NNDL 作业12-优化算法2D可视化 [HBU]
老师作业原博客地址:【23-24 秋学期】NNDL 作业12 优化算法2D可视化-CSDN博客
目录
深度学习中的优化算法总结 - ZingpLiu - 博客园 (cnblogs.com)
简要介绍图中的优化算法,编程实现并2D可视化
1. 被优化函数?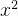
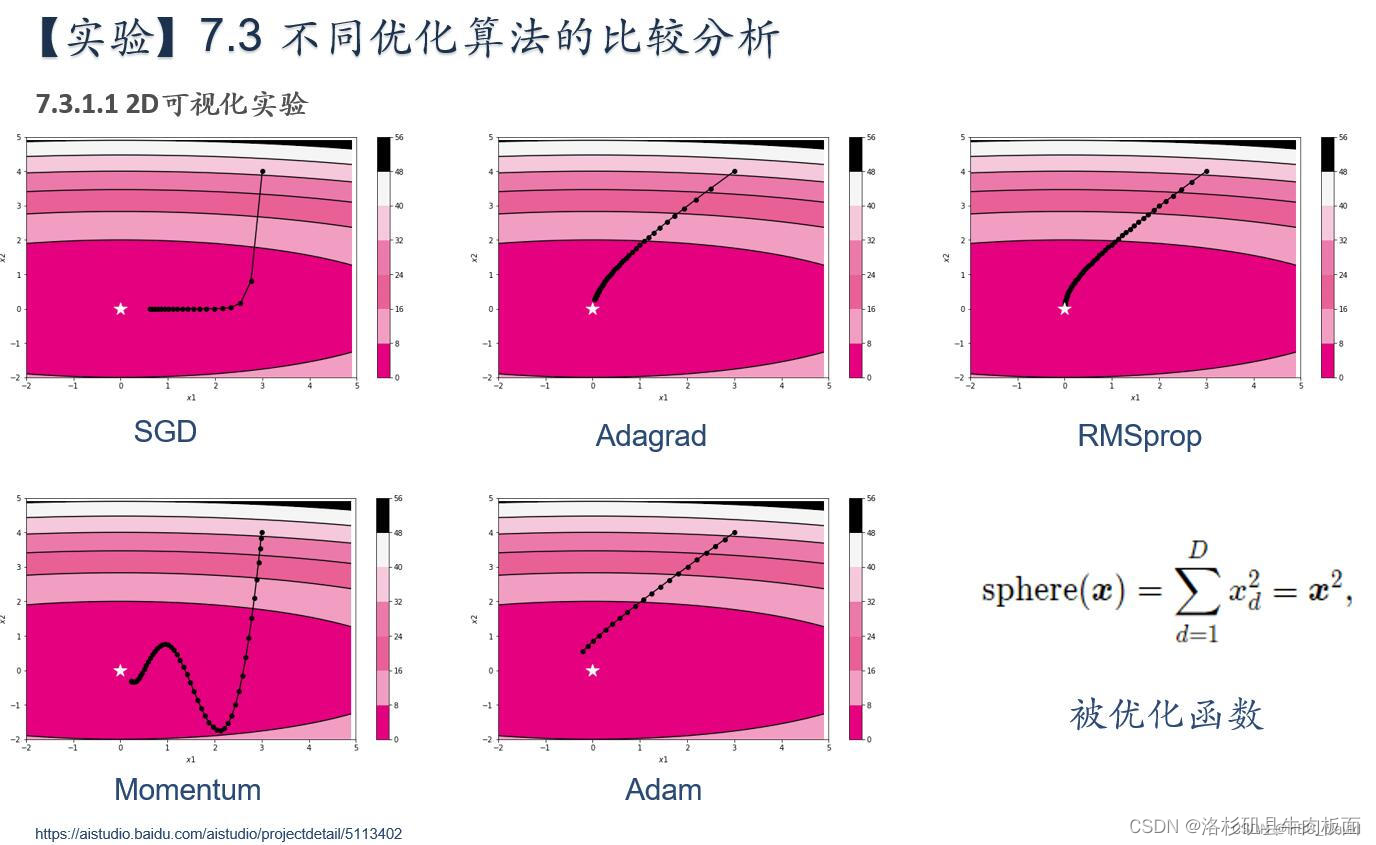
首先可视化一下此函数,这是一段非常简单的程序:
import matplotlib.pyplot as plt
import numpy as np
def fun(x):
return x ** 2
#创建一个x值的数组
x = np.linspace(-10,10,100)
plt.figure('x ** 2')
plt.title('y = x ** 2')
plt.xlabel('x')
plt.ylabel('y')
plt.plot(x,fun(x),color='r')
#plt.grid(True) #添加网格线
plt.show()结果:
现在介绍图示的优化算法:
深度学习中的优化算法总结 - ZingpLiu - 博客园 (cnblogs.com)
B站视频(这个比较简洁,适合小白 新手 ):纯python实现机器学习深度学习优化算法,随机梯度下降,动量法,SGD,Momentum,Ada Grad,Rms Prop,Ada Delta,Adam_哔哩哔哩_bilibili
SGD:
简单的梯度下降算法,用于优化机器学习模型的参数。它通过计算整个训练数据集的梯度来更新模型参数,而不是每次只考虑一个样本。
梯度更新公式:
from nndl.op import Op
import torch
import numpy as np
from matplotlib import pyplot as plt
from nndl.opitimizer import SimpleBatchGD
# 被优化函数
class OptimizedFunction(Op):
def __init__(self, w):
super(OptimizedFunction, self).__init__()
self.w = w
self.params = {'x': 0}
self.grads = {'x': 0}
def forward(self, x):
self.params['x'] = x
return torch.matmul(self.w.T, torch.tensor(torch.square(self.params['x']), dtype=torch.float32))
def backward(self):
self.grads['x'] = 2 * torch.multiply(self.w.T, self.params['x'])
# SGD梯度更新
import copy
def train_f(model, optimizer, x_init, epoch):
x = x_init
all_x = []
losses = []
for i in range(epoch):
all_x.append(copy.copy(x.numpy()))
loss = model(x)
losses.append(loss)
model.backward()
optimizer.step()
