Java开发工具积累(符合阿里巴巴手册规范)
2023-12-15 10:43:59
文章目录
一、集合篇
1. 栈、队列、双端队列
Stack<Integer> stack = new Stack<>(); // 栈
stack.push(1); // 压入
stack.pop(); // 弹出
stack.peek(); // 获取但不弹出
Queue<Integer> queue = new ArrayDeque<>(); //队列
queue.offer(1); //压入
queue.poll(); // 弹出
queue.peek(); // 获取但不弹出
Deque<Integer> deque = new ArrayDeque<>(); // 双端队列
deque.offerFirst(1); // 压入队头
deque.offerLast(2); // 压入对尾
deque.pollFirst(); // 弹出队头
deque.pollLast(); // 弹出队尾
deque.peekFirst(); // 获取队头但不弹出
deque.peekLast(); // 获取队尾但不弹出
2. List的升序倒序
List<Integer> list = Arrays.asList(10,1,6,4,8,7,9,3,2,5);
System.out.println("原始数据:");
list.forEach(n ->{System.out.print(n+", ");});
System.out.println("");
System.out.println("升序排列:");
Collections.sort(list); // 升序排列
list.forEach(n ->{System.out.print(n+", ");});
// 降序的话:需要先升序再倒序,才能有降序的结果
System.out.println("");
System.out.println("降序排列:");
Collections.reverse(list); // 倒序排列
list.forEach(n ->{System.out.print(n+", ");});
3. Map的升序降序
Map<Integer, String> map = new HashMap<>();
map.put(100, "I'am a");
map.put(99, "I'am c");
map.put(2, "I'am d");
map.put(33, "I'am b");
// 按照value进行倒排,如果要根据key进行排序的话使用Map.Entry.comparingByKey()
map.entrySet().stream().sorted(Collections.reverseOrder(Map.Entry.comparingByValue()))
.forEach(System.out::println);
// 根据value进行正序排序,根据key进行排序的话使用comparingByKey()
map.entrySet().stream().sorted(Map.Entry.comparingByValue()).forEach(System.out::println);
// 如果要将排序的结果返回的话,我们可以使用下面的方法(注意:要使用LinkedHashMap进行保存,linkedHashMap可以保存插入顺序)
Map<Integer, String> resultMap1 = map.entrySet().stream().sorted(Map.Entry.comparingByValue()).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (s, s2) -> s,
LinkedHashMap::new));
// 下面的这种写法同上面的写法,只不过是将简写展开了,这样更易于理解
Map<Integer, String> resultMap = map.entrySet().stream().sorted(Map.Entry.comparingByValue()).collect(Collectors.toMap(new Function<Map.Entry<Integer, String>, Integer>() {
@Override
public Integer apply(Map.Entry<Integer, String> integerStringEntry) {
return integerStringEntry.getKey();
}
}, new Function<Map.Entry<Integer, String>, String>() {
@Override
public String apply(Map.Entry<Integer, String> integerStringEntry) {
return integerStringEntry.getValue();
}
}, new BinaryOperator<String>() {
@Override
public String apply(String s, String s2) {
return s;
}
}, new Supplier<Map<Integer, String>>() {
@Override
public Map<Integer, String> get() {
return new LinkedHashMap<>();
}
}));
// 同样如果需要将排序的将结果作为Map进行返回我们还可以使用下面的方法,但是不推荐这种方式(effectivejava 178页中说:foreach操作应该只用于报告stream计算的结果,而不是执行计算)
Map<Integer, String> result2 = new LinkedHashMap<>();
map.entrySet().stream().sorted(Map.Entry.comparingByValue()).forEach(new Consumer<Map.Entry<Integer, String>>() {
@Override
public void accept(Map.Entry<Integer, String> integerStringEntry) {
result2.put(integerStringEntry.getKey(), integerStringEntry.getValue());
}
});
4. 二维数组排序
Arrays.sort(intervals, new Comparator<int[]>() {
