kafka学习笔记--生产者消息发送及原理
本文内容来自尚硅谷B站公开教学视频,仅做个人总结、学习、复习使用,任何对此文章的引用,应当说明源出处为尚硅谷,不得用于商业用途。
如有侵权、联系速删
视频教程链接:【尚硅谷】Kafka3.x教程(从入门到调优,深入全面)
发送的目的就一个,将消息发到kafka集群里,整体流程如下:
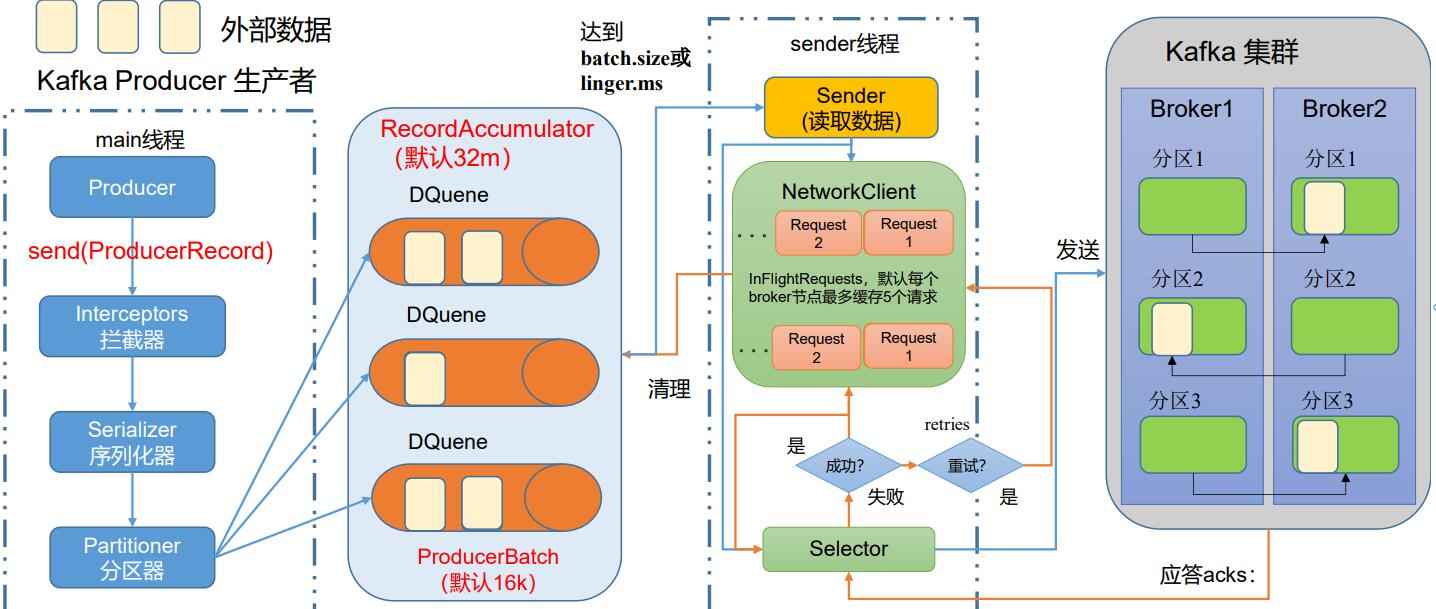
如上图,首先要有一个发送消息的主线程,也就是main线程,然后有一个读取数据的线程sender,所有的消息先经过拦截器(一般不用,因为大数据体系中,使用flume充当拦截器更加方便),然后抵达序列化器,最后抵达分区器,然后发送消息
为什么一般不用Java的序列化器?
Java的序列化过于笨重,一条消息要附带很多比如安全等功能的额外信息,大数据场景下,这些额外信息的负担太重,通常在spark、flink等框架中我们会自己实现序列化
分区器会在内存中,为每一个kafka分区创建一个双端队列,方便消息的管理,分区器大小为默认32M,每个队列在数据达到16k时,由sender线程读取,当然长时间达不到16k数据的队列,也会每隔一段时间(默认0ms)发送一次,采用默认策略则意味着每条消息都发送,在大数据场景下,应当灵活调整
队列数据累加上限的参数与等待发送时长的两个参数为:batch.size,linger.ms
这里其实是创建了一个32M大小的临时内存池,数据添加到队列就是内存池分配内存的过程,发送成功后清理数据,就是内存回归到内存池的过程
达到拉取条件(16k或时长)的数据,sender线程会主动从分区器内存空间中拉取数据,为每一个节点创建一个请求队列,队列中最多等待5个请求,发送到kafka集群,kafka给予应答回应
如果发送成功,则关闭、清理该请求,同时清理掉分区器队列中相应的数据
如果发送失败,则重试发送,直到重试到设定的次数为止(默认重试次数为int最大值)
应答级别分三种:
0:生产者发来的消息立即应答,不需要等到落盘
1:生产者发来的消息,等到leader收到数据后应答
-1:生产者发来的消息,等到leader和备份的所有节点都收到再应答
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!