x = model.params['x']
print(all_x)
return torch.tensor(all_x), losses
# 可视化
class Visualization(object):
def __init__(self):
"""
初始化可视化类
"""
# 只画出参数x1和x2在区间[-5, 5]的曲线部分
x1 = np.arange(-5, 5, 0.1)
x2 = np.arange(-5, 5, 0.1)
x1, x2 = np.meshgrid(x1, x2)
self.init_x = torch.tensor([x1, x2])
def plot_2d(self, model, x, fig_name):
"""
可视化参数更新轨迹
"""
fig, ax = plt.subplots(figsize=(10, 6))
cp = ax.contourf(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)),
colors=['#e4007f', '#f19ec2', '#e86096', '#eb7aaa', '#f6c8dc', '#f5f5f5', '#000000'])
c = ax.contour(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)), colors='black')
cbar = fig.colorbar(cp)
ax.plot(x[:, 0], x[:, 1], '-o', color='#000000')
ax.plot(0, 'r*', markersize=18, color='#fefefe')
ax.set_xlabel('$x1$')
ax.set_ylabel('$x2$')
ax.set_xlim((-2, 5))
ax.set_ylim((-2, 5))
plt.savefig(fig_name)
plt.show()
def train_and_plot_f(model, optimizer, epoch, fig_name):
"""
训练模型并可视化参数更新轨迹
"""
# 设置x的初始值
x_init = torch.tensor([3, 4], dtype=torch.float32)
print('x1 initiate: {}, x2 initiate: {}'.format(x_init[0].numpy(), x_init[1].numpy()))
x, losses = train_f(model, optimizer, x_init, epoch)
print(x)
losses = np.array(losses)
# 展示x1、x2的更新轨迹
vis = Visualization()
vis.plot_2d(model, x, fig_name)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = SimpleBatchGD(init_lr=0.2, model=model)
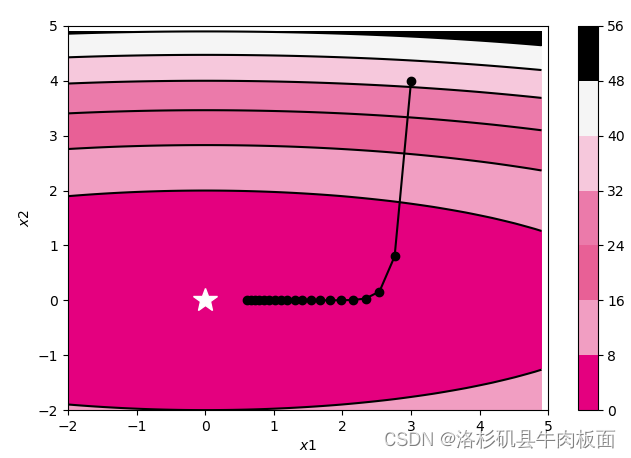
train_and_plot_f(model, opt, epoch=20, fig_name='opti-vis-para.pdf')运行结果:
Adagrad:
借鉴正则化的思想,每次迭代时自适应地调整每个参数的学习率。?
