Python - 深夜数据结构与算法之 Map & Set

目录
一.引言
前面介绍了列表 List 及其衍生的栈 Stack 与队列 Queue,接下来我们介绍常见的数据结构 Map 与 Set,这两个数据结构底层结构很多都是通过?Hash Table 实现,当然也有使用二叉树的案例。下面我们简单学习下 Hash Table 及其相关的 Map & Set。
二.Map 与 Set
1.Hash Table

通过 Hash 函数我们可以将我们需要存储的值映射到一个下标 index 并存储到数组中。因为其是一一对应的关系,所以天然的也可以实现去重。
2.Hash Function
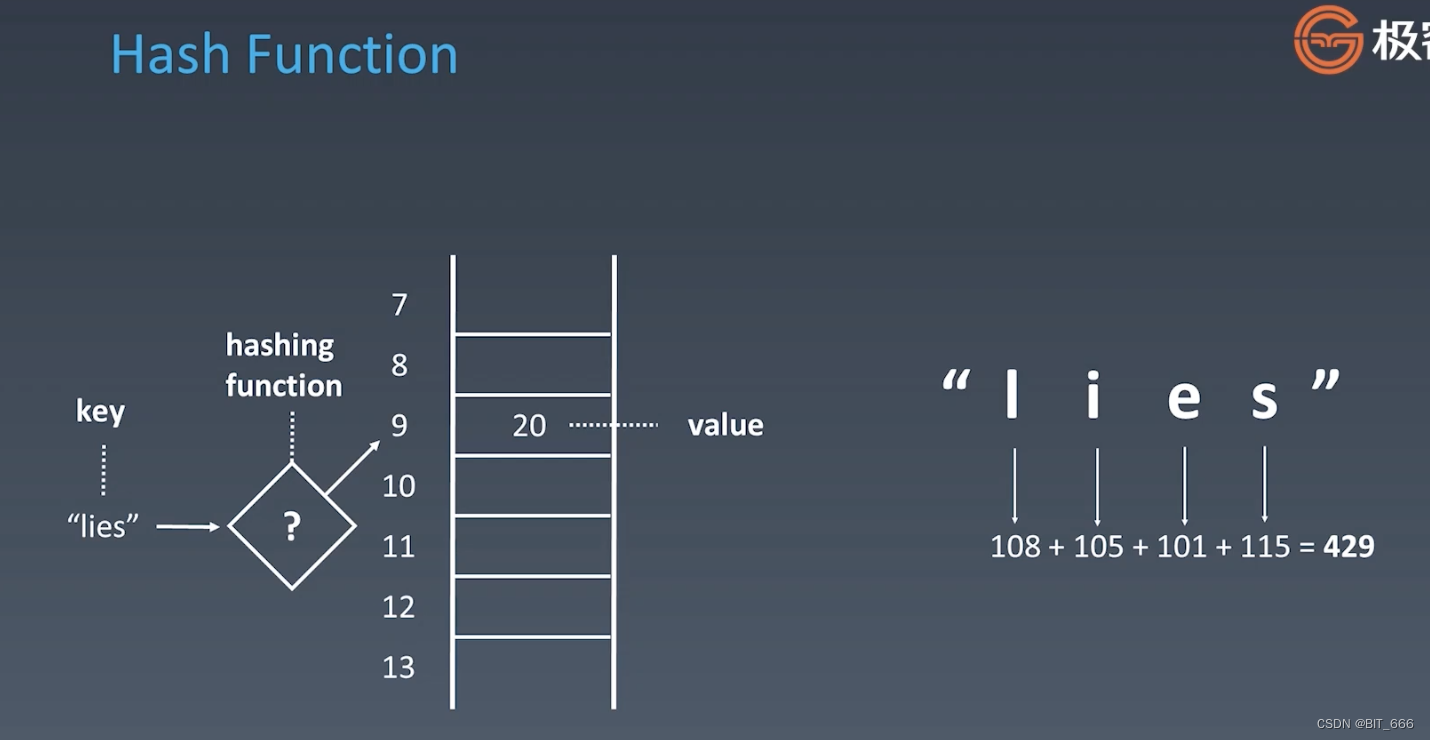
下面是 Hash Function 映射的示例,这里我们存储的 key 是一个 String,存储的 Value 是 Int,我们通过获取每个字符 Char 的 ASCII 码并相加 mod 10,最终得到 9,从而将 value=20 存储在数组中 9 的位置。
