1.1 Heterogeneous Parallel Computing
1.1 Heterogeneous Parallel Computing
前言
基于单个中央处理器(CPU)的微处理器,如英特尔奔腾系列和AMD皓龙系列的微处理器,二十多年来推动了计算机应用程序的性能快速提高和成本降低。
这些微处理器将每秒千兆浮点运算(GFLOPS,或千兆(每秒10%的浮点运算))带到桌面,每秒将tera浮点运算(TFLOPS,或每秒Tera(1012)浮点运算)带到数据中心。这种对性能改进的不懈推动使应用软件能够提供更多功能,拥有更好的用户界面,并产生更有用的结果。反过来,一旦用户习惯了这些改进,他们就会要求更多的改进,为计算机行业创造一个积极的(良性)循环。
然而,自2003年以来,由于能耗和散热问题,这种驱动器已经放缓,这些问题限制了时钟频率的增加和在单个CPU内每个时钟周期内可以执行的生产活动水平。
从那时起,几乎所有微处理器供应商都转向在每个芯片中使用多个处理单元(称为处理器核心)的模型,以提高处理能力。这个开关对软件开发人员社区[Sutter 2005]产生了巨大影响。
传统上,绝大多数软件应用程序都是作为顺序程序编写的,由处理器执行,其设计是由冯诺伊曼在1945年的开创性报告中[vonNeumann 1945]。这些的执行人类可以循序渐进地完成代码来理解程序。从历史上看,大多数软件开发人员都依靠硬件的进步来提高其在引擎盖下顺序应用程序的速度;随着每一代新处理器的推出,相同的软件运行速度更快。计算机用户也已经习惯了这些程序在每个新一代微处理器上运行得更快的期望。从今天起,这种期望不再有效。顺序程序只会在其中一个处理器内核上运行,从一代到一代不会明显加快。如果没有性能改进,随着新微处理器的引入,应用程序开发人员将不再能够在其软件中引入新的特性和功能,从而减少整个计算机行业的增长机会。
相反,随着微处理器的每次新生成,将继续获得显著性能改进的应用程序软件将是并行程序,其中多个执行线程合作以更快地完成工作。这种新的、急剧升级的并行程序开发的激励被称为并发革命[Sutter 2005]。并行编程的实践绝非新鲜事。几十年来,高性能计算社区一直在开发并行程序。这些程序通常在大规模、昂贵的计算机上运行。只有少数精英应用程序可以证明使用这些昂贵的计算机是合理的,因此并行编程的实践仅限于少数应用程序开发人员。现在,所有新的微处理器都是并行计算机,需要作为并行程序开发的应用程序数量急剧增加。现在,软件开发人员非常需要学习并行编程,这是本书的重点。
HETEROGENEOUS PARALLEL COMPUTING
自2003年以来,半导体行业确定了设计微处理器的两个主要轨迹[Hwu 2008]。多核轨迹旨在保持顺序程序的执行速度,同时进入多个核心。多核从双核处理器开始,随着每个半导体工艺的生成,内核数量不断增加。目前的范例是最新的英特尔多核微处理器,具有多达12个处理器内核,每个内核都是异序的多指令问题处理器,实现完整的X86指令集,支持两个硬件线程的超线程,旨在最大限度地提高顺序程序的执行速度。有关CPU的更多讨论,请参阅https:// en.wikipedia.org/wiki/Central -processing_unit。
相比之下,多线程轨迹更侧重于并行应用程序的执行吞吐量。多线程从大量线程开始,线程数量再次随着每一代而增加。目前的范例是NVIDIA Tesla P100图形处理单元(GPU),10s of 1000s
线程,在大量简单的、有序的管道中执行。自2003年以来,多线程处理器,特别是GPU,一直引领着发泡点性能的竞争。截至2016年,多线程GPU和多核CPU之间的峰值浮点计算吞吐量比率约为10,在过去几年中,这一比率大致保持不变。这些不一定是应用程序速度,而只是执行资源在这些芯片中可能支持的原始速度。有关GPUS的更多讨论,请参阅https://en.wikipedia.org/wiki/ Graphics_processing_unit。
