优化算法3D可视化
编程实现优化算法,并3D可视化
1. 函数3D可视化
分别画出?和?
的3D图
import numpy as np from matplotlib import pyplot as plt import torch # 画出x**2 class Op(object): def __init__(self): pass def __call__(self, inputs): return self.forward(inputs) def forward(self, inputs): raise NotImplementedError def backward(self, outputs_grads): raise NotImplementedError class OptimizedFunction3D1(Op): def __init__(self): super(OptimizedFunction3D1, self).__init__() self.params = {'x': 0} self.grads = {'x': 0} def forward(self, x): self.params['x'] = x return x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1] def backward(self): x = self.params['x'] gradient1 = 2 * x[0] + x[1] gradient2 = 2 * x[1] + 3 * x[1] ** 2 + x[0] grad1 = torch.Tensor([gradient1]) grad2 = torch.Tensor([gradient2]) self.grads['x'] = torch.cat([grad1, grad2]) class OptimizedFunction3D2(Op): def __init__(self): super(OptimizedFunction3D2, self).__init__() self.params = {'x': 0} self.grads = {'x': 0} def forward(self, x): self.params['x'] = x return x[0] * x[0] / 20 + x[1] * x[1] / 1 def backward(self): x = self.params['x'] gradient1 = 2 * x[0] / 20 gradient2 = 2 * x[1] / 1 grad1 = torch.Tensor([gradient1]) grad2 = torch.Tensor([gradient2]) self.grads['x'] = torch.cat([grad1, grad2]) # 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值 x1 = np.arange(-3, 3, 0.1) x2 = np.arange(-3, 3, 0.1) x1, x2 = np.meshgrid(x1, x2) init_x = torch.Tensor(np.array([x1, x2])) model1 = OptimizedFunction3D1() model2 = OptimizedFunction3D2() # 绘制 f_3d 函数的三维图像,分别在两个子图中绘制 fig = plt.figure() # 绘制第一个子图 ax1 = fig.add_subplot(121, projection='3d') X = init_x[0].numpy() Y = init_x[1].numpy() Z1 = model1(init_x).numpy() ax1.plot_surface(X, Y, Z1, cmap='rainbow') ax1.set_xlabel('x1') ax1.set_ylabel('x2') ax1.set_zlabel('f(x1, x2)') ax1.set_title('Function 1') # 绘制第二个子图 ax2 = fig.add_subplot(122, projection='3d') Z2 = model2(init_x).numpy() ax2.plot_surface(X, Y, Z2, cmap='rainbow') ax2.set_xlabel('x1') ax2.set_ylabel('x2') ax2.set_zlabel('f(x1, x2)') ax2.set_title('Function 2') plt.show()

2.加入优化算法,画出轨迹?
import torch import numpy as np import copy from matplotlib import pyplot as plt from matplotlib import animation from itertools import zip_longest from nndl.op import Op class Optimizer(object): # 优化器基类 def __init__(self, init_lr, model): """ 优化器类初始化 """ # 初始化学习率,用于参数更新的计算 self.init_lr = init_lr # 指定优化器需要优化的模型 self.model = model def step(self): """ 定义每次迭代如何更新参数 """ pass class SimpleBatchGD(Optimizer): def __init__(self, init_lr, model): super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model) def step(self): # 参数更新 if isinstance(self.model.params, dict): for key in self.model.params.keys(): self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key] class Adagrad(Optimizer): def __init__(self, init_lr, model, epsilon): """ Adagrad 优化器初始化 输入: - init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数 """ super(Adagrad, self).__init__(init_lr=init_lr, model=model) self.G = {} for key in self.model.params.keys(): self.G[key] = 0 self.epsilon = epsilon def adagrad(self, x, gradient_x, G, init_lr): """ adagrad算法更新参数,G为参数梯度平方的累计值。 """ G += gradient_x ** 2 x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x return x, G def step(self): """ 参数更新 """ for key in self.model.params.keys(): self.model.params[key], self.G[key] = self.adagrad(self.model.params[key], self.model.grads[key], self.G[key], self.init_lr) class RMSprop(Optimizer): def __init__(self, init_lr, model, beta, epsilon): """ RMSprop优化器初始化 输入: - init_lr:初始学习率 - model:模型,model.params存储模型参数值 - beta:衰减率 - epsilon:保持数值稳定性而设置的常数 """ super(RMSprop, self).__init__(init_lr=init_lr, model=model) self.G = {} for key in self.model.params.keys(): self.G[key] = 0 self.beta = beta self.epsilon = epsilon def rmsprop(self, x, gradient_x, G, init_lr): """ rmsprop算法更新参数,G为迭代梯度平方的加权移动平均 """ G = self.beta * G + (1 - self.beta) * gradient_x ** 2 x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x return x, G def step(self): """参数更新""" for key in self.model.params.keys(): self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key], self.model.grads[key], self.G[key], self.init_lr) class Momentum(Optimizer): def __init__(self, init_lr, model, rho): """ Momentum优化器初始化 输入: - init_lr:初始学习率 - model:模型,model.params存储模型参数值 - rho:动量因子 """ super(Momentum, self).__init__(init_lr=init_lr, model=model) self.delta_x = {} for key in self.model.params.keys(): self.delta_x[key] = 0 self.rho = rho def momentum(self, x, gradient_x, delta_x, init_lr): """ momentum算法更新参数,delta_x为梯度的加权移动平均 """ delta_x = self.rho * delta_x - init_lr * gradient_x x += delta_x return x, delta_x def step(self): """参数更新""" for key in self.model.params.keys(): self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key], self.model.grads[key], self.delta_x[key], self.init_lr) class Nesterov(Optimizer): def __init__(self, init_lr, model, rho): """ Nesterov优化器初始化 输入: - init_lr:初始学习率 - model:模型,model.params存储模型参数值 - rho:动量因子 """ super(Nesterov, self).