Maintaining Performance with Less Data(待补)

文章目录
hh
Abstract
为了降低神经网络模型的训练成本,我们提出了一种用于图像分类的神经网络训练的新方法,动态地减少输入数据。随着深度学习任务变得越来越流行,它们的计算复杂性也在增加,从而导致更复杂的算法和模型,这些算法和模型的运行时间更长,需要更多的输入数据。其结果是时间、硬件和环境资源的成本更高。通过使用数据缩减技术,我们减少了工作量,从而减少了人工智能技术对环境的影响。通过动态数据缩减,我们可以在保持准确性的同时,将运行时间减少多达50%,并按比例减少碳排放。
Introduction
在创建深度学习解决方案时,有两个主要因素决定其成功:首先是使用的模型,其次是用于训练的数据。
在本文中,我们分析了三种新的方法来动态分配用于训练神经网络模型的数据,用于图像分类任务。
Previous Work
Increasing data use
众所周知,如果提供更多的训练数据,深度学习模型将具有更高的性能。表1显示了跨六个数据集的图像分类模型的当前状态。每个模型都使用某种形式的数据增强来人为地增加可用于训练的数据的数量和种类,这使模型的准确性得到提高,从而使模型在排行榜上名列前茅。
Reducing data use
虽然使用增加数据的方法很流行,但也有数据缩减技术的用途。这种做法并不常见,因为基本的线性随机数据排除会导致系统性能呈指数级下降[14]。不仅平均准确率下降,而且准确率的标准差增加,说明训练输出不一致,难以验证[14]。与此相反,数据约简技术的某些使用可以提高神经网络模型的性能。在标记数据稀疏的领域,例如医学成像,数据经常遭受类别不平衡的困扰。在这种情况下,可以采用欠采样技术来减少大多数类的数据量,减轻类不平衡的影响[15]。随机排除的成功率较低,但聚类质心[16]和Tomek Links[17]等方法选择最合适的数据进行去除;它们通常与过采样技术一起使用,以提高模型性能[18]。欠采样是一种主要用于解决类不平衡的技术,因此不适合均匀平衡的数据集。
Variable data use
不同数据的使用是在整个训练过程中使用不同数据的过程。这是一个新颖的概念,在某些情况下,使用它可以提高性能,如下所述。实时或在线增强在每个epoch创建独特的数据。与离线增强相比,离线增强只对数据进行一次增强(在模型运行之前),在线增强在训练期间的每个epoch之前执行增强[21]。增强通常用于解决过拟合和数据短缺等问题[22]。
迁移学习的独特之处在于,当一个模型被引入到新的训练数据中时,旧的训练数据也不会被使用。这通常会导致灾难性的遗忘[26]。在训练开始时使用较少的数据,并随着训练的进行而增加数据,目前还没有调查**。与迁移学习不同的是,我们在训练开始时就有了所需的所有数据,但在执行训练时,我们选择保留一些数据。这是为了显示以受控方式使用不同数据的效果**。