参数更新差值为:
为每个参数梯度平方的累计值,当之前梯度较大时,
?增大,梯度的变化幅度就会减小;当之前梯度较小时,
?增大幅度减小,梯度的变化幅度就会增大,以此来达到自适应的效果。
class Adagrad(nndl.Optimizer):
def __init__(self, init_lr, model, epsilon):
"""
Adagrad 优化器初始化
输入:
- init_lr: 初始学习率
- model:模型,model.params存储模型参数值
- epsilon:保持数值稳定性而设置的非常小的常数
"""
super(Adagrad, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.epsilon = epsilon
def adagrad(self, x, gradient_x, G, init_lr):
"""
adagrad算法更新参数,G为参数梯度平方的累计值。
"""
G += gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""
参数更新
"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.adagrad(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Adagrad(init_lr=0.5, model=model, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para2.pdf')
plt.show()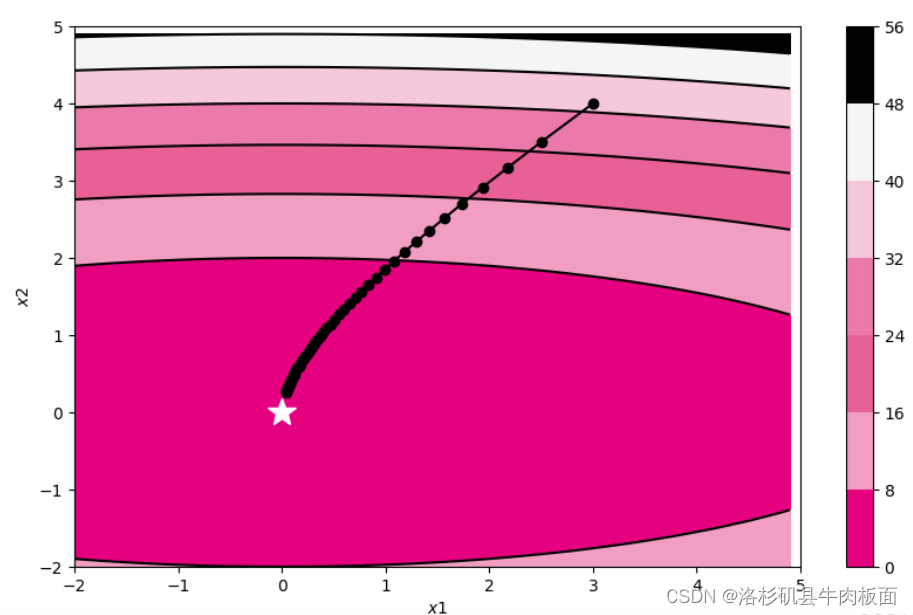
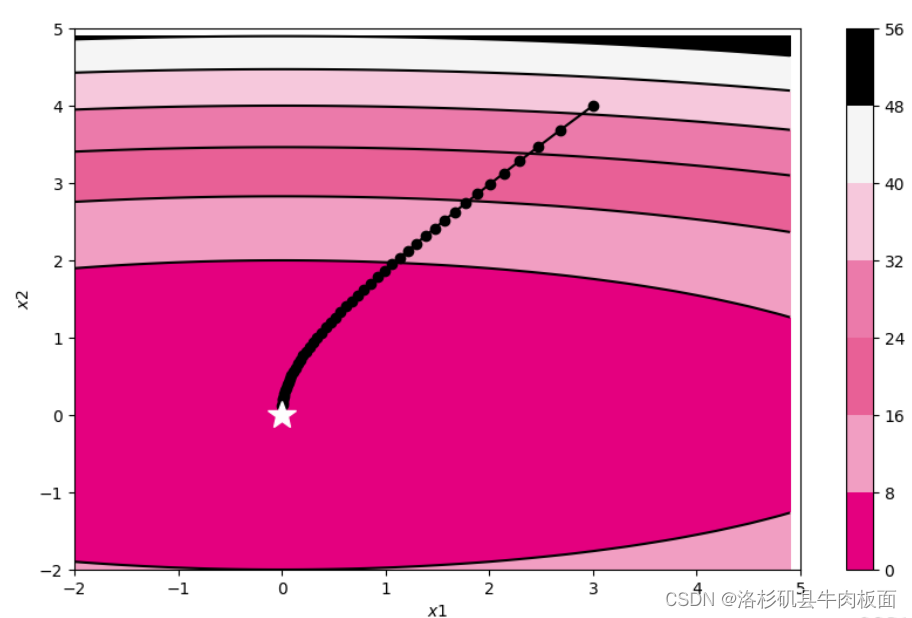
RMSprop:
?RMSprop:是对梯度的平方进行指数加权移动平均,并将其作为调整学习率的依据,使用一个衰减系数来控制历史梯度平方的衰减速度,的计算由累积方式变成了指数衰减移动平均。从而避免了AdaGrad中学习率过早衰减的问题。
参数更新差值如下:
class RMSprop(Optimizer):
def __init__(self, init_lr, model, beta, epsilon):
"""
RMSprop优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta:衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(RMSprop, self).__init__(init_lr=init_lr, model=model)
self.G = {}
for key in self.model.params.keys():
self.G[key] = 0
self.beta = beta
self.epsilon = epsilon
def rmsprop(self, x, gradient_x, G, init_lr):
"""
rmsprop算法更新参数,G为迭代梯度平方的加权移动平均
"""
G = self.beta * G + (1 - self.beta) * gradient_x ** 2
x -= init_lr / torch.sqrt(G + self.epsilon) * gradient_x
return x, G
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key] = self.rmsprop(self.model.params[key],
self.model.grads[key],