并行和顺序执行之间如此大的性能差距相当于巨大的电势“积累”,在某些时候,将不得不给出一些东西。我们已经到了那个地步。迄今为止,这种巨大的性能差距已经促使许多应用程序开发人员将其软件的计算密集型部分转移到GPU上进行执行。毫不奇怪,当有更多的工作要做时,这些计算密集型部分也是并行编程的主要目标,有更多的机会在合作的并行工人之间分配工作。
有人可能会问,为什么多线程GPU和通用多核CPU之间存在如此大的峰值吞吐量差距。答案在于两种类型的处理器之间基本设计哲学的差异,如图所示。1.1.CPU的设计针对顺序代码性能进行了优化。它利用复杂的控制逻辑,允许来自单个线程的指令并行执行,甚至不按顺序执行,同时保持顺序执行的外观。更重要的是,提供大型缓存存储器,以减少大型复杂应用程序的指令和数据访问延迟。控制逻辑和缓存存储器都不有助于峰值计算吞吐量。截至2016年,高端通用多核微处理器通常具有八个或更多大型处理器内核和许多兆字节的片上缓存存储器,旨在提供强大的顺序代码性能。
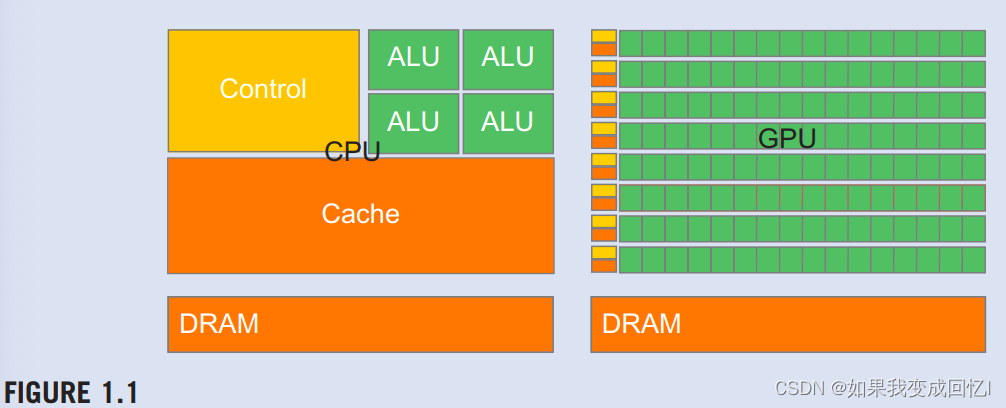
内存带宽是另一个重要问题。许多应用程序的速度受到数据从内存系统传输到处理器的速度的限制。图形芯片的运行速度大约是同时可用的CPU芯片的10倍。GPU必须能够将大量数据移入和移出其主要动态随机访问内存(DRAM),由于图形帧缓冲区要求。相比之下,通用的处理器必须满足传统操作系统、应用程序和I/O设备的要求,这些设备使内存带宽更困难。因此,我们预计CPU在内存带宽方面将在一段时间内继续处于劣势。
GPU的设计理念是由快速增长的视频游戏行业塑造的,该行业对在高级游戏中每个视频帧执行大量浮点计算的能力施加了巨大的经济压力。这种需求促使GPU供应商寻求最大化芯片面积和专用于浮点计算的电力预算的方法。一个重要的观察是,在功率和芯片区域方面,减少延迟比增加吞吐量要昂贵得多。因此,流行的解决方案是优化大量线程的执行吞吐量。该设计允许管道内存通道和算术运算具有长延迟,从而节省了芯片面积和功率。内存访问硬件和算术单元的减少面积和功率允许设计人员在芯片上拥有更多内存访问硬件和算术单元,从而增加总执行吞吐量。
另一方面,CPU旨在最大限度地减少单个线程的执行延迟。大型最后一级片上缓存旨在捕获经常访问的数据,并将一些长延迟内存访问转换为短延迟缓存访问。算术单元和操作数数据交付逻辑旨在最大限度地减少有效的操作延迟,但代价是增加芯片面积和功率的使用。通过减少同一线程中操作的延迟,CPU硬件减少了每个线程的执行延迟。然而,大缓存内存、低延迟算术单元和复杂的操作数交付逻辑消耗芯片区域和功率,否则可用于提供更多的算术执行单元和内存访问通道。这种设计风格通常被称为面向延迟的设计。
现在应该清楚的是,GPU被设计为并行的、面向吞吐量的计算引擎,它们在某些CPU被设计为性能良好的任务上表现不佳。对于具有一个或很少线程的程序,操作延迟较低的CPU可以实现比GPU更高的性能。当程序具有大量线程时,具有更高执行吞吐量的GPU可以实现比CPU更高的性能。因此,人们应该期望许多应用程序同时使用CPU和GPU,在CPU上执行顺序部分,在GPU上执行数字密集型部分。这就是为什么NVIDIA在2007年推出的CUDA编程模型旨在支持应用程序的联合CPU-GPU执行。支持联合CPU-GPU执行的需求进一步反映在最新的编程模型中,如OpenCL(附录A)、OpenACC(见章节:使用OpenACC进行并行编程)和C++AMP(附录D)。