Contribution
?描述了三种动态引入数据到模型的新方法,每种方法都减少了执行的评估量:-
– Data Step
– Data Increment
– Data Cut
?在三个数据集上进行了测试,展示了这些新方法对网络精度和运行时间的影响
?有证据表明,这些方法可以减少训练所需的资源,同时保持或提高训练输出的性能,运行时间减少50%以上。
第一个是理论贡献,后两个是实验贡献,其实压根没必要写,实验本就是为了支撑理论的
Methods
传统上,深度学习任务有三个阶段:数据收集[2]、数据处理[27][28]和网络模型的训练。这些步骤通常是按顺序执行的,但有时是相互关联的;例如,数据收集可能是实时图像或文本捕获,或者模型可能使用在线增强,其中数据在每个训练循环中以不同的方式增强。图1显示了带有在线增强的图像分类模型的数据流。在每个训练循环之后,模型返回到增强阶段。图2显示了本文提出的模型结构,其中有一个数据选择阶段。这允许模型在每个训练循环中动态地选择数据。这反过来又使本文进一步描述的各种数据缩减技术成为可能。
数据收集–>数据增强–>训练–>数据增强–>训练…–>训练完成–>输出
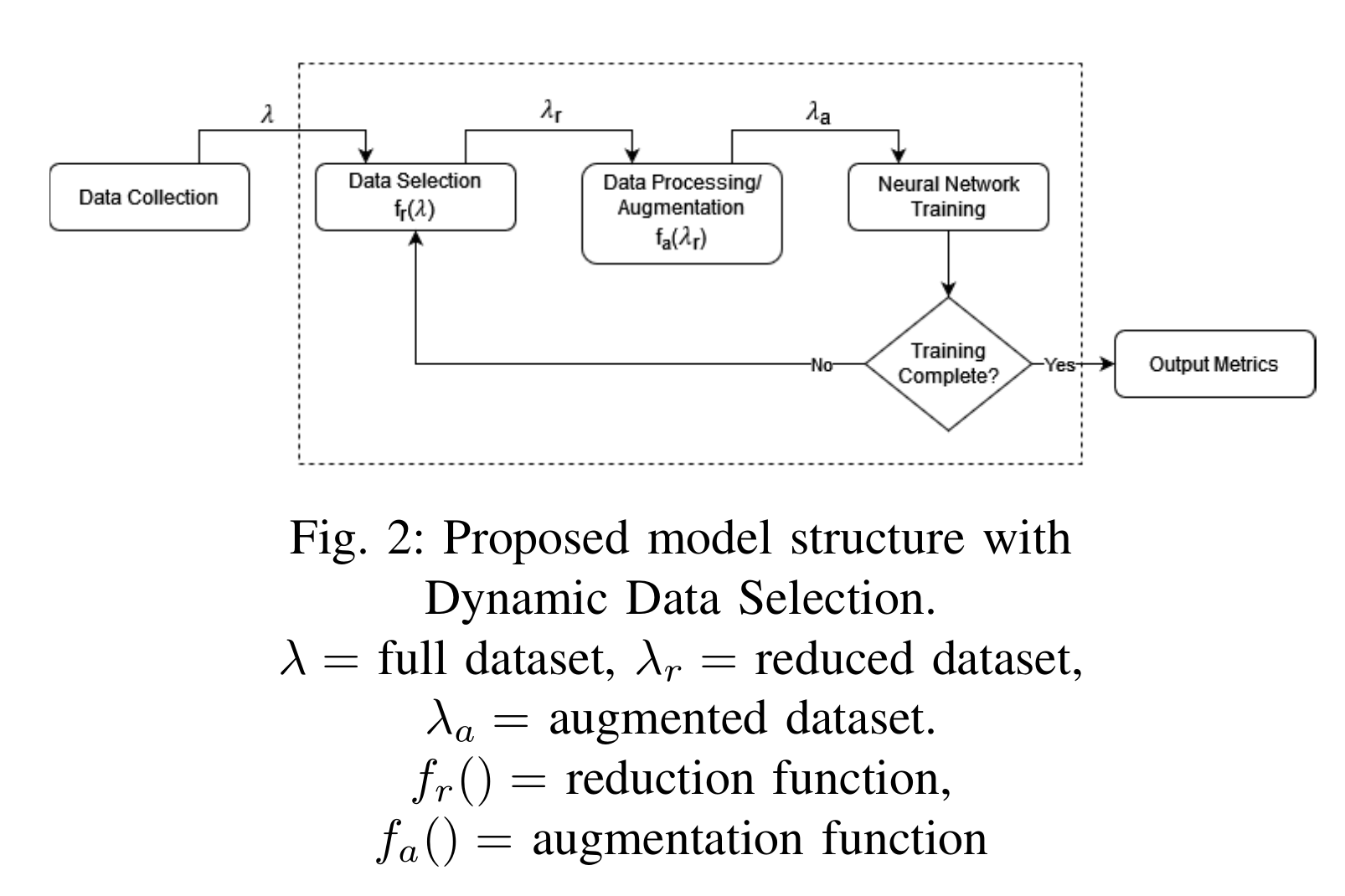
数据收集–>数据选择–>数据增强–>训练–>数据选择–>数据增强–>训练…–>训练完成–>输出
本文介绍并研究了三组实验,在数据选择阶段,每个epoch都选择数据进行训练。其结果是每个epoch都没有使用模型的所有数据
Datasets
我们进行了多种不同的实验,以观察不同数量的数据约简对模型性能的影响。因此,具有小图像尺寸的数据集是理想的,因为它们需要更少的时间来训练

Hardware
使用多种硬件来执行训练,以充分利用本研究可用的资源。每个数据集的训练只在一台机器上进行,以确保单个数据集的指标一致。还给出了每个GPU的平均CO2排放量,用于减排计算[32]。
Performance Metrics
这些实验是为了观察每个训练epoch使用的数据减少的效果。为了量化这一点,实验结果显示了执行的评估总数;每个评估都是用于训练的单个图像。每个实验的运行时间也被记录下来。模型的量化是成功的,达到了top1精度。每个实验的运行时间和精度直接与每个数据集的基线进行比较,以显示精度和运行时间性能的增加或减少。由于模型在使用数据约简技术运行时没有变化,因此每个实验的CO2减少量与运行时直接相关。因此,CO2的减少等于运行时间的减少。
Network Architecture
