【改进YOLOv8】融合重参数结构DiverseBranchBlock的冬小麦物候期检测系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
近年来,随着计算机视觉技术的迅速发展,物体检测成为了计算机视觉领域的一个重要研究方向。物体检测的目标是在给定图像中准确地识别和定位出感兴趣的物体。在农业领域,物候期检测对于精确的农作物管理和决策制定至关重要。冬小麦是我国重要的农作物之一,其物候期的准确检测对于农业生产的规划和管理具有重要意义。
然而,传统的物体检测方法在冬小麦物候期检测中存在一些挑战。首先,冬小麦的生长过程中,叶片的颜色和纹理会发生较大的变化,这给物候期检测带来了困难。其次,冬小麦的生长速度较快,需要对大量的图像进行实时检测,因此需要高效的算法来处理大规模的数据。此外,由于冬小麦的生长环境复杂多变,需要一个鲁棒性强的检测系统来适应各种环境条件。
为了解决上述问题,本研究提出了一种改进的YOLOv8算法,并融合了重参数结构DiverseBranchBlock,用于冬小麦物候期检测系统。YOLOv8是一种基于深度学习的物体检测算法,具有较高的检测精度和实时性能。通过引入DiverseBranchBlock,可以进一步提高YOLOv8算法的性能和鲁棒性。
DiverseBranchBlock是一种新颖的重参数结构,它通过引入多个分支网络来增加模型的多样性。每个分支网络可以学习不同的特征表示,从而提高模型的泛化能力。在冬小麦物候期检测中,DiverseBranchBlock可以帮助模型学习到更多的冬小麦生长特征,从而提高检测的准确性和鲁棒性。
本研究的意义主要体现在以下几个方面:
首先,本研究的成果可以为农业生产提供有力的支持。通过准确地检测冬小麦的物候期,可以及时采取相应的农业管理措施,提高农作物的产量和质量。同时,农民可以根据物候期检测结果进行农作物的规划和决策制定,提高农业生产的效益。
其次,本研究的方法可以为物体检测领域的研究提供新的思路和方法。通过融合DiverseBranchBlock,可以提高物体检测算法的性能和鲁棒性,对于其他物体检测任务也具有一定的借鉴意义。此外,本研究还可以为其他农作物的物候期检测提供参考,拓展了物候期检测的应用范围。
最后,本研究的成果对于推动农业智能化和数字化发展具有重要意义。随着农业技术的不断进步,农业生产越来越依赖于先进的技术手段。冬小麦物候期检测系统的研究可以为农业智能化提供一种有效的解决方案,推动农业生产向数字化、智能化方向发展。
综上所述,本研究的改进YOLOv8算法并融合重参数结构DiverseBranchBlock的冬小麦物候期检测系统具有重要的研究背景和意义。通过提高冬小麦物候期检测的准确性和鲁棒性,可以为农业生产提供有力的支持,同时也为物体检测领域的研究提供新的思路和方法,推动农业智能化和数字化发展。
2.图片演示



3.视频演示
【改进YOLOv8】融合重参数结构DiverseBranchBlock的冬小麦物候期检测系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集WHDatasets。

下面是一个简单的方法是使用Python脚本,该脚本读取分类图片文件,然后将其转换为所需的格式。
import os
import shutil
import random
# 指定输入和输出文件夹的路径
input_dir = 'train'
output_dir = 'output'
# 确保输出文件夹存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 遍历输入文件夹中的所有子文件夹
for subdir in os.listdir(input_dir):
input_subdir_path = os.path.join(input_dir, subdir)
# 确保它是一个子文件夹
if os.path.isdir(input_subdir_path):
output_subdir_path = os.path.join(output_dir, subdir)
# 在输出文件夹中创建同名的子文件夹
if not os.path.exists(output_subdir_path):
os.makedirs(output_subdir_path)
# 获取所有文件的列表
files = [f for f in os.listdir(input_subdir_path) if os.path.isfile(os.path.join(input_subdir_path, f))]
# 随机选择四分之一的文件
files_to_move = random.sample(files, len(files) // 4)
# 移动文件
for file_to_move in files_to_move:
src_path = os.path.join(input_subdir_path, file_to_move)
dest_path = os.path.join(output_subdir_path, file_to_move)
shutil.move(src_path, dest_path)
print("任务完成!")
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----dataset
-----dataset
|-----train
| |-----class1
| |-----class2
| |-----.......
|
|-----valid
| |-----class1
| |-----class2
| |-----.......
|
|-----test
| |-----class1
| |-----class2
| |-----.......
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.2 predict.py
封装为类后的代码如下:
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
def postprocess(self, preds, img, orig_imgs):
preds = ops.non_max_suppression(preds,
self.args.conf,
self.args.iou,
agnostic=self.args.agnostic_nms,
max_det=self.args.max_det,
classes=self.args.classes)
if not isinstance(orig_imgs, list):
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
results = []
for i, pred in enumerate(preds):
orig_img = orig_imgs[i]
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
img_path = self.batch[0][i]
results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
return results
这是一个名为predict.py的程序文件,它是基于检测模型进行预测的。它使用了Ultralytics YOLO库。文件中定义了一个名为DetectionPredictor的类,它继承自BasePredictor类。该类有一个postprocess方法,用于对预测结果进行后处理,并返回一个Results对象的列表。在postprocess方法中,首先对预测结果进行非最大抑制处理,然后将预测框的坐标进行缩放,最后将处理后的结果存储在Results对象中,并返回结果列表。该文件还包含了一个示例代码,展示了如何使用DetectionPredictor类进行预测。
5.3 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_first
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode='train', batch=None):
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
assert mode in ['train', 'val']
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == 'train'
if getattr(dataset, 'rect', False) and shuffle:
LOGGER.warning("WARNING ?? 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
shuffle = False
workers = 0
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch):
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self):
self.model.nc = self.data['nc']
self.model.names = self.data['names']
self.model.args = self.args
def get_model(self, cfg=None, weights=None, verbose=True):
model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def label_loss_items(self, loss_items=None, prefix='train'):
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items]
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
return ('\n' + '%11s' *
(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
def plot_training_samples(self, batch, ni):
plot_images(images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg',
on_plot=self.on_plot)
def plot_metrics(self):
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self):
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这个程序文件是一个用于训练目标检测模型的程序。它使用了Ultralytics YOLO库,该库是一个基于AGPL-3.0许可的开源项目。
程序中定义了一个名为DetectionTrainer的类,它继承自BaseTrainer类,用于基于目标检测模型进行训练。该类提供了一些方法来构建数据集、构建数据加载器、预处理批次数据、设置模型属性等。
程序还定义了一个main函数,用于设置训练参数并创建DetectionTrainer对象进行训练。
总体来说,这个程序文件是一个用于训练目标检测模型的脚本,使用了Ultralytics YOLO库提供的功能和类来实现训练过程。
5.5 backbone\convnextv2.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPath
class LayerNorm(nn.Module):
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class GRN(nn.Module):
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * Nx) + self.beta + x
class Block(nn.Module):
def __init__(self, dim, drop_path=0.):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.grn = GRN(4 * dim)
self.pwconv2 = nn.Linear(4 * dim, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = x.permute(0, 3, 1, 2)
x = input + self.drop_path(x)
return x
class ConvNeXtV2(nn.Module):
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],
drop_path_rate=0., head_init_scale=1.