同样重要的是要注意,当应用程序开发人员选择处理器来运行其应用程序时,速度并不是唯一的决策因素。其他几个因素可能更重要。首先,选择的处理器必须在市场上拥有非常大的影响力,称为处理器的安装基础。原因很简单。软件开发成本最好由非常多的客户群体来证明。在市场占有率较小的处理器上运行的应用程序不会拥有庞大的客户群。这是传统并行计算系统的一个主要问题,与通用微处理器相比,这些系统的市场占有率可以忽略不计。只有少数由政府和大公司资助的精英应用程序在这些传统的并行计算系统上成功开发。这种情况随着多线程GPU而改变。由于它们在PC市场上的受欢迎程度,GPU已售出数亿。几乎所有的PC都有GPU。到目前为止,有近10亿个支持CUDA的GPU在使用。如此庞大的市场存在使这些GPU对应用程序开发人员具有经济吸引力。
另一个重要的决策因素是实用的形式因素和易于访问。直到2006年,并行软件应用程序通常在数据中心服务器或部门集群上运行。但这种执行环境往往会限制这些应用程序的使用。例如,在医学成像等应用程序中,发布基于64节点集群机器的论文是可以的。然而,核磁共振机器上的现实世界临床应用利用了PC和特殊硬件加速器的某种组合。原因很简单,通用电气和西门子等制造商不能将带有计算机服务器盒架的核磁共振成像出售到临床环境中,而这在学术部门环境中很常见。事实上,NIH在一段时间内拒绝资助并行编程项目;他们认为并行软件的影响是有限的,因为巨大的基于集群的机器在临床环境中无法工作。今天,许多公司向带有GPU的核磁共振成像产品提供产品,美国国立卫生研究院使用GPU计算资助研究。
在选择执行数字计算应用程序的处理器时,另一个重要考虑因素是对IBBE浮点标准的支持水平。该标准使来自不同供应商的处理器之间能够获得可预测的结果。虽然早期GPU对IEEE浮点标准的支持并不强,但自2006年以来,新一代GPU也发生了变化。正如我们将在第6章中讨论的那样,数值考虑因素,对IEEE浮点标准的GPU支持已经变得可以与CPU相媲美。因此,人们可以期望将更多的数值应用程序移植到GPU,并产生与CPU相似的结果值。直到2009年,一个主要障碍是GPU浮点算术单元主要是单精度。真正需要双精度浮点的应用程序不适合GPU执行。然而,随着最近的GPU的双重精度执行速度接近单精度的一半,这种情况已经发生了变化,只有高端CPU核心才能达到这一水平。这使得GPU更适合数字应用。此外,GPU支持Fused Multiply-Add,这减少了因多次四舍五入操作而导致的错误。
直到2006年,图形芯片非常难以使用,因为程序员必须使用等效的图形应用程序编程接口(API)功能来访问处理单元,这意味着需要OpenGL或Direct3D技术来编程这些芯片。更简单地说,计算必须表示为以某种方式绘制像素的函数,才能在这些早期的GPU上执行。这种技术被称为GPGPU,用于使用GPU进行通用编程。即使有更高级别的编程环境,底层代码仍然需要适应设计用于绘制像素的API。这些API限制了人们实际上可以为早期GPU编写的应用程序类型。因此,它并没有成为一个普遍的编程现象。尽管如此,这项技术足够令人兴奋,激发了一些英勇的努力和出色的研究成果。
但随着CUDA[NVIDIA 2007]的发布,一切都在2007年发生了变化。NVIDIA实际上致力于硅领域来促进并行编程的便利性,因此这并不仅仅代表软件的变化;芯片中添加了额外的硬件。在G80及其后续并行计算芯片中,CUDA程序不再通过gqraphics接口。相反,硅芯片上一个新的通用并行编程接口可满足CUDA程序的请求。通用编程界面极大地扩展了人们可以轻松为GPU开发的应用程序类型。此外,所有其他软件层也都进行了重做,以便程序员可以使用熟悉的C/C++编程工具。我们的一些学生试图使用旧的基于OpenGL的编程接口完成实验室作业,他们的经验帮助他们非常欣赏这些改进,这些改进消除了将图形API用于通用计算应用程序的需要。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!