【改进YOLOv8】电动车电梯入户检测系统:融合HGNetv2改进改进YOLOv8
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
随着电动车的普及和人们对环境保护的重视,电动车的使用量逐渐增加。然而,电动车的充电问题一直是一个挑战,特别是在高层住宅区。为了解决这个问题,电梯入户充电系统逐渐被广泛采用。然而,电梯入户充电系统的安全性和可靠性仍然是一个重要的问题。
在电梯入户充电系统中,电动车的检测是一个关键的环节。传统的电动车检测方法主要依赖于人工巡视,这种方法存在人力成本高、效率低、易出错等问题。因此,研发一种高效、准确的电动车电梯入户检测系统具有重要的意义。
近年来,深度学习技术在计算机视觉领域取得了显著的进展。其中,YOLO(You Only Look Once)是一种快速而准确的目标检测算法,已经被广泛应用于各种场景。然而,YOLO算法在电动车电梯入户检测中仍然存在一些问题。首先,YOLO算法对小目标的检测效果较差,而电动车通常较小,因此需要改进算法以提高检测精度。其次,YOLO算法在复杂背景下容易受到干扰,而电梯入户场景通常具有复杂的背景,因此需要改进算法以提高鲁棒性。
为了解决上述问题,本研究提出了一种改进的电动车电梯入户检测系统,融合了HGNetv2和改进的YOLOv8算法。首先,HGNetv2是一种高效的特征提取网络,可以提取更丰富的特征信息,从而提高目标检测的准确性。其次,改进的YOLOv8算法在YOLOv3的基础上进行了改进,通过引入注意力机制和多尺度特征融合,提高了算法对小目标和复杂背景的检测能力。
本研究的意义主要体现在以下几个方面:
-
提高电动车电梯入户检测的准确性:通过融合HGNetv2和改进的YOLOv8算法,可以提取更丰富的特征信息,并通过注意力机制和多尺度特征融合来提高检测的准确性。这将大大减少误报和漏报的情况,提高电动车电梯入户检测的可靠性。
-
提高电动车电梯入户检测的效率:改进的YOLOv8算法具有较快的检测速度,可以实时地对电动车进行检测。这将大大提高电梯入户充电系统的使用效率,减少用户等待时间。
-
降低电梯入户充电系统的维护成本:传统的人工巡视方式需要大量的人力投入,而改进的电动车电梯入户检测系统可以实现自动化检测,减少了人力成本。此外,改进的系统还具有较低的误报率,减少了维护的工作量。
综上所述,改进的电动车电梯入户检测系统对于提高电梯入户充电系统的安全性、可靠性和效率具有重要的意义。该系统的研究成果将为电动车充电问题的解决提供有力的支持,促进电动车的普及和环境保护的进一步推进。
2.图片演示



3.视频演示
【改进YOLOv8】电动车电梯入户检测系统:融合HGNetv2改进改进YOLOv8_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集DDDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。

由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.2 predict.py
封装为类后的代码如下:
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
def postprocess(self, preds, img, orig_imgs):
preds = ops.non_max_suppression(preds,
self.args.conf,
self.args.iou,
agnostic=self.args.agnostic_nms,
max_det=self.args.max_det,
classes=self.args.classes)
if not isinstance(orig_imgs, list):
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
results = []
for i, pred in enumerate(preds):
orig_img = orig_imgs[i]