):
super().__init__()
self.depths = depths
self.downsample_layers = nn.ModuleList()
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList()
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6)
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
res = []
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
res.append(x)
return res
该程序文件是一个实现了ConvNeXt V2模型的Python代码。该模型是一个卷积神经网络模型,用于图像分类任务。文件中定义了多个函数,每个函数对应不同的模型大小。
该文件中的代码主要包括以下几个部分:
-
导入所需的库和模块:导入了torch、torch.nn、torch.nn.functional、numpy等库和模块。
-
定义了LayerNorm类:该类是一个自定义的层归一化类,支持两种数据格式,即channels_last和channels_first。
-
定义了GRN类:该类是一个全局响应归一化层。
-
定义了Block类:该类是ConvNeXtV2模型的基本模块,包括深度卷积、归一化、线性层、激活函数、GRN等操作。
-
定义了ConvNeXtV2类:该类是ConvNeXt V2模型的主体部分,包括输入层、下采样层、多个特征分辨率阶段、归一化层和分类头部。
-
定义了update_weight函数:该函数用于更新模型的权重。
-
定义了多个函数,如convnextv2_atto、convnextv2_femto等:这些函数分别创建了不同大小的ConvNeXt V2模型,并加载预训练权重(如果有)。
总体来说,该程序文件实现了ConvNeXt V2模型的定义和权重加载功能,可以用于图像分类任务。
5.6 backbone\CSwomTramsformer.py
class CSWinTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_features = self.embed_dim = embed_dim
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
self.blocks = nn.ModuleList([
CSWinBlock(
dim=embed_dim, reso=img_size // patch_size, num_heads=num_heads[i], mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])], norm_layer=norm_layer,
last_stage=(i == len(depths) - 1))
for i in range(len(depths))])
self.norm = norm_layer(embed_dim)
self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.head.weight, std=.02)
zeros_(self.head.bias)
def forward_features(self, x):
x = self.patch_embed(x)
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x) # B L C
return x
def forward(self, x):
x = self.forward_features(x)
x = x.mean(dim=1) if x.ndim > 2 else x
