【深度学习】DataComp论文,数据集介绍,大数据模型的数据集介绍
参考:
https://laion.ai/blog/datacomp/
论文:https://arxiv.org/abs/2304.14108
论文报告的一些内容
摘要
多模态数据集是近期如CLIP、Stable Diffusion和GPT-4等突破的关键组成部分,但它们的设计并没有得到与模型架构或训练算法相同的研究关注。为了解决这一机器学习生态系统中的不足,我们引入了DATACOMP,这是一个围绕来自Common Crawl的新候选池的128亿图像-文本对进行数据集实验的测试平台。参与者在我们的基准设计中开发新的过滤技术或策划新的数据源,然后通过运行我们的标准化CLIP训练代码并在38个下游测试集上测试结果模型来评估他们的新数据集。我们的基准包括涵盖四个数量级的多个计算规模,这使得研究不同资源的研究者可以使用该基准。我们的基线实验显示,DATACOMP工作流导致更好的训练集。我们的最佳基线DATACOMP-1B使得使用相同的训练程序和计算从头开始训练CLIP ViT-L/14在ImageNet上的零射击准确率为79.2%,超过OpenAI的3.7个百分点。我们在www.datacomp.ai上发布DATACOMP和所有相关代码。
1 引言
近期多模态学习的进步,如CLIP、DALL-E、Stable Diffusion、Flamingo和GPT-4,在零射击分类、图像生成和上下文学习方面提供了前所未有的泛化能力。尽管这些进步使用了不同的算法技术,例如对比学习、扩散或自回归建模,但它们都依赖于一个共同的基础:包含成对图像-文本示例的大型数据集。尽管图像-文本数据集起着核心作用,但人们对它们知之甚少。许多最先进的数据集是专有的,即使对于公开数据集,如LAION-2B,设计选择的影响也不清楚。在这篇论文中,我们提出了DATACOMP,这是一个新的多模态数据集设计基准。DATACOMP的焦点是在组装大型训练数据集时出现的两个关键挑战:训练的数据源以及如何过滤给定的数据源。我们的第三项贡献是对数据集设计的规模趋势进行调查。我们的第四项贡献是超过三百个基线实验,包括查询标题以获取相关关键词、基于图像嵌入进行过滤以及在CLIP分数上应用阈值。最后,我们的第五项贡献是DATACOMP-1B,一个新的多模态数据集。为了使DATACOMP成为一个控制数据集实验的共享环境,我们在www.datacomp.ai上公开发布了所有相关的代码。
2 相关工作
我们回顾了最相关的工作,并在附录C中包括了更多相关工作。
数据策划的影响。经典工作考虑数据集清理和异常值移除,以排除可能导致不良模型偏见的样本。相关的工作发展了核心选择算法,旨在选择导致与整个数据集训练相同性能的数据子集。最近的努力经常在已经策划过的数据集上进行。DATACOMP通过将数据中心的调查与大规模图像-文本训练对齐,弥合了这一差距。
DATACOMP 基准测试
DATACOMP 旨在促进以数据为中心的实验。传统的基准测试重点在于模型设计,而 DATACOMP 则围绕数据集开发,以便使用这些数据集训练高准确度的模型。我们专注于大型图像-文本数据集,并通过从头开始训练 CLIP 模型[111]并在 38 个下游图像分类和检索任务上评估其来量化数据集提交。此外,我们还有三个秘密测试集,将在一年后发布,以防止过拟合。为了方便这样的研究,我们提供了一个来自公共互联网的未筛选图像-文本对的候选池。我们的基准测试提供两个轨迹:一个要求参与者从我们提供的池中筛选样本,另一个则允许参与者使用外部数据。此外,DATACOMP 的结构可以适应具有不同计算资源的参与者:每个轨迹分为四个规模,计算要求各不相同。接下来,我们将讨论高级设计决策、构建一个 1280 亿的图像-文本数据池以促进比赛、基准测试轨迹、模型训练和评估。