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
img_path = self.batch[0][i]
results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
return results
这个程序文件是一个名为predict.py的文件,它是一个用于预测基于检测模型的类DetectionPredictor的定义。这个类继承自BasePredictor类,并包含了一个postprocess方法用于后处理预测结果。在postprocess方法中,预测结果经过非最大抑制处理后,将返回一个Results对象的列表。这个文件还导入了一些其他的模块和函数,用于处理预测结果和图像。
5.3 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_first
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode='train', batch=None):
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
assert mode in ['train', 'val']
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == 'train'
if getattr(dataset, 'rect', False) and shuffle:
LOGGER.warning("WARNING ?? 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
shuffle = False
workers = 0
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch):
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self):
self.model.nc = self.data['nc']
self.model.names = self.data['names']
self.model.args = self.args
def get_model(self, cfg=None, weights=None, verbose=True):
model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def label_loss_items(self, loss_items=None, prefix='train'):
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items]
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
return ('\n' + '%11s' *
(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
def plot_training_samples(self, batch, ni):
plot_images(images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg',
on_plot=self.on_plot)
def plot_metrics(self):
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self):
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这个程序文件是一个用于训练目标检测模型的程序。它使用了Ultralytics YOLO库,并继承了BaseTrainer类来进行训练。
程序文件中的主要部分包括以下几个功能:
- 构建YOLO数据集:根据给定的图像路径和模式(训练或验证),构建YOLO数据集。