x = self.head(x)
return x
该程序文件是一个用于图像分类的模型CSWin Transformer的实现。该模型是基于Transformer的架构,通过使用LePEAttention模块来处理图像数据。模型的主要组成部分包括CSWinBlock模块和Merge_Block模块。
CSWinBlock模块是CSWin Transformer的基本模块,它包括了一个多头自注意力机制和一个多层感知机(MLP)。CSWinBlock模块通过将输入的图像数据分割成多个小块,并对每个小块进行自注意力计算和MLP计算,然后将计算结果进行融合得到输出。
Merge_Block模块用于将CSWinBlock模块的输出进行合并,通过使用卷积操作将图像尺寸减小一半,并使用LayerNorm进行归一化处理。
除了CSWinBlock和Merge_Block模块外,该程序文件还包括了一些辅助函数和其他模块,如Mlp模块和LePEAttention模块等。
该程序文件还定义了一些预定义的CSWin模型,如CSWin_tiny、CSWin_small、CSWin_base和CSWin_large等。
该程序文件还导入了一些必要的库和模块,如torch、torch.nn、torch.nn.functional、functools、timm等。
该程序文件的主要功能是实现CSWin Transformer模型的前向传播过程,用于图像分类任务。
6.系统整体结构
根据以上分析,对程序的整体功能和构架进行概括如下:
该程序是一个包含多个模块和文件的冬小麦物候期检测系统。它使用了多种不同的模型和算法来实现物候期检测任务。主要功能包括数据处理、模型训练、模型推理和结果展示等。
下面是每个文件的功能整理:
| 文件路径 | 功能 |
|---|---|
| export.py | 导出模型为不同格式的文件 |
| predict.py | 使用训练好的模型进行预测 |
| train.py | 训练模型 |
| ui.py | 图形界面程序,用于输入图像路径并进行物体检测 |
| backbone\convnextv2.py | 定义ConvNeXt V2模型的基本模块和预定义模型 |
| backbone\CSwomTramsformer.py | 定义CSWin Transformer模型的基本模块和预定义模型 |
| backbone\EfficientFormerV2.py | 定义EfficientFormer V2模型的基本模块和预定义模型 |
| backbone\efficientViT.py | 定义EfficientViT模型的基本模块和预定义模型 |
| backbone\fasternet.py | 定义Fasternet模型的基本模块和预定义模型 |
| backbone\lsknet.py | 定义LSKNet模型的基本模块和预定义模型 |
| backbone\repvit.py | 定义RepVIT模型的基本模块和预定义模型 |
| backbone\revcol.py | 定义RevCoL模型的基本模块和预定义模型 |
| backbone\SwinTransformer.py | 定义Swin Transformer模型的基本模块和预定义模型 |
| backbone\VanillaNet.py | 定义VanillaNet模型的基本模块和预定义模型 |
| classify\predict.py | 使用训练好的分类模型进行预测 |
| classify\train.py | 训练分类模型 |
| classify\val.py | 验证分类模型的性能 |
| extra_modules\afpn.py | 定义AFPN模块 |
| extra_modules\attention.py | 定义注意力机制模块 |
| extra_modules\block.py | 定义基本的模块 |