__init__(init_lr=init_lr, model=model) self.delta_x = {} for key in self.model.params.keys(): self.delta_x[key] = 0 self.rho = rho def nesterov(self, x, gradient_x, delta_x, init_lr): """ Nesterov算法更新参数,delta_x为梯度的加权移动平均 """ delta_x_prev = delta_x delta_x = self.rho * delta_x - init_lr * gradient_x x += -self.rho * delta_x_prev + (1 + self.rho) * delta_x return x, delta_x def step(self): """参数更新""" for key in self.model.params.keys(): self.model.params[key], self.delta_x[key] = self.nesterov(self.model.params[key], self.model.grads[key], self.delta_x[key], self.init_lr) class Adam(Optimizer): def __init__(self, init_lr, model, beta1, beta2, epsilon): """ Adam优化器初始化 输入: - init_lr:初始学习率 - model:模型,model.params存储模型参数值 - beta1, beta2:移动平均的衰减率 - epsilon:保持数值稳定性而设置的常数 """ super(Adam, self).__init__(init_lr=init_lr, model=model) self.beta1 = beta1 self.beta2 = beta2 self.epsilon = epsilon self.M, self.G = {}, {} for key in self.model.params.keys(): self.M[key] = 0 self.G[key] = 0 self.t = 1 def adam(self, x, gradient_x, G, M, t, init_lr): """ adam算法更新参数 输入: - x:参数 - G:梯度平方的加权移动平均 - M:梯度的加权移动平均 - t:迭代次数 - init_lr:初始学习率 """ M = self.beta1 * M + (1 - self.beta1) * gradient_x G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2 M_hat = M / (1 - self.beta1 ** t) G_hat = G / (1 - self.beta2 ** t) t += 1 x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat return x, G, M, t def step(self): """参数更新""" for key in self.model.params.keys(): self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key], self.model.grads[key], self.G[key], self.M[key], self.t, self.init_lr) class OptimizedFunction3D(Op): def __init__(self): super(OptimizedFunction3D, self).__init__() self.params = {'x': 0} self.grads = {'x': 0} def forward(self, x): self.params['x'] = x return x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1] def backward(self): x = self.params['x'] gradient1 = 2 * x[0] + x[1] gradient2 = 2 * x[1] + 3 * x[1] ** 2 + x[0] grad1 = torch.Tensor([gradient1]) grad2 = torch.Tensor([gradient2]) self.grads['x'] = torch.cat([grad1, grad2]) class Visualization3D(animation.FuncAnimation): """ 绘制动态图像,可视化参数更新轨迹 """ def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=600, blit=True, **kwargs): """ 初始化3d可视化类 输入: xy_values:三维中x,y维度的值 z_values:三维中z维度的值 labels:每个参数更新轨迹的标签 colors:每个轨迹的颜色 interval:帧之间的延迟(以毫秒为单位) blit:是否优化绘图 """ self.fig = fig self.ax = ax self.xy_values = xy_values self.z_values = z_values frames = max(xy_value.shape[0] for xy_value in xy_values) self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0] for _, label, color in zip_longest(xy_values, labels, colors)] super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames, interval=interval, blit=blit, **kwargs) def init_animation(self): # 数值初始化 for line in self.lines: line.set_data([], []) # line.set_3d_properties(np.asarray([])) # 源程序中有这一行,加上会报错。 Edit by David 2022.12.4 return self.lines def animate(self, i): # 将x,y,z三个数据传入,绘制三维图像 for line, xy_value, z_value in zip(self.lines, self.xy_values, self.z_values): line.set_data(xy_value[:i, 0], xy_value[:i, 1]) line.set_3d_properties(z_value[:i]) return self.lines def train_f(model, optimizer, x_init, epoch): x = x_init all_x = [] losses = [] for i in range(epoch): all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4. loss = model(x) losses.append(loss) model.backward() optimizer.step() x = model.params['x'] return torch.Tensor(np.array(all_x)), losses # 构建6个模型,分别配备不同的优化器 model1 = OptimizedFunction3D() opt_gd = SimpleBatchGD(init_lr=0.01, model=model1) model2 = OptimizedFunction3D() opt_adagrad = Adagrad(init_lr=0.5, model=model2, epsilon=1e-7) model3 = OptimizedFunction3D() opt_rmsprop = RMSprop(init_lr=0.1, model=model3, beta=0.9, epsilon=1e-7) model4 = OptimizedFunction3D() opt_momentum = Momentum(init_lr=0.01, model=model4, rho=0.9) model5 = OptimizedFunction3D() opt_adam = Adam(init_lr=0.1, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7) model6 = OptimizedFunction3D() opt_Nesterov = Nesterov(init_lr=0.1, model=model6, rho=0.9) models = [model1, model2, model3, model4, model5, model6] opts = [opt_gd, opt_adagrad, opt_rmsprop, opt_momentum, opt_adam, opt_Nesterov] x_all_opts = [] z_all_opts = [] # 使用不同优化器训练 for model, opt in zip(models, opts): x_init = torch.FloatTensor([2, 3]) x_one_opt, z_one_opt = train_f(model, opt, x_init, 150) # epoch # 保存参数值 x_all_opts.append(x_one_opt.numpy()) z_all_opts.append(np.squeeze(z_one_opt)) # 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值 x1 = np.arange(-3, 3, 0.1) x2 = np.arange(-3, 3, 0.1) x1, x2 = np.meshgrid(x1, x2) init_x = torch.Tensor(np.array([x1, x2])) model = OptimizedFunction3D() # 绘制 f_3d函数 的 三维图像 fig = plt.figure() ax = plt.axes(projection='3d') X = init_x[0].numpy() Y = init_x[1].numpy() Z = model(init_x).numpy() # 改为 model(init_x).numpy() David 2022.12.4 ax.plot_surface(X, Y, Z, cmap='rainbow') ax.set_xlabel('x1') ax.set_ylabel('x2') ax.set_zlabel('f(x1,x2)') labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam', 'Nesterov'] colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000'] animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=fig, ax=ax) ax.legend(loc='upper left') plt.show() animator.save('animation.gif') # 效果不好,估计被挡住了…… 有待进一步提高 Edit by David 2022.12.4