用于测试的模型是一个具有简单单片结构的卷积神经网络。它使用9个卷积层,以及一个主胶囊层和一个辅助胶囊层。胶囊层使用均匀向量胶囊,它取代了完全连接的层。该模型基于23)尽管其网络层数较少,但表现出相对较高的性能。测试运行了300次epoch,批大小为120。使用Adam优化器进行优化,初始学习率为0.999,每个epoch的指数衰减率为0.005。这些值为所有数据集的所有实验提供一致的初始设置。
每种方法要排除的数据点是随机选择的。采用最简单的数据排除方法,即随机数据排除,通过实验来了解动态数据约简方法的效果。
Experimentation
Benchmark

Data step
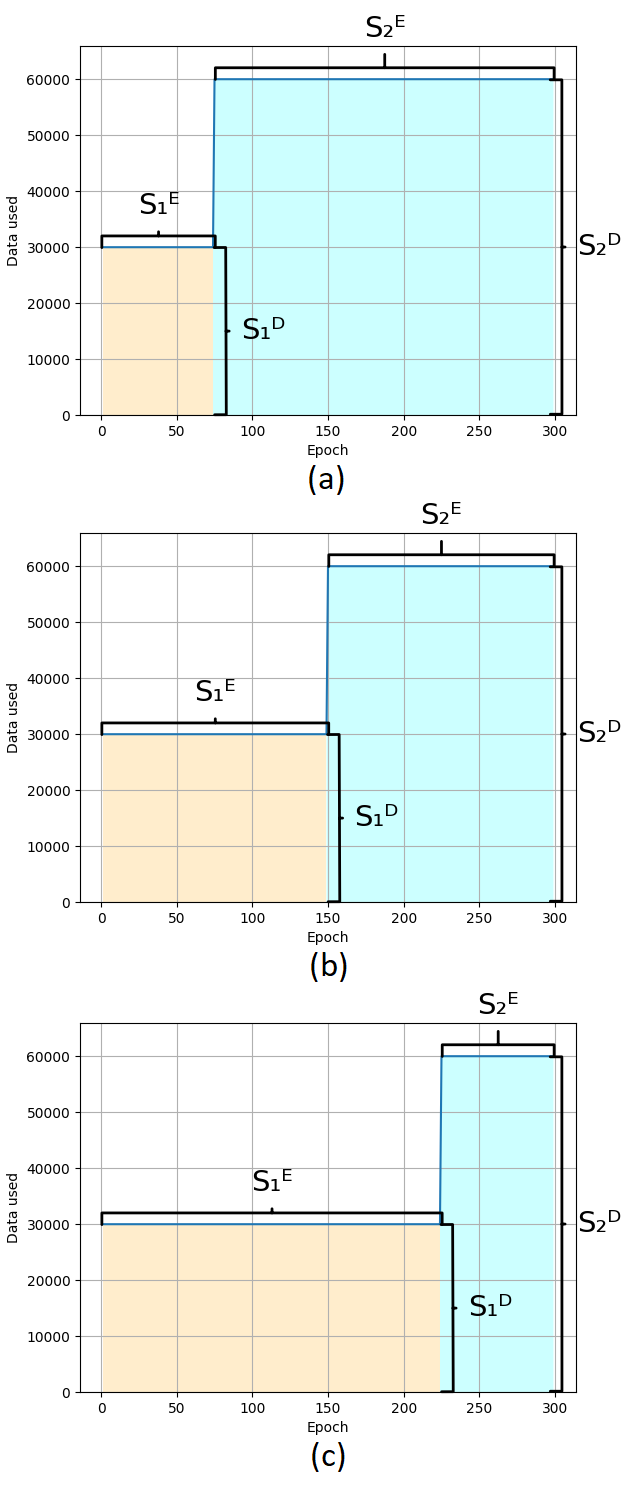
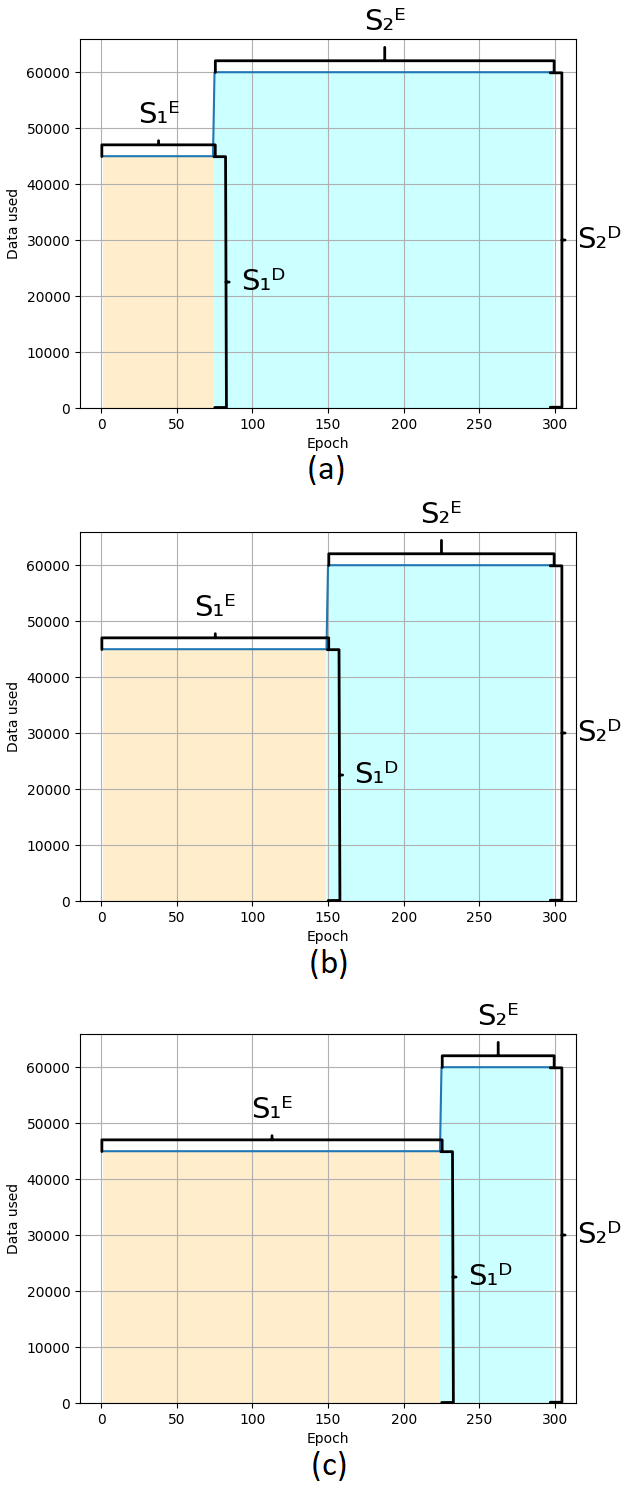
动态选择数据的最简单方法是在训练期间的给定点上“加强”数据的使用。数据集的一部分用于给定数量的训练循环,之后使用整个数据集进行训练。这将训练过程分成两个部分;第1节(S1)使用较少的数据,第2节(S2)使用完整的数据集。以下是这两个部分的定义:
这种数据分割会导致数据使用量的“上升”,并且模型在一段时间内只会使用一小部分数据进行训练。图3、图4和图5显示了如何在这些部分之间应用这种分割。假设是,由于在section S1中处理的数据较少,运行时将会减少。该步骤完成后,使用完整数据集;这是为了确保所有的特征在训练的某个时刻可用,尽管不是在每个时期。这是为了帮助减少过度拟合,当使用的数据太少时,这种情况很常见。Data Step方法的实验分为三个部分,每个部分有三个实验。

数据步骤实验从25%的数据开始,epoch在训练中占比(a)25%,(b)50%,?75%
Starting with 25% of the dataset

Starting with 50% of the dataset

Starting with 75% of the dataset
observe
测试的最后阶段使用最少的数据缩减,因此,运行时和平均准确性的减少是最小的
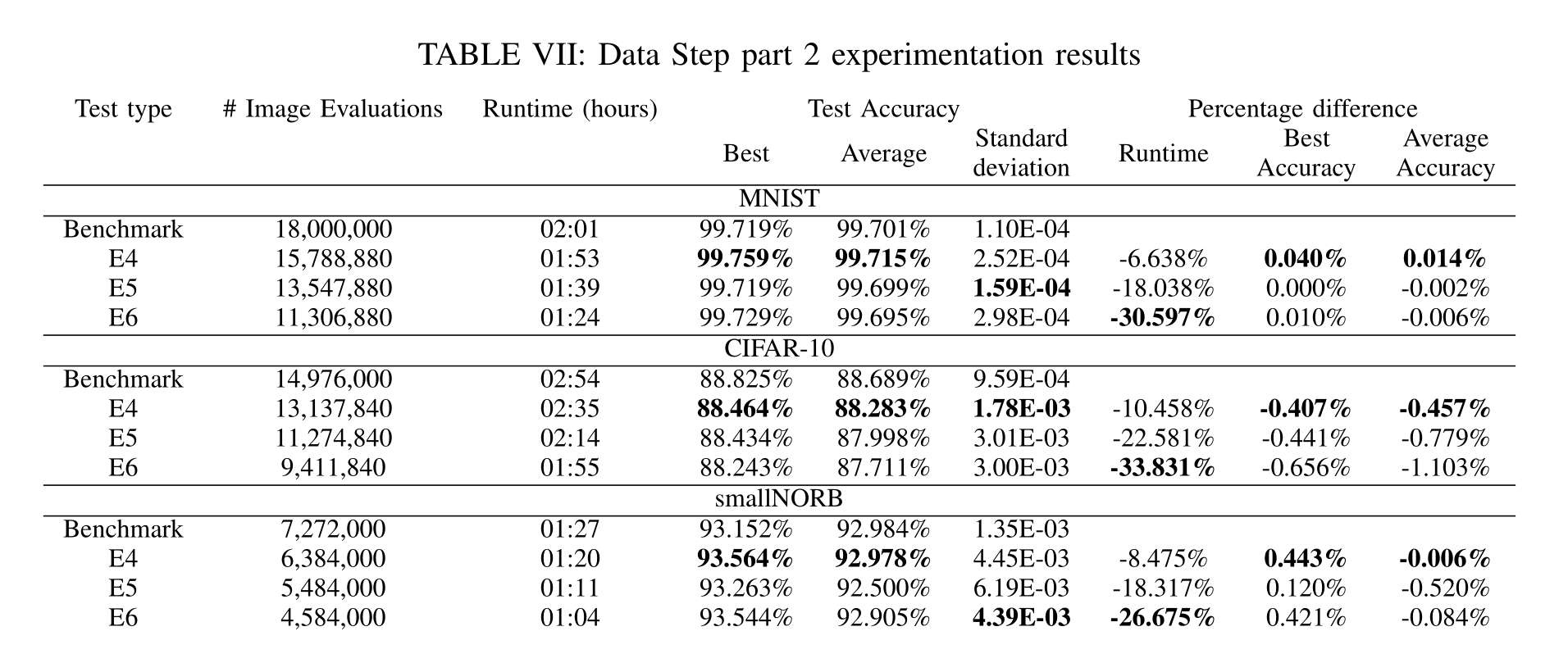
?使用MNIST数据集,所有实验的精度都有所提高:E7、E8和E9的平均精度分别提高了0.018%、0.016%和0.012%。实验E7显示,与基准相比,准确度的标准偏差有所降低。
?使用CIFAR-10数据集,结果遵循与最后一组实验结果相同的模式-准确性下降与使用数据的减少直接相关,尽管这种相关性是非线性的。E7、E8和E9的平均精度分别下降0.072%、0.324%和0.507%