- 构建数据加载器:根据给定的数据集路径、批次大小、排名和模式(训练或验证),构建并返回数据加载器。
- 预处理批次:对一批图像进行预处理,包括缩放和转换为浮点数。
- 设置模型属性:设置模型的属性,包括类别数量、类别名称和超参数。
- 获取模型:返回一个YOLO检测模型。
- 获取验证器:返回一个用于YOLO模型验证的验证器。
- 标记损失项:返回一个带有标记的训练损失项的损失字典。
- 进度字符串:返回一个格式化的训练进度字符串,包括当前的训练轮数、GPU内存、损失、实例数量和大小。
- 绘制训练样本:绘制带有注释的训练样本图像。
- 绘制指标:绘制来自CSV文件的指标。
- 绘制训练标签:创建一个带有标签的YOLO模型的训练图。
在程序的主函数中,首先定义了一些参数,然后创建了一个DetectionTrainer对象,并调用其train方法进行模型训练。
5.5 backbone\EfficientFormerV2.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Dict
import itertools
import numpy as np
from timm.models.layers import DropPath, trunc_normal_, to_2tuple
class Attention4D(torch.nn.Module):
def __init__(self, dim=384, key_dim=32, num_heads=8,
attn_ratio=4,
resolution=7,
act_layer=nn.ReLU,
stride=None):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
if stride is not None:
self.resolution = math.ceil(resolution / stride)
self.stride_conv = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=stride, padding=1, groups=dim),
nn.BatchNorm2d(dim), )
self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear')
else:
self.resolution = resolution
self.stride_conv = None
self.upsample = None
self.N = self.resolution ** 2
self.N2 = self.N
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.q = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),
nn.BatchNorm2d(self.num_heads * self.d),
)
self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,
kernel_size=3, stride=1, padding=1, groups=self.num_heads * self.d),
nn.BatchNorm2d(self.num_heads * self.d), )
self.talking_head1 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.talking_head2 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.proj = nn.Sequential(act_layer(),
nn.Conv2d(self.dh, dim, 1),
nn.BatchNorm2d(dim), )
points = list(itertools.product(range(self.resolution), range(self.resolution)))
