postgresql 流复制原理
2024-01-10 13:40:51
这部分纯理论内容,结合配图和数据进程了解流复制的工作逻辑。
通过WAL完成复制的方式
PostgreSQL在数据目录下的pg_wal(旧版为pg_xlog)子目录中维护了一个WAL日志文件,该文件用于记录数据库文件的每次改变,这种日志文件机制提供了一种数据库热备份的方案,即:在把数据库使用文件系统的方式备份出来的同时也把相应的WAL日志进行备份,即使备份出来的数据块不一致,也可以重放WAL日志把备份的内容推到一致状态。这也就是基于时间点的备份(Point-in-Time Recovery),简称PITR。
把WAL日志传送到另一台服务器有两种方式,分别是:
- WAL日志归档(base-file)
写完一个WAL日志后,才把WAL日志文件拷贝到standby数据库中,简言之就是通过cp命令实现远程备份,这样通常备库会落后主库一个WAL日志文件。 - 流复制(streaming replication)
流复制是postgresql9.x之后才提供的新的传递WAL日志的方法,它的好处是只要master库一产生日志,就会马上传递到standby库,同第一种相比有更低的同步延迟,所以我们肯定也会选择流复制的方式。
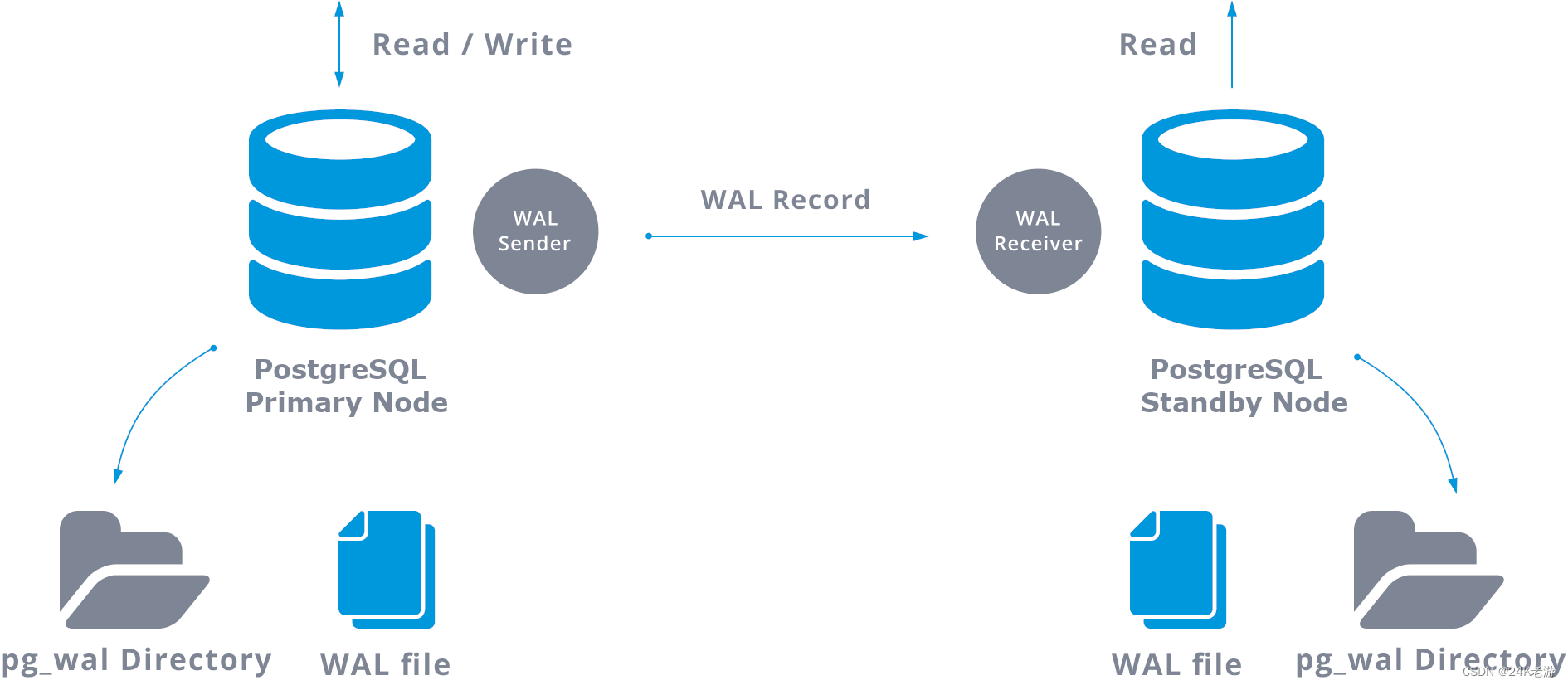
postgresql wal 日志介绍
wal日志即write ahead log预写式日志,简称wal日志。wal日志可以说是PostgreSQL中十分重要的部分,相当于oracle中的redo日志。
当数据库中数据发生变更时:
change发生时:先要将变更后内容计入wal buffer中,再将变更后的数据写入data buffer;
commit发生时:wal buffer中数据刷新到磁盘;
checkpoint发生时:将所有data buffer刷新的磁盘。
如果没有wal日志,那么每次更新都会将数据刷到磁盘上,并且这个动作是随机i/o,性能可想而知。并且没有wal日志,关系型数据库中事务的ACID如何保证呢?因此wal日志重要性可想而知。其中心思想就是:先写入日志文件,再写入数据。
最简的主从配置完成后,可以观察主库和从库启动的进程。
[pg@localhost ~]$ ps -auxf|grep postgres|grep -v grep
pg 31569 0.0 0.4 396536 17048 pts/0 S 10:17 0:00 /usr/pgsql-10/bin/postgres -D /data/db2
pg 31570 0.0 0.0 251456 1952 ? Ss 10:17 0:00 \_ postgres: logger process