?对于smallNorb数据集,E7的平均准确率提高了0.081%,E8和E9的平均准确率分别下降了0.062%和0.250%。实验E7的性能有所提高;这是在smallNorb数据集上唯一一个性能提高的实验。实验E8和E9的平均精度降低了,这表明在执行的评估数量上如此微小的差异对模型的影响有多大。
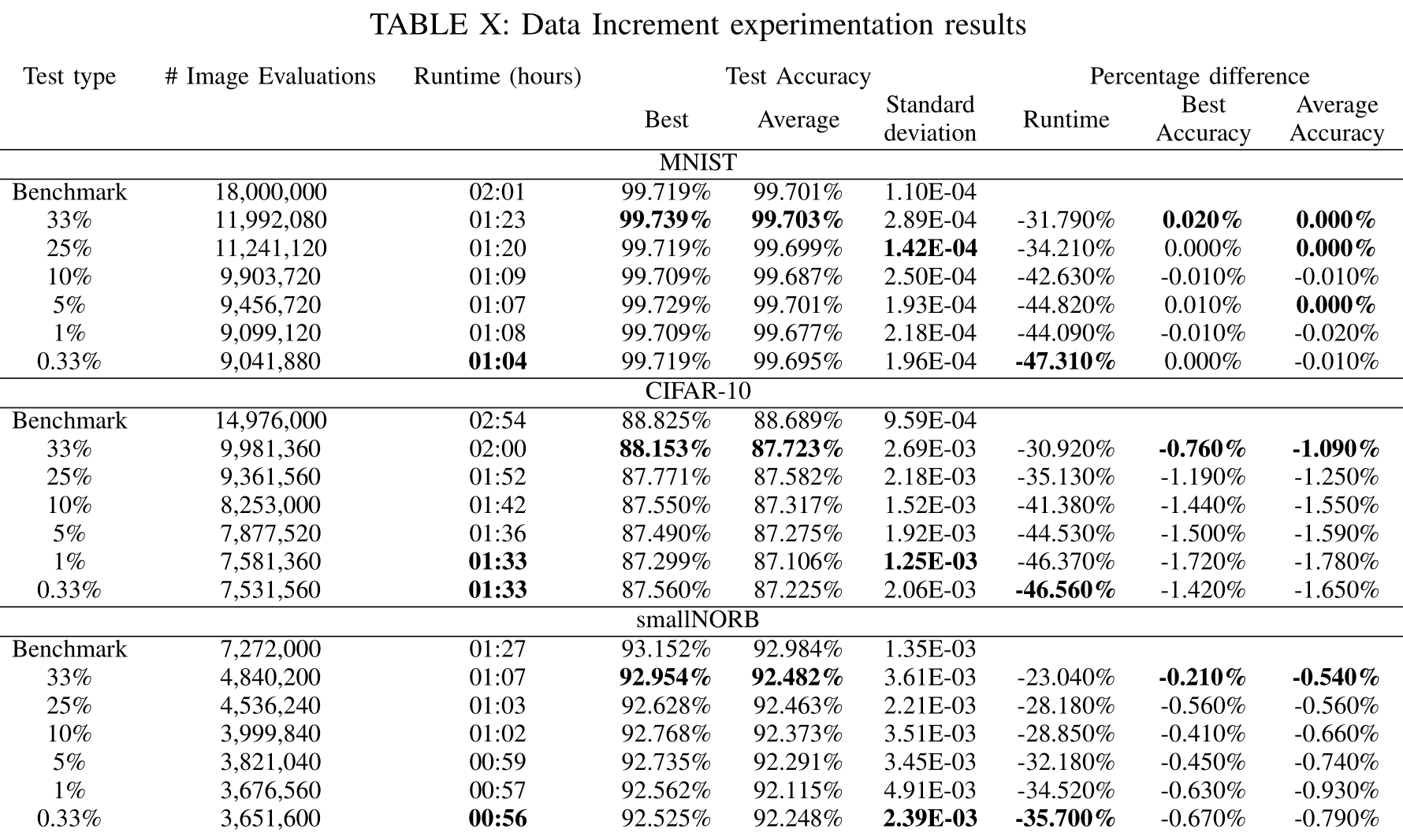
Data Increment

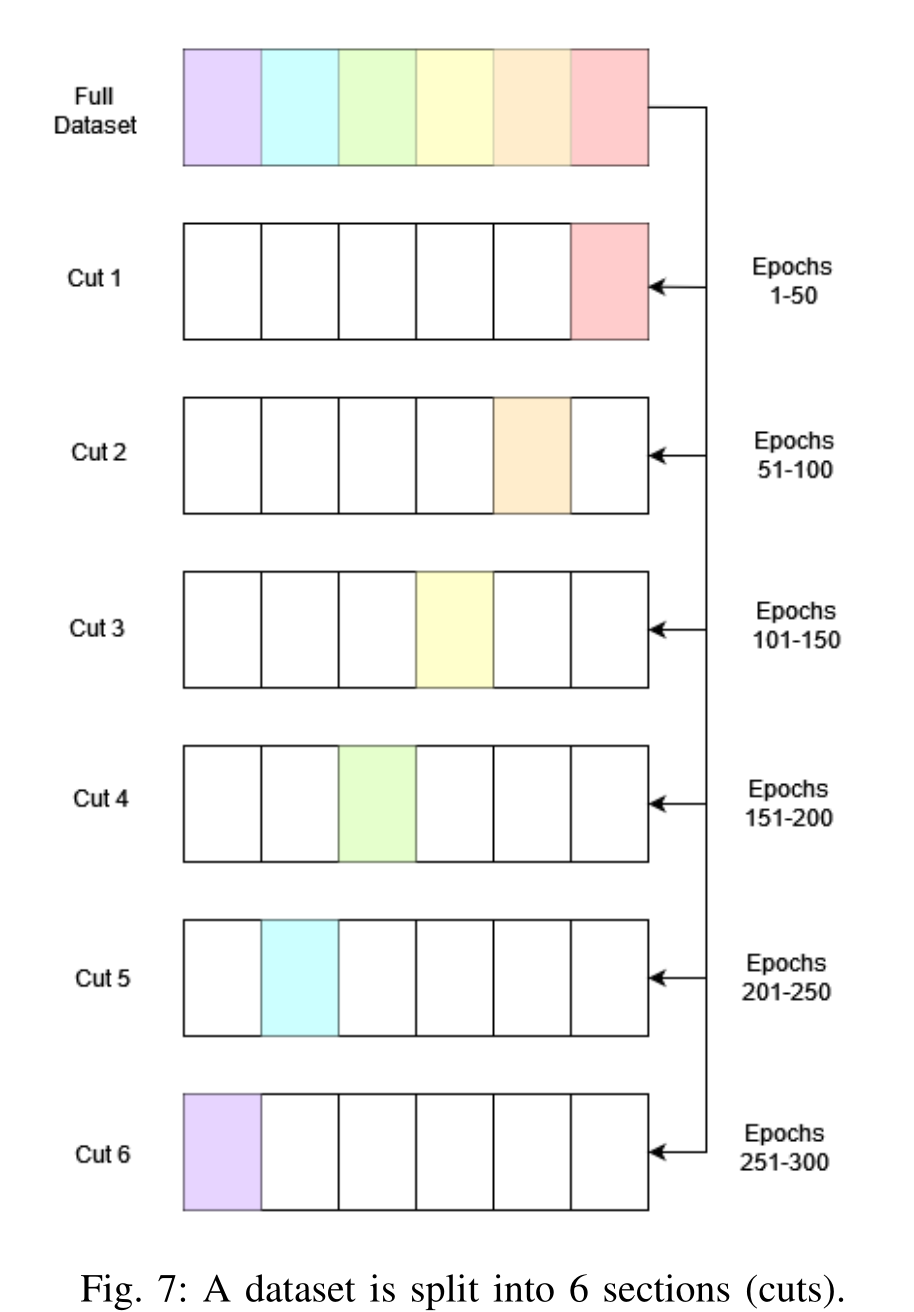
Data Cut

Discussion
实验的运行时间与执行的评估总数直接相关。这与预期的一样,因为执行的评估越少,神经网络执行的计算就越少。
对于Data Step方法,最显著的结果是MNIST数据集的结果,以及smallNorb的E7、E8和E9的结果,因为尽管执行的评估次数较少,但它们显示出准确性的提高。未来的研究方向将是调查为什么在这些情况下会有性能提高,以及如何纠正对稳定性的有害影响。此外,还可以进一步研究CIFAR-10为什么没有显示出任何增加。
与Data Step方法一样,Data Increment方法表明,减少执行的计算次数会减少运行时。然而,尽管这两种方法都完成了相同的数据简化基本任务,但对于执行的评估次数大致相同,它们产生的结果却不同。例如,将数据步进法的E2实验与25%的数据增量进行比较,我们可以观察到在进行大致相同次数的评估时的准确性。