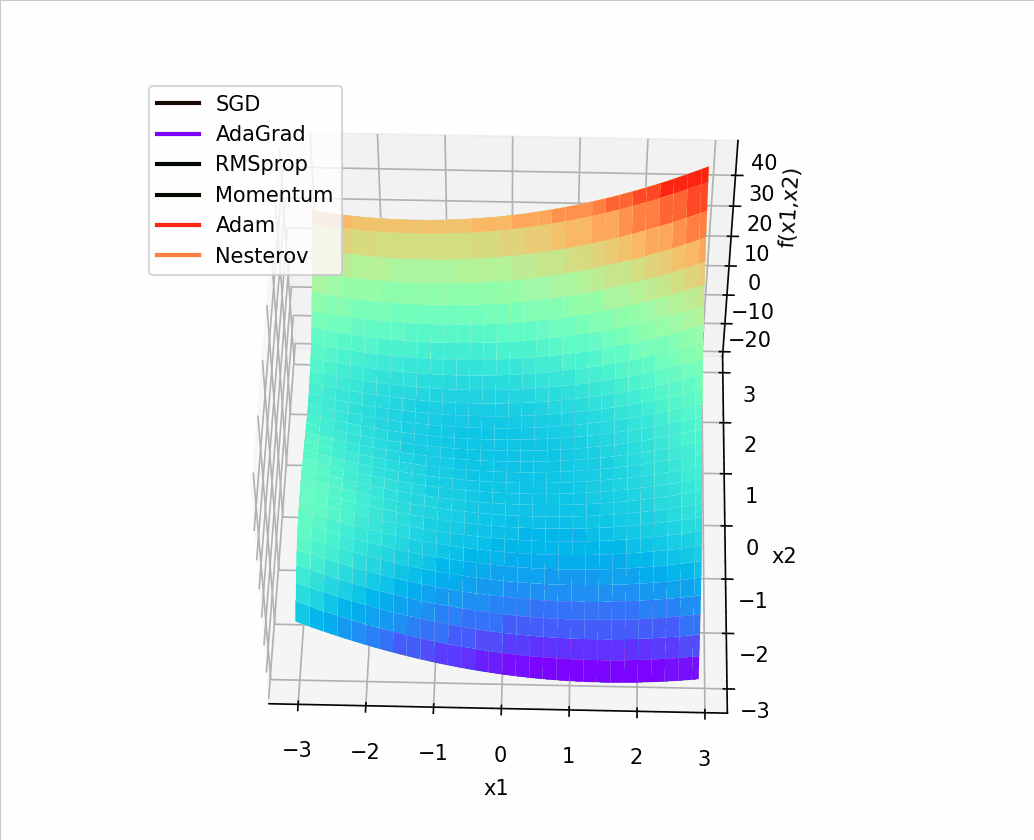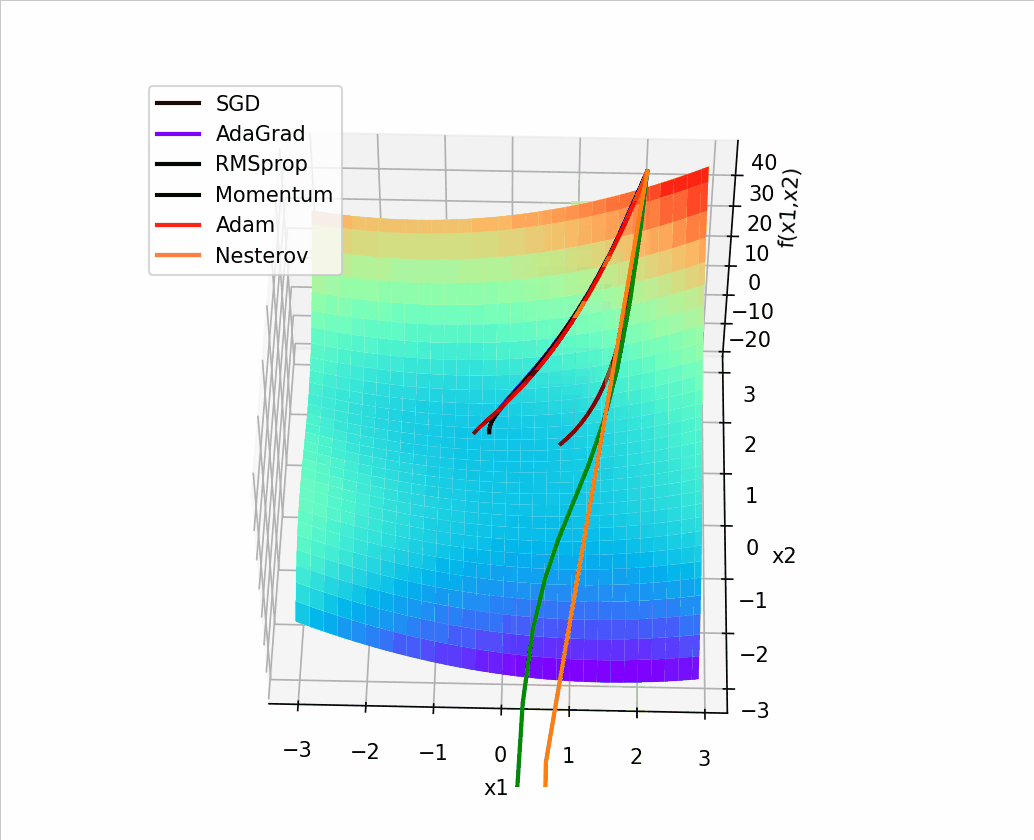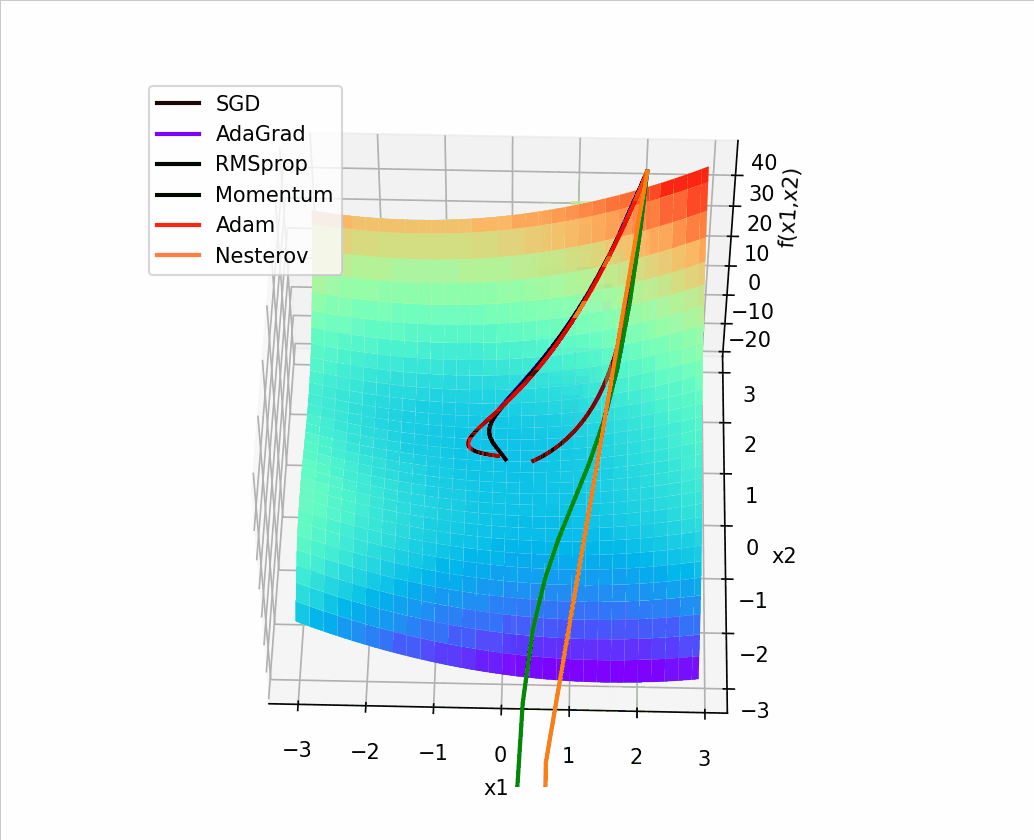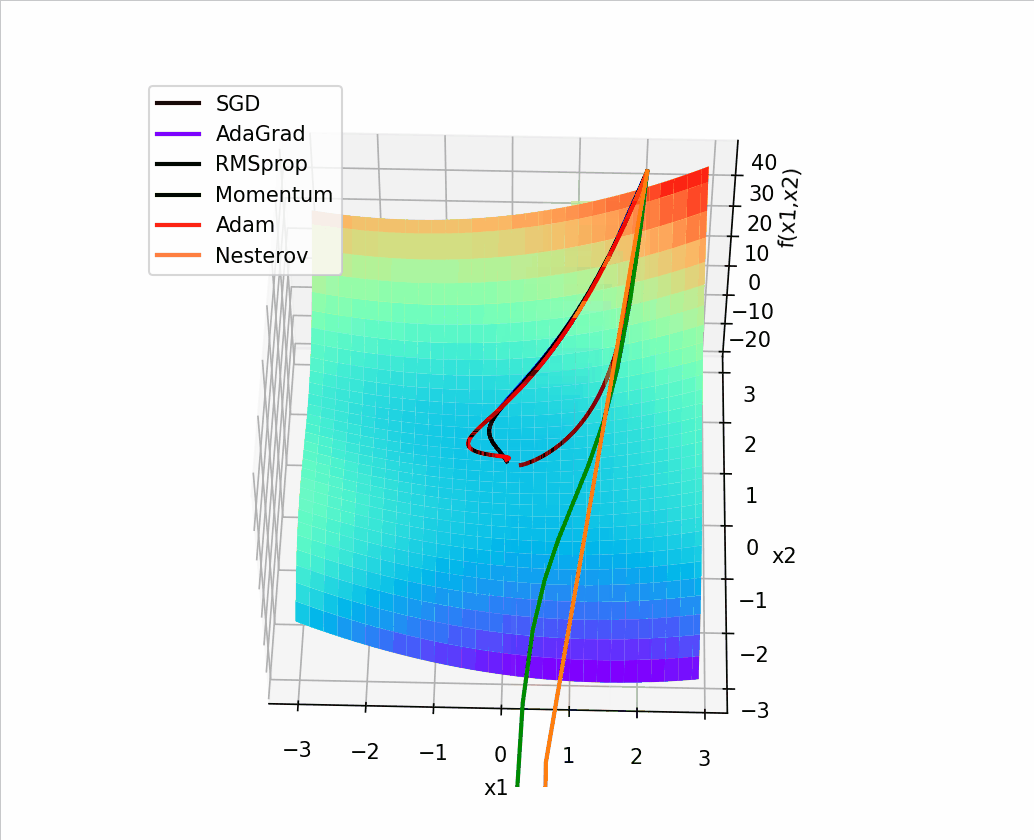
import torch
import numpy as np
import copy
from matplotlib import pyplot as plt
from matplotlib import animation
from itertools import zip_longest
from matplotlib import cm
class Op(object):
def __init__(self):
pass
def __call__(self, inputs):
return self.forward(inputs)
# 输入:张量inputs
# 输出:张量outputs
def forward(self, inputs):
# return outputs
raise NotImplementedError
# 输入:最终输出对outputs的梯度outputs_grads
# 输出:最终输出对inputs的梯度inputs_grads
def backward(self, outputs_grads):
# return inputs_grads
raise NotImplementedError
class Optimizer(object): # 优化器基类
def __init__(self, init_lr, model):
"""
优化器类初始化
"""
# 初始化学习率,用于参数更新的计算
self.init_lr = init_lr
# 指定优化器需要优化的模型
self.model = model
def step(self):
"""
定义每次迭代如何更新参数
"""
pass
class SimpleBatchGD(Optimizer):
def __init__(self, init_lr, model):
super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)
def step(self):
# 参数更新
if isinstance(self.model.params, dict):
for key in self.model.params.keys():
self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]
class Adagrad(Optimizer):
def __init__(self, init_lr, model, epsilon):
"""
Adagrad 优化器初始化
输入:
- init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数
"""
super(Adagrad, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.epsilon = epsilon
def adagrad(self, x, gradient_x, G, init_lr):
"""
adagrad算法更新参数,G为参数梯度平方的累计值。
"""
G += gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""
参数更新
"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
class RMSprop(Optimizer):
def __init__(self, init_lr, model, beta, epsilon):
"""
RMSprop优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta:衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(RMSprop, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.beta = beta
self.epsilon = epsilon
def rmsprop(self, x, gradient_x, G, init_lr):
"""
rmsprop算法更新参数,G为迭代梯度平方的加权移动平均
"""
G = self.beta * G + (1 - self.beta) * gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
class Momentum(Optimizer):
def __init__(self, init_lr, model, rho):
"""
Momentum优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- rho:动量因子
"""
super(Momentum, self).__init__(init_lr=init_lr, model=model)
self.delta_x = {}
for key in self.model.params.keys():
self.delta_x[key] = 0
self.rho = rho
def momentum(self, x, gradient_x, delta_x, init_lr):
"""
momentum算法更新参数,delta_x为梯度的加权移动平均
"""
delta_x = self.rho * delta_x - init_lr * gradient_x
x += delta_x
return x, delta_x
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],
self.model.grads[key],
self.delta_x[key],
self.init_lr)
class Adam(Optimizer):
def __init__(self, init_lr, model, beta1, beta2, epsilon):
"""
Adam优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta1, beta2:移动平均的衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(Adam, self).__init__(init_lr=init_lr, model=model)
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.M, self.G = {}, {}
for key in self.model.params.keys():
self.M[key] = 0
self.G[key] = 0
self.t = 1
def adam(self, x, gradient_x, G, M, t, init_lr):
"""
adam算法更新参数
输入:
- x:参数
- G:梯度平方的加权移动平均
- M:梯度的加权移动平均
- t:迭代次数
- init_lr:初始学习率
"""
M = self.beta1 * M + (1 - self.beta1) * gradient_x
G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2
M_hat = M / (1 - self.beta1 ** t)
G_hat = G / (1 - self.beta2 ** t)
t += 1
x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat
return x, G, M, t
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],
self.model.grads[key],
self.G[key],
self.M[key],
self.t,
self.init_lr)
class OptimizedFunction3D(Op):
def __init__(self):
super(OptimizedFunction3D, self).__init__()
self.params = {'x': 0}
self.grads = {'x': 0}
def forward(self, x):
self.params['x'] = x
return x[0] * x[0] / 20 + x[1] * x[1] / 1 # x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1]
def backward(self):
x = self.params['x']
gradient1 = 2 * x[0] / 20
gradient2 = 2 * x[1] / 1
grad1 = torch.Tensor([gradient1])
grad2 = torch.Tensor([gradient2])
self.grads['x'] = torch.cat([grad1, grad2])
class Visualization3D(animation.FuncAnimation):
""" 绘制动态图像,可视化参数更新轨迹 """
def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=100, blit=True, **kwargs):
"""
初始化3d可视化类
输入:
xy_values:三维中x,y维度的值
z_values:三维中z维度的值
labels:每个参数更新轨迹的标签
colors:每个轨迹的颜色
interval:帧之间的延迟(以毫秒为单位)
blit:是否优化绘图
"""
self.fig = fig
self.ax = ax
self.xy_values = xy_values
self.z_values = z_values
frames = max(xy_value.shape[0] for xy_value in xy_values)
self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0]
for _, label, color in zip_longest(xy_values, labels, colors)]
self.points = [ax.plot([], [], [], color=color, markeredgewidth=1, markeredgecolor='black', marker='o')[0]
for _, color in zip_longest(xy_values, colors)]
# print(self.lines)
super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames,
interval=interval, blit=blit, **kwargs)
def init_animation(self):
# 数值初始化
for line in self.lines:
line.set_data_3d([], [], [])
for point in self.points:
point.set_data_3d([], [], [])
return self.points + self.lines
def animate(self, i):
