Halcon深度学习,语义分割,预处理和部署过程
halcon在深度学习中提供了7种学习方式和例子。其中最为常见的为语义分割,一般使用与在需要标注显示的缺陷检测项目中。几乎所有的2D缺陷检测都可以使用语义分割作为项目部署。
先上完整程序
预处理部分
*** 设置输入输出路径 ***
*总路径
AllDir := 'E:/HALCONDeepingLearn/单一缺陷/训练图/训练'
*图片路径
ImageDir := AllDir +'/全部训练_images'
*语义分割标注好的图像,label,分割图片路径
DivisionImagesDir := AllDir + '/全部训练_labels'
*存放数据总路径,存放输出的全部参数
DataDir := AllDir + '/data'
*预处理后的路径
DataDirectoryBaseName := DataDir + '/dldataset'
*存储预处理参数
PreprocessParamFileBaseName := DataDir + '/dl_preprocess_param'
* 预处理后DLDataset的文件路径。
*注:调整DataDirectory预处理后与另一个图像大小。
DataDirectory :=AllDir + '/data/dldataset/samples'
DLDatasetFileName := AllDir + '/data/dldataset'+ '/dl_dataset.hdict'
*最终训练模型的输出路径。
FinalModelBaseName := AllDir + '/final_dl_model_segmentation'
*最优评价模型的输出路径。
BestModelBaseName := AllDir + '/best_dl_model_segmentation'
*** 设置参数 ***
*类别名称
ClassNames := ['好','凸粉','擦花']
*类别ID
ClassIDs := [0,1,2]
*拆分数据集,训练百分比例,验证百分比例
TrainingPercent := 70
ValidationPercent := 15
*图片尺寸参数,图像宽,图像高,图像颜色通道数
ImageWidth := 400
ImageHeight := 400
ImageNumChannels := 3
*图片灰度范围
ImageRangeMin := -127
ImageRangeMax := 128
*图像预处理的进一步参数
*图像归一化,用于缩小图像分辨率
ContrastNormalization := 'none'
*域处理,全局缩放。crop_domain(指定缩放,与reduce_domain相使用)
DomainHandling := 'full_domain'
*不需要训练的类别的ID
IgnoreClassIDs := []
*设置背景类ID
SetBackgroundID := []
ClassIDsBackground := []
*随机种子
SeedRand := 42
*** 处理图片并进行拆分 ***
*设置随机种子
set_system ('seed_rand', SeedRand)
*通过参数将文件夹中数据分割为数据集 参数:图像路径、分割图像路径、类别名称、类别ID、图像路径列表、分割图像路径列表、字典、生成的数据集
read_dl_dataset_segmentation (ImageDir, DivisionImagesDir, ClassNames, ClassIDs, [], [], [], DLDataset)
*拆分数据集。数据集字典,训练图像百分比,验证图像百分比,测试图像百分比
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, [])
************************************** 预处理数据集 *************************
*创建预处理输出文件夹
file_exists (DataDir, FileExists)
if (not FileExists)
make_dir (DataDir)
endif
*创建预处理参数
*classification', 'detection', 'segmentation';分类,检测,分割
create_dl_preprocess_param ('segmentation', ImageWidth, ImageHeight, ImageNumChannels, ImageRangeMin, ImageRangeMax, ContrastNormalization, DomainHandling, IgnoreClassIDs, SetBackgroundID, ClassIDsBackground, [], DLPreprocessParam)
*预处理后的数据集路径
PreprocessParamFile := PreprocessParamFileBaseName +'.hdict'
*将参数写入
write_dict (DLPreprocessParam, PreprocessParamFile, [], [])
*创建字典
create_dict (GenParam)
set_dict_tuple (GenParam, 'overwrite_files', true)
*预处理
preprocess_dl_dataset (DLDataset, DataDirectoryBaseName, DLPreprocessParam, GenParam, DLDatasetFilename)
*******************************检查********************
*随机选取10张图像
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
find_dl_samples (DatasetSamples, 'split', 'train', 'match', SampleIndices)
tuple_shuffle (SampleIndices, ShuffledIndices)
read_dl_samples (DLDataset, ShuffledIndices[0:9], DLSampleBatchDisplay)
*
create_dict (WindowHandleDict)
for Index := 0 to |DLSampleBatchDisplay| - 1 by 1
*可视化不同的图像、注释和推理结果
dev_display_dl_data (DLSampleBatchDisplay[Index], [], DLDataset, ['image','segmentation_image_ground_truth'], [], WindowHandleDict)
get_dict_tuple (WindowHandleDict, 'segmentation_image_ground_truth', WindowHandleImage)
dev_set_window (WindowHandleImage[1])
Text := 'Press Run (F5) to continue'
dev_disp_text (Text, 'window', 400, 40, 'black', [], [])
endfor
stop ()
*关闭窗体
dev_display_dl_data_close_windows (WindowHandleDict)
*校验GPU是否正常运行与可连接状态
get_system ('cuda_loaded', Information1)
get_system ('cuda_version', Information2)
get_system ('cuda_devices', Information3)
get_system ('cudnn_loaded', Information4)
get_system ('cudnn_version', Information5)
get_system ('cublas_loaded', Information6)
get_system ('cublas_version', Information7)
query_available_dl_devices (['runtime','runtime'], ['gpu','cpu'], DLDeviceHandles)
if (|DLDeviceHandles| == 0)
throw ('No supported device found to continue this example.')
endif
* Due to the filter used in query_available_dl_devices, the first device is a GPU, if available.
