【2023 CCF 大数据与计算智能大赛】基于TPU平台实现超分辨率重建模型部署 基于预训练ESPCN的轻量化图像超分辨率模型TPU部署方案
2023 CCF 大数据与计算智能大赛
《基于TPU平台实现超分辨率重建模型部署》
作品名:基于预训练ESPCN的轻量化图像超分辨率模型TPU部署方案
队伍名:Absofastlutely
蒋松儒
计算机科学与技术系 硕士
南京大学
中国-江苏
kahsolt@qq.com
吕欢欢
计算机科学与技术系 博士
南京大学
中国-江苏
huanhuanlv@smail.nju.edu.cn
张凯铭
物理学系 本科
四川大学
中国-四川
2835742517@qq.com
团队简介
一个喜欢折腾神经网络和量子计算的无名小队,学艺不精脑洞不大,啥都只会一点,但没关系可以慢慢学的嘛……
摘要
本文介绍了一种在TPU平台上部署轻量化超分模型ESPCN的方法。介绍了三种图像分块策略、两种定义和搜索最优分块大小的方法;介绍了多线程加速、后处理滤波等模型性能优化技巧。最后在TPU平台上进行了模型部署和性能评估实验。
关键词
超分辨率,轻量化,TPU,模型部署
1 引言
2022年是图像生成式网络发展再度爆炸的一年。自Stable Diffusion开源,Embedding/Hypernetwork/LoRA微调、Depthmap/ControlNet条件化、AnimeDiff/Tune-A-Video连续帧化等等优化技术和下游应用也快速涌现。
但Stable Diffusion能直接产出相对优质图像尺寸是512~1024px,而我们时常需要更高分辨率如4k/8k的图像才能满足生产需求,因此超分辨率模型成了解决这个问题的一个可行桥梁方案。
总之就是,比赛要求参赛者在边缘设备TPU上移植并部署一个超分辨率模型。
2 解决方案
2.1 模型选择
考虑到TPU设备的计算性能相对较低,我们主要调研了轻量化的图像和视频超分辨率网络,并先后尝试了Real-ESRGAN[1]、NinaSR[4]、CARN、FSRCNN、ESPCN[2]等多种网络结构,最后选定了使用ESPCN。
2.1 图像分块
模型编译过程中需要确定输入张量的尺寸,虽然TPU文档里指出支持动态大小输入,但可用的SDK并未提供此功能,因此为了应对尺寸各异的输入图像,做统一尺寸的图像分块是必要的步骤。
2.1.1 分块策略
我们尝试了三种典型的分块策略:
- 朴素分块:即无重叠地裁剪后,各块分别推理,最后无重叠地粘接在一起。这种方式有最低的时间开销,但是会导致生成图像存在接缝。
- 重叠缝合:有重叠地裁剪后,各块分别推理,最后有重叠地粘接在一起,重叠区域按朴素平均、高斯羽化等方式做缝合。这种方式需要计算CNN模型的填充感受野,在重叠区域设置大于填充感受野时可以做到理论的无接缝,但缝合会产生额外的时间开销。
- 边缘裁剪:有重叠地裁剪后,各块分别推理并裁剪掉一圈边缘,最后无重叠地粘接在一起。这种方式也能实现理论的无接缝,额外计算面积比重叠缝合法小,但如果分片尺寸设置不合适,可能会导致更多的分片数量,反而增加额外计算量。

图1:三种分块策略(朴素分块、重叠缝合、边缘裁剪)

图2:朴素分块导致的接缝
考虑到时间效率优先,我们最终选用了朴素分块的策略。
2.1.2 最优分块大小
分块大小直接决定了分块数量,间接决定了模型处理处理的事件,因此合适的分块大小选取可以节省不必要的额外计算开销。我们探索了两种估算最优分块大小的方法:
- 最小化冗余计算量:考虑最小化分片导致的外向填充区域的面积。定义代价函数:
如图3所示,为代表原始图像大小的灰色区域,为所有红色分片总共覆盖的面积大小,为分片数量;是一个正则化常数,避免分片尺寸退化到无穷小,实验中取值为1。
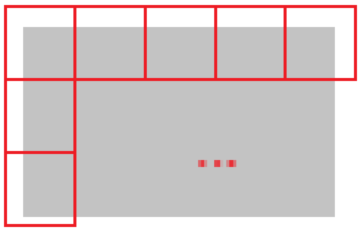
图3:分片外向填充
使用双重退火、差分演化或者暴力穷举法最小化此代价函数都可以得到最优解 。
- 最小化单位计算费率:考虑最小化TPU处理张量中每个数据单元的时间开销。我们测试了ESPCN模型在TPU上处理不同尺寸输入的开销:
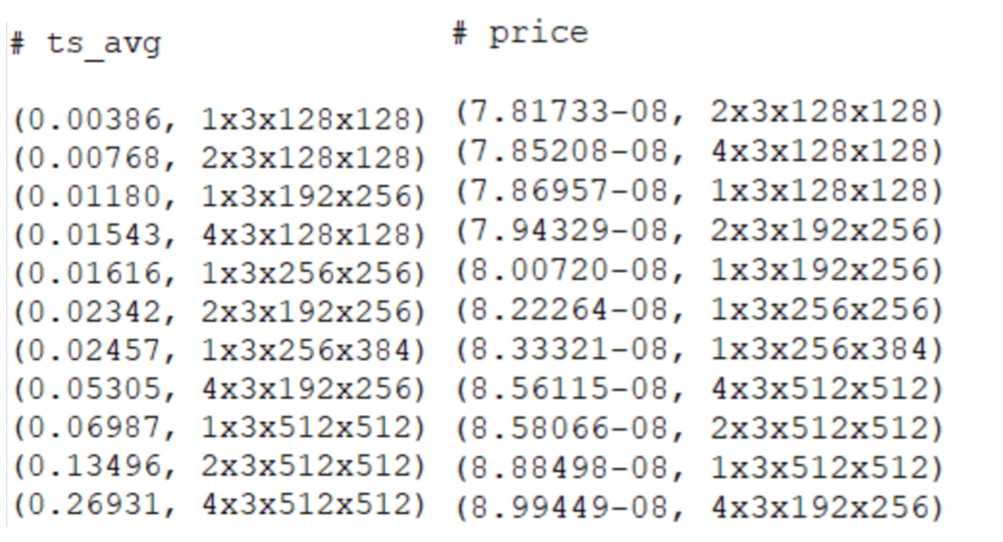