self.G[key],
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = RMSprop(init_lr=0.1, model=model, beta=0.9, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para3.pdf')结果:
Momentum:
动量法:该算法为梯度估计修正算法,用之前积累的动量替代真正的梯度,每次迭代的梯度可以看作加速度。当某个参数在最近一段时间内梯度方向不一致时,其参数更新幅度变小,起到减速的作用;相反,当在最近一段时间内梯度方向一致时,其参数更新幅度变大,起到加速作用。
在第𝑡 次迭代时,计算负梯度的“加权移动平均”作为参数的更新方向。
class Momentum(Optimizer):
def __init__(self, init_lr, model, rho):
"""
Momentum优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- rho:动量因子
"""
super(Momentum, self).__init__(init_lr=init_lr, model=model)
self.delta_x = {}
for key in self.model.params.keys():
self.delta_x[key] = 0
self.rho = rho
def momentum(self, x, gradient_x, delta_x, init_lr):
"""
momentum算法更新参数,delta_x为梯度的加权移动平均
"""
delta_x = self.rho * delta_x - init_lr * gradient_x
x += delta_x
return x, delta_x
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.delta_x[key] = self.momentum(self.model.params[key],
self.model.grads[key],
self.delta_x[key],
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Momentum(init_lr=0.01, model=model, rho=0.9)
train_and_plot_f(model, opt, epoch=50, fig_name='opti-vis-para4.pdf')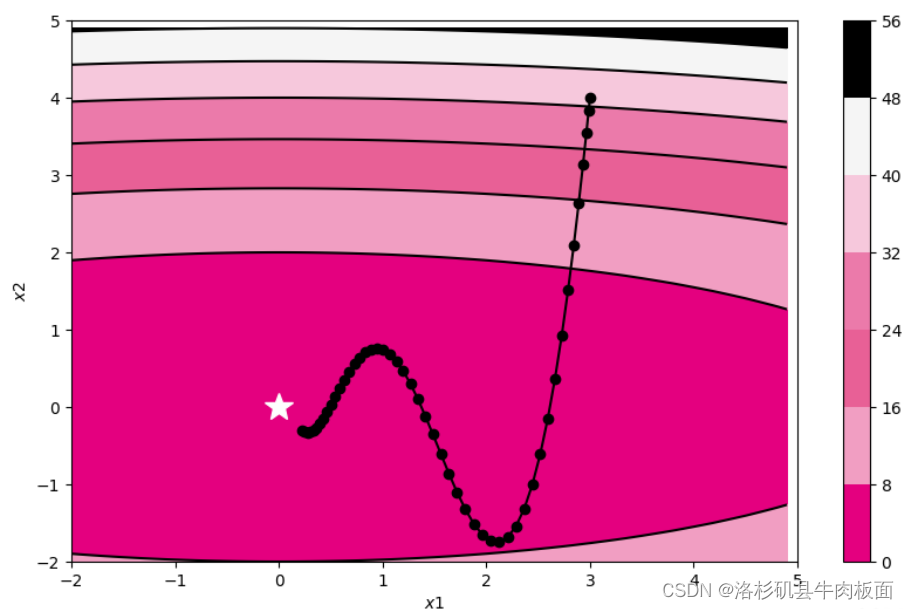
Adam:
Adam方法结合了上述的动量(Momentum)和自适应(Adaptive),同时对梯度和学习率进行动态调整。如果说动量相当于给优化过程增加了惯性,那么自适应过程就像是给优化过程加入了阻力。速度越快,阻力也会越大。
Adam首先计算了梯度的一阶矩估计和二阶矩估计,分别代表了原来的动量和自适应部分
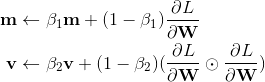
β_1 与 β_2 是两个特有的超参数,一般设为0.9和0.999
但是,Adam还需要对计算出的矩估计进行修正

简单来说就是由于m和v的初始指为0,所以第一轮的时候会非常偏向第二项,那么在后面计算更新值得时候根据β_1 与 β_2的初始值来看就会非常的大,需要将其修正回来。而且由于β_1 与 β_2很接近于1,所以如果不修正,对于最初的几轮迭代会有很严重的影响。
最后就是更新参数值,和AdaGrad几乎一样,只不过是用上了上面计算过的修正的矩估计:
![]()
代码:
class Adam(Optimizer):
def __init__(self, init_lr, model, beta1, beta2, epsilon):
"""
Adam优化器初始化
输入:
- init_lr:初始学习率
- model:模型,model.params存储模型参数值
- beta1, beta2:移动平均的衰减率
- epsilon:保持数值稳定性而设置的常数
"""
super(Adam, self).__init__(init_lr=init_lr, model=model)
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.M, self.G = {}, {}
for key in self.model.params.keys():
self.M[key] = 0
self.G[key] = 0
self.t = 1
def adam(self, x, gradient_x, G, M, t, init_lr):
"""
adam算法更新参数
输入:
- x:参数
- G:梯度平方的加权移动平均
- M:梯度的加权移动平均
- t:迭代次数
- init_lr:初始学习率
"""
M = self.beta1 * M + (1 - self.beta1) * gradient_x
G = self.beta2 * G + (1 - self.beta2) * gradient_x ** 2
M_hat = M / (1 - self.beta1 ** t)
G_hat = G / (1 - self.beta2 ** t)
t += 1
x -= init_lr / torch.sqrt(G_hat + self.epsilon) * M_hat
return x, G, M, t
def step(self):
"""参数更新"""
for key in self.model.params.keys():
self.model.params[key], self.G[key], self.M[key], self.t = self.adam(self.model.params[key],
self.model.grads[key],
self.G[key],
self.M[key],
self.t,
self.init_lr)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
model = OptimizedFunction(w)
opt = Adam(init_lr=0.2, model=model, beta1=0.9, beta2=0.99, epsilon=1e-7)
train_and_plot_f(model, opt, epoch=20, fig_name='opti-vis-para5.pdf')结果:
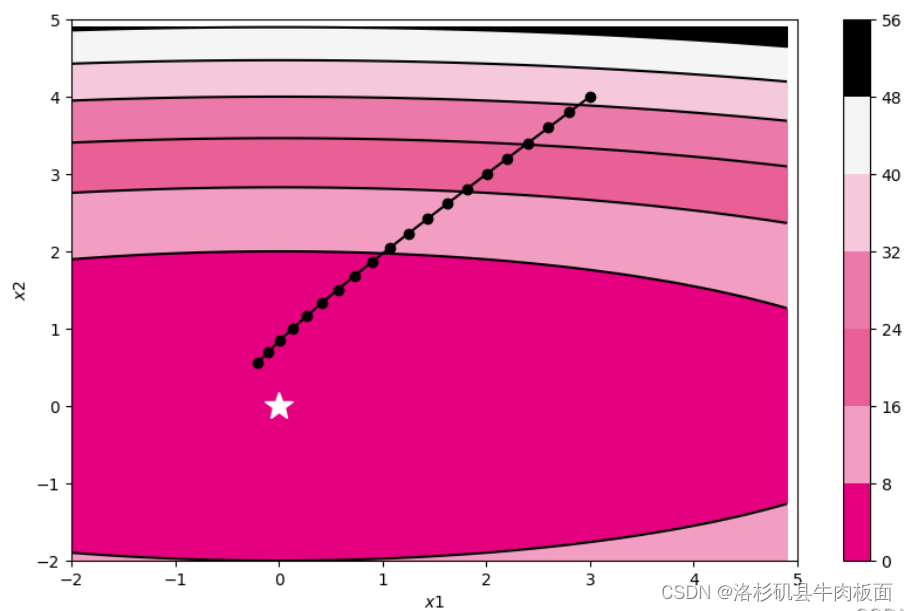
2. 被优化函数? ?
?

首先画出3D图形,来看一下此函数的效果。代码:
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def func(x, y):
return x * x / 20 + y * y
#用于绘制3D图像
def paint_loss_func():
x = np.linspace(-50, 50, 100) # x的绘制范围[-50,50],从区间均匀取100个数
y = np.linspace(-50, 50, 100) # y的绘制范围[-50,50],从区间均匀取100个数
#创建X,Y网格, 计算每个点上的函数值