3.1 比赛设计
概述。在许多机器学习领域,更大的数据集通常导致性能更好的模型[87, 79, 73, 107, 66, 28, 19, 111, 112]。因此,仅比较大小相同的数据集是一个自然的起点。但这种方法有缺陷,因为控制数据集大小忽略了关键的筛选约束:候选池大小(即要收集的图像-文本对的数量)和训练计算。为了使 DATACOMP 成为一个真实的基准测试,我们在筛选轨迹中固定候选池,但允许参与者控制训练集的大小。
计算成本是另一个相关的约束。为了使不同大小的数据集处于同一水平,我们规定了总的训练样本数。例如,在 1280 亿的计算规模和筛选后的数据集 A 和 B 中,A 和 B 分别有 64 亿和 32 亿的图像-文本对。在这个规模上,我们对 A 进行两次训练,而对 B 进行四次。我们实验的一个关键结果是,规模较小、筛选得更为严格的数据集可以导致更好的泛化模型。
比赛轨迹。组装训练数据集的两个关键过程是筛选数据源[128, 129, 20]和聚合数据源[36, 37]。为反映这种结构,DATACOMP 有两个轨迹:筛选轨迹,参与者从 COMMONPOOL 中选择样本的子集;自带数据轨迹 (BYOD),参与者可以使用任何数据源。每个轨迹的关键决策在第 3.2 和 3.3 节中描述。有关完整比赛轨迹规则,请参见附录 A。
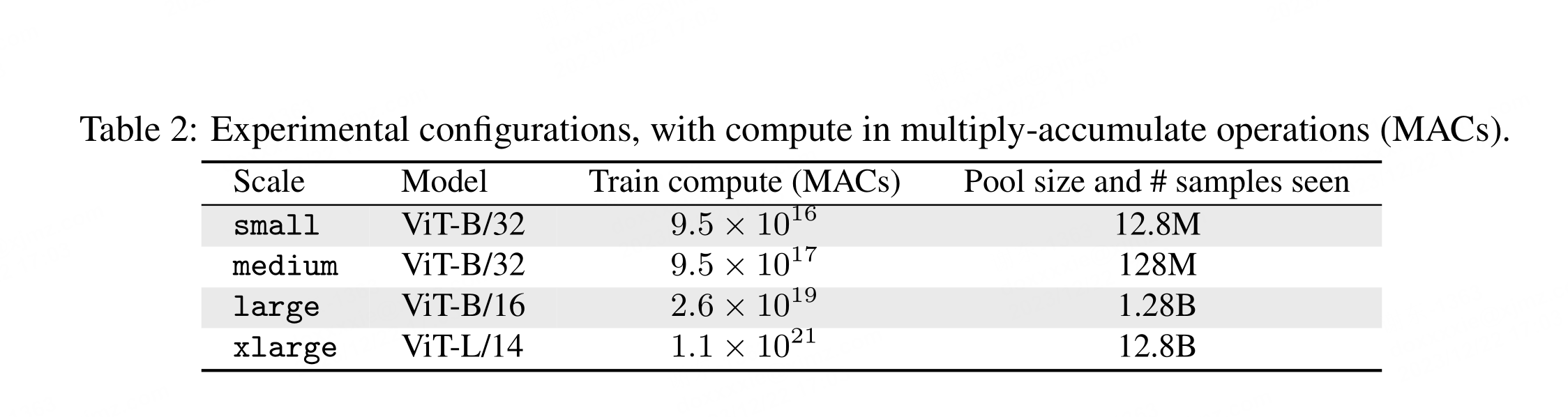
比赛计算规模。为了研究扩展趋势并适应具有不同计算资源的参与者,我们使用四个计算规模构建 DATACOMP:小、中、大和超大。每个新规模都将训练过程中看到的样本数增加 10 倍(从 1280 万到 1280 亿样本),并且我们提供的池也按同样的因子增加(从 1280 万样本到 1280 亿样本)。表 2 提供了每个规模使用的实验配置。对于小规模,我们在 A100 GPU 上运行了 4 小时,对于超大规模,我们在 512 个 GPU 上运行了 81 小时。
3.2 筛选轨迹的 COMMONPOOL 生成
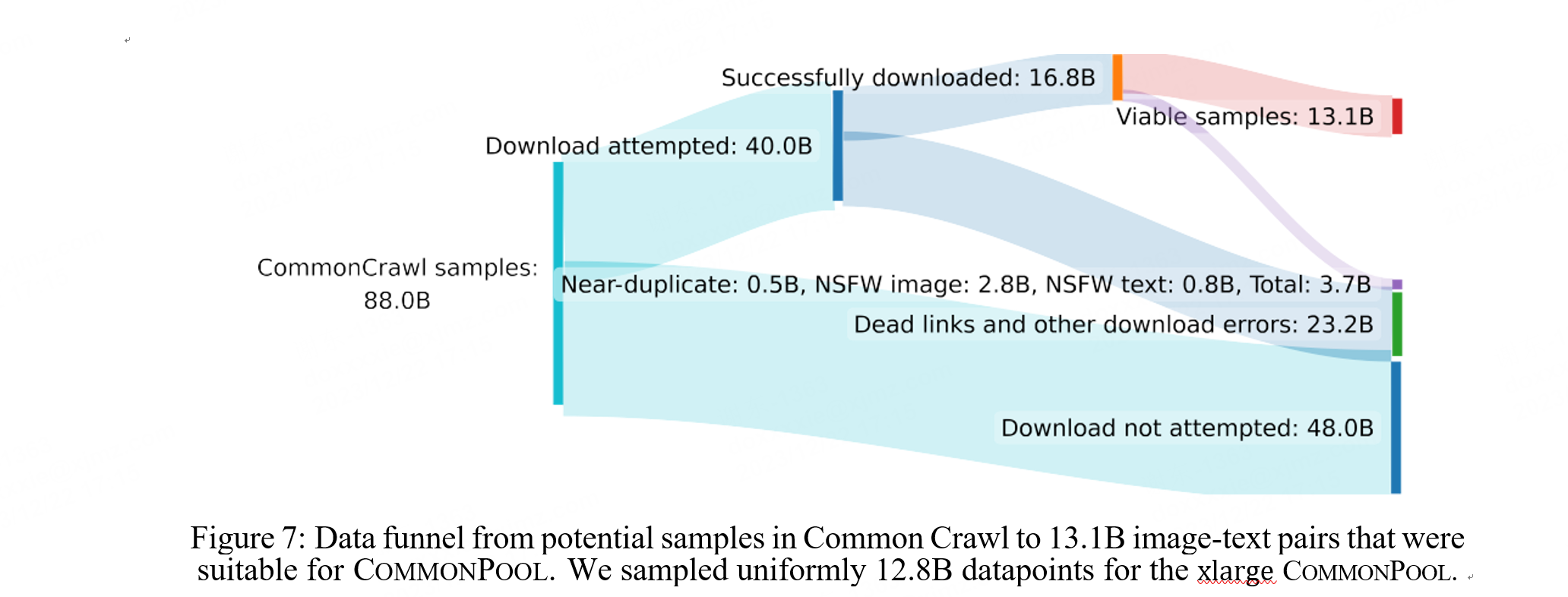
我们从 Common Crawl[3] 构建了一个大规模的图像-文本对池,称为 COMMONPOOL。CommonPool 作为图像 url-文本对索引在 CC-BY-4.0 许可下分发。我们的池构建流程有四个步骤:url 提取和数据下载、NSFW 检测、评估集去重和人脸模糊处理。我们还为每个样本提供了元数据(例如,CLIP 特征)。从超大的 COMMONPOOL 开始,我们获取连续的随机子集以创建大、中和小的 COMMONPOOL。
3.3 自带数据轨迹 (BYOD) 轨迹
尽管 COMMONPOOL 可以用于研究不同的筛选技术,但现代的顶级模型通常训练于来自不同来源的数据。为了促进从多个来源筛选数据的非专有研究,我们实例化了一个独立的 DATAC
5.2 DATACOMP 设计分析