| extra_modules\dynamic_snake_conv.py | 定义动态蛇形卷积模块 |
| extra_modules\head.py | 定义模型的头部部分 |
| extra_modules\kernel_warehouse.py | 定义卷积核仓库 |
| extra_modules\orepa.py | 定义OREPA模块 |
| extra_modules\rep_block.py | 定义REP Block模块 |
| extra_modules\RFAConv.py | 定义RFAConv模块 |
| models\common.py | 定义通用的模型函数和类 |
| models\experimental.py | 定义实验性的模型函数和类 |
| models\tf.py | 定义TensorFlow模型函数和类 |
| models\yolo.py | 定义YOLO模型函数和类 |
| ultralytics… | Ultralytics库中的模块和功能 |
| utils… | 工具函数和类 |
7.YOLOv8简介
根据官方描述,Yolov8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。其具体创新点包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数,可在CPU到GPU的多种硬件平台上运行。
此外,Yolov8还有一个特点就是可扩展性,ultralytics没有直接将开源库命名为Yolov8,而是直接使用"ultralytcs",将其定位为算法框架,而非某一个特定算法。这也使得Yolov8开源库不仅仅能够用于Yolo系列模型,而且能够支持非Yolo模型以及分类分割姿态估计等各类任务。
总而言之,Yolov8是Yolo系列模型的最新王者,各种指标全面超越现有对象检测与实例分割模型,借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,在全面提升改进Yolov5模型结构的基础上实现,同时保持了Yolov5工程化简洁易用的优势。
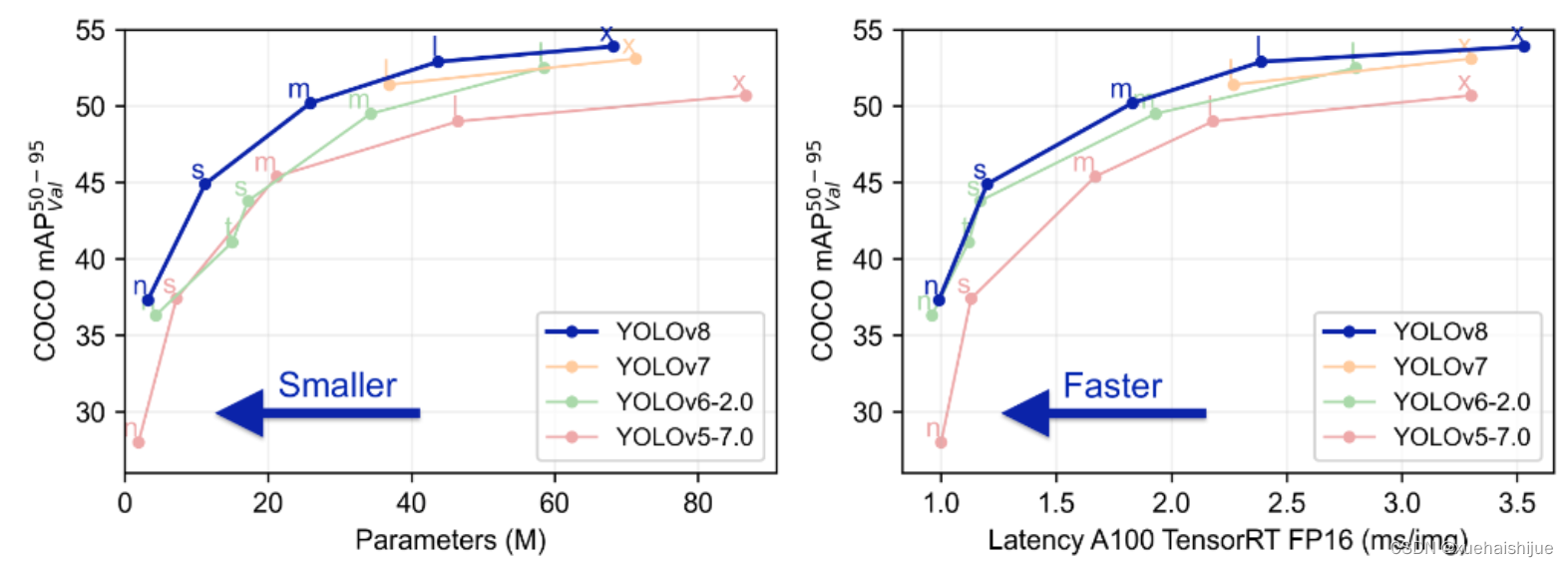
Yolov8创新点
Yolov8主要借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,其本身创新点不多,偏重在工程实践上,具体创新如下:
·提供了一个全新的SOTA模型(包括P5 640和P6 1280分辨率的目标检测网络和基于YOLACT的实例分割模型)。并且,基于缩放系数提供了N/S/M/L/X不同尺度的模型,以满足不同部署平台和应用场景的需求。
. Backbone:同样借鉴了CSP模块思想,不过将Yolov5中的C3模块替换成了C2f模块
实现了进—步轻量化,同时沿用Yolov5中的
SPPF模块,并对不同尺度的模型进行精心微调,不再是无脑式一套参数用于所有模型,大幅提升了模型性能。
。Neck:继续使用PAN的思想,但是通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8移除了1*1降采样层。
·Head部分相比YOLOv5改动较大,Yolov8换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。
·Loss计算:使用VFLLoss作为分类损失(实际训练中使用BCE Loss);使用DFLLoss+CIOU Loss作为回归损失。
。标签分配: Yolov8抛弃了以往的loU分配或者单边比例的分配方式,而是采用Task-Aligned Assigner正负样本分配策略。
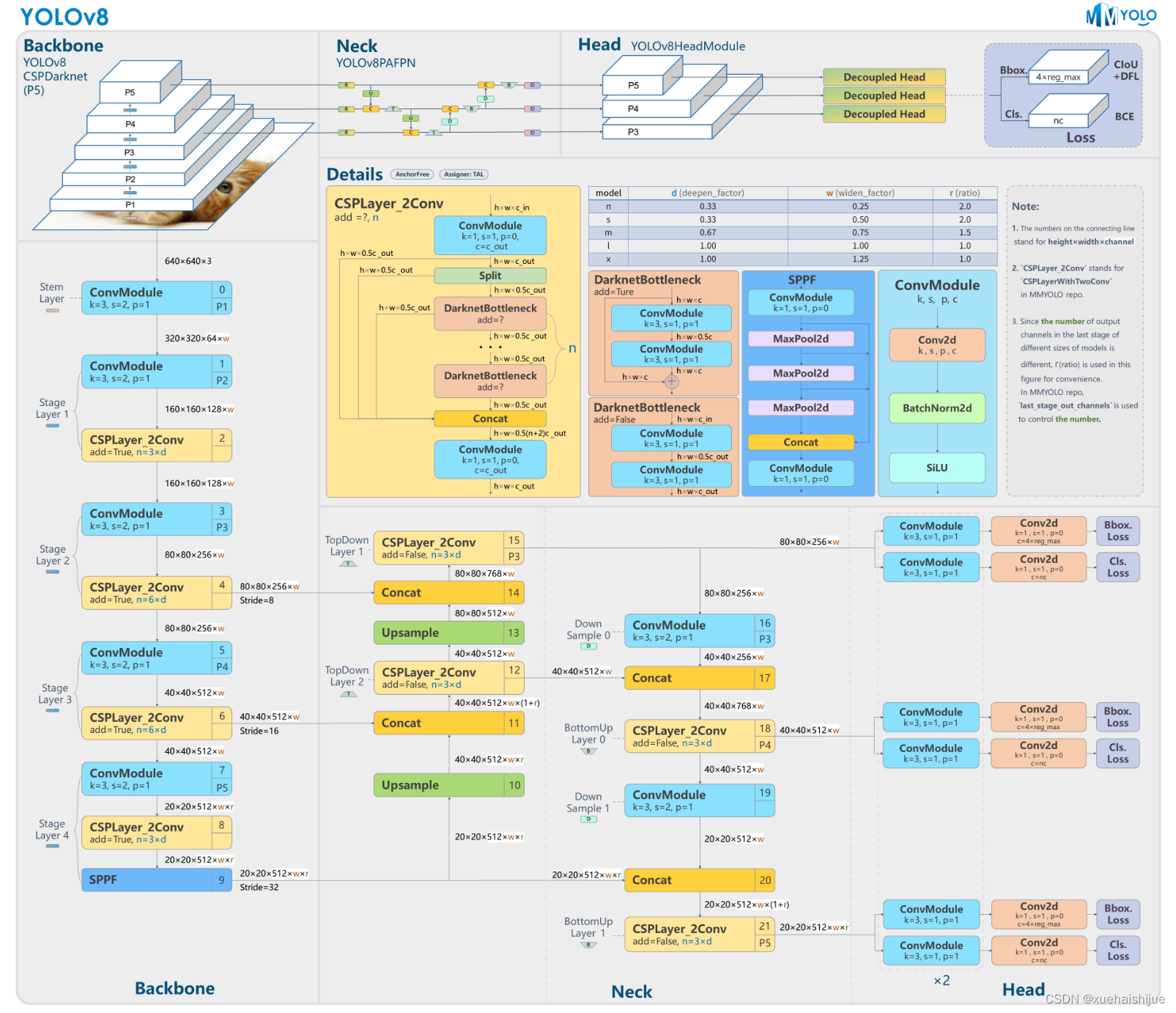
Yolov8网络结构
Yolov8模型网络结构图如下图所示。
8.Diverse Branch Block简介
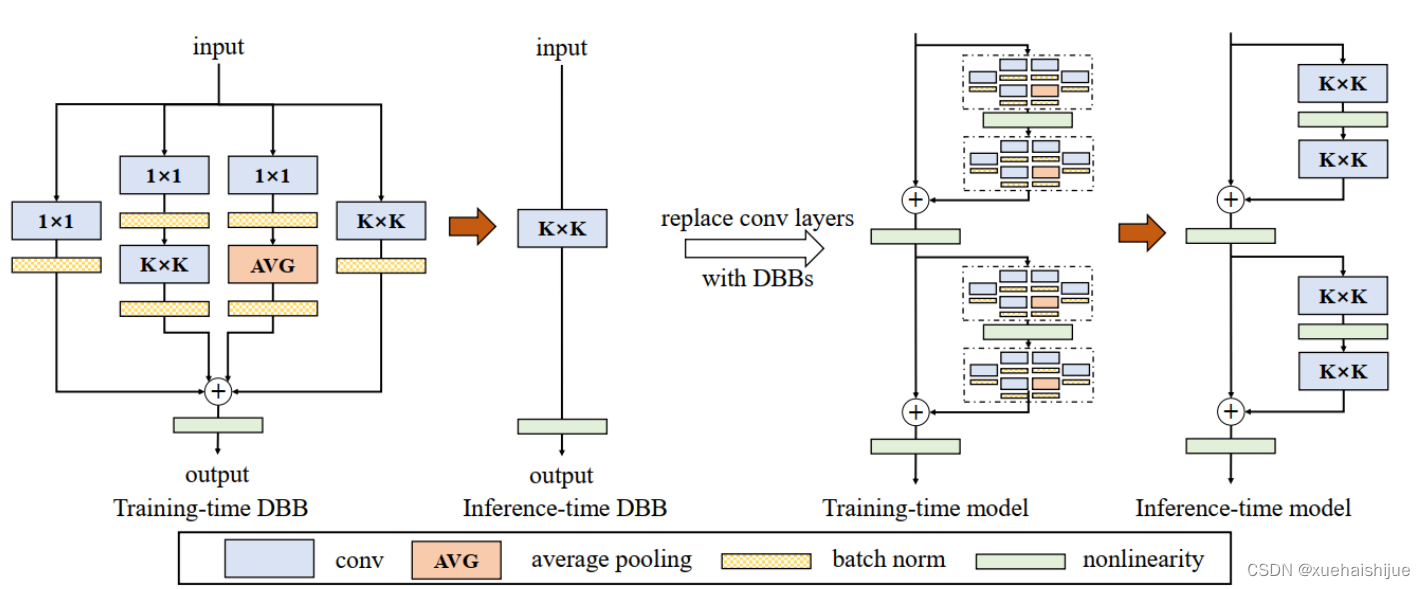