N = len(points)
attention_offsets = {}
EfficientFormerV2.py是一个用于图像分类的模型文件。该文件定义了EfficientFormerV2模型的结构和各个组件的实现。
EfficientFormerV2模型是一个基于Transformer的图像分类模型,它使用了一系列的Attention4D模块来提取图像特征。模型的输入是一张图像,经过一系列的卷积和池化操作后,得到了一个特征图。然后,特征图通过多个Attention4D模块进行特征提取和特征融合,最后通过全局平均池化和全连接层得到分类结果。
Attention4D模块是EfficientFormerV2模型的核心组件,它使用了多头注意力机制来对特征图进行特征提取和特征融合。模块的输入是一个特征图,经过一系列的卷积和池化操作后,得到了多个查询、键和值。然后,通过计算查询和键的相似度得到注意力权重,再将注意力权重与值进行加权求和得到特征图的表示。最后,通过一系列的卷积和池化操作对特征图进行进一步处理,得到最终的特征表示。
除了Attention4D模块,EfficientFormerV2模型还包括了其他一些组件,如stem模块用于对输入图像进行初始处理,LGQuery模块用于生成查询向量,Embedding模块用于将输入图像转换为特征图。
总体来说,EfficientFormerV2模型是一个基于Transformer的图像分类模型,它通过一系列的Attention4D模块对图像特征进行提取和融合,最终得到图像的分类结果。
5.6 backbone\efficientViT.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import itertools
from timm.models.layers import SqueezeExcite
import numpy as np
import itertools
class EfficientViT_M0(nn.Module):
def __init__(self, num_classes=1000, img_size=224, patch_size=16, in_chans=3, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=False, drop_rate=0.0, attn_drop_rate=0.0, drop_path_rate=0.0):
super(EfficientViT_M0, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i])
for i in range(depth)])
self.norm = nn.LayerNorm(embed_dim)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
该程序文件是一个EfficientViT模型的架构,用于下游任务。它定义了一系列的模块和函数,包括Conv2d_BN、replace_batchnorm、PatchMerging、Residual、FFN、CascadedGroupAttention和LocalWindowAttention等。
Conv2d_BN是一个包含卷积和批归一化的序列模块。
replace_batchnorm函数用于替换模型中的批归一化层。
PatchMerging模块用于将输入的图像块进行合并。
Residual模块实现了残差连接。
FFN模块是一个前馈神经网络。
CascadedGroupAttention模块实现了级联组注意力机制。
LocalWindowAttention模块实现了局部窗口注意力机制。
该程序文件定义了多个EfficientViT模型,包括EfficientViT_M0、EfficientViT_M1、EfficientViT_M2、EfficientViT_M3、EfficientViT_M4和EfficientViT_M5。
