WebRTC AEC回声消除算法拆解
WebRTC AEC算法流程分析——时延估计(一)
其实,网上有很多类似资料,各个大厂研发不同应用场景设备的音频工程师基本都对其进行了拆解,有些闪烁其词,有些却很深奥,笔者随着对WebRTC了解的深入,逐渐感觉其算法构思巧夺天工,算法逻辑的设计也采用了很多技巧,这就导致没有一定的C语言基础,很难理解其精妙之处,笔者精读完之后不禁让拍案叫绝,作为交流,本系列文章有感而记之,并为来者谏。(笔者C代码水平有限,难免所有错误)
前言
WebRTC AEC主要分为三大部分:延时估计,频域分块NLMS滤波器和非线性滤波,三部分数据处理相互关联,不可分割,且每一部分对整个语音信号处理来说至关重要,本篇文章主要针对时延估计模块进行分析,其他模块会陆续进行展开。
一、far_end 远端信号的处理
远端数据处理是一个单独的模块,主要包括对信号的分帧、加窗以及对应的傅里叶变换,并将处理之后的不同数据分配到不同的Buffer中,这里的数据块主要采用环形数组。
首先对一些参数进行初始化:
WebRtcAec_Create(&aecmInst);
WebRtcAec_Init(aecmInst, 16000, 16000);
config.nlpMode = kAecNlpAggressive;
WebRtcAec_set_config(aecmInst, config);
用fread(far_frame, sizeof(short), NN, fp_far)函数读入远端数据,并通过WebRtcAec_BufferFarend(aecmInst, far_frame, NN)函数对远端数据进行处理:
int32_t WebRtcAec_BufferFarend(void* aecInst,
const int16_t* farend,
int16_t nrOfSamples) {
这里的处理主要包括两部分:
for (i = 0; i < newNrOfSamples; i++) {
tmp_farend[i] = (float)farend_ptr[i];
}
WebRtc_WriteBuffer(aecpc->far_pre_buf, farend_float, (size_t)newNrOfSamples);
// Transform to frequency domain if we have enough data.
while (WebRtc_available_read(aecpc->far_pre_buf) >= PART_LEN2) {
// We have enough data to pass to the FFT, hence read PART_LEN2 samples.
WebRtc_ReadBuffer(
aecpc->far_pre_buf, (void**)&farend_float, tmp_farend, PART_LEN2);
WebRtcAec_BufferFarendPartition(aecpc->aec, farend_float);
// Rewind |far_pre_buf| PART_LEN samples for overlap before continuing.
WebRtc_MoveReadPtr(aecpc->far_pre_buf, -PART_LEN);
第一步:通过WebRtc_WriteBuffer函数将远端数据读入到环形数组中,环形数组的定义为:
RingBuffer* far_pre_buf; // Time domain far-end pre-buffer.
第二步就是通过While循环对数组进行缓存,由于读入的是10ms的数据,但是算法处理的帧长为64,重叠率50%,因此对数据进行了缓存,使fft变换的数据长度为128,通过WebRtc_MoveReadPtr(aecpc->far_pre_buf, -PART_LEN)函数对缓存数据进行更新,保证重叠率为50%;
数组缓存之后,通过WebRtcAec_BufferFarendPartition函数接口需要对数组进行FFT:
void WebRtcAec_BufferFarendPartition(AecCore* aec, const float* farend) {
float fft[PART_LEN2];
float xf[2][PART_LEN1];
// Check if the buffer is full, and in that case flush the oldest data.
if (WebRtc_available_write(aec->far_buf) < 1) {
WebRtcAec_MoveFarReadPtr(aec, 1);
}
// Convert far-end partition to the frequency domain without windowing.
memcpy(fft, farend, sizeof(float) * PART_LEN2);
TimeToFrequency(fft, xf, 0);
WebRtc_WriteBuffer(aec->far_buf, &xf[0][0], 1);
// Convert far-end partition to the frequency domain with windowing.