DLDevice := DLDeviceHandles[0]
*返回98在0o支持深度学习的设备参数,默认优先级为GPU
get_dl_device_param (DLDevice, 'type', DLDeviceType)
if (DLDeviceType == 'cpu')
* The number of used threads may have an impact
* on the training duration.
NumThreadsTraining := 4
set_system ('thread_num', NumThreadsTraining)
endif
**********************************************开始训练模式*********************************
* 以下参数需要经常调整。
*模型参数。
*需要重新训练的分割模型。选取默认的halcon模型
ModelFileName := 'pretrained_dl_segmentation_enhanced.hdl'
* 批处理大小。
*如果设置为“maximum”,批量大小由set_dl_model_param_max_gpu_batch_size设置
*如果运行时'gpu'给定。
BatchSize := 'maximum'
* 初始学习率。
InitialLearningRate := 0.0001
* 如果批量大小较小,动量应该很高。
Momentum := 0.99
*train_dl_model使用的参数。
*训练模型的epoch(迭代次数)数。
NumEpochs := 100
* 评估间隔(以epoch为单位)用于计算验证分裂上的评估度量。
EvaluationIntervalEpochs := 1
* 在接下来的时代中改变学习率,例如[15,30]。
*如果不需要更改学习率,请设置为[]。
ChangeLearningRateEpochs := []
* 将学习率更改为以下值,例如InitialLearningRate *[0.1, 0.01]。
*元组必须与ChangeLearningRateEpochs具有相同的长度。
ChangeLearningRateValues := []
*
* ***********************************
* *** 设置高级参数。 ***
* ***********************************
*
* 在极少数情况下,可能需要更改以下参数。
*模型参数。
*使用[]默认权重优先。
WeightPrior := []
*
* train_dl_model参数。
*控制是否显示训练进度(true/false)。
EnableDisplay := true
* 为训练设置一个随机种子。
RandomSeed := 42
set_system ('seed_rand', RandomSeed)
*
*为了在同一GPU上获得近乎确定性的训练结果
* (system, driver, cuda-version)你可以指定"cudnn_deterministic"为
*“true”。注意,这可能会减慢训练速度。
* set_system ('cudnn_deterministic', 'true')
* 设置create_dl_train_param的通用参数。
*请参阅create_dl_train_param的文档,了解所有可用参数的概述。
GenParamName := []
GenParamValue := []
*
* 改变策略。
*可以在训练过程中更改模型参数。
*在这里,如果上面指定,我们会改变学习率。
if (|ChangeLearningRateEpochs| > 0)
create_dict (ChangeStrategy)
* 指定要更改的模型参数。
set_dict_tuple (ChangeStrategy, 'model_param', 'learning_rate')
* 以“initial value”开始参数值。
set_dict_tuple (ChangeStrategy, 'initial_value', InitialLearningRate)
* 在每个“epochs”步骤更改参数值。
set_dict_tuple (ChangeStrategy, 'epochs', ChangeLearningRateEpochs)
* 将参数值修改为“值”中的对应值。
set_dict_tuple (ChangeStrategy, 'values', ChangeLearningRateValues)
* 收集所有变更策略作为输入。
GenParamName := [GenParamName,'change']
GenParamValue := [GenParamValue,ChangeStrategy]
endif
*
* 串行化策略。
*有几种将中间模型保存到磁盘的选项(参见create_dl_train_param)。
*在这里,最好的和最终的模型被保存到上面设置的路径。
create_dict (SerializationStrategy)
set_dict_tuple (SerializationStrategy, 'type', 'best')
set_dict_tuple (SerializationStrategy, 'basename', BestModelBaseName)
GenParamName := [GenParamName,'serialize']
GenParamValue := [GenParamValue,SerializationStrategy]
create_dict (SerializationStrategy)
set_dict_tuple (SerializationStrategy, 'type', 'final')
set_dict_tuple (SerializationStrategy, 'basename', FinalModelBaseName)
GenParamName := [GenParamName,'serialize']
GenParamValue := [GenParamValue,SerializationStrategy]
*
*显示参数。
*在此示例中,训练的评估措施不显示
* training(默认)。如果您想这样做,请选择一定百分比的训练
*在训练过程中用于评估模型的样本。较低的百分比有助于加快速度
*设置自动评估。
SelectedPercentageTrainSamples := 0
*设置训练集的X轴参数
XAxisLabel := 'epochs'
create_dict (DisplayParam)
set_dict_tuple (DisplayParam, 'selected_percentage_train_samples', SelectedPercentageTrainSamples)
set_dict_tuple (DisplayParam, 'x_axis_label', XAxisLabel)
GenParamName := [GenParamName,'display']
GenParamValue := [GenParamValue,DisplayParam]
*
*
* *********************************
* *** 读取所需要的模型和预处理训练集. ***
* *********************************
*
*检查是否存在所需要的全部文件
check_data_availability (AllDir, DLDatasetFileName)
*
*读取预处理的文件(hdict后缀)
read_dict (DLDatasetFileName, [], [], DLDataset)
*读取预处理的初始化模型,选取halcon的模型。
*C:/Program Files/MVTec/HALCON-20.11-Progress/dl/pretrained_dl_segmentation_enhanced.hdl。
read_dl_model (ModelFileName, DLModelHandle)
set_dl_model_param (DLModelHandle, 'device', DLDevice)
*
* ******************************
* *** 设置模型参数. ***
* ******************************
*
* 根据预处理参数设置模型.
get_dict_tuple (DLDataset, 'preprocess_param', DLPreprocessParam)
get_dict_tuple (DLDataset, 'class_ids', ClassIDs)
set_dl_model_param_based_on_preprocessing (DLModelHandle, DLPreprocessParam, ClassIDs)
*
* 设置模型超参数.