# 将x,y,z三个数据传入,绘制三维图像
for line, xy_value, z_value in zip(self.lines, self.xy_values, self.z_values):
line.set_data_3d(xy_value[:i, 0], xy_value[:i, 1], z_value[:i])
for point, xy_value, z_value in zip(self.points, self.xy_values, self.z_values):
point.set_data_3d(xy_value[i, 0], xy_value[i, 1], z_value[i])
return self.points + self.lines
def train_f(model, optimizer, x_init, epoch):
x = x_init
all_x = []
losses = []
for i in range(epoch):
all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4.
loss = model(x)
losses.append(loss)
model.backward()
optimizer.step()
x = model.params['x']
return torch.Tensor(np.array(all_x)), losses
# 构建5个模型,分别配备不同的优化器
model1 = OptimizedFunction3D()
opt_gd = SimpleBatchGD(init_lr=0.95, model=model1)
model2 = OptimizedFunction3D()
opt_adagrad = Adagrad(init_lr=1.5, model=model2, epsilon=1e-7)
model3 = OptimizedFunction3D()
opt_rmsprop = RMSprop(init_lr=0.05, model=model3, beta=0.9, epsilon=1e-7)
model4 = OptimizedFunction3D()
opt_momentum = Momentum(init_lr=0.1, model=model4, rho=0.9)
model5 = OptimizedFunction3D()
opt_adam = Adam(init_lr=0.3, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7)
models = [model1, model2, model3, model4, model5]
opts = [opt_gd, opt_adagrad, opt_rmsprop, opt_momentum, opt_adam]
x_all_opts = []
z_all_opts = []
# 使用不同优化器训练
for model, opt in zip(models, opts):
x_init = torch.FloatTensor([-7, 2])
x_one_opt, z_one_opt = train_f(model, opt, x_init, 100) # epoch
# 保存参数值
x_all_opts.append(x_one_opt.numpy())
z_all_opts.append(np.squeeze(z_one_opt))
# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值
x1 = np.arange(-10, 10, 0.01)
x2 = np.arange(-5, 5, 0.01)
x1, x2 = np.meshgrid(x1, x2)
init_x = torch.Tensor(np.array([x1, x2]))
model = OptimizedFunction3D()
# 绘制 f_3d函数 的 三维图像
fig = plt.figure()
ax = plt.axes(projection='3d')
X = init_x[0].numpy()
Y = init_x[1].numpy()
Z = model(init_x).numpy() # 改为 model(init_x).numpy() David 2022.12.4
surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm)
# fig.colorbar(surf, shrink=0.5, aspect=1)
# ax.set_zlim(-3, 2)
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_zlabel('f(x1,x2)')
labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam']
colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000']
animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=fig, ax=ax)
ax.legend(loc='upper right')
plt.show()
# animator.save('teaser' + '.gif', writer='imagemagick',fps=10) # 效果不好,估计被挡住了…… 有待进一步提高 Edit by David 2022.12.4
# save不好用,不费劲了,安装个软件做gif https://pc.qq.com/detail/13/detail_23913.html 这段代码我试了老师给的代码,不对劲,不能动,而且没有轨迹,更过分就是一会儿就自动关闭了,还有再优化优化
这段代码我试了老师给的代码,不对劲,不能动,而且没有轨迹,更过分就是一会儿就自动关闭了,还有再优化优化
改了一上午,终于好了,我修改了
class Visualization3D(animation.FuncAnimation)函数和图形显示部分
以下是我的代码:
import torch
import numpy as np
import copy
from matplotlib import pyplot as plt
from matplotlib import animation
from itertools import zip_longest
from matplotlib import cm
class Op(object):
def __init__(self):
pass
def __call__(self, inputs):
return self.forward(inputs)
# 输入:张量inputs
# 输出:张量outputs
def forward(self, inputs):
# return outputs
raise NotImplementedError
# 输入:最终输出对outputs的梯度outputs_grads
# 输出:最终输出对inputs的梯度inputs_grads
def backward(self, outputs_grads):
# return inputs_grads
raise NotImplementedError
class Optimizer(object): # 优化器基类
def __init__(self, init_lr, model):
"""
优化器类初始化
"""
# 初始化学习率,用于参数更新的计算
self.init_lr = init_lr
# 指定优化器需要优化的模型
self.model = model
def step(self):
"""
定义每次迭代如何更新参数
"""
pass
class SimpleBatchGD(Optimizer):
def __init__(self, init_lr, model):
super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)
def step(self):
# 参数更新
if isinstance(self.model.params, dict):
for key in self.model.params.keys():
self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]
class Adagrad(Optimizer):
def __init__(self, init_lr, model, epsilon):
"""
Adagrad 优化器初始化
输入:
- init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数
"""
super(Adagrad, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.epsilon = epsilon
def adagrad(self, x, gradient_x, G, init_lr):
"""
adagrad算法更新参数,G为参数梯度平方的累计值。
"""
G += gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""
参数更新
"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
class RMSprop(Optimizer):
def __init__(self, init_lr, model, beta, epsilon):
"""
RMSprop优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta:衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(RMSprop, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.beta = beta
self.epsilon = epsilon
def rmsprop(self, x, gradient_x, G, init_lr):
"""
rmsprop算法更新参数,G为迭代梯度平方的加权移动平均
"""
G = self.beta * G + (1 - self.beta) * gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
class Momentum(Optimizer):
def __init__(self, init_lr, model, rho):
"""
Momentum优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- rho:动量因子
"""
super(Momentum, self).__init__(init_lr=init_lr, model=model)
self.delta_x = {}
for key in self.model.params.keys():
self.delta_x[key] = 0
self.rho = rho
def momentum(self, x, gradient_x, delta_x, init_lr):
"""
momentum算法更新参数,delta_x为梯度的加权移动平均
"""
delta_x = self.rho * delta_x - init_lr * gradient_x
