pandas分组聚合转换
分组的一般模式
分组操作在日常生活中使用极其广泛:
- 依据性别性别分组,统计全国人口寿命寿命的平均值平均值
- 依据季节季节分组,对每一个季节的温度温度进行组内标准化组内标准化
从上述的例子中不难看出,想要实现分组操作,必须明确三个要素:分组依据分组依据、数据来源数据来源、操作及其返回结果操作及其返回结果。同时从充分性的角度来说,如果明确了这三方面,就能确定一个分组操作,从而分组代码的一般模式:
df.groupby(分组依据)[数据来源].使用操作例如第一个例子中的代码就应该如下:
df.groupby('Gender')['Longevity'].mean()回到学生体测的数据集上,如果想要按照性别统计身高中位数,就可以写出:
df = pd.read_csv('data/students.csv')
df.groupby('Gender')['Height'].median()
#
Gender
,Female 169.7
,Male 171.2
分组依据的本质
前面提到的都是以单一维度进行分组的,比如根据性别,如果现在需要根据多个维度进行分组,只需在groupby中传入相应列名构成的列表即可。希望根据学校和性别进行分组,统计身高的均值可以写出:
df.groupby(['School', 'Gender'])['Height'].mean()
#
School Gender
,Fudan University Female 158.7769
, Male 176.2122
,Peking University Female 158.6666
, Male 172.0301
,Shanghai Jiao Tong University Female 159.1222
, Male 176.7600
,Tsinghua University Female 159.7566
, Male 171.6777
,Name: Height, dtype: float64?groupby的分组依据都是直接可以从列中按照名字获取的,如果希望通过一定的复杂逻辑来分组,比如根据学生体重是否超过总体均值来分组,同样还是计算身高的均值。
首先应该先写出分组条件:
con = df.weight > df.weight.mean()?然后将其传入groupby中:
df.groupby(condition)['Height'].mean()
#
Weight
,False 159.034646
,True 172.705357?或直接写入括号:
df.groupby( df.weight > df.weight.mean() )['Height'].mean( )
Groupby对象
最终具体做分组操作时,调用的方法都来自于pandas中的groupby对象,这个对象定义了许多方法,也具有一些方便的属性。
gro?= df.groupby(['School', 'grade'])
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x001B2B6AB1408>
通过groups属性,可以返回从组名组名映射到组索引列表组索引列表的字典:
con = gro.groups
con.keys()
#
dict_keys([('Fudan University', 'Freshman'), ('Fudan University', 'Junior'), ('Fudan University', 'Senior'), ('Fudan University', 'Sophomore'), ('Peking University', 'Freshman'), ('Peking University', 'Junior'), ('Peking University', 'Senior'), ('Peking University', 'Sophomore'), ('Shanghai Jiao Tong University', 'Freshman'), ('Shanghai Jiao Tong University', 'Junior'), ('Shanghai Jiao Tong University', 'Senior'), ('Shanghai Jiao Tong University', 'Sophomore'), ('Tsinghua University', 'Freshman'), ('Tsinghua University', 'Junior'), ('Tsinghua University', 'Senior'), ('Tsinghua University', 'Sophomore')])当size作为DataFrame的属性时,返回的是表长乘以表宽的大小,但在groupby对象上表示统计每个组的元素个数:
gro.size()
#
School Grade
,Fudan University Freshman 9
, Junior 12
, Senior 11
, Sophomore 8
,Peking University Freshman 13
, Junior 8
, Senior 8
, Sophomore 5
,Shanghai Jiao Tong University Freshman 13
, Junior 17
, Senior 22
, Sophomore 5
,Tsinghua University Freshman 17
, Junior 22
, Senior 14
, Sophomore 16
,dtype: int64get_group方法可以直接获取所在组对应的行,此时必须知道组的名字:
gb.get_group(('Fudan University', 'Freshman'))内置聚合函数
直接定义在groupby对象的聚合函数,包括如下函数:max/min/mean/median/count/all/any/idxmax/idxmin/mad/nunique/quantile/sum/std/var/size
| ? | Height | |
|---|---|---|
| Gender | ? | ? |
| Female | 170.2 | 63.0 |
| Male | 193.9 | 89.0 |
?agg方法
groupby对象有一些缺点:
- 无法同时使用多个函数
- 无法对特定的列使用特定的聚合函数
- 无法使用自定义的聚合函数
- 无法直接对结果的列名在聚合前进行自定义命名
可以通过agg函数解决这些问题:
当使用多个聚合函数时,需要用列表的形式把内置聚合函数对应的字符串传入,先前提到的所有字符串都是合法的。
?