3.Hash Collisions
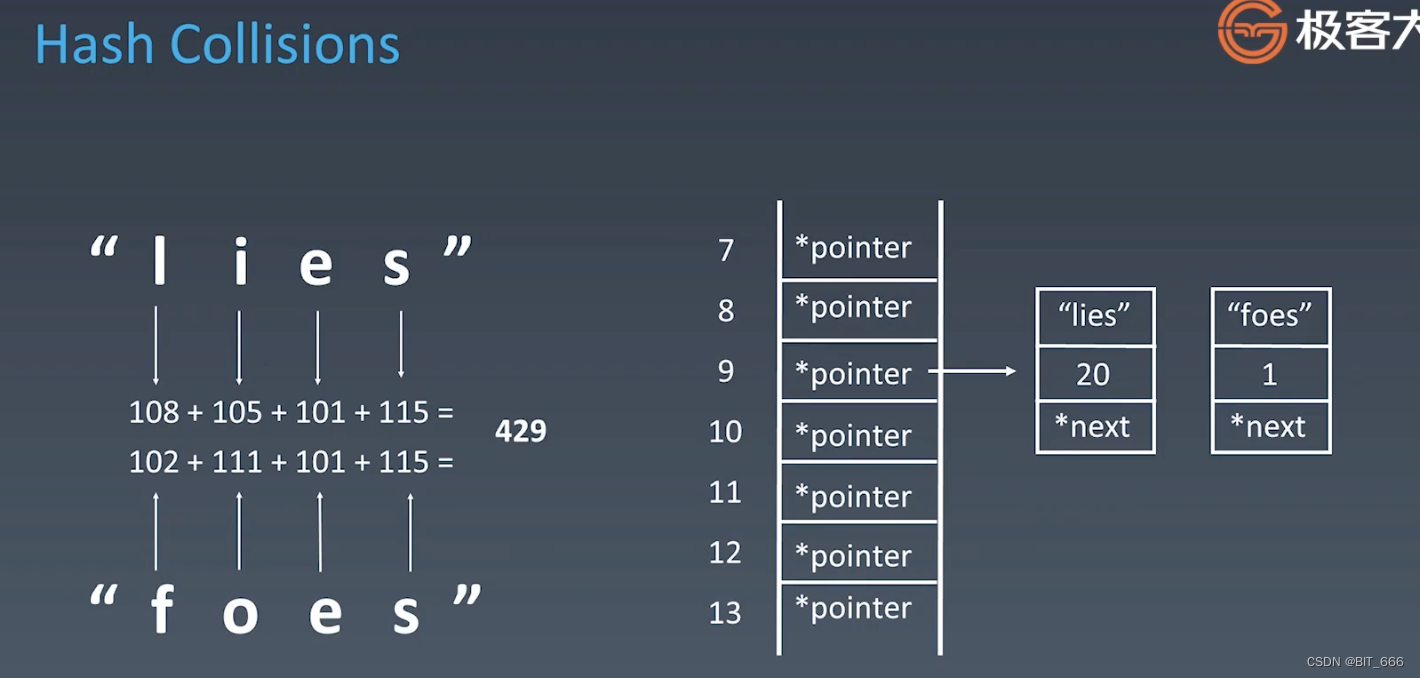
Hash 碰撞,对于一个 Hash Table 而言,好的 Hash Function 可以使得到的元素存储索引尽可能的分散,但实际情况中难免出现不同字符 Hash 到相同为止的情况。当使用 ASCII + mod 的 Hash Function 时,就会出现碰撞的情况,此时一种做法是直接覆盖,这样做会造成数据的丢失或异常,还有一种做法就是做一条 '拉链',我们在索引 9 处构造一个链表,每当碰撞时都会给链表添加一个新的 Node,以此类推。使用 Hash Table 寻找索引的时间复杂度为 o(1),但是如果索引处出现多次重复将会导致查询的复杂度升级为 o(n),所以对于 Hash Table 而言,一个好的 Hash Function 很关键。
4.Java/Python Code
◆?Java