x += delta_x
return x, delta_x
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],
self.model.grads[key],
self.delta_x[key],
self.init_lr)
class Adam(Optimizer):
def __init__(self, init_lr, model, beta1, beta2, epsilon):
"""
Adam优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta1, beta2:移动平均的衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(Adam, self).__init__(init_lr=init_lr, model=model)
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.M, self.G = {}, {}
for key in self.model.params.keys():
self.M[key] = 0
self.G[key] = 0
self.t = 1
def adam(self, x, gradient_x, G, M, t, init_lr):
"""
adam算法更新参数
输入:
- x:参数
- G:梯度平方的加权移动平均
- M:梯度的加权移动平均
- t:迭代次数
- init_lr:初始学习率
"""
M = self.beta1 * M + (1 - self.beta1) * gradient_x
G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2
M_hat = M / (1 - self.beta1 ** t)
G_hat = G / (1 - self.beta2 ** t)
t += 1
x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat
return x, G, M, t
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],
self.model.grads[key],
self.G[key],
self.M[key],
self.t,
self.init_lr)
class OptimizedFunction3D(Op):
def __init__(self):
super(OptimizedFunction3D, self).__init__()
self.params = {'x': 0}
self.grads = {'x': 0}
def forward(self, x):
self.params['x'] = x
return x[0] * x[0] / 20 + x[1] * x[1] / 1 # x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1]
def backward(self):
x = self.params['x']
gradient1 = 2 * x[0] / 20
gradient2 = 2 * x[1] / 1
grad1 = torch.Tensor([gradient1])
grad2 = torch.Tensor([gradient2])
self.grads['x'] = torch.cat([grad1, grad2])
class Visualization3D(animation.FuncAnimation):
""" 绘制动态图像,可视化参数更新轨迹 """
def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=100, blit=True, **kwargs):
"""
初始化3d可视化类
输入:
xy_values:三维中x,y维度的值
z_values:三维中z维度的值
labels:每个参数更新轨迹的标签
colors:每个轨迹的颜色
interval:帧之间的延迟(以毫秒为单位)
blit:是否优化绘图
"""
self.fig = fig
self.ax = ax
self.xy_values = xy_values
self.z_values = z_values
frames = max(xy_value.shape[0] for xy_value in xy_values)
self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0]
for _, label, color in zip_longest(xy_values, labels, colors)]
self.points = [ax.plot([], [], [], color=color, markeredgewidth=1, markeredgecolor='black', marker='o')[0]
for _, color in zip_longest(xy_values, colors)]
# print(self.lines)
super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames,
interval=interval, blit=blit, **kwargs)
def init_animation(self):
# 数值初始化
for line in self.lines:
line.set_data([], [])
line.set_3d_properties([])
for point in self.points:
point.set_data([], [])
point.set_3d_properties([])
return self.points + self.lines
def animate(self, i):
# 将x,y,z三个数据传入,绘制三维图像
for line, xy_value, z_value, point in zip(self.lines, self.xy_values, self.z_values, self.points):
line.set_data(xy_value[:i, 0], xy_value[:i, 1])
line.set_3d_properties(z_value[:i])
point.set_data(xy_value[i, 0], xy_value[i, 1])
point.set_3d_properties(z_value[i])
return self.points + self.lines
def train_f(model, optimizer, x_init, epoch):
x = x_init
all_x = []
losses = []
for i in range(epoch):
all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4.
loss = model(x)
losses.append(loss)
model.backward()
optimizer.step()
x = model.params['x']
return torch.Tensor(np.array(all_x)), losses
# 构建5个模型,分别配备不同的优化器
model1 = OptimizedFunction3D()
opt_gd = SimpleBatchGD(init_lr=0.95, model=model1)
model2 = OptimizedFunction3D()
opt_adagrad = Adagrad(init_lr=1.5, model=model2, epsilon=1e-7)
model3 = OptimizedFunction3D()
opt_rmsprop = RMSprop(init_lr=0.05, model=model3, beta=0.9, epsilon=1e-7)
model4 = OptimizedFunction3D()
opt_momentum = Momentum(init_lr=0.1, model=model4, rho=0.9)
model5 = OptimizedFunction3D()
opt_adam = Adam(init_lr=0.3, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7)
models = [model1, model2, model3, model4, model5]
opts = [opt_gd, opt_adagrad, opt_rmsprop, opt_momentum, opt_adam]
x_all_opts = []
z_all_opts = []
# 使用不同优化器训练
for model, opt in zip(models, opts):
x_init = torch.FloatTensor([-7, 2])
x_one_opt, z_one_opt = train_f(model, opt, x_init, 100) # epoch
# 保存参数值
x_all_opts.append(x_one_opt.numpy())
z_all_opts.append(np.squeeze(z_one_opt))
# 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-10, 10],以0.01为间隔的数值
x1 = np.arange(-10, 10, 0.01)
x2 = np.arange(-5, 5, 0.01)
x1, x2 = np.meshgrid(x1, x2)
init_x = torch.Tensor(np.array([x1, x2]))
model = OptimizedFunction3D()
fig = plt.figure()
ax = plt.axes(projection='3d')
X = init_x[0].numpy()
Y = init_x[1].numpy()
Z = model(init_x).numpy()
surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm)
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_zlabel('f(x1,x2)')
# 添加轨迹图
labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam']
colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000']
for x_opt, z_opt, label, color in zip(x_all_opts, z_all_opts, labels, colors):
ax.plot(x_opt[:, 0], x_opt[:, 1], z_opt, label=label, color=color)
ax.legend(loc='upper right')
# 修改下面这行,将Visualization3D的初始化参数中的fig和ax改为ax.figure和ax
animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=ax.figure, ax=ax)
plt.show()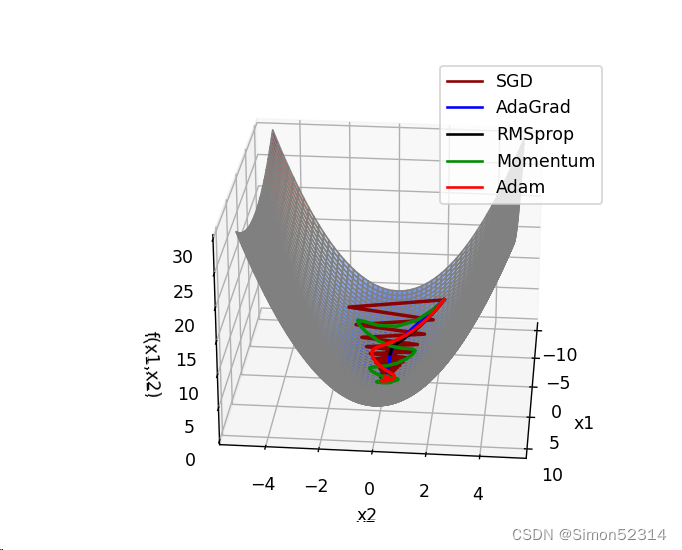 ?
