Cache伪共享
伪共享
什么是伪共享
为了解决计算机系统中主内存与CPU之间运行速度差问题,会在CPU与主内存之间添加一级或者多级高速缓冲存储器(Cache)。
这个Cache一般是被集成到CPU内部的,所以也叫CPU Cache。

在Cache内部是按行存储的,其中每一行称为一个Cache行。Cache行是Cache与主内存进行数据交换的单位,Cache行的大小一般为2的幂次数字节。

当CPU访问某个变量时,首先会去看CPU Cache内是否有该变量,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache行大小的内存复制到Cache中。
由于存放到Cache行的是内存块而不是单个变量,所以可能会把多个变量存放到一个Cache行中。
当多个线程同时修改一个缓存行里面的多个变量时,由于同时只能有一个线程操作缓存行,所以相比将每个变量放到一个缓存行,性能会有所下降,这就是伪共享。
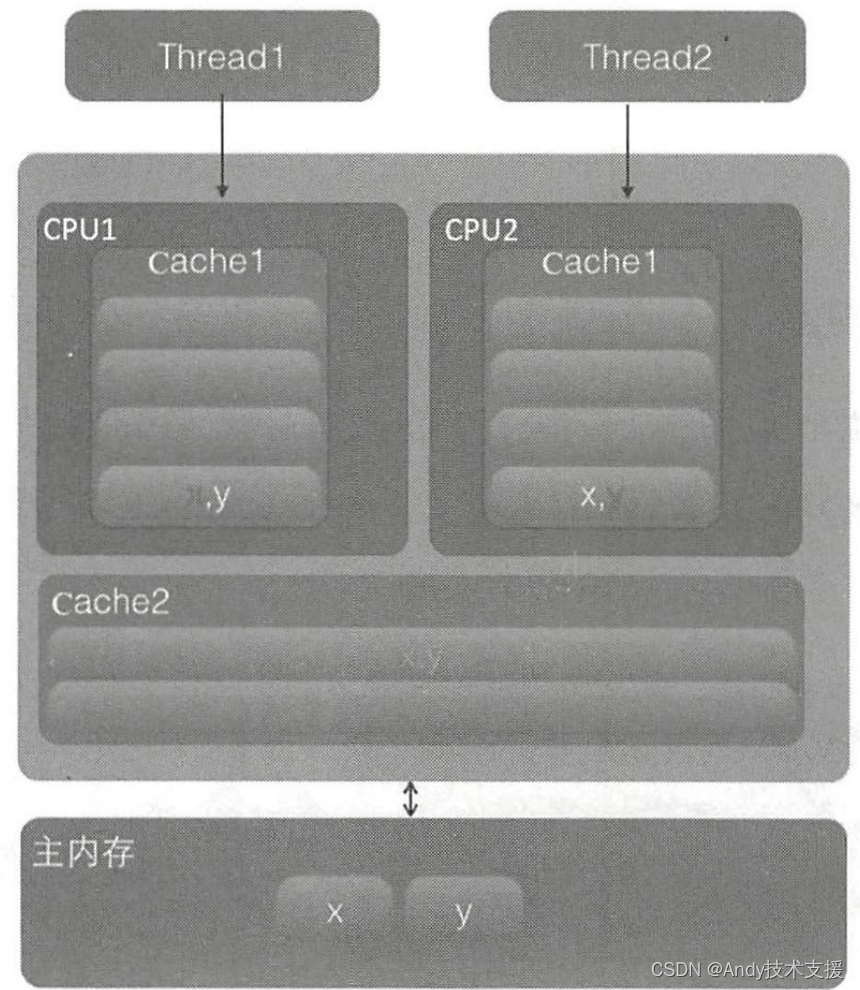
在该图中,变量x和y同时被放到了CPU的一级和二级缓存,当线程1使用CPU1对变量x进行更新时,首先会修改CPU1的一级缓存变量x所在的缓存行,这时候在缓存一致性协议下,CPU2中变量x对应的缓存行失效。
那么线程2在写入变量x时就只能去二级缓存里查找,这就破坏了一级缓存。
而一级缓存比二级缓存更快,这也说明了多个线程不可能同时去修改自己所使用的CPU中相同缓存行里面的变量。
更坏的情况是,如果CPU只有一级缓存,则会导致频繁地访问主内存。
为何会出现伪共享
伪共享的产生是因为多个变量被放入了一个缓存行中,并且多个线程同时去写入缓存行中不同的变量。
那么为何多个变量会被放入一个缓存行呢?其实是因为缓存与内存交换数据的单位就是缓存行,当CPU要访问的变量没有在缓存中找到时,根据程序运行的局部性原理,会把该变量所在内存中大小为缓存行的内存放入缓存行。
long a;
long b;
long c;
long d;
如上代码声明了四个long变量,假设缓存行的大小为32字节,那么当CPU访问变量a时,发现该变量没有在缓存中,就会去主内存把变量a以及内存地址附近的b、c、d放入缓存行。
也就是地址连续的多个变量才有可能会被放到一个缓存行中。
当创建数组时,数组里面的多个元素就会被放入同一个缓存行。
那么在单线程下多个变量被放入同一个缓存行对性能有影响吗?其实在正常情况下单线程访问时将数组元素放入一个或者多个缓存行对代码执行是有利的,因为数据都在缓存中,代码执行会更快。
如何避免伪共享
在JDK8之前一般都是通过字节填充的方式来避免该问题,也就是创建一个变量时使用填充字段填充该变量所在的缓存行,这样就避免了将多个变量存放在同一个缓存行中。

假如缓存行为64字节,那么我们在FilledLong类里面填充了6个long类型的变量,每个long类型变量占用8字节,加上value变量的8字节总共56字节。
另外,这里FilledLong是一个类对象,而类对象的字节码的对象头占用8字节,所以一个FilledLong对象实际会占用64字节的内存,这正好可以放入一个缓存行。
JDK8提供了一个sun.misc.Contended注解,用来解决伪共享问题。

在这里注解用来修饰类,当然也可以修饰变量,比如在Thread类中。

Thread类里面这三个变量默认被初始化为0,这三个变量会在ThreadLocalRandom类中使用。
需要注意的是,在默认情况下,@Contended注解只用于Java核心类,比如rt包下的类。
如果用户类路径下的类需要使用这个注解,则需要添加JVM参数:-XX:-RestrictContended。
填充的宽度默认为128,要自定义宽度则可以设置-XX:ContendedPaddingWidth参数。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!