*设置初始学习率
set_dl_model_param (DLModelHandle, 'learning_rate', InitialLearningRate)
*设置动量
set_dl_model_param (DLModelHandle, 'momentum', Momentum)
if (BatchSize == 'maximum' and DLDeviceType == 'gpu')
*设置GPU训练,当程序出现报错时,为内存占用过大,重启程序即可
*重启程序不行,则需要减少训练图像数,或者增加电脑内存
set_dl_model_param_max_gpu_batch_size (DLModelHandle, 100)
else
if (BatchSize == 'maximum' and DLDeviceType == 'cpu')
* Please set a suitable batch size in case of 'cpu'
* training before continuing.
stop ()
endif
set_dl_model_param (DLModelHandle, 'batch_size', 1)
endif
if (|WeightPrior| > 0)
set_dl_model_param (DLModelHandle, 'weight_prior', WeightPrior)
endif
set_dl_model_param (DLModelHandle, 'runtime_init', 'immediately')
*
* *************************
* *** 开始训练模型. ***
* *************************
*
* 创建通用训练字典
create_dl_train_param (DLModelHandle, NumEpochs, EvaluationIntervalEpochs, EnableDisplay, RandomSeed, GenParamName, GenParamValue, TrainParam)
*
* 通过下列算子开始训练
* train_dl_model_batch () within the following procedure.
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0.0, TrainResults, TrainInfos, EvaluationInfos)
*
* Stop after the training has finished, before closing the windows.
dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], [])
stop ()
*
* Close training windows.
dev_close_window ()
dev_close_window ()
*
write_dl_model (DLModelHandle, DLDatasetFileName)
* Set parameters for evaluation.
set_dl_model_param (DLModelHandle, 'optimize_for_inference', 'true')
*将训练好的文件写入路径中
write_dl_model (DLModelHandle, 'E:/HALCONDeepingLearn/单一缺陷/best_dl_model_segmentation.hdl')
************************************************评估模型*********************************
SegmentationMeasures := ['mean_iou','pixel_accuracy','class_pixel_accuracy','pixel_confusion_matrix']
create_dict (GenParamEval)
set_dict_tuple (GenParamEval, 'measures', SegmentationMeasures)
set_dict_tuple (GenParamEval, 'show_progress', 'true')
*
* 评估训练好的模型
evaluate_dl_model (DLDataset, DLModelHandle, 'split', 'test', GenParamEval, EvaluationResult, EvalParams)
*
*
* ******************************
* ** 显示结果 ***
* ******************************
*
* Display measures.
create_dict (WindowHandleDict)
create_dict (GenParamEvalDisplay)
set_dict_tuple (GenParamEvalDisplay, 'display_mode', ['measures','absolute_confusion_matrix'])
dev_display_segmentation_evaluation (EvaluationResult, EvalParams, GenParamEvalDisplay, WindowHandleDict)
*
dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', 'box', 'true')
stop ()
模型部署
*设置训练好模型的路径
AllDir := 'E:/HALCONDeepingLearn/单一缺陷/训练图/训练'
RetrainedModelFileName:=AllDir+'/best_dl_model_segmentation.hdl'
PreprocessParamFileName:=AllDir+'/data/dl_preprocess_param.hdict'
*校验GPU是否可以使用
query_available_dl_devices (['runtime','runtime'], ['gpu','cpu'], DLDeviceHandles)
if (|DLDeviceHandles| == 0)
throw ('No supported device found to continue this example.')
endif
*设置运行设备
DLDevice := DLDeviceHandles[0]
ClassNames := ['好','凸粉','擦花']
ClassIDs := [0,1,2]
*检查程序必须文件是否齐全
check_data_availability (AllDir, PreprocessParamFileName, RetrainedModelFileName, true)
*
*读取训练好的模型
read_dl_model (RetrainedModelFileName, DLModelHandle)
*
* 设置批处理量为1,(将每张图片做为单次处理).
set_dl_model_param (DLModelHandle, 'batch_size', 1)
*
* 初始化部署推理模型.
set_dl_model_param (DLModelHandle, 'device', DLDevice)
*
* 获取预处理参数.
