memory Pools
除了tuple和index还需要其他memory:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!