在所有情况下,数据增量法都显示出较差的精度。虽然数据增量法确实执行了更少的评估,但数据的差异(所有数据集的差异小于1%)相当于少于3次训练。这个量是可以忽略不计的,因为模型的最高精度是在更早的时代确定的。实验结果表明,用增量法减少评价次数对模型的精度影响较大。
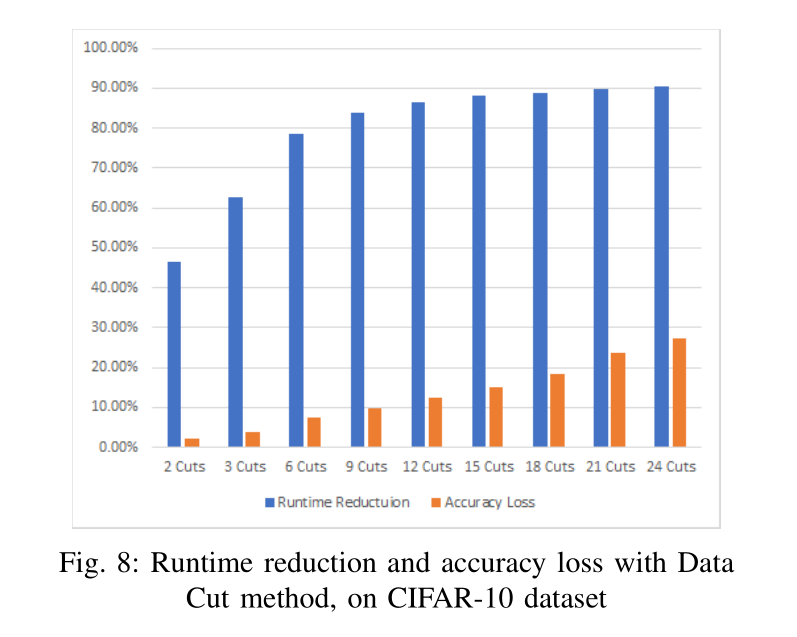
所有观测数据切割实验的精度都比数据增量法差。我们可以得出结论,由于数据增量法不如data step法,数据切割法在保持精度方面效果最差。但是,如果需要在不影响准确性的情况下尽可能地减少运行时,那么将数据分割为9段似乎是运行时和准确性之间的最佳折衷。
Conclusion
本文的结果表明,与常规相反,减少用于训练的数据在某些情况下提高了模型的性能。这证明了并不是所有的数据都是训练所必需的,事实上有些数据可能会阻碍训练。使用的方法有些野蛮,随机排除数据而不考虑删除的数据点的值,引用的其他作品已经展示了算法方法来选择要删除哪些数据以提高性能,这是变化数据使用的下一步。尽管如此,即使随机排除也能改善结果,似乎不同的数据使用还有待进一步的详细探讨。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!