read_dict (PreprocessParamFileName, [], [], DLPreprocessParam)
* Image Acquisition 01: Code generated by Image Acquisition 01
list_files ('E:/HALCONDeepingLearn/单一缺陷/擦花', ['files','follow_links'], ImageFiles)
tuple_regexp_select (ImageFiles, ['\\.(tif|tiff|gif|bmp|jpg|jpeg|jp2|png|pcx|pgm|ppm|pbm|xwd|ima|hobj)$','ignore_case'], ImageFiles)
for Index := 0 to |ImageFiles| - 1 by 1
read_image (Image, ImageFiles[Index])
* 生成图像模型
gen_dl_samples_from_images (Image, DLSampleBatch)
*
* 预处理图像模型
preprocess_dl_samples (DLSampleBatch, DLPreprocessParam)
*
* 将学习模型,应用到图像模型中
apply_dl_model (DLModelHandle, DLSampleBatch, ['segmentation_image','segmentation_confidence'], DLResultBatch)
* 获取预处理图像
get_dict_object (Image, DLSampleBatch, 'image')
* 获取结果图像
get_dict_object (SegmentationImage, DLResultBatch, 'segmentation_image')
*获取1号缺陷
threshold (SegmentationImage, Region_Tu, 1, 1)
gen_contour_region_xld (Region_Tu, Contours, 'border')
*获取2号缺陷
threshold (SegmentationImage, Region_Ca, 2, 2)
gen_contour_region_xld (Region_Ca, Contours1, 'border')
dev_display (Image)
dev_set_color ('red')
dev_display (Contours)
dev_set_color ('green')
dev_display (Contours1)
stop ()
endfor
讲解部分
第一:图像标注
在图像标注时,我们需要针对我们所需要识别的图像,尽可能的减少缺陷的数量和类别,保证标注的准确性。
文章中我选取,阿里天池数据大赛铝材表面缺陷检测基础图像进行训练和测试,数据源网址:https://tianchi.aliyun.com/competition/entrance/231682/information
缺陷部分选取在项目上最为常见的金属突起缺陷(凸粉)与金属表面划痕部分(擦花)作为文章的参考。
标注工具,文章选取halcon开发的标注工具MVTec Deep Learning Tool 22.10 版本进行标注。
标注过程。在标注时我们需要新建2种缺陷标注,即为擦花和凸粉,还有背景(无缺陷的图片)
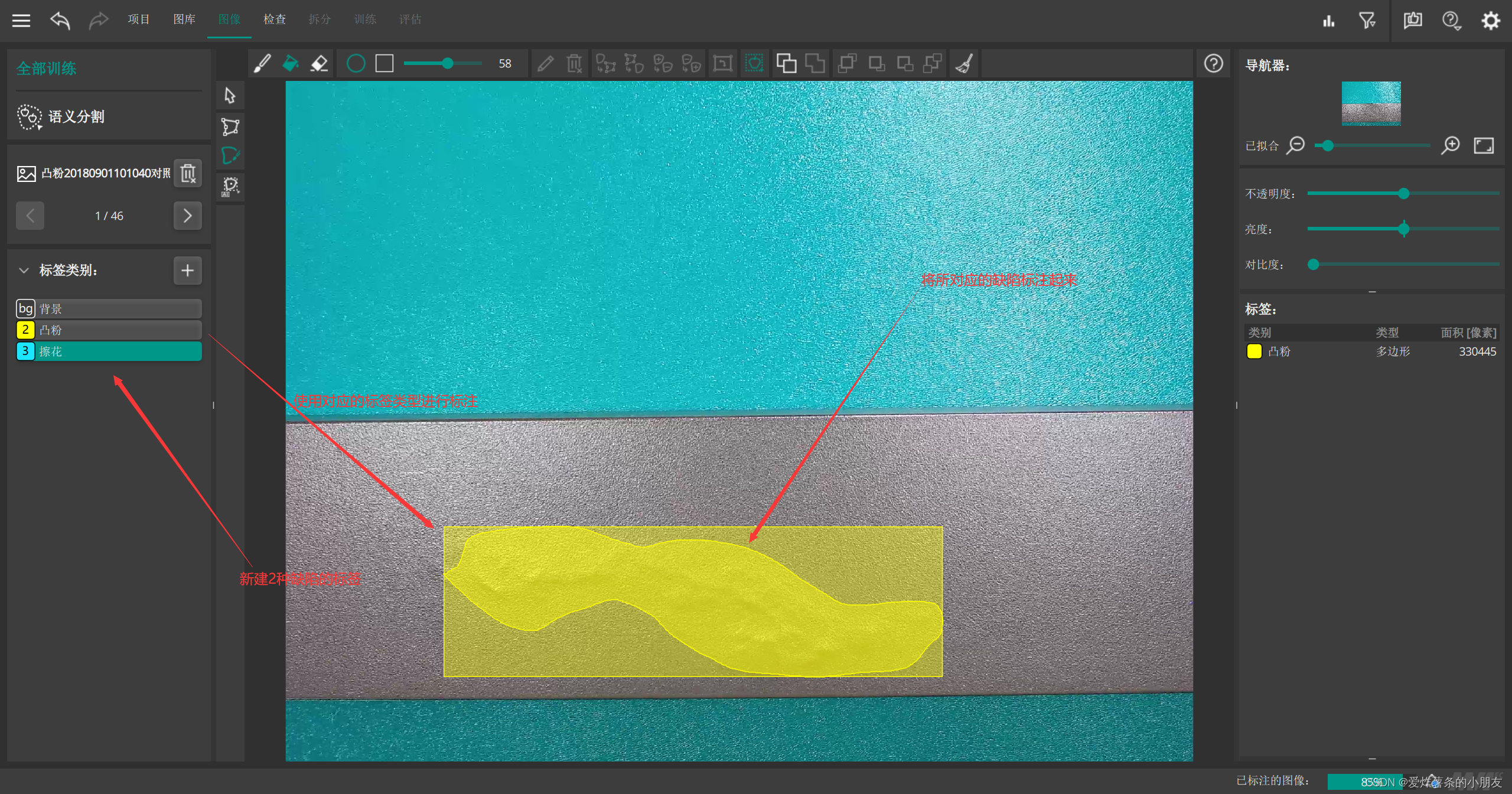


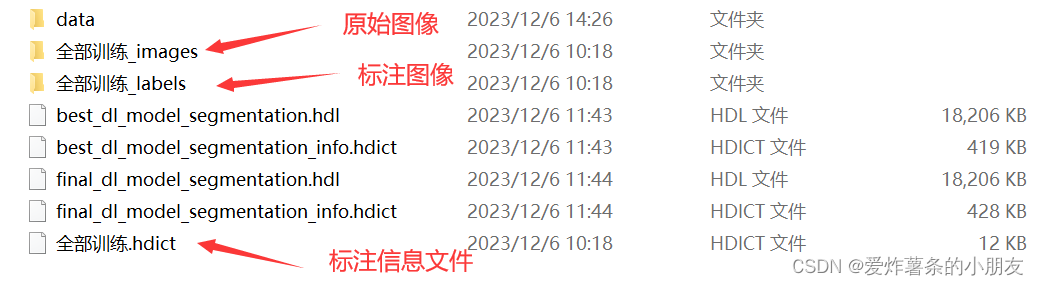
第二:开始图像预处理
1.导入图像路径
将我们标注好的图像文件夹路径写入到预处理的文件夹中。
*** 设置输入输出路径 ***
*总路径
AllDir := 'E:/HALCONDeepingLearn/单一缺陷/训练图/训练'
*图片路径,原始图像路径
ImageDir := AllDir +'/全部训练_images'
*语义分割标注好的图像,label,分割图片路径
DivisionImagesDir := AllDir + '/全部训练_labels'
*存放数据总路径,存放输出的全部参数
DataDir := AllDir + '/data'
*预处理后的路径
DataDirectoryBaseName := DataDir + '/dldataset'
*存储预处理参数
PreprocessParamFileBaseName := DataDir + '/dl_preprocess_param'
* 预处理后DLDataset的文件路径。
*注:调整DataDirectory预处理后与另一个图像大小。
DataDirectory :=AllDir + '/data/dldataset/samples'
DLDatasetFileName := AllDir + '/data/dldataset'+ '/dl_dataset.hdict'
2.设置图像预处理参数
其中类别ID,0代表为我们标注的背景图像,1和2代表我们标注的缺陷类型,与标注标签循序相关。
拆分数据集。训练与验证半分比的和应小于100%,测试百分比可以设置为默认即可。在实际训练中训练百分比通常为70%以上即可。可根据实际训练效果来选取。
图像尺寸参数。图像尺寸越大训练和部署的时间越长,所以推荐使用400*400的图像大小。图像通道数根据自身图像可使用单通道与三通道2种。