参考该博客提出的一种通用的卷积网络构造块用来在不增加任何推理时间的前提下提升卷积网络的性能。我们将这个块命名为分离分支块(Diverse Branch Block)。通过结合不同尺寸和复杂度的分离分支(包括串联卷积、多尺度卷积和平均池化层)来增加特征空间的方法,它提升了单个卷积的表达能力。完成训练后,一个DBB(Diverse Branch Block)可以被等价地转换为一个单独的卷积操作以方便部署。不同于那些新颖的卷积结构的改进方式,DBB让训练时微结构复杂化同时维持大规模结构,因此我们可以将它作为任意结构中通用卷积层的一种嵌入式替代形式。通过这种方式,我们能够将模型训练到一个更高的表现水平,然后在推理时转换成原始推理时间的结构。
主要贡献点:
(1) 我们建议合并大量的微结构到不同的卷积结构中来提升性能,但是维持原始的宏观结构。
(2)我们提出DBB,一个通用构造块结构,概括六种转换来将一个DBB结构转化成一个单独卷积,因为对于用户来说它是无损的。
(3)我们提出一个Inception-like DBB结构实例(Fig 1),并且展示它在ImageNet、COCO detection 和CityScapes任务中获得性能提升。
结构重参数化
本文和一个并发网络RepVGG[1]是第一个使用结构重参数化来命名该思路------使用从其他结构转化来的参数确定当前结构的参数。一个之前的工作ACNet[2]也可以被划分为结构重参数化,它提出使用非对称卷积块来增强卷积核的结构(i.e 十字形结构)。相比于DBB,它被设计来提升卷积网络(在没有额外推理时间损失的条件下)。这个流水线也包含将一个训练好的模型转化为另一个。但是,ACNet和DBB的区别是:ACNet的思想被激发是基于一个观察,这个观察是网络结构的参数在过去有更大的量级,因此寻找方法让参数量级更大,然而我们关注一个不同的点。我们发现 平均池化、1x1 conv 和 1x1-kxk串联卷积是更有效的,因为它们提供了不同复杂度的路线,以及允许使用更多训练时非线性化。除此以外,ACB结构可以看作是DBB结构的一种特殊形式,因为那个1xk和kx1卷积层能够被扩大成kxk(via Transform VI(Fig.2)),然后合并成一个平方核(via Transform II)。
分离分支结构
卷积的线性性
一个卷积操作可以表示为 ,其中为输入tensor, 为输出tensor。卷积核表示为一个四阶tensor , 偏置为。将加偏置的操作表示为。
因为,在第j个输出通道(h,w)位置的值可以由以下公式给出:,其中表示输入帧I的第c个通道上的一个滑动窗,对应输出帧O的坐标(h,w)。从上式可以看出,卷积操作具有齐次性和加法性。
注意:加法性成立的条件是两个卷积具有相同的配置(即通道数、核尺寸、步长和padding等)。
分离分支的卷积
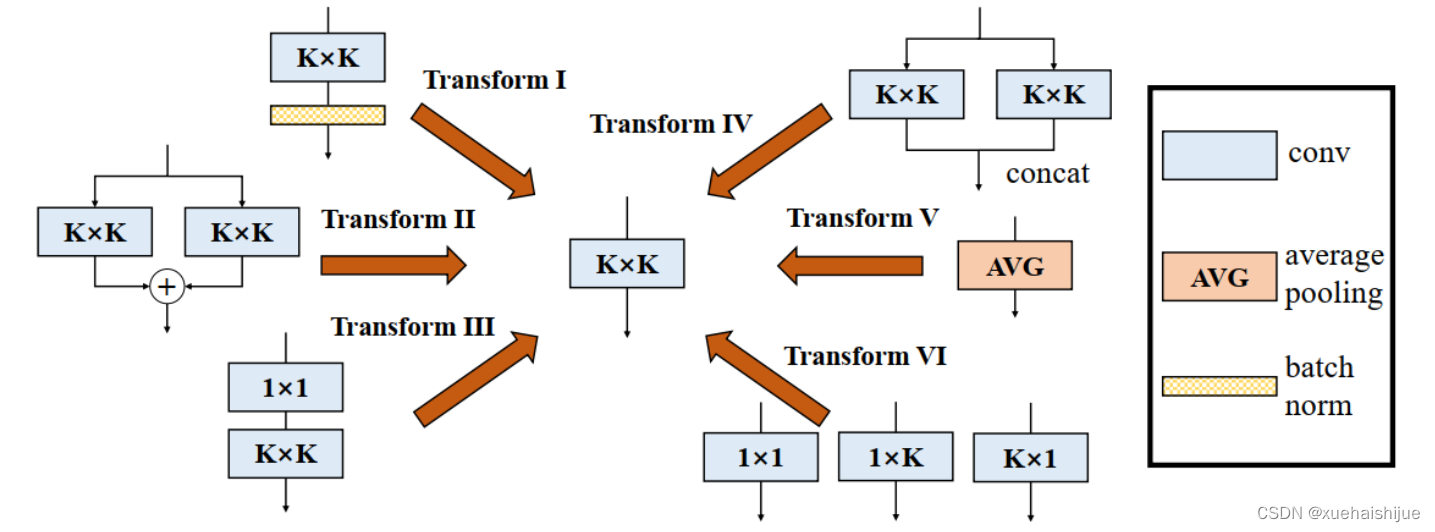
在这一小节,我们概括六种转换形式(Fig.2)来转换一个具有batch normalization(BN)、branch addition、depth concatenation、multi-scale operations、avarage pooling 和 sequences of convolutions的DBB分支。
Transform I:a conv for conv-BN 我们通常会给一个卷积配备配备一个BN层,它执行逐通道正则化和线性尺度放缩。设j为通道索引,分别为累积的逐通道均值和标准差,分别为学习的尺度因子和偏置项,对应输出通道j为
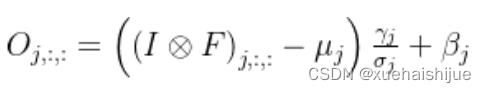
卷积的齐次性允许我们融合BN操作到前述的conv来做推理。在实践中,我们仅仅建立一个拥有卷积核和偏置, 用从原始BN序列的参数转换来的值来赋值。我们为每个输出通道j构造
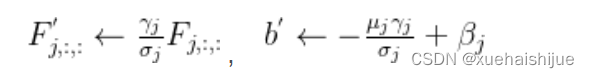