图4:TPU上处理不同尺寸输入的开销
观察可知,TPU设备上使用批处理并没有时间并行化效果,并且越小的张量尺寸计算费率越低。可以得到最优解 。
2.2 性能优化
为了进一步加速运行和提高图像质量,我们引入多线程处理和经典后处理滤波EDGE_ENHANCE和一个简化版本的UnsharpMask。后处理可以在CPU或者TPU上实现,视具体情况而定。
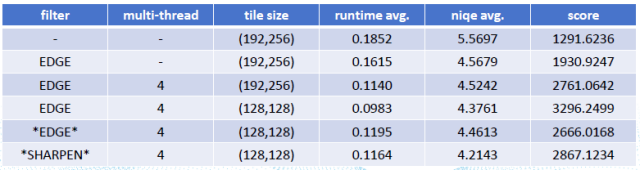
图5:引入多线程和后处理的稳定提升
3 部署和评估
模型部署:使用TPU-mlir[5]工具箱,将预训练好的ESPCN网络权重编译为TPU可加载的bmodel格式,量化类型设置为FP16,输入张量形状绑定为[1, 3, 128, 128],部署运行时代码到TPU设备sophon BM1684[6]上。
使用下列计算公式来评估模型得分:
其中为平均自然图像质量评估度量[7]的得分,越小越好,而为模型的平均推理运行时间(单位为秒),同样越小越好。在两个各含有600张2k以下尺寸图像的数据集上测试表现如下:
| 模型 | 数据集 | runtime | niqe | score |
|---|---|---|---|---|
| Real-ESRGAN | test | 5.2462 | 3.9364 | 66.7269 |
| ESPCN | test | 0.1924 | 4.4465 | 1661.0888 |
| ESPCN | val | 0.0983 | 4.3761 | 3295.7186 |
对比可见,轻量化的ESPCN相比作为基准模型的Real-ESRGAN而言,虽然NIQE质量还很差,但凭借极高的推理速度,从而在综合得分方面有显著的提升。
致谢
感谢CCF BDCI平台提供的比赛机会和开放计算资源;感谢其他参赛队伍令人触目惊心的刷榜分数;感谢无数个太阳、朝露、地神的吐息。
参考
[1] Wang X, Xie L, Dong C, et al. Real-esrgan: Training real-world blind super-resolution with pure synthetic data[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 1905-1914.
[2] Shi W, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 1874-1883.
[3] Lornatang. ESPCN-PyTorch [EB/OL] https://github.com/Lornatang/ESPCN-PyTorch
[4] Coloquinte. NinaSR: scalable neural network for Super-Resolution [EB/OL] https://github.com/Coloquinte/torchSR/blob/main/doc/NinaSR.md
[5] sophgo. TPU-MLIR [EB/OL] https://github.com/sophgo/tpu-mlir
[6] sophgo. BM1684X Introduction V1.7 [EB/OL] https://sophon-file.sophon.cn/sophon-prods3/drive/23/03/02/20/BM1684X%20Introduction%20V1.7.pdf
[7] Anish Mittal, Rajiv Soundararajan and Alan C. Bovik, Fellow, IEEE. Making a ‘Completely Blind’ Image Quality Analyzer. [EB/OL] http://live.ece.utexas.edu/research/quality/niqe_spl.pdf
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!