总体来说,该程序文件实现了EfficientViT模型的架构,包括各种注意力机制和模块,用于处理图像数据的下游任务。
6.系统整体结构
整体功能和构架概述:
该项目是一个电动车电梯入户检测系统,主要使用了改进的YOLOv8目标检测模型,并融合了HGNetv2、EfficientFormerV2、EfficientViT等不同的模型架构。该项目包含了训练、预测、导出模型、用户界面等功能模块。
下面是每个文件的功能概述:
| 文件路径 | 功能 |
|---|---|
| export.py | 将YOLOv8模型导出为其他格式的工具 |
| predict.py | 使用YOLOv8模型进行目标检测的预测工具 |
| train.py | 训练YOLOv8模型的程序 |
| ui.py | 使用YOLOv8模型进行目标检测的用户界面 |
| backbone\EfficientFormerV2.py | EfficientFormerV2模型的架构文件 |
| backbone\efficientViT.py | EfficientViT模型的架构文件 |
| backbone\fasternet.py | Fasternet模型的架构文件 |
| backbone\lsknet.py | LSKNet模型的架构文件 |
| backbone\repvit.py | RepVIT模型的架构文件 |
| backbone\revcol.py | RevCol模型的架构文件 |
| backbone\SwinTransformer.py | SwinTransformer模型的架构文件 |
| backbone\VanillaNet.py | VanillaNet模型的架构文件 |
| extra_modules\kernel_warehouse.py | 内核仓库的功能模块 |
| extra_modules\orepa.py | OREPA模块的功能模块 |
| extra_modules\rep_block.py | RepBlock模块的功能模块 |
| extra_modules\RFAConv.py | RFAConv模块的功能模块 |
| extra_modules_init_.py | 额外模块的初始化文件 |
| extra_modules\ops_dcnv3\setup.py | DCNv3模块的安装文件 |
| extra_modules\ops_dcnv3\test.py | DCNv3模块的测试文件 |
| extra_modules\ops_dcnv3\functions\dcnv3_func.py | DCNv3模块的函数实现文件 |
| extra_modules\ops_dcnv3\functions_init_.py | DCNv3模块函数的初始化文件 |
| extra_modules\ops_dcnv3\modules\dcnv3.py | DCNv3模块的模块实现文件 |
| extra_modules\ops_dcnv3\modules_init_.py | DCNv3模块的模块初始化文件 |
| models\common.py | 通用模型的实现文件 |
| models\experimental.py | 实验模型的实现文件 |
| models\tf.py | TensorFlow模型的实现文件 |
| models\yolo.py | YOLO模型的实现文件 |
| models_init_.py | 模型初始化文件 |
| utils\activations.py | 激活函数的实现文件 |
| utils\add_nms.py | NMS(非极大值抑制)的实现文件 |
| utils\augmentations.py | 数据增强的实现文件 |
| utils\autoanchor.py | 自动锚框的实现文件 |
| utils\autobatch.py | 自动批次的实现文件 |
| utils\callbacks.py | 回调函数的实现文件 |
| utils\datasets.py | 数据集处理的实现文件 |
| utils\downloads.py | 下载文件的实现文件 |