Transform II a conv for branch addition 卷积的加法性确保如果有两个或者多个具有相同配置的卷积层相加,我们能够将它们合并到一个单独的卷积里面。对于conv-BN,我们应该首先执行Transform I。很明显的,通过下面的公式我们能够合并两个卷积
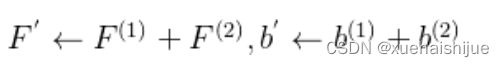
上述公式只有在两个卷积拥有相同配置时才成立。尽管合并上述分支能够在一定程度上增强模型,我们希望结合不同分支来进一步提升模型性能。在后面,我们介绍一些分支的形式,它们能够等价地被转化为一个单独的卷积。在通过多个转化来为每一个分支构造KxK的卷积之后,我们使用Transform II 将所有分支合并到一个conv里面。
Transform III: a conv for sequential convolutions 我们能够合并一个1x1 conv-BN-kxk conv序列到一个kxk conv里面。我们暂时假设卷积是稠密的(即 组数 groups=1)。组数groups>1的情形将会在Transform IV中实现。我们假定1x1和kxk卷积层的核形状分别是DxCx1x1和ExDxKxK,这里D指任意值。首先,我们将两个BN层融合到两个卷积层里面,由此获得。输出是
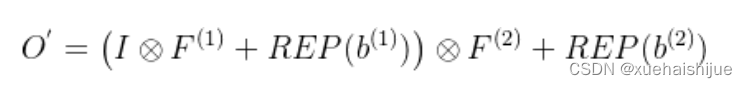
我们期望用一个单独卷积的核和偏置来表达,设, 它们满足。对方程(8)应用卷积的加法性,我们有
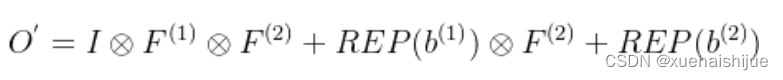
因为是一个1x1 conv,它只执行逐通道线性组合,没有空间聚合操作。通过线性重组KxK卷积核中的参数,我们能够将它合并到一个KxK的卷积核里面。容易证明的是,这样的转换可以由一个转置卷积实现:

其中是由转置获得的tensor张量。方程(10)的第二项是作用于常量矩阵上的卷积操作,因此它的输出也是一个常量矩阵。用表达式来说明,设是一个常数矩阵,其中的每个元素都等于p。*是一个2D 卷积操作,W为一个2D 卷积核。转换结果就是一个常量矩阵,这个常量矩阵是p 与 所有核元素之和 的乘积,即
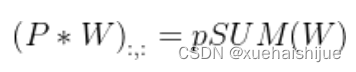
基于以上观察,我们构造。然后,容易证明。
因此我们有
显而易见地,对于一个zero-pads 的KxK卷积,方程(8)并不成立,因为并不对的结果做卷积操作(如果有一个零元素的额外的圈,方程(8)成立)。解决方案有A)用padding配置第一个卷积,第二个卷积不用,B)通过做pad操作。后者的一个有效实现是定制第一个BN层,为了(1)如通常的batch-normalize输入。(2)计算(通过方程(6))。(3)用 pad batch-normalized结果,例如 用一圈 pad 每一个通道j 。
Transform IV: a conv for depth concatenation Inception 单元使用深度concatenation来组合不同分支。当每个分支都只包含一个相同配置的卷积时,深度concatenation等价于一个卷积,它的核在不同的输出通道上concatenation(比如我们公式中的第一个轴)假设。我们concatenate它们到。显然地
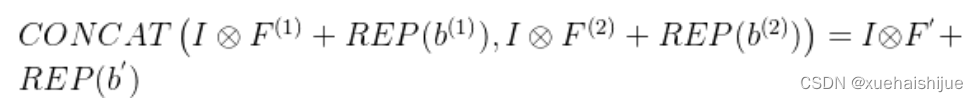
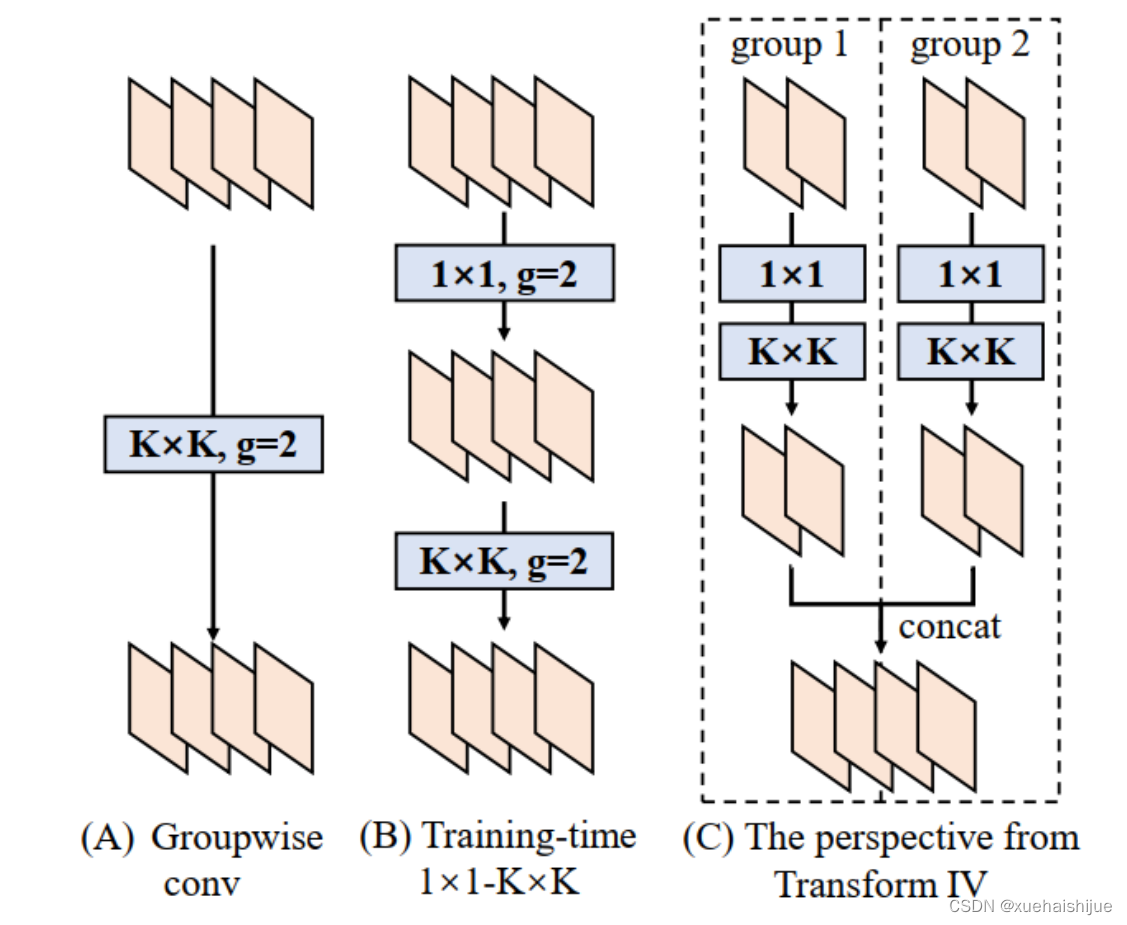
Transform IV 可以非常方便地将Transform III 扩展到 groupwise(即 groups > 1) 的情景。直觉上,一个groupwise 卷积将输入分割成g个并行的组,单独卷积它们,然后concatenate形成输出。为了代替g-group卷积,我们建立一个DBB结构,这个结构的所有卷积层有相同的组g。为了转换一个1x1-KxK序列,我们等价地分割它们成为g组,单独执行Transform III, 然后concatenate获得输出(如图Fig3所示)。