?
用网页做的竟然还带水印 ?不在意水印的推荐
?不在意水印的推荐
?
3.复现CS231经典动画?
import torch import numpy as np import copy from matplotlib import pyplot as plt from matplotlib import animation from itertools import zip_longest from matplotlib import cm class Op(object): def __init__(self): pass def __call__(self, inputs): return self.forward(inputs) # 输入:张量inputs # 输出:张量outputs def forward(self, inputs): # return outputs raise NotImplementedError # 输入:最终输出对outputs的梯度outputs_grads # 输出:最终输出对inputs的梯度inputs_grads def backward(self, outputs_grads): # return inputs_grads raise NotImplementedError class Optimizer(object): # 优化器基类 def __init__(self, init_lr, model): """ 优化器类初始化 """ # 初始化学习率,用于参数更新的计算 self.init_lr = init_lr # 指定优化器需要优化的模型 self.model = model def step(self): """ 定义每次迭代如何更新参数 """ pass class SimpleBatchGD(Optimizer): def __init__(self, init_lr, model): super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model) def step(self): # 参数更新 if isinstance(self.model.params, dict): for key in self.model.params.keys(): self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key] class Adagrad(Optimizer): def __init__(self, init_lr, model, epsilon): """ Adagrad 优化器初始化 输入: - init_lr: 初始学习率 - model:模型,model.params存储模型参数值 - epsilon:保持数值稳定性而设置的非常小的常数 """ super(Adagrad, self).__init__(init_lr=init_lr, model=model) self.G = {} for key in self.model.params.keys(): self.G[key] = 0 self.epsilon = epsilon def adagrad(self, x, gradient_x, G, init_lr): """ adagrad算法更新参数,G为参数梯度平方的累计值。 """ G += gradient_x ** 2 x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x return x, G def step(self): """ 参数更新 """ for key in self.model.params.keys(): self.model.params[key], self.G[key] = self.adagrad(self.model.params[key], self.model.grads[key], self.G[key], self.init_lr) class RMSprop(Optimizer): def __init__(self, init_lr, model, beta, epsilon): """ RMSprop优化器初始化 输入: - init_lr:初始学习率 - model:模型,model.params存储模型参数值 - beta:衰减率 - epsilon:保持数值稳定性而设置的常数 """ super(RMSprop, self).__init__(init_lr=init_lr, model=model) self.G = {} for key in self.model.params.keys(): self.G[key] = 0 self.beta = beta self.epsilon = epsilon def rmsprop(self, x, gradient_x, G, init_lr): """ rmsprop算法更新参数,G为迭代梯度平方的加权移动平均 """ G = self.beta * G + (1 - self.beta) * gradient_x ** 2 x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x return x, G def step(self): """参数更新""" for key in self.model.params.keys(): self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key], self.model.grads[key], self.G[key], self.init_lr) class Momentum(Optimizer): def __init__(self, init_lr, model, rho): """ Momentum优化器初始化 输入: - init_lr:初始学习率 - model:模型,model.params存储模型参数值 - rho:动量因子 """ super(Momentum, self).__init__(init_lr=init_lr, model=model) self.delta_x = {} for key in self.model.params.keys(): self.delta_x[key] = 0 self.rho = rho def momentum(self, x, gradient_x, delta_x, init_lr): """ momentum算法更新参数,delta_x为梯度的加权移动平均 """ delta_x = self.rho * delta_x - init_lr * gradient_x x += delta_x return x, delta_x def step(self): """参数更新""" for key in self.model.params.keys(): self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key], self.model.grads[key], self.delta_x[key], self.init_lr) class Adam(Optimizer): def __init__(self, init_lr, model, beta1, beta2, epsilon): """ Adam优化器初始化 输入: - init_lr:初始学习率 - model:模型,model.params存储模型参数值 - beta1, beta2:移动平均的衰减率 - epsilon:保持数值稳定性而设置的常数 """ super(Adam, self).__init__(init_lr=init_lr, model=model) self.beta1 = beta1 self.beta2 = beta2 self.epsilon = epsilon self.M, self.G = {}, {} for key in self.model.params.keys(): self.M[key] = 0 self.G[key] = 0 self.t = 1 def adam(self, x, gradient_x, G, M, t, init_lr): """ adam算法更新参数 输入: - x:参数 - G:梯度平方的加权移动平均 - M:梯度的加权移动平均 - t:迭代次数 - init_lr:初始学习率 """ M = self.beta1 * M + (1 - self.beta1) * gradient_x G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2 M_hat = M / (1 - self.beta1 ** t) G_hat = G / (1 - self.beta2 ** t) t += 1 x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat return x, G, M, t def step(self): """参数更新""" for key in self.model.params.keys(): self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key], self.model.grads[key], self.G[key], self.M[key], self.t, self.init_lr) class OptimizedFunction3D(Op): def __init__(self): super(OptimizedFunction3D, self).