图像域处理,预处理中可以选择全局或者指定区域,指定区域需要使用reduce_domain算子进行对图像进行裁剪
*** 设置参数 ***
*类别名称
ClassNames := ['好','凸粉','擦花']
*类别ID
ClassIDs := [0,1,2]
*拆分数据集,训练百分比例,验证百分比例
TrainingPercent := 70
ValidationPercent := 15
*图片尺寸参数,图像宽,图像高,图像颜色通道数
ImageWidth := 400
ImageHeight := 400
ImageNumChannels := 3
*图片灰度范围
ImageRangeMin := -127
ImageRangeMax := 128
*图像预处理的进一步参数
*图像归一化,用于缩小图像分辨率
ContrastNormalization := 'none'
*域处理,全局缩放。crop_domain(指定缩放,与reduce_domain相使用)
DomainHandling := 'full_domain'
*不需要训练的类别的ID
IgnoreClassIDs := []
*设置背景类ID
SetBackgroundID := []
ClassIDsBackground := []
*随机种子
SeedRand := 42
3.拆分和检测图像集
read_dl_dataset_segmentation函数报错:通常为在文件夹中的原图像数量与标注文件夹的数量不一致造成的
*** 处理图片并进行拆分 ***
*设置随机种子
set_system ('seed_rand', SeedRand)
*通过参数将文件夹中数据分割为数据集 参数:图像路径、分割图像路径、类别名称、类别ID、图像路径列表、分割图像路径列表、字典、生成的数据集
read_dl_dataset_segmentation (ImageDir, DivisionImagesDir, ClassNames, ClassIDs, [], [], [], DLDataset)
*拆分数据集。数据集字典,训练图像百分比,验证图像百分比,测试图像百分比
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, [])
************************************** 预处理数据集 *************************
*创建预处理输出文件夹
file_exists (DataDir, FileExists)
if (not FileExists)
make_dir (DataDir)
endif
*创建预处理参数
*classification', 'detection', 'segmentation';分类,检测,分割
create_dl_preprocess_param ('segmentation', ImageWidth, ImageHeight, ImageNumChannels, ImageRangeMin, ImageRangeMax, ContrastNormalization, DomainHandling, IgnoreClassIDs, SetBackgroundID, ClassIDsBackground, [], DLPreprocessParam)
*预处理后的数据集路径
PreprocessParamFile := PreprocessParamFileBaseName +'.hdict'
*将参数写入
write_dict (DLPreprocessParam, PreprocessParamFile, [], [])
*创建字典
create_dict (GenParam)
set_dict_tuple (GenParam, 'overwrite_files', true)
*预处理
preprocess_dl_dataset (DLDataset, DataDirectoryBaseName, DLPreprocessParam, GenParam, DLDatasetFilename)
*******************************检查********************
*随机选取10张图像
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
find_dl_samples (DatasetSamples, 'split', 'train', 'match', SampleIndices)
tuple_shuffle (SampleIndices, ShuffledIndices)
read_dl_samples (DLDataset, ShuffledIndices[0:9], DLSampleBatchDisplay)
*
create_dict (WindowHandleDict)
for Index := 0 to |DLSampleBatchDisplay| - 1 by 1
*可视化不同的图像、注释和推理结果
dev_display_dl_data (DLSampleBatchDisplay[Index], [], DLDataset, ['image','segmentation_image_ground_truth'], [], WindowHandleDict)
get_dict_tuple (WindowHandleDict, 'segmentation_image_ground_truth', WindowHandleImage)