gb.agg(['sum', 'idxmax', 'skew'])
# 对height和weight分别用三种方法聚合,所以共返回六列数据
对特定的列使用特定的聚合函数
可以通过构造字典传入agg中实现,其中字典以列名为键,以聚合字符串或字符串列表为值
gb.agg({'Height':['mean','max'], 'Weight':'count'})使用自定义函数?
在agg中可以使用具体的自定义函数,需要注意传入函数的参数是之前数据源中的列,逐列进行计算需要注意传入函数的参数是之前数据源中的列,逐列进行计算。分组计算身高和体重的极差:
?
gb.agg(lambda x: x.mean()-x.min())?
| ? | height | weight |
| gender | ? | ? |
| female | 13.79697 | 13.918519 |
| male | 17.92549 | 21.759259 |
????????
def my_mean_diff(values,diff_value):
return values.mean() - diff_value
global_mean = df.lifeExp.mean()
df.groupby('continent')['lifeExp'].aggregate(my_mean_diff,diff_value = global_mean)
# 结果
continent
Africa -10.609109
Americas 5.184297
Asia 0.590464
Europe 12.429247
Oceania 14.851769
Name: lifeExp, dtype: float64agg函数对某个组进行聚合操作,一个组返回一个值
# 对一个字段 做多种不同聚合计算
df.groupby('year').lifeExp.agg([np.mean,np.std,np.count_nonzero])变换函数与transform方法
变换函数的返回值为同长度的序列,最常用的内置变换函数是累计函数:cumcount/cumsum/cumprod/cummax/cummin,它们的使用方式和聚合函数类似,只不过完成的是组内累计操作。
gb.cummax().head()| ? | Height | |
|---|---|---|
| 0 | 158.9 | 46.0 |
| 1 | 166.5 | 70.0 |
| 2 | 188.9 | 89.0 |
| 3 | NaN | 46.0 |
| 4 | 188.9 | 89.0 |
?
当用自定义变换时需要使用transform方法,被调用的自定义函数,其传入值为数据源的序列其传入值为数据源的序列,与agg的传入类型是一致的,其最后的返回结果是行列索引与数据源一致的DataFrame。
分组之后, 如果走聚合, 每一组会对应一条记录, 当分组之后, 后续的处理不要影响数据的条目数, 把聚合值和每一条记录进行计算, 这时就可以使用分组转换(类似SQL的窗口函数)
def my_zscore(x):
return (x-x.mean())/x.std()
df['zScore_by_year'] = df.groupby('year')['lifeExp'].transform(my_zscore)
transform其实就是对每一组的每个元素与mean(聚合值)值进行计算,列数与原来一样:
可以看出条目数没有发生变化:?
 ?
?
对身高和体重进行分组标准化,即减去组均值后除以组的标准差:
gb.transform(lambda x: (x-x.mean())/x.std()).head()
# gb是对gender的分组,x.mean()是x所属的组的平均值| ? | Height | Weight |
| 0 | -0.058760 | -0.354888 |
| 1 | -1.010925 | -0.355000 |
| 2 | 2.167063 | 2.089498???????? |
| 3 | NaN | -1.279789 |
| 4 | 0.053133 | 0.159631 |
?transform只能返回同长度的序列,但还可以返回一个标量,会使得结果被广播到其所在的整个组,这种标量广播标量广播的技巧在特征工程中是非常常见的。构造两列新特征来分别表示样本所在性别组的身高均值和体重均值:
gb.transform('mean').head() # 传入返回标量的函数也是可以的| ? | Height | Weight |
| 0 | 159.19697 ? | 47.918519 |
| 1 | 173.62549 | 72.759259 |
| 2 | 173.62549???????? | 72.759259 |
组索引与过滤
过滤在分组中是对于组的过滤,而索引是对于行的过滤,返回值无论是布尔列表还是元素列表或者位置列表,本质上都是对于行的筛选,如果符合筛选条件的则选入结果表,否则不选入。
组过滤作为行过滤的推广,指的是如果对一个组的全体所在行进行统计的结果返回True则会被保留,False则该组会被过滤,最后把所有未被过滤的组其对应的所在行拼接起来作为DataFrame返回。
在groupby对象中,定义了filter方法进行组的筛选,其中自定义函数的输入参数为数据源构成的DataFrame本身,在之前定义的groupby对象中,传入的就是df[['Height', 'Weight']],因此所有表方法和属性都可以在自定义函数中相应地使用,同时只需保证自定义函数的返回为布尔值即可。
在原表中通过过滤得到所有容量大于100的组:
gb.filter(lambda x: x.shape[0] > 100).head()apply自定义函数
还有一种常见的分组场景,无法用前面介绍的任何一种方法处理,定义身体质量指数BMI:
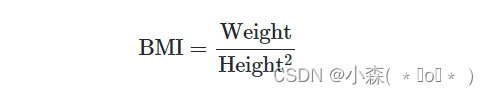
不是过滤操作,因此filter不符合要求;返回的均值是标量而不是序列,因此transform不符合要求;agg函数能够处理,但是聚合函数是逐列处理的,而不能够多列数据同时处理。引出了apply函数来解决这一问题。?