__init__() self.params = {'x': 0} self.grads = {'x': 0} def forward(self, x): self.params['x'] = x return - x[0] * x[0] / 2 + x[1] * x[1] / 1 # x[0] ** 2 + x[1] ** 2 + x[1] ** 3 + x[0] * x[1] def backward(self): x = self.params['x'] gradient1 = - 2 * x[0] / 2 gradient2 = 2 * x[1] / 1 grad1 = torch.Tensor([gradient1]) grad2 = torch.Tensor([gradient2]) self.grads['x'] = torch.cat([grad1, grad2]) class Visualization3D(animation.FuncAnimation): """ 绘制动态图像,可视化参数更新轨迹 """ def __init__(self, *xy_values, z_values, labels=[], colors=[], fig, ax, interval=100, blit=True, **kwargs): """ 初始化3d可视化类 输入: xy_values:三维中x,y维度的值 z_values:三维中z维度的值 labels:每个参数更新轨迹的标签 colors:每个轨迹的颜色 interval:帧之间的延迟(以毫秒为单位) blit:是否优化绘图 """ self.fig = fig self.ax = ax self.xy_values = xy_values self.z_values = z_values frames = max(xy_value.shape[0] for xy_value in xy_values) # , marker = 'o' self.lines = [ax.plot([], [], [], label=label, color=color, lw=2)[0] for _, label, color in zip_longest(xy_values, labels, colors)] print(self.lines) super(Visualization3D, self).__init__(fig, self.animate, init_func=self.init_animation, frames=frames, interval=interval, blit=blit, **kwargs) def init_animation(self): # 数值初始化 for line in self.lines: line.set_data([], []) # line.set_3d_properties(np.asarray([])) # 源程序中有这一行,加上会报错。 Edit by David 2022.12.4 return self.lines def animate(self, i): # 将x,y,z三个数据传入,绘制三维图像 for line, xy_value, z_value in zip(self.lines, self.xy_values, self.z_values): line.set_data(xy_value[:i, 0], xy_value[:i, 1]) line.set_3d_properties(z_value[:i]) return self.lines def train_f(model, optimizer, x_init, epoch): x = x_init all_x = [] losses = [] for i in range(epoch): all_x.append(copy.deepcopy(x.numpy())) # 浅拷贝 改为 深拷贝, 否则List的原值会被改变。 Edit by David 2022.12.4. loss = model(x) losses.append(loss) model.backward() optimizer.step() x = model.params['x'] return torch.Tensor(np.array(all_x)), losses # 构建5个模型,分别配备不同的优化器 model1 = OptimizedFunction3D() opt_gd = SimpleBatchGD(init_lr=0.05, model=model1) model2 = OptimizedFunction3D() opt_adagrad = Adagrad(init_lr=0.05, model=model2, epsilon=1e-7) model3 = OptimizedFunction3D() opt_rmsprop = RMSprop(init_lr=0.05, model=model3, beta=0.9, epsilon=1e-7) model4 = OptimizedFunction3D() opt_momentum = Momentum(init_lr=0.05, model=model4, rho=0.9) model5 = OptimizedFunction3D() opt_adam = Adam(init_lr=0.05, model=model5, beta1=0.9, beta2=0.99, epsilon=1e-7) models = [model5, model2, model3, model4, model1] opts = [opt_adam, opt_adagrad, opt_rmsprop, opt_momentum, opt_gd] x_all_opts = [] z_all_opts = [] # 使用不同优化器训练 for model, opt in zip(models, opts): x_init = torch.FloatTensor([0.00001, 0.5]) x_one_opt, z_one_opt = train_f(model, opt, x_init, 100) # epoch # 保存参数值 x_all_opts.append(x_one_opt.numpy()) z_all_opts.append(np.squeeze(z_one_opt)) # 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-3, 3],以0.1为间隔的数值 x1 = np.arange(-1, 2, 0.01) x2 = np.arange(-1, 1, 0.05) x1, x2 = np.meshgrid(x1, x2) init_x = torch.Tensor(np.array([x1, x2])) model = OptimizedFunction3D() # 绘制 f_3d函数 的 三维图像 fig = plt.figure() ax = plt.axes(projection='3d') X = init_x[0].numpy() Y = init_x[1].numpy() Z = model(init_x).numpy() # 改为 model(init_x).numpy() David 2022.12.4 surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm) # fig.colorbar(surf, shrink=0.5, aspect=1) ax.set_zlim(-3, 2) ax.set_xlabel('x1') ax.set_ylabel('x2') ax.set_zlabel('f(x1,x2)') labels = ['Adam', 'AdaGrad', 'RMSprop', 'Momentum', 'SGD'] colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000'] animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=fig, ax=ax) ax.legend(loc='upper right') plt.show() # animator.save('animation.gif') # 效果不好,估计被挡住了…… 有待进一步提高 Edit by David 2022.12.4
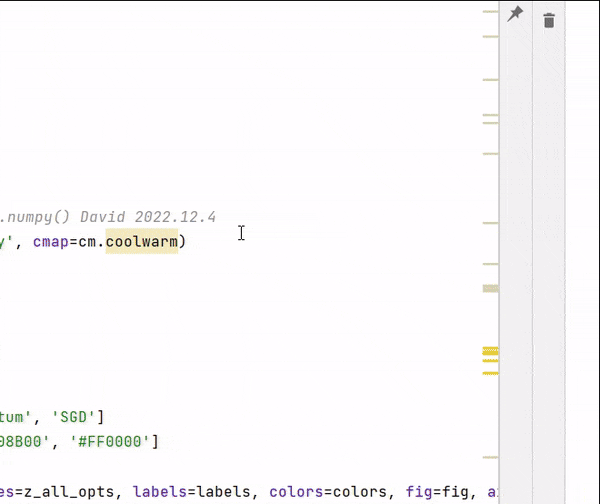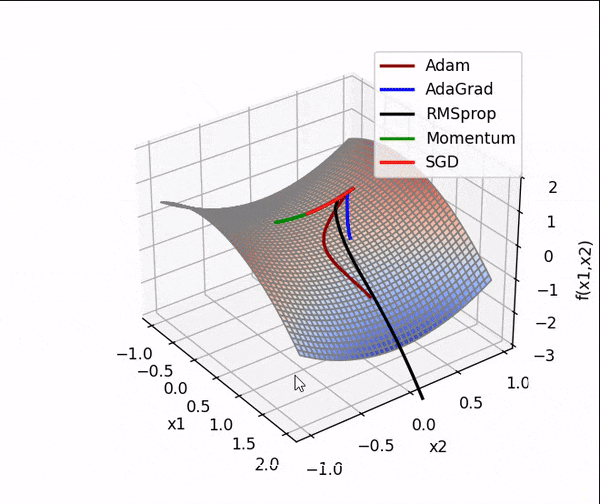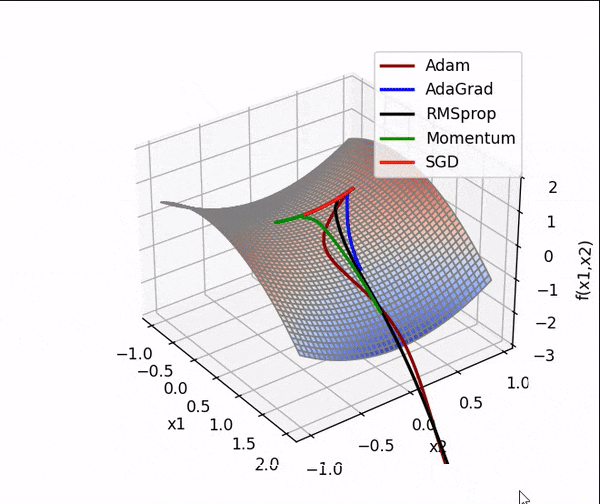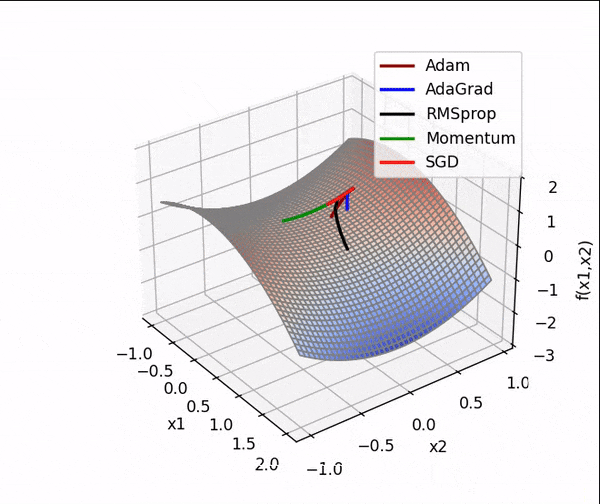
4.?结合3D动画,用自己的语言,从轨迹、速度等多个角度讲解各个算法优缺点?
1、SGD
? ?SGD从图像上来看,呈现“之”字形,路径不够平滑,而且在刚才那个图中,就陷入了局部最小值,而且还出不来。
优点:1、对于大的数据集来说,速度比较快,因为每次就算一个数据的梯度就可以了。
? ? ? ? ? ?2、计算复杂度也低,因为就算一个数据的梯度
缺点:1、震荡的很,呈现“之”字型
? ? ? ? ? ?2、容易陷入局部极小值
? ? ? ? ? ?3、容易受噪声的影响,如果碰巧选择噪声点来进行更新,那就偏了。
? ? ? ? ? ?4、需要调节成合适的学习率
2、AdaGrad
? ? ? ?从上面看出 蓝色线(AdaGrad)一开始更新的很快,然后后面逐渐变慢,但是也能看出来最平滑了? ? ? ? ? ??