dev_set_window (WindowHandleImage[1])
Text := 'Press Run (F5) to continue'
dev_disp_text (Text, 'window', 400, 40, 'black', [], [])
endfor
stop ()
*关闭窗体
dev_display_dl_data_close_windows (WindowHandleDict)
4.设置训练设备
在深度学习训练中GPU的训练速度是同等级别下的CPU的10倍,所以通常情况下使用GPU进行训练。
训练前可以先校验GPU是否处于连接状态。halcon是否可以识别
*校验GPU是否正常运行与可连接状态
*当对应的信息正确时,代表GPU校验成功
get_system ('cuda_loaded', Information1),'true'
get_system ('cuda_version', Information2)
get_system ('cuda_devices', Information3),'NVIDIA GeForce RTX 3050 Ti Laptop GPU'
get_system ('cudnn_loaded', Information4),'true'
get_system ('cudnn_version', Information5)
get_system ('cublas_loaded', Information6),'true'
get_system ('cublas_version', Information7)
query_available_dl_devices (['runtime','runtime'], ['gpu','cpu'], DLDeviceHandles)
if (|DLDeviceHandles| == 0)
throw ('No supported device found to continue this example.')
endif
* Due to the filter used in query_available_dl_devices, the first device is a GPU, if available.
DLDevice := DLDeviceHandles[0]
*返回98在0o支持深度学习的设备参数,默认优先级为GPU
get_dl_device_param (DLDevice, 'type', DLDeviceType)
if (DLDeviceType == 'cpu')
* The number of used threads may have an impact
* on the training duration.
NumThreadsTraining := 4
set_system ('thread_num', NumThreadsTraining)
endif
5.设置训练参数
图像分割处理模型。在halcon的安装目录下
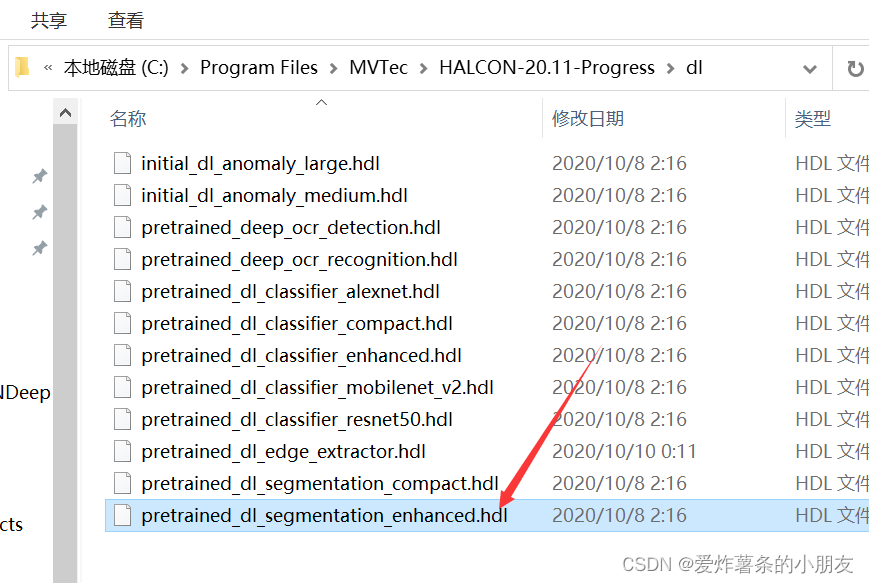
训练模型迭代次数:在实际训练中迭代次数大于80即可获得较好的效果,当然可以跟Loss训练曲线来衡量是否增加或者减少迭代次数。推荐迭代次数100次。
* 以下参数需要经常调整。
*模型参数。
*需要重新训练的分割模型。选取默认的halcon模型
ModelFileName := 'pretrained_dl_segmentation_enhanced.hdl'
* 批处理大小。
*如果设置为“maximum”,批量大小由set_dl_model_param_max_gpu_batch_size设置
*如果运行时'gpu'给定。
BatchSize := 'maximum'
* 初始学习率。
InitialLearningRate := 0.0001
* 如果批量大小较小,动量应该很高。
Momentum := 0.99
*train_dl_model使用的参数。
*训练模型的epoch(迭代次数)数。
NumEpochs := 100
* 评估间隔(以epoch为单位)用于计算验证分裂上的评估度量。
EvaluationIntervalEpochs := 1
* 在接下来的时代中改变学习率,例如[15,30]。
*如果不需要更改学习率,请设置为[]。
ChangeLearningRateEpochs := []
* 将学习率更改为以下值,例如InitialLearningRate *[0.1, 0.01]。
*元组必须与ChangeLearningRateEpochs具有相同的长度。
ChangeLearningRateValues := []
6.开始训练模型
* *************************
* *** 开始训练模型. ***
* *************************
*
* 创建通用训练字典
create_dl_train_param (DLModelHandle, NumEpochs, EvaluationIntervalEpochs, EnableDisplay, RandomSeed, GenParamName, GenParamValue, TrainParam)
*
* 通过下列算子开始训练
* train_dl_model_batch () within the following procedure.