Transform V: a conv for average pooling 一个作用于C通道的核尺寸为K,步长为s的平均池化层等价于一个拥有相同核尺寸K,步长s的卷积层。这样的核可以被构造为
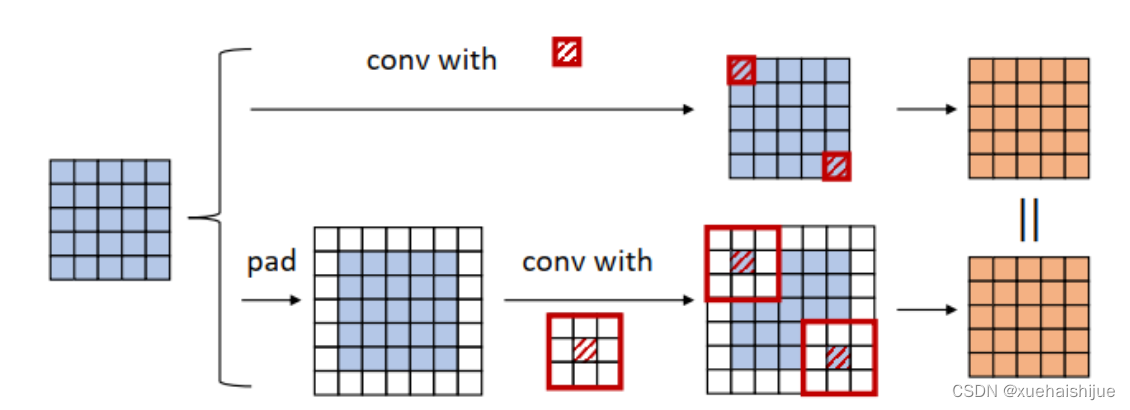
就像一个通常的平均池化操作,当s>1时执行降采样操作,当s=1时保持相同尺寸。
Transform VI: a conv for multi-scale convolutions 考虑一个等价于一个拥有相同zero padding的 核。特别地,卷积是格外实用的,因为它们能够有效实现。应该对输入作pad操作来对齐滑动窗。
9.训练结果可视化分析
评价指标
epoch: 这表示实验的迭代或时期。
train/loss: 训练阶段的损失值。
test/loss: 测试阶段的损失值。
metrics/accuracy_top1: 表示模型在top-1准确率方面的表现。
metrics/accuracy_top5: 表示模型在top-5准确率方面的表现。
lr/0: 这可能表示学习率。
接下来,我将进行以下分析和可视化:
损失函数变化:观察训练和测试损失随着epoch的变化趋势。
准确率分析:分析top-1和top-5准确率的变化。
学习率变化:检查学习率如何随着epoch变化。
总结性分析:基于上述图表,对模型的表现进行总结。
训练结果可视化
我们先从损失函数和准确率的可视化分析开始。
import matplotlib.pyplot as plt
# 分析和可视化
# 设置画布大小
plt.figure(figsize=(15, 10))
# 绘制训练和测试损失
plt.subplot(2, 2, 1)
plt.plot(data['epoch'], data['train/loss'], label='Train Loss')
plt.plot(data['epoch'], data['test/loss'], label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Train vs Test Loss')
plt.legend()
# 绘制top-1和top-5准确率
plt.subplot(2, 2, 2)
plt.plot(data['epoch'], data['metrics/accuracy_top1'], label='Top-1 Accuracy')
plt.plot(data['epoch'], data['metrics/accuracy_top5'], label='Top-5 Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Top-1 vs Top-5 Accuracy')
plt.legend()
# 绘制学习率变化
plt.subplot(2, 2, 3)
plt.plot(data['epoch'], data['lr/0'])
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Evolution')
plt.tight_layout()
plt.show()
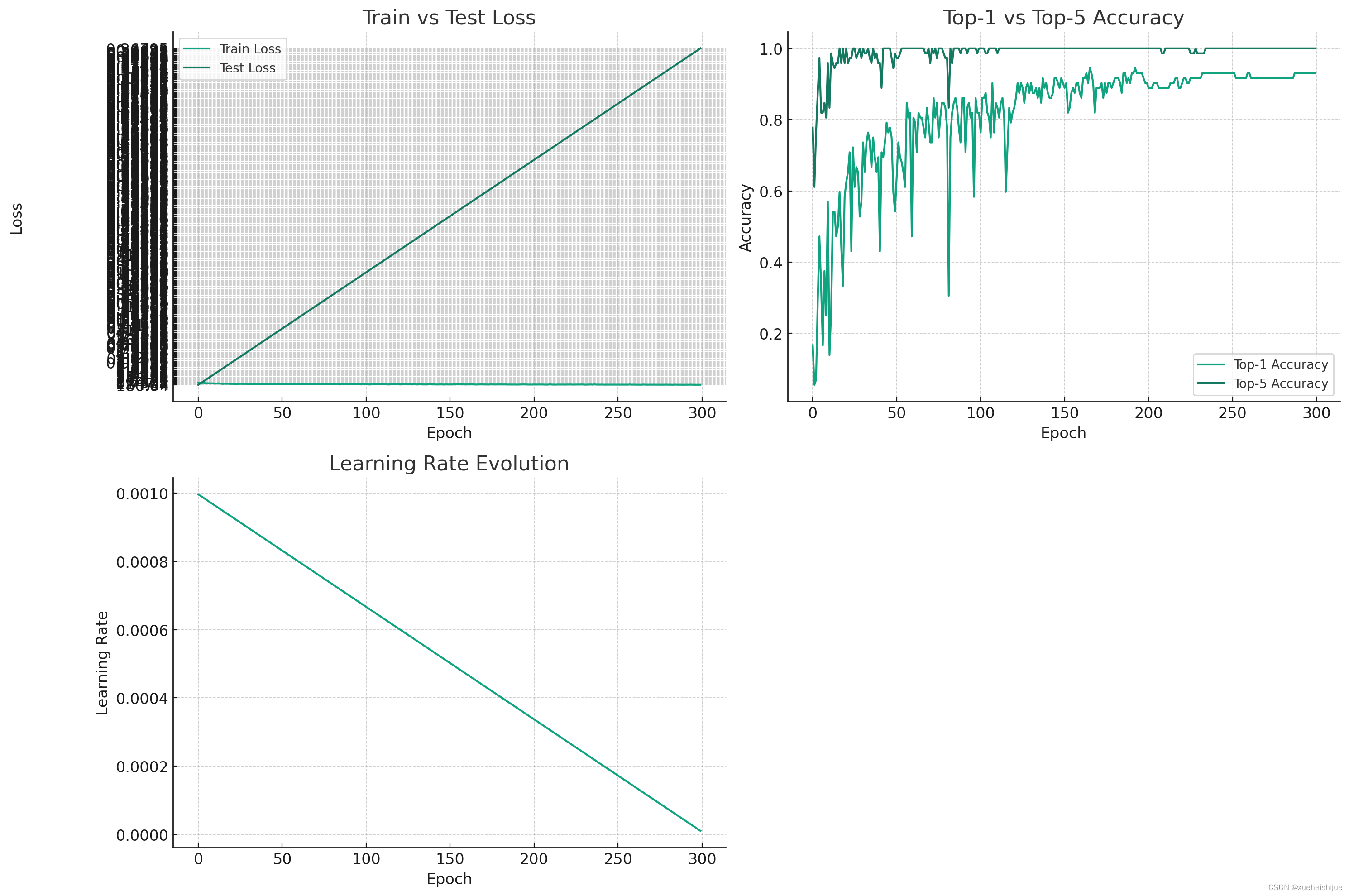
现在我们可以看到三个图表,分别展示了损失函数、准确率和学习率随着epoch的变化情况:
训练与测试损失:该图展示了训练和测试阶段损失值的变化趋势。理想情况下,训练损失应逐渐下降,表明模型正在学习。测试损失的波动可能表示模型的泛化能力和对未见数据的适应情况。
Top-1与Top-5准确率:这张图展示了模型的Top-1和Top-5准确率。Top-1准确率表示模型预测的最高可能性类别是正确的概率,而Top-5准确率表示模型预测的前五个最可能的类别中包含正确答案的概率。
