学习pytorch18 pytorch完整的模型训练流程
2023-12-14 21:35:06
pytorch完整的模型训练流程
1. 流程
1. 整理训练数据 使用CIFAR10数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
2. 搭建网络结构

model.py
3. 构建损失函数
loss_fn = nn.CrossEntropyLoss()
4. 使用优化器
learing_rate = 1e-2 # 0.01
optimizer = torch.optim.SGD(net.parameters(), lr=learing_rate)
5. 训练模型
output = net(imgs) # 数据输入模型
loss = loss_fn(output, targets) # 损失函数计算损失 看计算的输出和真实的标签误差是多少
# 优化器开始优化模型 1.梯度清零 2.反向传播 3.参数优化
optimizer.zero_grad() # 利用优化器把梯度清零 全部设置为0
loss.backward() # 设置计算的损失值的钩子,调用损失的反向传播,计算每个参数结点的参数
optimizer.step() # 调用优化器的step()方法 对其中的参数进行优化
6. 测试数据 计算模型预测正确率
output = net(imags)
# 计算测试集的正确率
preds = (output.argmax(1)==targets).sum()
accuracy += preds
rate = accuracy/len(test_data)
调用模型输出tensor 数据类型的 argmax方法, argmax或获取一行或者一列数值中最大数值的下标位置,argmax(0) 是从列的维度取一列数值的最大值的下标,argmax(1) 是从行的维度取一行数值的最大值的下标
output.argmax(1)==targets 会输出如下图最后一行 [false, ture], 对应位置相同则为true,对应位置不同则为false;
调用sum()方法,计算求和,false值为0,true值为1.
最后计算得出测试集整体正确率: rate = accuracy/len(test_data)