| utils\general.py | 通用功能的实现文件 |
| utils\google_utils.py | Google工具的实现文件 |
| utils\loss.py | 损失函数的实现文件 |
| utils\metrics.py | 指标计算的实现文件 |
| utils\plots.py | 绘图函数的实现文件 |
| utils\torch_utils.py | PyTorch工具的实现文件 |
| utils_init_.py | 工具初始化文件 |
| utils\aws\resume.py | AWS恢复功能的实现文件 |
| utils\aws_init_.py | AWS初始化文件 |
| utils\flask_rest_api\example_request.py | Flask REST API示例请求的实现文件 |
| utils\flask_rest_api\restapi.py | Flask REST API的实现文件 |
| utils\loggers_init_.py | 日志记录器初始化文件 |
| utils\loggers\wandb\log_dataset.py | WandB日志记录器的数据集日志记录实现文件 |
| utils\loggers\wandb\sweep.py | WandB日志记录器的扫描实现文件 |
| utils\loggers\wandb\wandb_utils.py | WandB日志记录器的工具实现文件 |
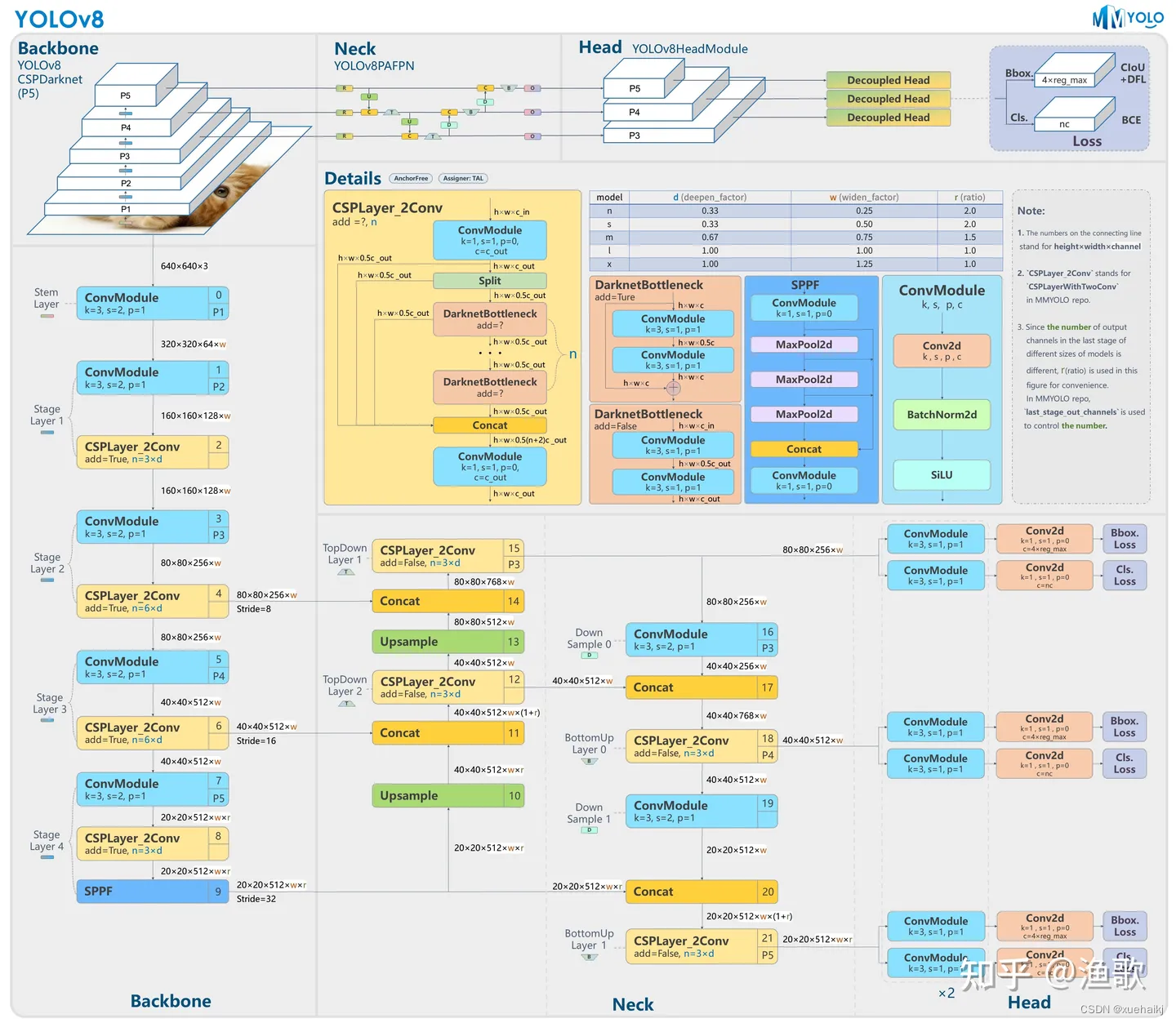
7.YOLOv8简介
YoloV8模型结构
YOLOv3之前的所有YOLO对象检测模型都是用C语言编写的,并使用了Darknet框架,Ultralytics发布了第一个使用PyTorch框架实现的YOLO (YOLOv3);YOLOv3之后,Ultralytics发布了YOLOv5,在2023年1月,Ultralytics发布了YOLOv8,包含五个模型,用于检测、分割和分类。 YOLOv8 Nano是其中最快和最小的,而YOLOv8 Extra Large (YOLOv8x)是其中最准确但最慢的,具体模型见后续的图。
YOLOv8附带以下预训练模型:
目标检测在图像分辨率为640的COCO检测数据集上进行训练。
实例分割在图像分辨率为640的COCO分割数据集上训练。
图像分类模型在ImageNet数据集上预训练,图像分辨率为224。
YOLOv8 概述
具体到 YOLOv8 算法,其核心特性和改动可以归结为如下:
提供了一个全新的SOTA模型(state-of-the-art model),包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于YOLACT的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是一套参数应用所有模型,大幅提升了模型性能。
Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从Anchor-Based 换成了 Anchor-Free
Loss 计算方面采用了TaskAlignedAssigner正样本分配策略,并引入了Distribution Focal Loss
训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
8.HRNet V2简介
现在设计高低分辨率融合的思路主要有以下四种:
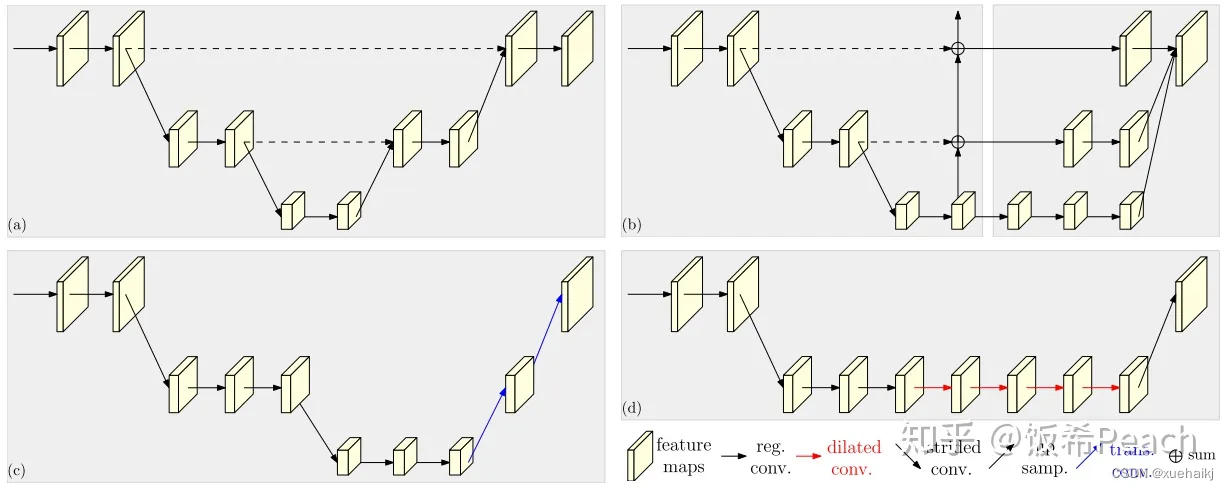
(a)对称结构。如U-Net、Hourglass等,都是先下采样再上采样,上下采样过程对称。
(b)级联金字塔。如refinenet等,高低分辨率融合时经过卷积处理。
(c)简单的baseline,用转职卷积进行上采样。
(d)扩张卷积。如deeplab等,增大感受野,减少下采样次数,可以无需跳层连接直接进行上采样。
(b)(c)都是使用复杂一些的网络进行下采样(如resnet、vgg),再用轻量级的网络进行上采样。