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0.0, TrainResults, TrainInfos, EvaluationInfos)
*
* Stop after the training has finished, before closing the windows.
dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], [])
stop ()
*
* Close training windows.
dev_close_window ()
dev_close_window ()
*
write_dl_model (DLModelHandle, DLDatasetFileName)
* Set parameters for evaluation.
set_dl_model_param (DLModelHandle, 'optimize_for_inference', 'true')
*将训练好的文件写入路径中
write_dl_model (DLModelHandle, 'E:/HALCONDeepingLearn/单一缺陷/best_dl_model_segmentation.hdl')

训练完成时,我们可以根据对训练曲线对图像迭代次数进行优化和选取,并且调配其他参数。
7.验证模型和写入文件
*写入模型文件
write_dl_model (DLModelHandle, DLDatasetFileName)
* Set parameters for evaluation.
set_dl_model_param (DLModelHandle, 'optimize_for_inference', 'true')
*将训练好的文件写入路径中
write_dl_model (DLModelHandle, 'E:/HALCONDeepingLearn/单一缺陷/best_dl_model_segmentation.hdl')
SegmentationMeasures := ['mean_iou','pixel_accuracy','class_pixel_accuracy','pixel_confusion_matrix']
create_dict (GenParamEval)
set_dict_tuple (GenParamEval, 'measures', SegmentationMeasures)
set_dict_tuple (GenParamEval, 'show_progress', 'true')
*
* 评估训练好的模型
evaluate_dl_model (DLDataset, DLModelHandle, 'split', 'test', GenParamEval, EvaluationResult, EvalParams)
*
*
* ******************************
* ** 显示结果 ***
* ******************************
*
* Display measures.
create_dict (WindowHandleDict)
create_dict (GenParamEvalDisplay)
set_dict_tuple (GenParamEvalDisplay, 'display_mode', ['measures','absolute_confusion_matrix'])
dev_display_segmentation_evaluation (EvaluationResult, EvalParams, GenParamEvalDisplay, WindowHandleDict)
*

我们可以根据训练的评估结果进行判断是否需要再次调整参数进行训练。
LOU参数代表实际预测量与标注量的交集比值。越接近1越好。但是其实际值收到我们标注的效果直接影响,如果标注的面积过大会找出数值过低。PixAcc:匹配准确度。匹配准确度可以更加的直观的发现模型对缺陷的识别效果,当准确度达到0.9以上即可。
8.优化模型
针对上面的训练结果,我们可以提出几个改进的地方。第一:在标注时尽可能的贴近缺陷位置,可以使得LOU参数提高。第二:增加标注好的图像(文章中的缺陷各选取20张图像)。第三:调整参数配置。
第三:模型部署
在我们训练好所需要的模型后就可以开始部署和验证使用模型
1.导出训练好的模型和校验GPU
*设置训练好模型的路径
AllDir := 'E:/HALCONDeepingLearn/单一缺陷/训练图/训练'
RetrainedModelFileName:=AllDir+'/best_dl_model_segmentation.hdl'
PreprocessParamFileName:=AllDir+'/data/dl_preprocess_param.hdict'
*校验GPU是否可以使用
query_available_dl_devices (['runtime','runtime'], ['gpu','cpu'], DLDeviceHandles)
if (|DLDeviceHandles| == 0)
throw ('No supported device found to continue this example.')
endif
*设置运行设备
DLDevice := DLDeviceHandles[0]
ClassNames := ['好','凸粉','擦花']
ClassIDs := [0,1,2]
2.检查文件是否缺失和读取文件
*检查程序必须文件是否齐全
check_data_availability (AllDir, PreprocessParamFileName, RetrainedModelFileName, true)
*
*读取训练好的模型
read_dl_model (RetrainedModelFileName, DLModelHandle)
*
* 设置批处理量为1,(将每张图片做为单次处理).
set_dl_model_param (DLModelHandle, 'batch_size', 1)
*
* 初始化部署推理模型.
set_dl_model_param (DLModelHandle, 'device', DLDevice)
*
* 获取预处理参数.