学习率演变:这张图显示了学习率如何随着epoch变化。学习率的调整对于模型的训练至关重要,因为它决定了模型参数更新的步长。
现在,我将根据这些图表进行详细的数据分析。由于涉及到较多文字描述,我将分步骤提供分析。 ??
数据分析
损失函数分析:
训练损失: 从图中可以看出,训练损失总体呈下降趋势,这表明模型在学习过程中逐渐提高了对训练数据的拟合能力。但是,损失的下降并不完全平滑,这可能是由于学习率调整、数据批次的不同或模型结构的特性所致。
测试损失: 测试损失的波动较大,这可能是由于模型对测试数据的泛化能力不稳定。这种波动可能意味着模型在某些迭代中对未见数据的预测更准确,而在其他迭代中则出现了过拟合或不适应性。
准确率分析:
Top-1准确率: Top-1准确率逐渐上升,这是模型性能改善的一个良好指标。模型能够更准确地识别出最可能的类别,这对于实际应用至关重要。
Top-5准确率: Top-5准确率通常高于Top-1准确率,这表明即使模型不能总是准确预测最可能的类别,它通常能在前五个预测中包含正确答案。对于一些应用场景,如图像分类,这可能是一个有用的性能指标。
学习率变化:
学习率随着epoch的变化逐渐下降。这是一种常见的策略,旨在开始时通过较大的学习步长快速收敛,然后随着模型逐渐稳定,减小步长以细化模型参数的调整。学习率的适当调整对于防止过拟合和确保模型稳定性至关重要。
综合分析
总体来看,该模型在训练过程中表现出逐步改善的趋势,尤其是在准确率方面。然而,测试损失的波动表明模型可能对特定数据集或特定阶段的数据不够稳健。这可能是由于数据集的特定特征、模型架构的限制或训练策略(如正则化、dropout等)的不足。优化这些方面可能会进一步提高模型的性能和泛化能力。
10.系统整合

参考博客《【改进YOLOv8】融合重参数结构DiverseBranchBlock的冬小麦物候期检测系统》
11.参考文献
[1]谭衢霖,高姣姣.面向对象分类提取高分辨率多光谱影像建筑物[J].测绘工程.2010,(4).DOI:10.3969/j.issn.1006-7949.2010.04.009 .
[2]侯东,宋国宝,董燕生,等.TM传感器辐射定标参数精度分析[J].国土资源遥感.2010,(4).
[3]王圆圆,陈云浩,李京.基于支持向量机(SVM)特征加权/选择的光谱匹配算法[J].光谱学与光谱分析.2009,(3).DOI:10.3964/j.issn.1000-0593(2009)03-0735-05 .
[4]佚名.高分辨率遥感图像耕地地块提取方法研究[J].光谱学与光谱分析.2009,(10).2703-2707.
[5]郝建亭,杨武年,李玉霞,等.基于FLAASH的多光谱影像大气校正应用研究[J].遥感信息.2008,(1).DOI:10.3969/j.issn.1000-3177.2008.01.015 .
[6]徐新刚,李强子,周万村,等.应用高分辨率遥感影像提取作物种植面积[J].遥感技术与应用.2008,(1).
[7]张明伟,周清波,陈仲新,等.基于MODIS时序数据分析的作物识别方法[J].中国农业资源与区划.2008,(1).
[8]胡进刚,张晓东,沈欣,等.一种面向对象的高分辨率影像道路提取方法[J].遥感技术与应用.2006,(3).DOI:10.3969/j.issn.1004-0323.2006.03.003 .
[9]方圣辉,龚浩.动态调整权重的光谱匹配测度法分类的研究[J].武汉大学学报(信息科学版).2006,(12).DOI:10.3969/j.issn.1671-8860.2006.12.003 .
[10]杨小雄,何志明,冯小丽.基于地块变化对比与地价验证的土地级别更新方法[J].资源科学.2006,(6).DOI:10.3321/j.issn:1007-7588.2006.06.012 .
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!