微软近日推出了Phi-2,这是一款小型语言模型,但其性能却十分强大
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/
来这里看看: https://huggingface.co/microsoft/phi-2
当我们谈论与生成性人工智能(AI)相关的语言模型时,我们通常首先想到的是大型语言模型(LLM),这些模型驱动了大多数流行的聊天机器人,例如ChatGPT、Bard和Copilot。然而,微软的新型语言模型Phi-2展示了小型语言模型(SLM)在生成性AI领域也有巨大的潜力。
微软于周三发布了Phi-2,这是一款能够进行常识推理和语言理解的小型语言模型,现已在Azure AI Studio模型目录中提供。尽管Phi-2被称为“小型”,但它在模型中包含了27亿参数,远超过Phi-1.5的13亿参数。Phi-2在不到130亿参数的语言模型中展现了“最先进的性能”,甚至在复杂基准测试中超越了规模大25倍的模型。Phi-2在多个不同的基准测试中超越了包括Meta的Llama-2、Mistral以及谷歌的Gemini Nano 2在内的模型,Gemini Nano 2是谷歌最强大LLM的最小版本。
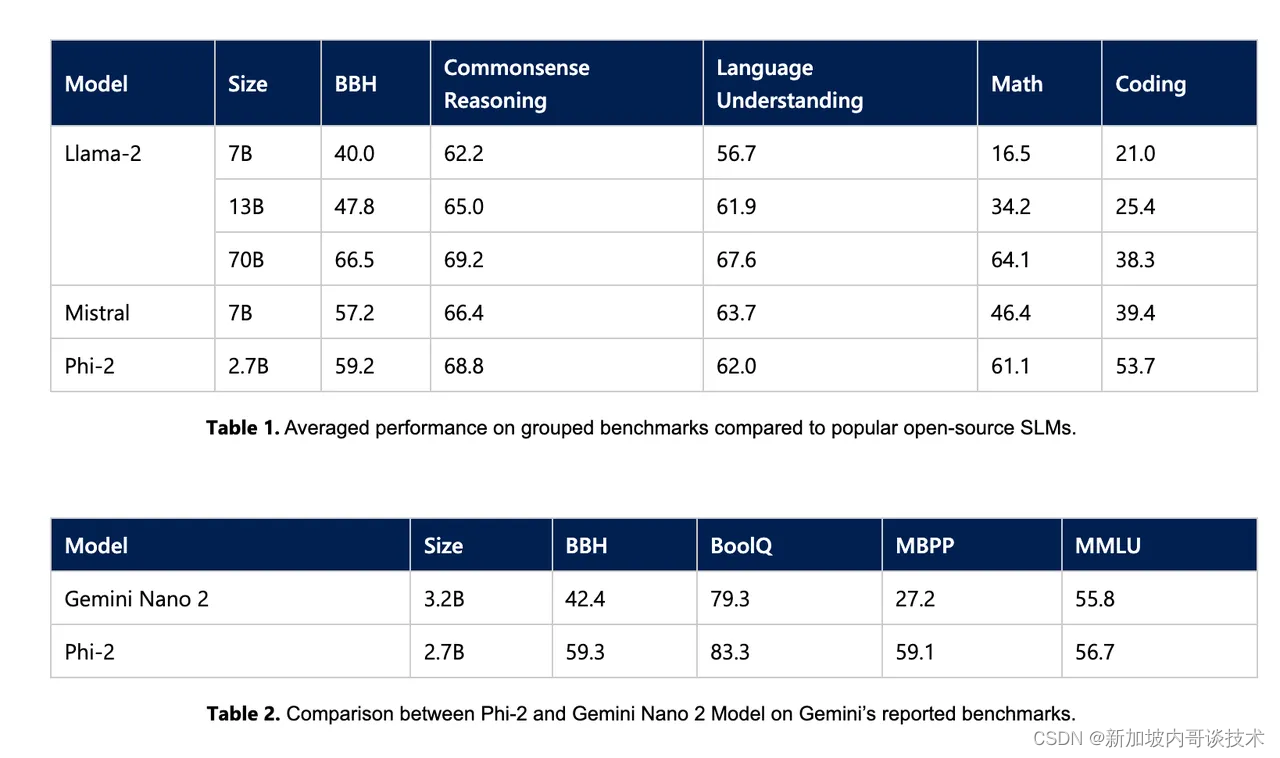
Phi-2的性能结果与微软开发具有突破性能力和与大规模模型相当性能的SLM的目标一致。
微软在训练Phi-2时非常挑剔地选择了数据。公司首先使用了所谓的“教科书质量”数据。微软随后通过添加精心挑选的网络数据来增强语言模型数据库,这些数据在教育价值和内容质量上经过了筛选。
那么,为什么微软专注于SLM?
SLM是LLM的一种成本效益较高的替代品。在不需要LLM的强大能力来完成任务时,较小的模型也很有用。
此外,运行SLM所需的计算能力远低于LLM。这种降低的要求意味着用户不必投资昂贵的GPU来满足他们的数据处理需求。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!