pg 31571 0.0 0.0 396632 3416 ? Ss 10:17 0:00 \_ postgres: startup process recovering 000000010000000000000001
pg 31572 0.0 0.0 396536 3704 ? Ss 10:17 0:00 \_ postgres: checkpointer process
pg 31573 0.0 0.0 396536 3212 ? Ss 10:17 0:00 \_ postgres: writer process
pg 31574 0.0 0.0 251452 1988 ? Ss 10:17 0:00 \_ postgres: stats collector process
pg 4314 0.0 0.1 403804 4236 ? Ss 11:41 0:00 \_ postgres: wal receiver process streaming 0/16BEDA0
pg 4304 0.0 0.4 396536 17040 pts/0 S 11:41 0:00 /usr/pgsql-10/bin/postgres -D /data/db1
pg 4305 0.0 0.0 251456 1956 ? Ss 11:41 0:00 \_ postgres: logger process
pg 4307 0.0 0.0 396688 3688 ? Ss 11:41 0:00 \_ postgres: checkpointer process
pg 4308 0.0 0.0 396536 3448 ? Ss 11:41 0:00 \_ postgres: writer process
pg 4309 0.0 0.1 396536 6348 ? Ss 11:41 0:00 \_ postgres: wal writer process
pg 4310 0.0 0.0 396944 3080 ? Ss 11:41 0:00 \_ postgres: autovacuum launcher process
pg 4311 0.0 0.0 251588 2180 ? Ss 11:41 0:00 \_ postgres: stats collector process
pg 4312 0.0 0.0 396828 2520 ? Ss 11:41 0:00 \_ postgres: bgworker: logical replication launcher
pg 4315 0.0 0.0 397328 3568 ? Ss 11:41 0:00 \_ postgres: wal sender process pg ::1(43162) streaming 0/16BEDA0