COMMONPOOL 和 LAION 使用相同的过滤方式具有可比性。为了验证我们的数据集构建,我们展示了在我们的数据池上采用 LAION-2B 的过滤技术可以构建与其相当的数据集。LAION-2B 选择所有英文标题的样本,并使用训练有素的 ViT-B/32 CLIP 模型的余弦相似度得分超过 0.28 的样本。我们使用相同数量的样本(大规模,130M)在我们的数据池上比较这种过滤方法。结果显示,不同的数据源表现相当:在 ImageNet 上的准确率分别为 55.3% 和 55.7%,在我们的池和 LAION-2B 上的平均性能分别为 0.501 和 0.489。
各种规模之间的一致性:我们发现在不同规模上,过滤策略的排名通常是一致的。如图 3 所示,小规模和中规模的基线是正相关的。此外,在附录表 22 中显示,不同规模对之间的性能排名相关性很高,介于 0.71 和 0.90 之间。
在训练变化中的一致性:DATACOMP 固定了训练过程,所以一个自然的问题是 DATACOMP 的更好的数据集在 DATACOMP 之外是否更好。尽管 DATACOMP-1B 是在 xlarge 规模上训练的,但我们在附录表 23 中展示了即使在 ViT-B/16 或 ViT-B/32 上替换训练,DATACOMP-1B 的性能优于 OpenAI 的 WIT 和 LAION-2B。此外,我们发现修改如训练步骤和批次大小的超参数对下游性能上不同的数据筛选方法的相对顺序影响很小。超参数消融的详细信息在附录 L 中。
5.3 评估趋势
ImageNet 的准确性是指示性的,但不是完整的图景。与 Kornblith 等人类似,附录图 25 中我们发现 ImageNet 的性能与我们研究的所有数据集的平均性能高度相关,总体相关性为 0.99。但是,ImageNet 的性能并不代表所有评估任务,因为 ImageNet 准确性与其他个别数据集上的准确性之间的相关性有很大的变化。
鲁棒性和公平性:在数据分布变化下,典型的目标任务训练模型往往性能大幅下降,而零射击 CLIP 模型已知在许多分布上表现强劲。在附录图 26 中,我们展示了使用我们数据池中的数据训练的 CLIP 模型比 Taori 等人的测试床中的 ImageNet 训练模型更具鲁棒性。
6 限制和结论
在社会风险方面,从公共互联网创建图像文本对索引可能存在问题。因此,我们希望未来的工作将进一步探索 COMMONPOOL 和 DATACOMP-1B 的偏见和风险。我们看到 DATACOMP 作为改进训练数据集的第一步,并希望我们的新基准将促进进一步的研究。
datacomp-1B 数据质量比lainon2B要好

不同规模数据有多少数据
数据处理
NSFW过滤:使用Detoxify模型[60],特别是多语言XLM-RoBERTa变体,扫描与每个图像相关的文本,以识别并过滤可能被视为不安全或不适当的内容。
人脸模糊:为了保护我们数据集中的个人隐私,我们使用SCRFD人脸检测器[53]识别并提取图像中的面部区域,并对这些区域进行模糊处理,确保个人的身份得到匿名保护。
去重:为了确保数据的完整性并防止冗余,我们使用Yokoo提出的去重模型[150],通过余弦相似度阈值0.604169识别并从COMMONPOOL中移除重复或近似的图像。
数据来源
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!