优点:? ? 1、Adagrad的速度受益于自适应学习率的特性,可以根据每个参数的历史梯度动态调整学习率,更有效地更新参数。
? ? ? ? ? ? ? ?2、对于具有梯度稀疏性的问题,Adagrad可能更为有效,因为它可以根据每个参数历史梯度的信息来调整学习率。(根据公式就可以知道)
?缺点:? ? 1、随着时间推移,Adagrad累积的历史梯度平方可能导致学习率逐渐减小,可能导致训练后期学习率过小,使得模型参数更新幅度过小,难以收敛。
? ? ? ? ? ? ? ? 2、衰减的过快,可能会早停
3、RMSprop
从轨迹上看? 整体上虽然没有AdaGrad平滑,但是依然比其他的要平滑,并且整体上速度很块,由于学习率的自适应性,RMSprop的路径可能在优化过程中逐渐收敛,呈现出更为平稳的特点。?
优点:? ? ?1、RMSprop同样有自适应学习率,它通过梯度平方的移动平均来调整学习率,能够在不同参数之间适应性地选择学习率。
? ? ? ? ? ? ? ? 2、因为有自适应学习率,所以路径平滑,此外,历史梯度逐渐削弱,速度会块,解决了早停的问题。
缺点:? ? ?1、类似于Adagrad,RMSprop可能随着时间推移导致学习率逐渐减小,这可能使得在训练后期模型参数更新幅度过小,难以收敛。
4、Momentum
从路径上来看,速度很快,但是会找错路,并且,它是这几个算法里对一个方向的更新时间最持续的并且很直
优点:? ? ?1、Momentum算法通过积累动量,能够更快地加速收敛,尤其是在具有平坦或弯曲路径的情况下,相对于SGD具有更好的表现。
? ? ? ? ? ? ? ? 2、引入动量有助于平滑更新路径,减轻震荡,使得模型更为稳定。(不走错路还挺平滑的,走错了会有“之”)
缺点:? ? ?1、非凸优化问题中,动量算法可能使得路径过于迅速地越过全局最优点,导致无法稳定地收敛。
?5、Nesterov
? 从路径上看,也会走错,但是是最先纠正路径的,速度最快,改路最快可能是Nesterov先用当前的速度v更新一遍参数,在用更新的临时参数计算梯度。
优点:? ?1、有前瞻性(改路最快)能够更快速地收敛,特别是在梯度较为复杂的情况下,相对于标准Momentum表现更好。
? ? ? ? ? ? ? 2、路径平滑,对于训练更稳定。
? ? ? ? ? ? ? 3、块
缺点:
? ? ? ? ? ?调参复杂,参数多
6、Adam
从路径来看? 不像动量法那样会走错,既没走错,也不慢,中间的样子,还是比较平滑的。
优点: 1、其自适应学习率机制,能够根据每个参数的历史梯度信息动态调整学习率,适应不同参数的特点。
? ? ? ? ? ?2、方向性比较好,速度也不慢
缺点: 1、Adam算法需要维护每个参数的一阶矩和二阶矩的历史信息,导致内存需求较高,尤其是在参数较多的情况下。




总结:
1、第一个实验,就出师未捷身先死,用的同学的代码复现打算,结果一直只有第一张图,第二张图片出不来,左一那样,我看了看代码,感觉没啥毛病,于是,我按照我自己的想法开始改,结果两张图出是出来了,就是出现在一张图上,而且第二个函数的图还有点怪怪的,我瞅着代码上看没啥毛病,我猜测是因为度量衡的问题,于是,我又把两张图分开看,就长最下面那样,嘿,成了!
 ?
?
 ?
?
原因就是,我一开始就用来一个画布,后面加了一个画布就好了
 ?
?
2、第二个代码一开始出现的图像,我不能动,而且没有轨迹,最狗的就是一会儿就自己关了,我修改了一部分,终于和小伙伴们一样拥有了自己的动图,太不容易了,看其他同学貌似也有同样问题奉上我的修改过程:
class Visualization3D(animation.FuncAnimation): # ... (不变) def init_animation(self): # 数值初始化 for line in self.lines: line.set_data([], []) line.set_3d_properties([]) for point in self.points: point.set_data([], []) point.set_3d_properties([]) return self.points + self.lines def animate(self, i): # 将x,y,z三个数据传入,绘制三维图像 for line, xy_value, z_value, point in zip(self.lines, self.xy_values, self.z_values, self.points): line.set_data(xy_value[:i, 0], xy_value[:i, 1]) line.set_3d_properties(z_value[:i]) point.set_data(xy_value[i, 0], xy_value[i, 1]) point.set_3d_properties(z_value[i]) return self.points + self.lines # (后面的代码不变) # 构建5个模型,分别配备不同的优化器 # ... (不变) # 使用不同优化器训练 # ... (不变) # 使用numpy.meshgrid生成x1,x2矩阵,矩阵的每一行为[-10, 10],以0.01为间隔的数值 # ... (不变) # 绘制 f_3d函数 的 三维图像 fig = plt.figure() ax = plt.axes(projection='3d') X = init_x[0].numpy() Y = init_x[1].numpy() Z = model(init_x).numpy() surf = ax.plot_surface(X, Y, Z, edgecolor='grey', cmap=cm.coolwarm) ax.set_xlabel('x1') ax.set_ylabel('x2') ax.set_zlabel('f(x1,x2)') # 添加轨迹图 labels = ['SGD', 'AdaGrad', 'RMSprop', 'Momentum', 'Adam'] colors = ['#8B0000', '#0000FF', '#000000', '#008B00', '#FF0000'] for x_opt, z_opt, label, color in zip(x_all_opts, z_all_opts, labels, colors): ax.plot(x_opt[:, 0], x_opt[:, 1], z_opt, label=label, color=color) ax.legend(loc='upper right') # 修改下面这行,将Visualization3D的初始化参数中的fig和ax改为ax.figure和ax animator = Visualization3D(*x_all_opts, z_values=z_all_opts, labels=labels, colors=colors, fig=ax.figure, ax=ax) plt.show()?我是这样修改的,原因如下:
? ? 在原始的代码中,
Visualization3D类的init_animation和animate方法的实现存在一些问题,这有可能导致轨迹图无法正确显示。原始实现中使用了set_data_3d方法,但是这个方法可能没有正确地设置Z轴的值,导致轨迹图在三维空间中无法正确显示。
? Visualization3D类的初始化参数中有fig和ax,而在动画的过程中,我注意到ax在这个类中被用作动画的轴。在原始代码中,fig和ax的值分别传递给了Visualization3D类,但是在动画的过程中,ax的figure属性才是正确的Figure对象。? 所以,我对
Visualization3D的初始化参数进行了修改,将fig和ax改为ax.figure和ax,以确保Visualization3D正确连接到已有的ax上。此外,我还更新了init_animation和animate方法。在init_animation方法中,我修改了对line.set_data_3d和point.set_data_3d的调用,将其分别改为line.set_data和point.set_data,同时添加了set_3d_properties来设置Z轴的值。在animate方法中,也做了类似的修改,以确保在动画过程中正确更新轨迹图的数据。
参考链接:
NNDL实验 优化算法3D轨迹 复现cs231经典动画_深度学习 优化算法 动画展示-CSDN博客
【23-24 秋学期】NNDL 作业13 优化算法3D可视化-CSDN博客
3、又是美好的一天过去了,学了不少知识,希望睡一觉不会忘记!!
NNDL结束了,完结!撒花!!
 ?
?
给老师一个,真是辛苦了,看了我写了一学期的学术垃圾

?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!