apply的使用
Series的Apply方法
df = pd.DataFrame({'a':[10,20,30],'b':[20,30,40]})
def my_sq(x):
return x**2
df['a'].apply(my_sq)
# 结果
0 100
1 400
2 900
# apply传入多个参数
def my_exp(x,e):
return x**e
df['a'].apply(my_exp,e =3)
# 结果
0 1000
1 8000
2 27000
Name: a, dtype: int64题目:创建一个新的列'new_column',其值为'column1'中每个元素的两倍,当原来的元素大于10的时候,将新列里面的值赋0????
import pandas as pd
data = {'column1':[1, 2, 15, 4, 8]}
df = pd.DataFrame(data)
df['new_column'] =df['column1'].apply(lambda x:x*2)
# 检查'column1'中的每个元素是否大于10,如果是,则将新列'new_column'中的值赋为0
df['new_column'] = df.apply(lambda row: 0 if row['column1'] > 10 else row['new_column'], axis=1) # 按行
最后的检查部分是按行传入apply方法,lambda row 是标明传入的是行,可以简单理解为df['new_column'] = 0或原值,执行了五次,每次都是行内检查赋值。?
题目:请创建一个两列的DataFrame数据,自定义一个lambda函数用来两列之和,并将最终的结果添加到新的列'sum_columns'当中? ?
import pandas as pd
data = {'column1': [1, 2, 3, 4, 5], 'column2': [6, 7, 8, 9, 10]}
df = pd.DataFrame(data)
sum_columns =df.apply(lambda row:row['column1']+row['column2'],axis=1) # 按行
df['sum_columns'] = sum_columns
# sum_columns 返回值是row['column1']+row['column2'],所以要按行传入:lambda rowapply的自定义函数传入参数与filter完全一致,只不过后者只允许返回布尔值。?
当apply()函数与groupby()结合使用时,传入apply()的是每个分组的DataFrame。这个DataFrame包含了被分组列的所有值以及该分组在其他列上的所有值。
gb = df.groupby('Gender')[['Height', 'Weight']]
def BMI(x):
Height = x['Height']/100 # 先按行操作
Weight = x['Weight']
BMI_value = Weight/Height**2
return BMI_value.mean() # 再按列操作
gb.apply(BMI)
#
Gender
,Female 18.860930
,Male 24.318654
,dtype: float64标量情况:结果得到的是?Series?,索引与?agg?的结果一致
gb = df.groupby(['Gender','Test_Number'])[['Height','Weight']]
gb.apply(lambda x: 0)
#
Gender Test_Number
,Female 1 0
, 2 0
, 3 0
,Male 1 0
, 2 0
, 3 0
,dtype: int64? 将每个组的每个元素都分配了一个值? ? ??
gb.apply(lambda x: [0, 0]) # 虽然是列表,但是作为返回值仍然看作标量
#
Gender Test_Number
,Female 1 [0, 0]
, 2 [0, 0]
, 3 [0, 0]
,Male 1 [0, 0]
, 2 [0, 0]
, 3 [0, 0]
,dtype: object????????
????????
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!