memcpy(fft, farend, sizeof(float) * PART_LEN2);
TimeToFrequency(fft, xf, 1);
WebRtc_WriteBuffer(aec->far_buf_windowed, &xf[0][0], 1);
}
考虑到后续回声消除和非线性处理会用到加窗和不加窗两部分不同的数组,因此,这里对缓存的数组进行加窗和不加窗两种处理方式,并放置在不同的buffer中。
以上是对远端数据的一个基本操作,但这里还有一点需要注意,由于初始缓存是160个数据,也就是10ms的数据,因此导致系统存在一个延迟,通过:
WebRtcAec_SetSystemDelay(aecpc->aec,
WebRtcAec_system_delay(aecpc->aec) + newNrOfSamples);
函数进行设置system_delay=160。这个在ProcessNormal函数中会用到。
msInSndCardBuf =
msInSndCardBuf > kMaxTrustedDelayMs ? kMaxTrustedDelayMs : msInSndCardBuf;
// TODO(andrew): we need to investigate if this +10 is really wanted.
msInSndCardBuf += 10;
二、时延估计
在网友博客webrtc aecd算法解析
中,罗列了导致延时的三种类型,可以作为参考:
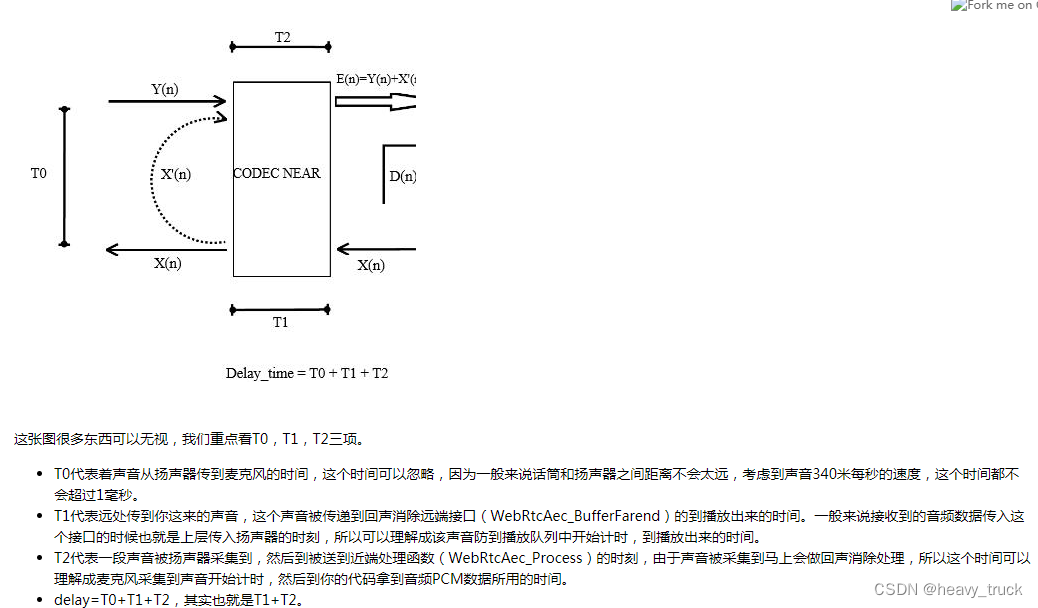
此外,这里还说到,硬件方面的延迟很容易确定,倒是软件方面的延迟比较难以估计。至于为什么这里以后会补充。
2.程序分析
其实,但从数据来说,系统的延迟时间前期可以通过仿真确定,手机,会议机以及耳机等终端设备的不同会导致不同程度的信号延迟,在前期仿真中可以通过互相关函数确定延迟的具体值。在WebRTC中,有两种模式对延迟信号进行估计。
首先通过WebRtcAec_Process函数将近端数据进行输入:
WebRtcAec_Process(aecmInst, near_frame, NULL, out_frame, NULL, NN, 40, 0);
这里的40就是前期估计的延迟时间,WebRtcAec_Process的函数为:
nt32_t WebRtcAec_Process(void* aecInst,
const int16_t* nearend,
const int16_t* nearendH,
int16_t* out,
int16_t* outH,
int16_t nrOfSamples,
int16_t msInSndCardBuf,
int32_t skew)
这里关注以下msInSndCardBuf参数,WebRTC的给的解释是:
* int16_t msInSndCardBuf Delay estimate for sound card and
* system buffers
这个参数就是前期代码仿真时通过互相关函数确定的延迟时间,在extended_filter_enabled=1的时候,以下会使能:
if (WebRtcAec_delay_correction_enabled(aecpc->aec)) {
ProcessExtended(
aecpc, nearend, nearendH, out, outH, nrOfSamples, msInSndCardBuf, skew);
然后会根据输入的msInSndCardBuf计算目标延迟,通过仿真完全可以和延迟时间对得上:
int target_delay = startup_size_ms * self->rate_factor * 8;
int overhead_elements = (WebRtcAec_system_delay(self->aec) - target_delay) / PART_LEN;
WebRtcAec_MoveFarReadPtr(self->aec, overhead_elements);
并根据计算出的overhead_elements 对信号进行延迟补充,WebRtcAec_MoveFarReadPtr函数如下:
int WebRtcAec_MoveFarReadPtr(AecCore* aec, int elements) {
int elements_moved = WebRtc_MoveReadPtr(aec->far_buf_windowed, elements);
WebRtc_MoveReadPtr(aec->far_buf, elements);
#ifdef WEBRTC_AEC_DEBUG_DUMP
WebRtc_MoveReadPtr(aec->far_time_buf, elements);
#endif
aec->system_delay -= elements_moved * PART_LEN;
return elements_moved;
}
这里其实对加窗和不加窗数据进行move。
以上是根据msInSndCardBuf参数进行的延迟计算,当然在线性滤波器阶段,本身还存一个延时估计:
if (aec->delayEstCtr == 0) {
wfEnMax = 0;
aec->delayIdx = 0;
for (i = 0; i < aec->num_partitions; i++) {
pos = i * PART_LEN1;
wfEn = 0;
for (j = 0; j < PART_LEN1; j++) {
wfEn += aec->wfBuf[0][pos + j] * aec->wfBuf[0][pos + j] +
aec->wfBuf[1][pos + j] * aec->wfBuf[1][pos + j];
}
if (wfEn > wfEnMax) {
wfEnMax = wfEn;
aec->delayIdx = i;
}
}
}
这里会估计出一个aec->delayIdx,那么和moved element就构成所有的延迟时间。
第二种方式通过一端时间的迭代,Web给出6帧数据,判断延迟是否稳定,在ProcessNormal中进行处理。
// Before we fill up the far-end buffer we require the system delay
// to be stable (+/-8 ms) compared to the first value. This
// comparison is made during the following 6 consecutive 10 ms
// blocks. If it seems to be stable then we start to fill up the
// far-end buffer.
待数据稳定之后就会通计算给出要移动的数据个数移动。
overhead_elements =
WebRtcAec_system_delay(aecpc->aec) / PART_LEN - aecpc->bufSizeStart;
WebRtcAec_MoveFarReadPtr(aecpc->aec, overhead_elements);
并在EstBufDelayNormal函数中进行一定条件的筛选。
至此,延迟主要的逻辑基本叙述完毕,其实Web真正深奥的倒是那些约束条件,这个不经过一定的实践和及深厚的理论基础是很难想得到,有机会再做补充。
3.参数说明
对于16k采用率,每帧处理的采样点数为64,对于的FFT变化的长度为128;
#define FRAME_LEN 80
#define PART_LEN 64 // Length of partition
#define PART_LEN1 (PART_LEN + 1) // Unique fft coefficients
#define PART_LEN2 (PART_LEN * 2) // Length of partition * 2
但是为了能够覆盖大部分延迟时间,数据开闭的buffer为1s的数据块:
static const size_t kBufSizePartitions = 250; // 1 second of audio in 16 kHz.
由于一帧数为64/16=4ms,那么16块对应64ms,12块数据对应48ms数据,因此也基本上能够覆盖一般的穿戴设备。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!