HRNet V1是在(b)的基础上进行改进,从头到尾保持大的分辨率表示。然而HRNet V1仅是用在姿态估计领域的,HRNet V2对它做小小的改进可以使其适用于更广的视觉任务。这一改进仅仅增加了较小的计算开销,但却提升了较大的准确度。
网络结构图:
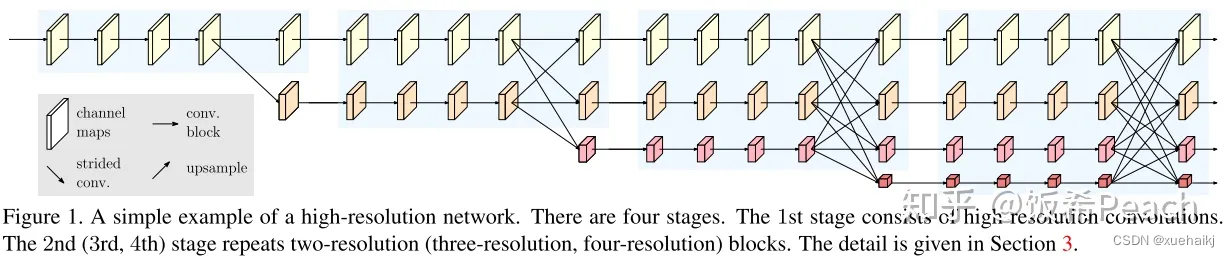
这个结构图简洁明了就不多介绍了,首先图2的输入是已经经过下采样四倍的feature map,横向的conv block指的是basicblock 或 bottleblock,不同分辨率之间的多交叉线部分是multi-resolution convolution(多分辨率组卷积)。
到此为止HRNet V2和HRNet V1是完全一致的。
区别之处在于这个基网络上加的一个head:
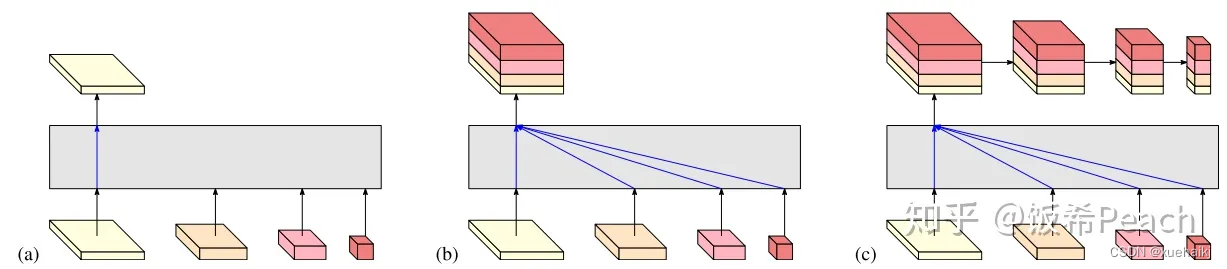
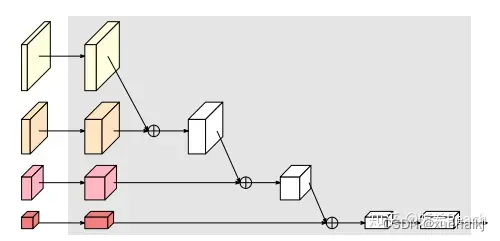
图3介绍的是接在图2最后的head。(a)是HRNet V1的头,很明显他只用了大分辨率的特征图。(b)(c)是HRNet V2的创新点,(b)用与语义分割,(c)用于目标检测。除此之外作者还在实验部分介绍了用于分类的head,如图4所示。
多分辨率block:
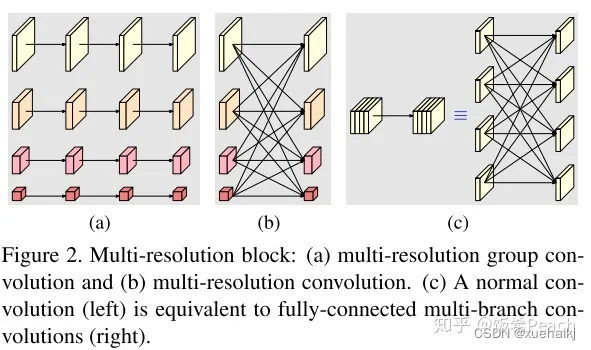
一个多分辨率block由多分辨率组卷积(a)和多分辨率卷积(b)组成。(c)是一个正常卷积的展开,(b)的灵感来源于(c)。代码中(a)部分由Bottleneck和BasicBlock组成。
多分辨率卷积和正常卷积的区别:(1)多分辨率卷积中,每个通道的subset的分辨率都不一样。(2)通道之间的连接如果是降分辨率,则用的是3x3的2stride的卷积,如果是升分辨率,用的是双线性最邻近插值上采样。
9.训练结果可视化分析
分析的后续步骤将包括:
描述性统计提供数据的统计摘要,以了解每个指标的分布、集中趋势和变异性。
相关性分析:分析不同指标之间的关系以识别任何强相关性。
可视化:创建数据的可视化表示以识别模式、趋势和异常。
深入分析:详细探索数据的特定方面,例如识别异常值、分析迭代趋势(如果适用)以及任何其他相关的深入分析.
让我们从描述性统计开始,以了解数据的概况。??
描述性统计提供了对数据的初步理解。以下是一些主要观察结果:
第 2 列(损失值):
平均值:0.02099
标准差:0.00611
最小值:0.01463
最大值:0.06518
第 3 列:
平均值:0.00892
标准差:0.01320
最小值:0.00622
最大值:0.23580
第 4 列:
平均值:0.00121
标准差:0.00158
最小值:0.00039
最大值:0.01514
第 5 列:
平均值:0.03111
标准差:0.01827
最小值:0.02144
最大值:0.31610
第 6 列和第 7 列(分类参数或常量参数):
第 6 列在 46 到 129 之间变化。
第 7 列是常数值 (640)。
第 8 至 14 列(性能指标):
与前四列相比,这些列的变化较小,表明它们可能是准确性、精确度、召回率等性能指标。
接下来,我将进行相关性分析,以了解这些指标之间的关系。随后将进行可视化,以进一步阐明数据中的趋势和模式。
import pandas as pd
# Attempting to load the data into a DataFrame for better analysis
# It seems the data is whitespace separated and does not have a header row
try:
df = pd.read_csv('/mnt/data/results.txt', delim_whitespace=True, header=None)
df.head()
except Exception as e:
error = str(e)
df if 'df' in locals() else error