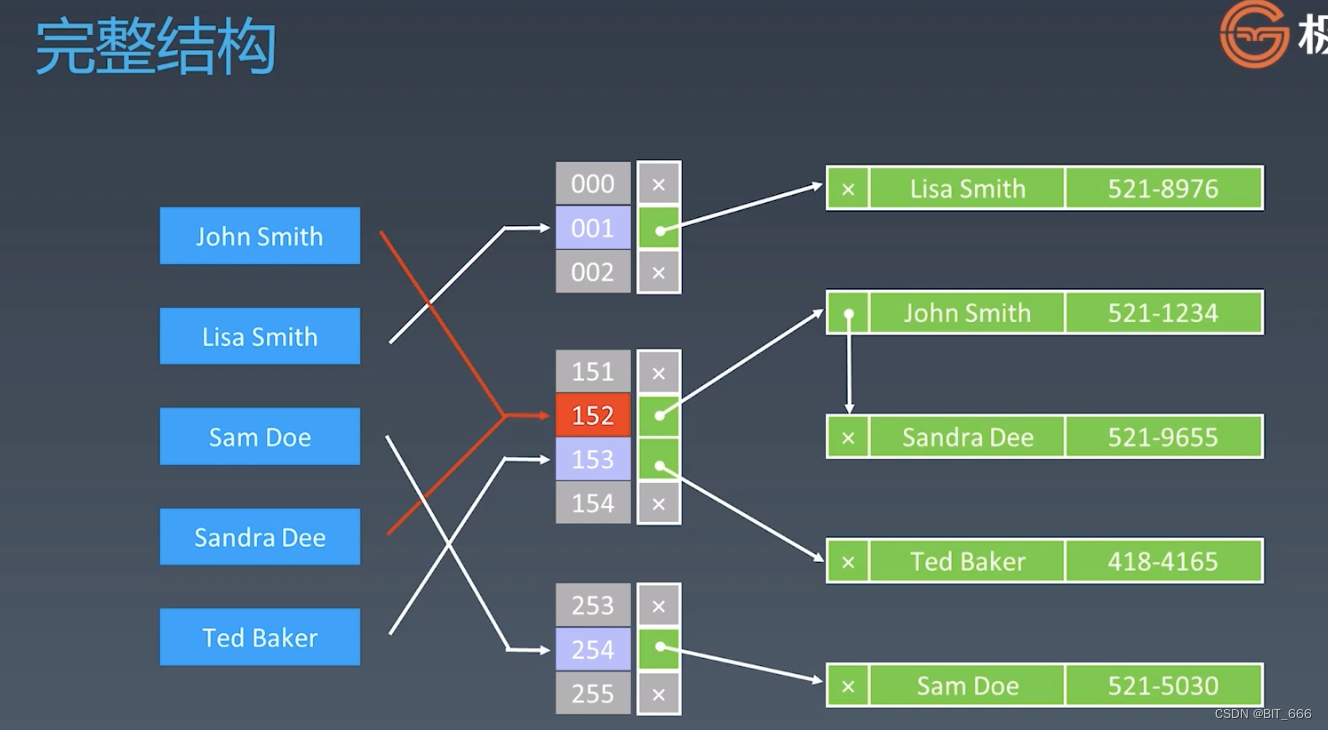
由 Hash Table 衍生而来最常用的数据结构就是 Map 与 Set,其中 Map 的 key 不重复,value 可以重复,其存储 k-v 对;而 Set 则是只存储不重复的元素。?最常用的就是 HashMap、HashSet,可以在 Collections 库中找到实现。
◆?Python

Python 使用 dict{} 与 set{} 实现,相比 Java 会更加简洁一点,但其存储特性和功能是一致的。?
三.经典算法实战
1.Two-Sum [1]
两数之和:?https://leetcode-cn.com/problems/two-sum/

◆?题目分析
算法的经典老大哥,在数组遍历的同时,我们引入 HashMap 记录遍历的值与索引,空间换时间提高算法效率。
◆?索引缓存
class Solution(object):
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
re = {}
for i in range(len(nums)):
cur_val = target - nums[i]
# 寻找与 target 的差值是否在 re 中
if cur_val in re:
# 在的话直接返回索引
return [i, re[cur_val]]
else:
re[nums[i]] = i通过 HashMap 存储对应元素的值与索引,如果找到匹配的值,返回二者的下标,没有找到匹配则存储继续向后遍历。?
2.Group-Anagrams [49]
字母异位词分组:?https://leetcode.cn/problems/group-anagrams/