X, Y = np.meshgrid(x, y)
Z = func(X, Y)
fig = plt.figure() # figsize=(10, 10))
ax = Axes3D(fig) #在此图形窗口中创建一个3D坐标轴
plt.xlabel('x')
plt.ylabel('y')
#使用3D绘图法绘制函数表面,设置步长和颜色'plasma'
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='plasma')
#尝试其他的颜色主题
#ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='cividis')
#ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='rainbow')
plt.show()
paint_loss_func()
3D效果
颜色plasma:
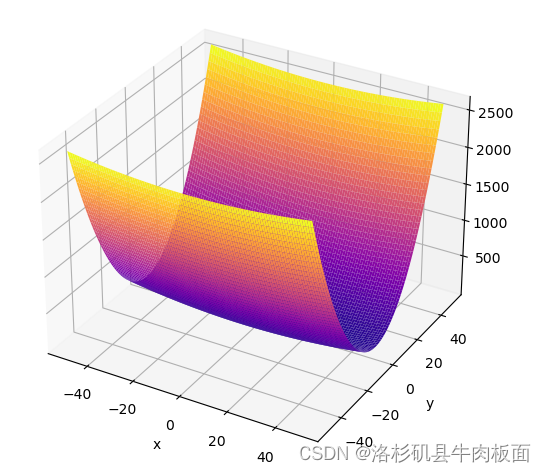
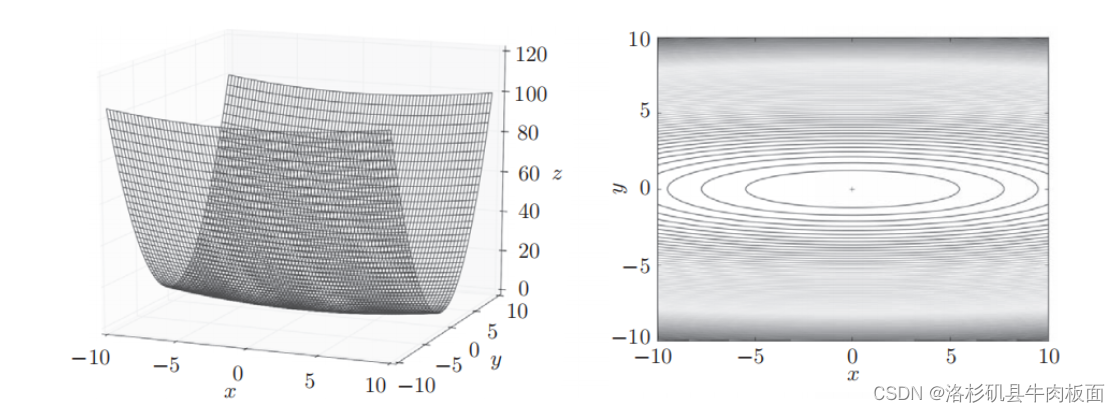
结果显示3D图的特征:有全局最小值、是一个向x轴方向延申的“碗”状函数。
可以多尝试一些3D图形的颜色主题,下面是一些常见的颜色映射:
'viridis': 非常鲜艳的颜色映射,经常用于数据可视化。'plasma': 科幻感'inferno': 有深度和对比度,适合表示负值和正值之间的差异。'magma': 类似于 'inferno',但对比度稍小。'cividis': 自然颜色映射,适用于显示生物数据。'Greys': 灰度颜色映射。'Blues': 基于蓝色的颜色映射。'Greens': 基于绿色的颜色映射。'Oranges': 基于橙色的颜色映射。'Reds': 基于红色的颜色映射。
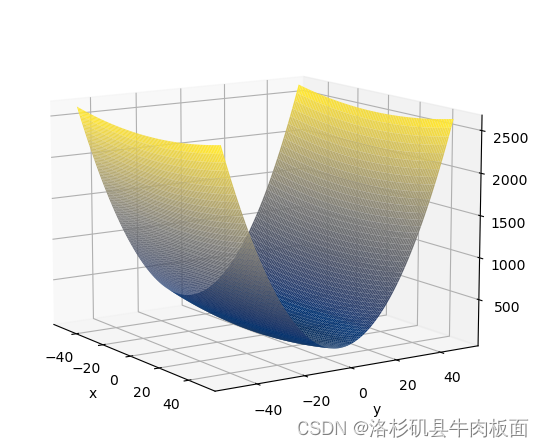
基于viridis(左)和cividis(右)的映射效果:
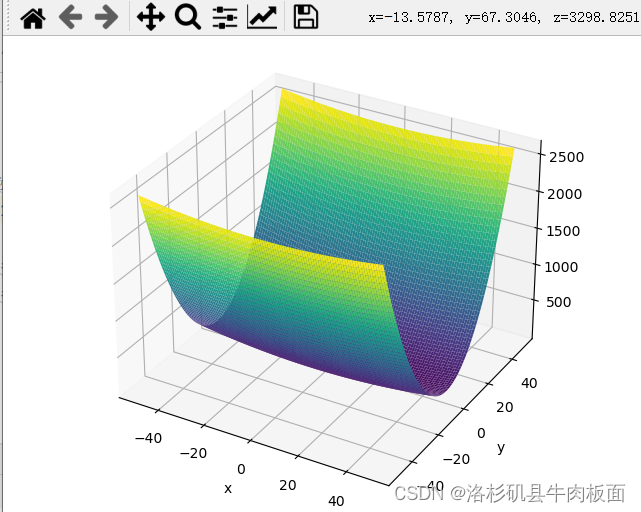
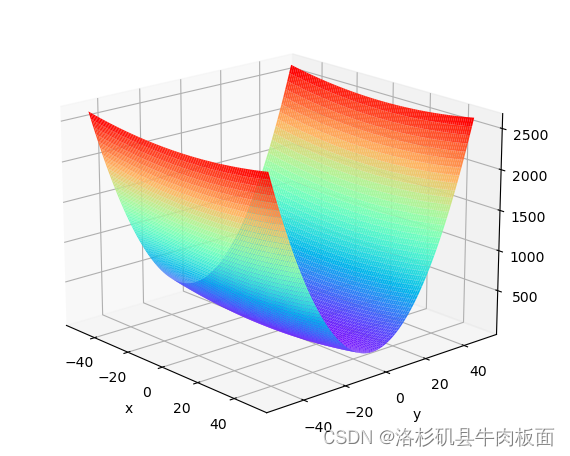
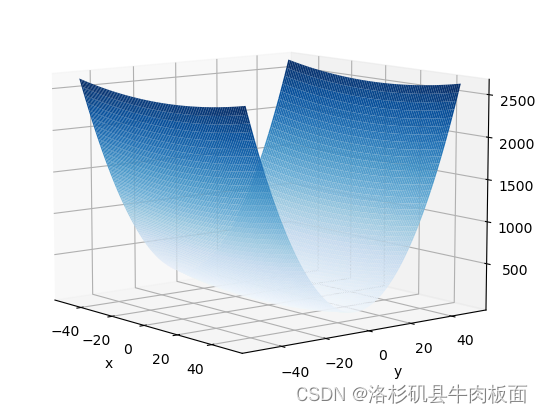
我个人觉得最好看的是rainbow(左)映射效果;右边是Blues映射效果,太单调了:
鱼书中给出的图。右边是等高线图,等高线呈向x轴方向延伸的椭圆状?:
再来实现一下使用不同优化器形成的轨迹:
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def f(x, y):
return x ** 2 / 20.0 + y ** 2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
learningrate = [0.9, 0.3, 0.3, 0.6, 0.6, 0.6, 0.6]
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=learningrate[0])
optimizers["Momentum"] = Momentum(lr=learningrate[1])
optimizers["Nesterov"] = Nesterov(lr=learningrate[2])
optimizers["AdaGrad"] = AdaGrad(lr=learningrate[3])
optimizers["RMSprop"] = RMSprop(lr=learningrate[4])
optimizers["Adam"] = Adam(lr=learningrate[5])