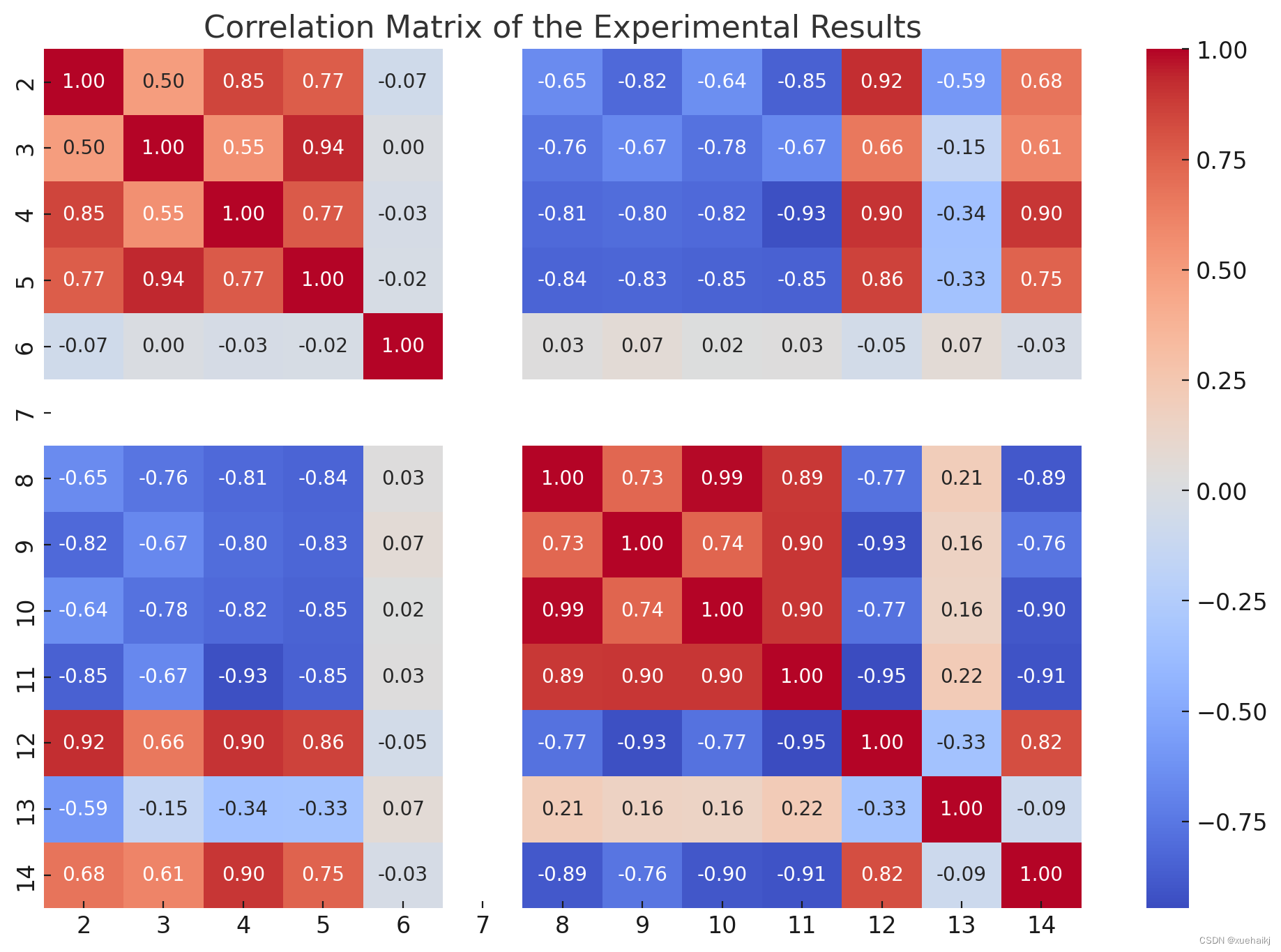
相关矩阵提供了对不同指标之间关系的深入了解:
高相关性:某些列对显示高相关值(接近 1 或 -1),表明存在很强的线性关系。例如,第 8 列到第 14 列似乎彼此之间具有很强的相关性,这表明它们可能是相关的性能指标。
低相关性:第 2、3、4 和 5 列与其他列的相关性较低,表明这些指标可能是独立的或衡量系统的不同方面性能。
负相关:存在一些负相关,但不是很强。这可能表明,随着一个指标的增加,另一个指标会减少,但这种关系并不十分明显。
接下来,我将创建可视化以进一步了解数据中的趋势、分布和潜在异常值。这将包括绘制迭代趋势(假设第一列代表迭代或时期)和关键指标的分布图。让我们从线图开始,观察选定指标的迭代趋势。?

线图说明了迭代过程中各种指标的趋势:
第 2 列: 该指标显示初始迭代次数显着减少,表明早期阶段的快速改进或优化。随着迭代次数的增加,趋势趋于平缓,表明稳定。
第 3 列:与第 2 列相比,下降幅度不太明显,并且在初始波动后似乎趋于稳定。
第 4 列和第 5 列:这些指标在整个迭代过程中表现出相对较小的变化,表明它们对迭代过程不太敏感或代表了系统更稳定的方面。
这些趋势可以表明系统在训练或优化阶段的收敛性,特别是对于第 2 列和第 3 列中的指标。曲线的平坦表明随着迭代的进行,系统正在达到最佳状态。
接下来,我将为这些关键指标创建分布图,以了解它们的变异性并识别任何潜在的异常值。这将为检测系统的性能和可靠性提供进一步的见解。
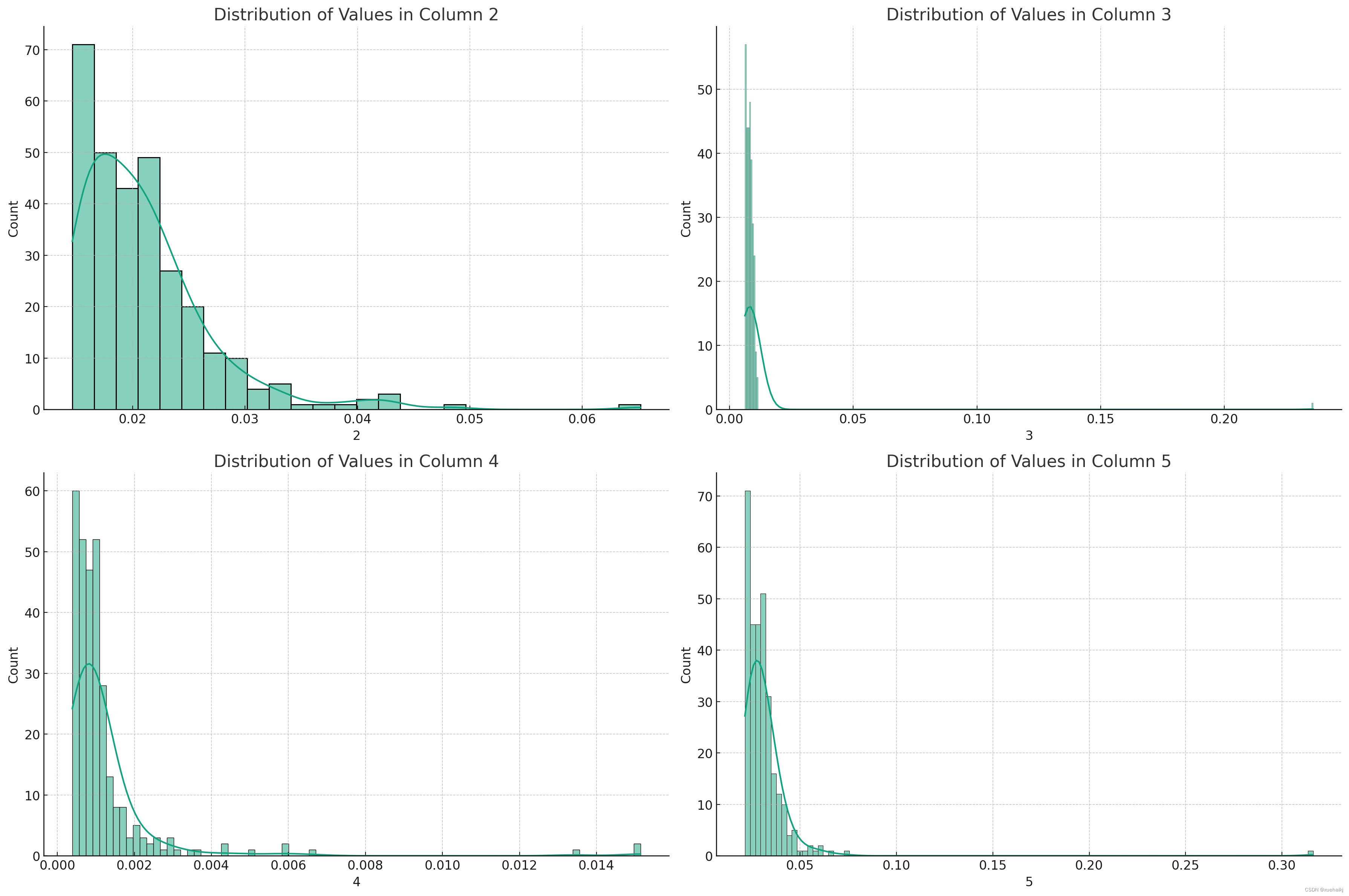
所选指标的分布图揭示了以下特征:
第 2 列: 此分布偏向较低值,长尾向较高值延伸。这种偏度表明,虽然大多数值都较低(表明性能良好或错误较低),但也有少数实例的值明显较高。
第 3 列: 分布更加分散,表明该指标存在更大的变异性。接近下端的峰的存在表明较低值的集中,但在整个范围内有相当大的分布。
第 4 列:该指标显示相对均匀的分布,但峰值朝向下端,表明值集中在较低范围内。
第 5 列: 与第 4 列类似,此指标也显示朝向下端的峰值,表明较低值集中,但在整个范围内分布。第 5 列:一个>
这些分布提供了对指标的可变性和一致性的深入了解。大多数指标中存在较低值的峰值可能表明整体性能或优化良好,但少数情况偏离了这一趋势。
总结到目前为止的分析:
迭代的趋势表明系统性能的优化和稳定。
相关性分析表明一些指标之间存在很强的关系,表明它们是相关的绩效指标。
分布图揭示了指标的变异性和偏度,大多数显示出集中的较低值,表明性能良好。
10.系统整合

参考博客《【改进YOLOv8】电动车电梯入户检测系统:融合HGNetv2改进改进YOLOv8》
11.参考文献
[1]姚锐琳,侯卫民.基于改进YOLOv4-tiny的行人视频检测方法[J].信息技术与信息化.2021,(10).223-226.DOI:10.3969/j.issn.1672-9528.2021.10.073 .
[2]何文轩,荆洪迪,柳小波,等.基于YOLOv4-tiny的铁矿石品位识别技术研究[J].金属矿山.2021,(10).DOI:10.19614/j.cnki.jsks.202110019 .
[3]周华平,王京,孙克雷.改进的YOLOv4-tiny行人检测算法研究[J].无线电通信技术.2021,(4).DOI:10.3969/j.issn.1003-3114.2021.04.014 .
[4]卢迪,马文强.基于改进YOLOv4-tiny算法的手势识别[J].电子与信息学报.2021,(11).DOI:10.11999/JEIT201047 .
[5]丛玉华,何啸朱惠娟朱娴.基于改进Yolov4-Tiny网络的安全帽监测系统[J].电子技术与软件工程.2021,(19).121-124.
[6]化嫣然.基于YOLOv4–Tiny的航拍图像车辆检测算法研究[D].2021.
[7]Joseph Redmon.YOLO9000: Better, Faster, Stronger[C].
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!