postgresql主从同步流程
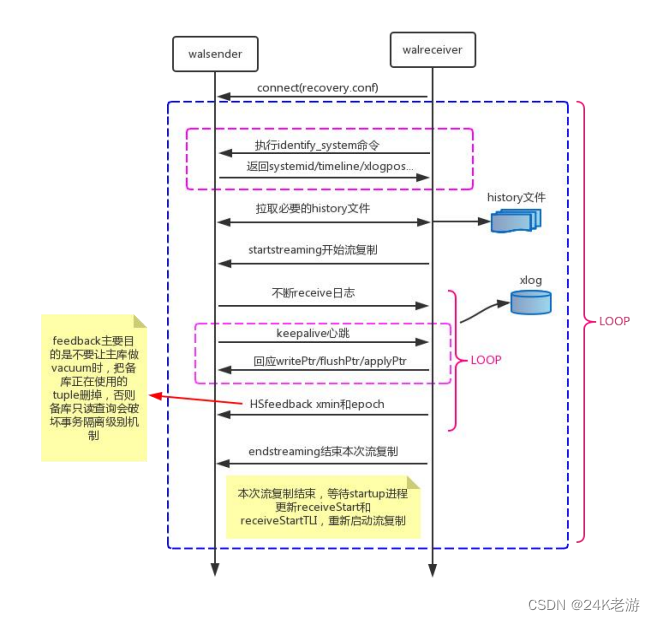
主要分为以下几个流程:
- 备库启动walreceiver进程,walreceiver进程向主库发送连接请求。
- 主库收到连接请求后启动walsender进程,并与walreceiver进程建立tcp连接。
- 备库walreceiver进程发送最新的wal lsn给主库。
- 主库进行lsn对比,定期向备库发送心跳信息来确认备库可用性,并且将没有传递的wal日志进行发送,同时调用SyncRepWaitForLSN()函数来获取锁存器,并且等待备库响应,锁存器的释放时机和主备同步模式的选择有关。
- 备库调用操作系统write()函数将wal写入缓存,然后调用操作系统fsync()函数将wal刷新到磁盘,然后进行wal回放。同时备库向主库返回ack信息,ack信息中包含write_lsn、flush_lsn、replay_lsn,这些信息会发送给主库,用以告知主库当前wal日志在备库的应用位置及状态,相关位置信息可以通过pg_stat_replication视图查看。
- 如果启用了hot_standby_feedback参数,备库会定期向主库发送xmin信息,用以保证主库不会vacuum掉备库需要的元组信息
postgresql同步模式
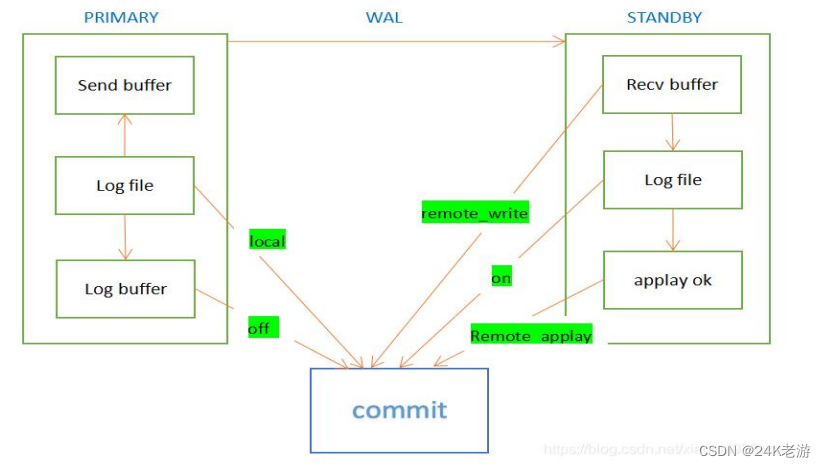
Postgresql数据库提供了五种同步模式,同步模式主要由synchronous_commit参数控制。下面简单介绍一下五种同步模式的区别:
- off:对于本机wal不用写到磁盘就可以提交,是异步模式,存在数据丢失风险。
- local:不管有没有备库只需要保证本机的wal日志刷到磁盘就行。
- remote_write:等待主库日志刷新到磁盘,同时日志传递到备库的操作系统缓存中,不需要刷盘就 能提交,不能避免操作系统崩溃。
- on:如果没有备库,表示wal日志需要刷新到本地的磁盘中才能提交,如果存在同步备库时(synchronous_standby_name不为空),需要等待远程备库也刷新到磁盘主库才能提交。
- remote_apply:pg高版本才出来的功能,备库刷盘并且回放成功,事务被标记为可见,用于做负载均衡,读写分离等
文章来源:https://blog.csdn.net/usoa/article/details/135500232
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!