read_dict (PreprocessParamFileName, [], [], DLPreprocessParam)
3.图像验证和缺陷提取
list_files ('E:/HALCONDeepingLearn/单一缺陷/擦花', ['files','follow_links'], ImageFiles)
tuple_regexp_select (ImageFiles, ['\\.(tif|tiff|gif|bmp|jpg|jpeg|jp2|png|pcx|pgm|ppm|pbm|xwd|ima|hobj)$','ignore_case'], ImageFiles)
for Index := 0 to |ImageFiles| - 1 by 1
read_image (Image, ImageFiles[Index])
* 生成图像模型
gen_dl_samples_from_images (Image, DLSampleBatch)
*
* 预处理图像模型
preprocess_dl_samples (DLSampleBatch, DLPreprocessParam)
*
* 将学习模型,应用到图像模型中
apply_dl_model (DLModelHandle, DLSampleBatch, ['segmentation_image','segmentation_confidence'], DLResultBatch)
* 获取预处理图像
get_dict_object (Image, DLSampleBatch, 'image')
* 获取结果图像
get_dict_object (SegmentationImage, DLResultBatch, 'segmentation_image')
*获取1号缺陷
threshold (SegmentationImage, Region_Tu, 1, 1)
gen_contour_region_xld (Region_Tu, Contours, 'border')
*获取2号缺陷
threshold (SegmentationImage, Region_Ca, 2, 2)
gen_contour_region_xld (Region_Ca, Contours1, 'border')
dev_display (Image)
dev_set_color ('red')
dev_display (Contours)
dev_set_color ('green')
dev_display (Contours1)
stop ()
endfor
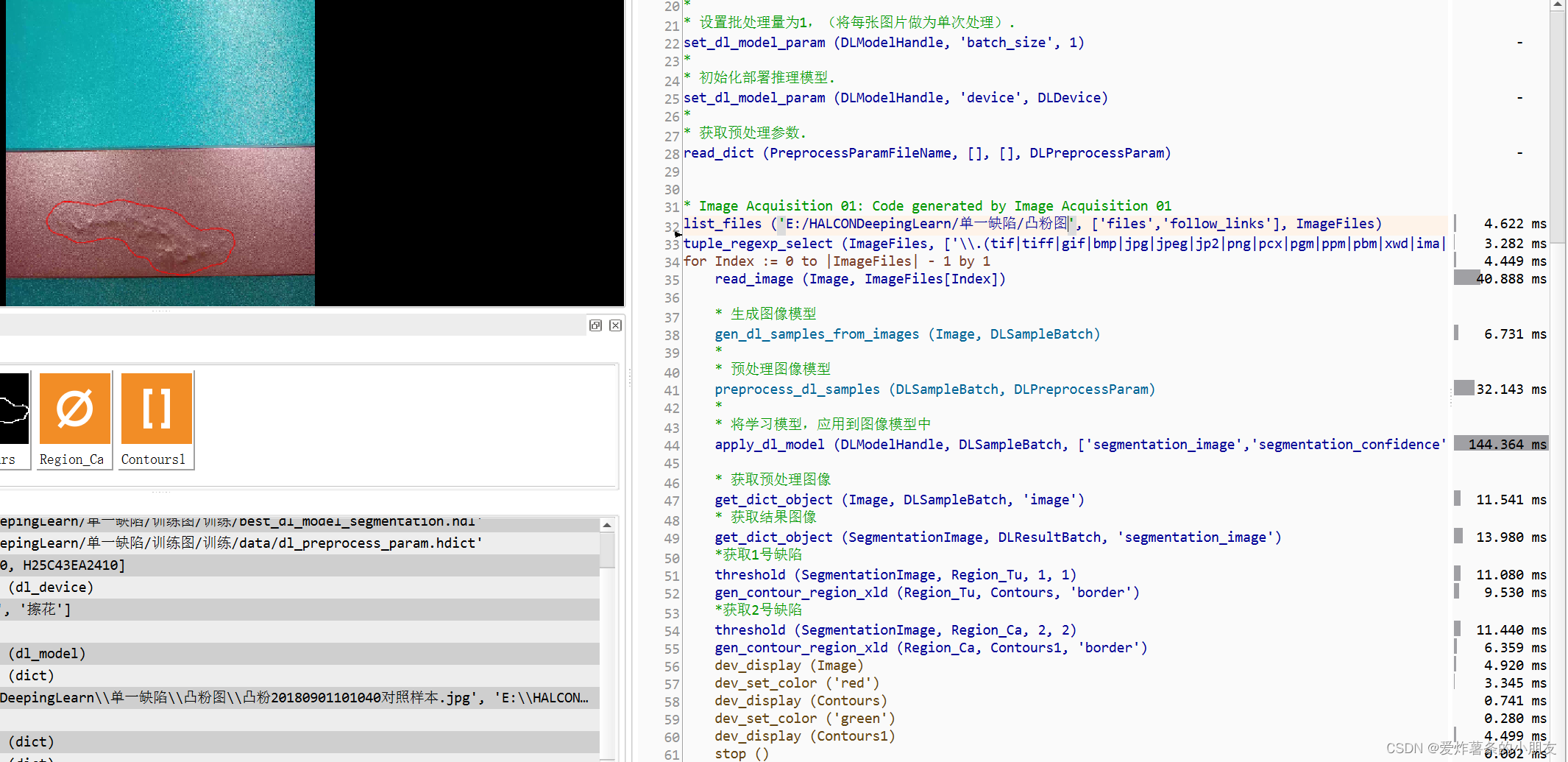
第四:结尾
halcon的深度学习由于是属于封装好的学习模块,所以对于很多项目来说,并不需要过多的修改参数(甚至不需要修改参数),往往默认参数的效果最佳。其次提升训练效果的最佳办法是增加缺陷图像,尤其是明显缺陷图像,有助于降低部署的NG率。对于细小的缺陷(例如很小的表面划痕或者油污这些)可以大量增加特定种类的训练图。
如果出现无法识别GPU的情况,可以访问这篇文章解决:https://www.cnblogs.com/QuincyYi/articles/14209643.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!