7. 保存模型
torch.save(net, './net_epoch{}.pth'.format(i))
2. 代码
1. model.py
import torch
from torch import nn
# 2. 搭建模型网络结构--神经网络
class Cifar10Net(nn.Module):
def __init__(self):
super(Cifar10Net, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.net(x)
return x
if __name__ == '__main__':
net = Cifar10Net()
input = torch.ones((64, 3, 32, 32))
output = net(input)
print(output.shape)
2. train.py
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from p24_model import *
# 1. 准备数据集
# 训练数据
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 测试数据
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 查看数据大小--size
print("训练数据集大小:", len(train_data))
print("测试数据集大小:", len(test_data))
# 利用DataLoader来加载数据集
train_loader = DataLoader(dataset=train_data, batch_size=64)
test_loader = DataLoader(dataset=test_data, batch_size=64)
# 2. 导入模型结构 创建模型
net = Cifar10Net()
# 3. 创建损失函数 分类问题--交叉熵
loss_fn = nn.CrossEntropyLoss()
# 4. 创建优化器
# learing_rate = 0.01
# 1e-2 = 1 * 10^(-2) = 0.01
learing_rate = 1e-2
print(learing_rate)
optimizer = torch.optim.SGD(net.parameters(), lr=learing_rate)
# 设置训练网络的一些参数
epoch = 10 # 记录训练的轮数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
# 利用tensorboard显示训练loss趋势
writer = SummaryWriter('./train_logs')
for i in range(epoch):
# 训练步骤开始
net.train() # 可以加可以不加 只有当模型结构有 Dropout BatchNorml层才会起作用
for data in train_loader:
imgs, targets = data # 获取数据
output = net(imgs) # 数据输入模型
loss = loss_fn(output, targets) # 损失函数计算损失 看计算的输出和真实的标签误差是多少
# 优化器开始优化模型 1.梯度清零 2.反向传播 3.参数优化
optimizer.zero_grad() # 利用优化器把梯度清零 全部设置为0
loss.backward() # 设置计算的损失值,调用损失的反向传播,计算每个参数结点的参数
optimizer.step() # 调用优化器的step()方法 对其中的参数进行优化
# 优化一次 认为训练了一次
total_train_step += 1
if total_train_step % 100 == 0:
print('训练次数: {} loss: {}'.format(total_train_step, loss))
# 直接打印loss是tensor数据类型,打印loss.item()是打印的int或float真实数值, 真实数值方便做数据可视化【损失可视化】
# print('训练次数: {} loss: {}'.format(total_train_step, loss.item()))
writer.add_scalar('train-loss', loss.item(), global_step=total_train_step)
# 利用现有模型做模型测试
# 测试步骤开始
total_test_loss = 0
accuracy = 0
net.eval() # 可以加可以不加 只有当模型结构有 Dropout BatchNorml层才会起作用
with torch.no_grad():
for data in test_loader:
imags, targets = data
output = net(imags)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
# 计算测试集的正确率
preds = (output.argmax(1)==targets).sum()
accuracy += preds
# writer.add_scalar('test-loss', total_test_loss, global_step=i+1)
writer.add_scalar('test-loss', total_test_loss, global_step=total_test_step)
writer.add_scalar('test-accracy', accuracy/len(test_data), total_test_step)
total_test_step += 1
print("---------test loss: {}--------------".format(total_test_loss))
print("---------test accuracy: {}--------------".format(accuracy))
# 保存每一个epoch训练得到的模型
torch.save(net, './net_epoch{}.pth'.format(i))
writer.close()
3. 结果
训练数据集大小: 50000
测试数据集大小: 10000
0.01
训练次数: 100 loss: 2.2905373573303223
训练次数: 200 loss: 2.2878968715667725
训练次数: 300 loss: 2.258394718170166
训练次数: 400 loss: 2.1968581676483154
训练次数: 500 loss: 2.0476632118225098
训练次数: 600 loss: 2.002145767211914
训练次数: 700 loss: 2.016021728515625
---------test loss: 316.382279753685--------------
训练次数: 800 loss: 1.8957302570343018
训练次数: 900 loss: 1.8659226894378662
训练次数: 1000 loss: 1.9004186391830444
训练次数: 1100 loss: 1.9708642959594727
......
tensorboard结果
安装tensorboard运行环境
pip install tensorboard
pip install opencv-python
pip install six
tensorboard --logdir=train_logs
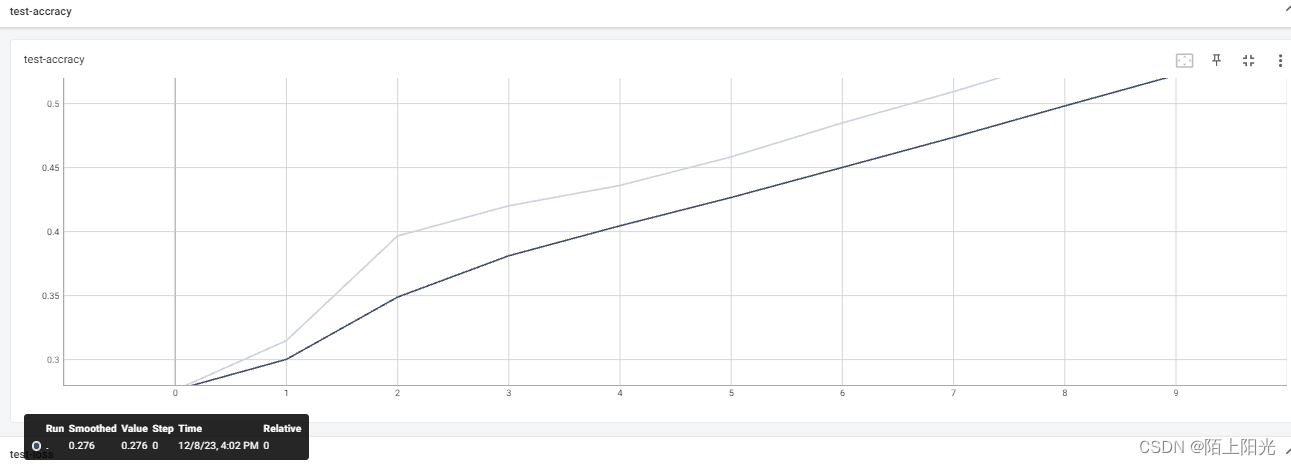
以下图片 颜色较浅的线是真实计算的值,颜色较深的线是做了平滑处理的值
训练loss

测试loss

测试集正确率
4. 需要注意的细节
https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
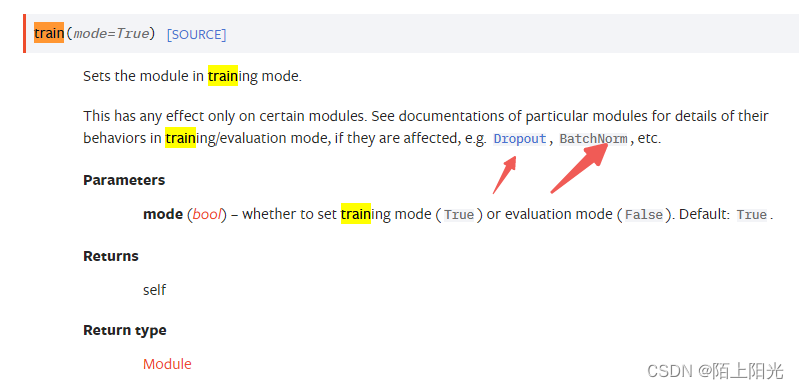
所有网络层继承于torch.nn.Module, net.train() net.eval() 在模型训练或测试之初 可以加可以不加 只有当模型结构有 Dropout BatchNorml层才会起作用,当模型有这两个网络层的时候,两个代码需要加上。

文章来源:https://blog.csdn.net/weixin_42831564/article/details/134809437
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!