idx = 1
id_lr = 0
for key in optimizers:
optimizer = optimizers[key]
lr = learningrate[id_lr]
id_lr = id_lr + 1
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 3, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="#9932CC")
# plt.contour(X, Y, Z) # 绘制等高线
plt.contour(X, Y, Z, cmap='gray') # 颜色填充
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
# plt.axis('off')
# plt.title(key+'\nlr='+str(lr), fontstyle='italic')
plt.text(0, 10, key + '\nlr=' + str(lr), fontsize=20, color="b",
verticalalignment='top', horizontalalignment='center', fontstyle='italic')
plt.xlabel("x")
plt.ylabel("y")
plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
plt.show()结果:
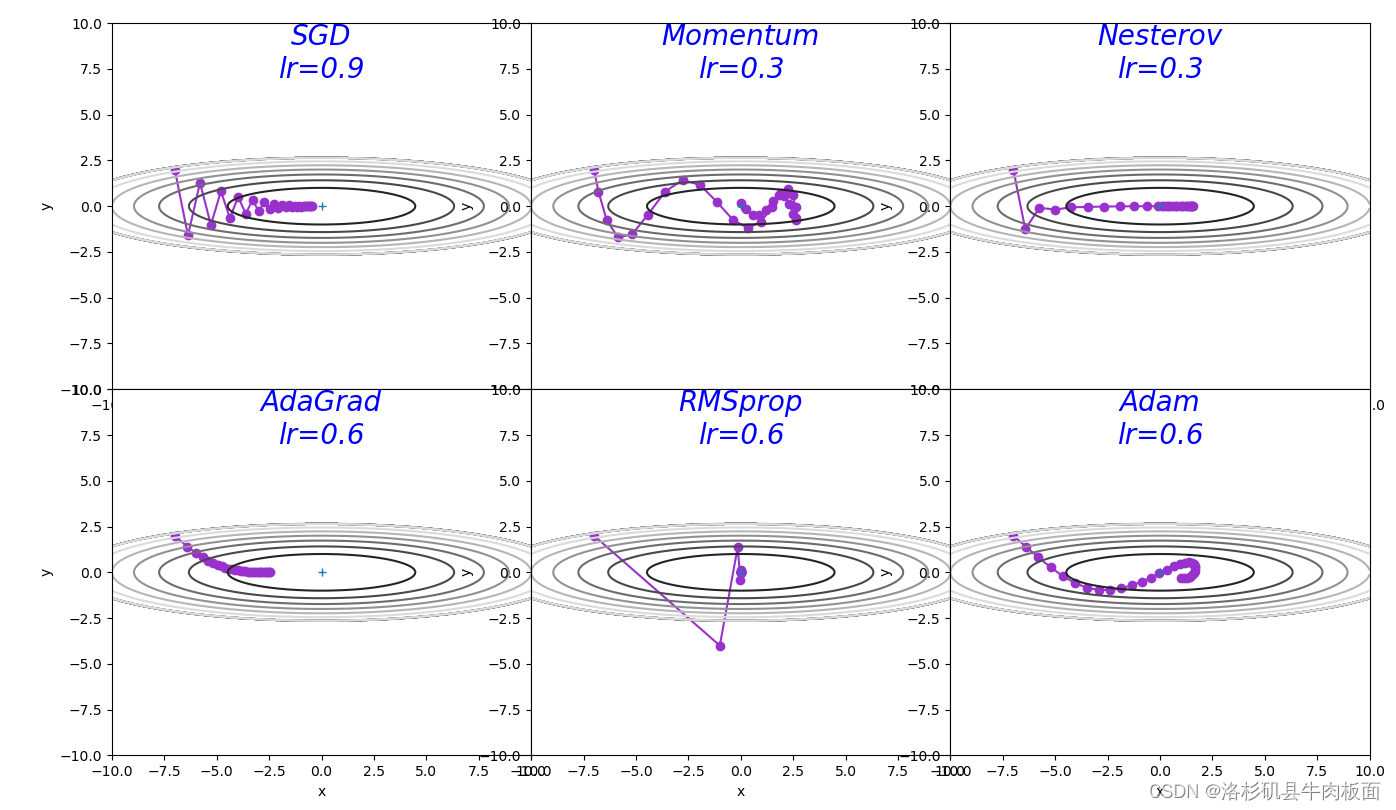
3.?解释不同轨迹的形成原因
分析各个算法的优缺点.:
参考博客:【Adam】优化算法浅析 - 知乎 (zhihu.com)
深度学习中的优化算法(Optimizer)理解与python实现 - 知乎 (zhihu.com)
参考文献:
《Deep Learning》花书
《深度学习入门——基于python的理论与实现》
(1)SGD
轨迹形成原因:SGD收敛轨迹呈“之”字形,是因为y方向变化很大,x方向变化很小,随机收敛只能迂回往复地寻找,效率很低。单纯的朝着梯度方向,使得在函数的形状非均向时,只能反复的寻找。优点:1.计算效率高:每次迭代只需要计算一个样本的梯度,计算量较小,适用于大规模数据集;2.收敛速度快:SGD每次只考虑一个样本,因此更容易跳出局部最优点,从而找到全局最优解。
?缺点:1.更新不稳定:由于SGD只考虑一个样本,因此每次更新都有一定的随机性,导致更新不稳定。2.容易陷入局部最优:虽然SGD容易跳出局部最优,但是由于随机性的影响,也容易陷入局最优点。3.需要调整学习率:SGD的收敛速度很快,但是需要调整学习率,否则可能导致模型无法收敛或收敛速度过慢。
(2)AdaGrad
AdaGrad是一种自适应优化算法。它通过每个参数的历史梯度,动态更新每一个参数的学习率,使得每个参数的更新率都能够逐渐减小。前期梯度加大的,学习率减小得更快,梯度小的,学习率减小得更慢些。
轨迹形成原因:函数的取值高效地向着最小值移动。 由于y轴方向上的梯度较大,因此刚开始变动较大,但是后面会根据前面较大的变动进行调整,减小更新的步伐,导致y轴方向上的更新程度被减弱,“之”字形的变动程度衰减,呈现稳定的向最优点收敛。优点:1.自适应算法:AdaGrad算法根据每个参数的历史梯度信息来自适应地调整学习率,使得梯度不会太大或太小。2.收敛快速:由于学习率的自适应调整,AdaGrad在训练初期可使用较大的学习率,有助于收敛速度的提升。
缺点:1.学习率衰减过快,发生早停现象:随着训练的进行,AdaGrad会累积历史梯度的平方和,导致学习率不断减小。在训练后期,学习率可能会变得非常小,甚至接近于零,导致训练过早停止。2.在非凸问题中,AdaGrad可能会受到累积梯度平方的影响,导致陷入局部最优解。