◆?题目分析
字母异位词是指两个字符串字符与数量相同,但是位置不同的字符,例如 "abc"、"bca"、"cba" 等等。这里一个简单的方法就是对字符串进行排序即 sort,排序后的字符串有序,这样我们根据 key 构造 HashMap 存储即可。
◆?字符排序
class Solution(object):
def groupAnagrams(self, strs):
"""
:type strs: List[str]
:rtype: List[List[str]]
"""
re = {}
for text in strs:
# 排序后的字符作为 key
sorted_text = ''.join(sorted(text))
if sorted_text not in re:
re[sorted_text] = []
# 添加结果
re[sorted_text].append(text)
return re.values()这个题目和后面第 242 题的有效的字母异位词比较类似,都是借助 HashTable 实现去重和比较。?
3.Valid-Anagram [242]
有效的字母异位词:?https://leetcode.cn/problems/valid-anagram

◆?题目分析
有效的字母异位词,这里?Anagram 就是英文里异位词的意思,给定两个字符串,如果二者的每个字符出现次数一样,则认为二者互为异位词。因为是针对每个字符 Char 其出现次数一样,这里我们可以很快想到使用 WordCount,而最简单的办法就是构造 HashMap。
◆?WordCount
class Solution(object):
def isAnagram(self, s, t):
"""
:type s: str
:type t: str
:rtype: bool
"""
# 长度不一致直接返回
if len(s) != len(t):
return False
# 统计字符数量是否相等
word_count = {}
# 遍历 s 的 char
for char in s:
if char not in word_count:
word_count[char] = [0, 0]
word_count[char][0] += 1
# 遍历 t 的 char
for char in t:
# 情况1: 不满足包含相同字符
if char not in word_count:
return False
word_count[char][1] += 1
for listValue in word_count.values():
# 情况2: 不满足字符数量相同
if listValue[0] != listValue[1]:
return False
return True
使用 dict 记录 key 是否相同,key 不同直接返回 False;key 相同的情况下判断数组中 s、t 的 char 数量是否相同即可。?

◆?WordCount Plus
class Solution(object):
def isAnagram(self, s, t):
"""
:type s: str
:type t: str
:rtype: bool
"""
if len(s) != len(t):
return False
# 统计字符数量是否相等
word_count = {}
for i in range(len(s)):
# 加减抵消
if t[i] not in word_count:
word_count[t[i]] = 0
if s[i] not in word_count:
word_count[s[i]] = 0
word_count[s[i]] += 1
word_count[t[i]] -= 1
for count in word_count.values():
if count != 0:
return False
return True上面这个方法使用 [0, 0] 的计数数组进行 Char 的比较,还有一个省事的办法是使用一个变量,s 使用 +,t 使用 - ,如果遍历完该变量为 0,则代表 Char 数量一致。内存
![]()
◆?WordCount Pro Max
class Solution(object):
def isAnagram(self, s, t):
"""
:type s: str
:type t: str
:rtype: bool
"""
if len(s) != len(t):
return False
# 统计字符数量是否相等
word_count = [0] * 26
for char in s:
word_count[ord(char) - ord('a')] += 1
for char in t:
word_count[ord(char) - ord('a')] -= 1
# 判断 0
for count in word_count:
if count != 0:
return False
return True这里使用 ASCII 码 + List 实现了上面简介里最朴素的 Hash Function,这里使用 ord 获取 ASCII 码,使用 - ord('a') 获取相对位置,虽然用了 [0] x 26 限制了空间,但是空间复杂度还是不好。这里主要是引入?ord ASCII 码的思想,而上面的 Plus 则是引入抵消的思想。
四.总结
这里 HashMap 和 Set 的题目相比 ArrayList、Stack 和 Queue 要少一些,但是其核心思想需要掌握,那就是去重以及其空间换时间的操作。除此之外,这里我们学到了字符串的排序与字符串的 ASCII 码,这些辅助办法在后续的题目中也会需要。Keep Fighting!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!