(3)RMSprop
AdaGrad有个问题,那就是学习率会不断地衰退。这样就会使得很多任务在达到最优解之前学习率就已经过量减小,所以RMSprop采用了使用指数衰减平均来慢慢丢弃先前得梯度历史。这样一来就能够防止学习率过早地减小。
轨迹形成原因:RMSprop算法的轨迹图与AdaGrad相比,RMSprop的轨迹到后期表现出更加平缓和稳定的学习率变化,从而更有效地收敛到损失函数的最小值。但是由于该算法会逐渐遗忘过去的梯度,只被近期的梯度所影响,在最初的时候会收敛的更快,变化幅度大。优点:1.自适应学习率: RMSprop根据梯度的大小调整学习率,可以导致更高效的训练。2.收敛速度快解决了AdaGrad算法的早停问题: 特别是在循环神经网络中,收敛速度较快,并且引入了衰减率,不会一直累积梯度平方,对于过去的梯度,会相应的衰减,解决了AdaGrad的早衰问题。
缺点:?1.超参数增多: 虽然它减少了对全局学习率的微调需求,但引入了需要配置的移动平均衰减的新超参数。2.对于稀疏梯度可能导致学习率爆炸:RMSprop算法使用了梯度的平方的指数加权移动平均来调整学习率,这意味着如果某个参数的梯度一直都很小,那么它的学习率会一直被放大,导致更新过大。尤其是对于稀疏梯度,由于只有少量的梯度值是非零的,梯度的平方的指数加权移动平均可能会导致学习率爆炸,导致权重更新过大,从而使得训练过程不稳定。
(4)Momentum
轨迹形成原因:该算法的收敛路径以一种有所抑制的振荡模式接近最小值。动量法是梯度估计修正算法,引入了动量的概念,当梯度方向不一致时,会起到减速作用,增加稳定性。所以,与SGD的“之”字形相比较,在x轴方向上受到的力小,一直在同向受力,导致加速。 y轴方向上受到的力大,交互正反向的力,会互相抵消。 和SGD相比,可更快朝x轴方向靠近,减弱“之”字形变动程度。
优点:1.更快的收敛速度:特别是对于具有许多不规则表面或在一个维度上非常陡峭而在另一个维度上非常平坦的问题(鞍点等)。并且由于动量项维持了运动,能够更有效地收敛至局部最小值或平坦区域。2.稳定性强:减少垂直于梯度方向的振荡,导致更稳定的更新。
缺点:1.引入了一个额外的超参数(动量系数),需要进行配置,这可能会使调整变得更加复杂。如果动量系数设置得太高,可能导致超过最小值,如果不适当控制甚至可能导致发散。在高度凸问题或需要精确收敛到确切最小值的情况下,可能效果不佳。
(5)Nesterov
轨迹形成原因:该算法是对动量法的改进,不仅仅根据当前梯度调整位置,而是根据当前动量在预期的未来位置计算梯度。所以,算法可以相应地调整更新,避免在使用梯度下降时可能出现的振荡,特别是当表面具有陡峭的峡谷时,可能会导致更快地收敛到最小值。图中的轨迹呈现出更加平滑、更有方向性的路径朝向最优点。优点:1.相对于标准梯度下降,更快地收敛到最小值。2.考虑了动量,有助于避免振荡。
缺点:1.需要调整学习率和动量参数。
(6)Adam
轨迹形成原因:Adam的收敛轨迹图和其他的相比,明显要稳定,基本上是呈直线,或者前期收敛幅度较大,后期逐渐平稳,朝着最优点不断移动。Adam算法由于可以结合了动量法和 RMSprop 算法,不仅何以自适应调整学习率,收敛速度快,并且参数更新更加平稳。优点:
超参数具有很好的解释性,且通常无需调整或仅需很少的微调
更新的步长能够被限制在大致的范围内(初始学习率)
能自然地实现步长退火过程(自动调整学习率)
适用于不稳定目标函数
适用于梯度稀疏或梯度存在很大噪声的问题
缺点:
在非凸函数上可能不会收敛到全局最小值。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!