public int compare(int[] interval1, int[] interval2) {
return interval1[0] - interval2[0];
}
});
5. 集合之间的转换
// Object转基本元素
List<String> tableNames=list.stream().map(User::getMessage).collect(Collectors.toList());
// Object转Map
Map<String, Account> map = accounts.stream().collect(Collectors.toMap(Account::getUsername, Function.identity(), (key1, key2) -> key2));
// Object转Map
/**
* 1. 避免key重复
* 在使用 java.util.stream.Collectors 类的 toMap()方法转为 Map 集合时,一定要使
* 用含有参数类型为 BinaryOperator,参数名为 mergeFunction 的方法,否则当出现相同 key
* 值时会抛出 IllegalStateException 异常。
* 说明:参数 mergeFunction 的作用是当出现 key 重复时,自定义对 value 的处理策略
* 2. 避免值为null
* 在使用 java.util.stream.Collectors 类的 toMap()方法转为 Map 集合时,一定要注
* 意当 value 为 null 时会抛 NPE 异常。
**/
Map<Long, String> getIdNameMap = accounts.stream().collect(Collectors.toMap(Account::getId, Account::getUsernamee, (v1, v2) -> v2));
// String转Long
List<Long>=stringList.stream().map(Long::valueOf).collect(Collectors.toList());
// Long转String
List<String>=longList.stream().map(String::valueOf).collect(Collectors.toList());
// Integer转Long
List<Long> listLong = JSONArray.parseArray(listInt.toString(),Long.class);
// Long 转Integer
List<Integer> integerList = JSONArray.parseArray(LongList.toString(), Integer.class);
// 或者
List<Integer> integerList = longList.stream().map(x -> Integer.valueOf(String.valueOf(x))).collect(Collectors.toList());
// JSONArray转List
JSONArray jsonArray = updateApplicationSchemaDTO.getJSONArray("configTrophyDTOList");
configTrophyDTOList = jsonArray.toJavaList(ConfigTrophyDTO.class);
// List转数组
String[] array = list.toArray(new String[0]);
// 数组转List
List list = Arrays.asList(strArray);
6. Map键值对遍历
System.out.println("====4、通过entrySet()获得key-value值——使用迭代器遍历====");
Set set1 = hashMap.entrySet();
Iterator iterator1 = set1.iterator();
while(iterator1.hasNext()){
Object itset = iterator1.next();
Map.Entry entry = (Map.Entry) itset;
System.out.println(entry.getKey()+"-"+entry.getValue());
}
二、并发篇
1. 创建线程池
ThreadPoolExecutor 参数介绍
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
参数 1:corePoolSize
核心线程数,线程池中始终存活的线程数。
参数 2:maximumPoolSize
最大线程数,线程池中允许的最大线程数,当线程池的任务队列满了之后可以创建的最大线程数。
参数 3:keepAliveTime
最大线程数可以存活的时间,当线程中没有任务执行时,最大线程就会销毁一部分,最终保持核心线程数量的线程。
参数 4:unit:
单位是和参数 3 存活时间配合使用的,合在一起用于设定线程的存活时间 ,参数 keepAliveTime 的时间单位有以下 7 种可选:
TimeUnit.DAYS:天
TimeUnit.HOURS:小时
TimeUnit.MINUTES:分
TimeUnit.SECONDS:秒
TimeUnit.MILLISECONDS:毫秒
TimeUnit.MICROSECONDS:微妙
TimeUnit.NANOSECONDS:纳秒
参数 5:workQueue
一个阻塞队列,用来存储线程池等待执行的任务,均为线程安全,它包含以下 7 种类型:较常用的是 LinkedBlockingQueue 和 Synchronous,线程池的排队策略与 BlockingQueue 有关。
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
参数 6:threadFactory
线程工厂,主要用来创建线程,默认为正常优先级、非守护线程。
参数 7:handler
拒绝策略,拒绝处理任务时的策略,系统提供了 4 种可选:默认策略为 AbortPolicy。
AbortPolicy:拒绝并抛出异常。
CallerRunsPolicy:使用当前调用的线程来执行此任务。
DiscardOldestPolicy:抛弃队列头部(最旧)的一个任务,并执行当前任务。
DiscardPolicy:忽略并抛弃当前任务。
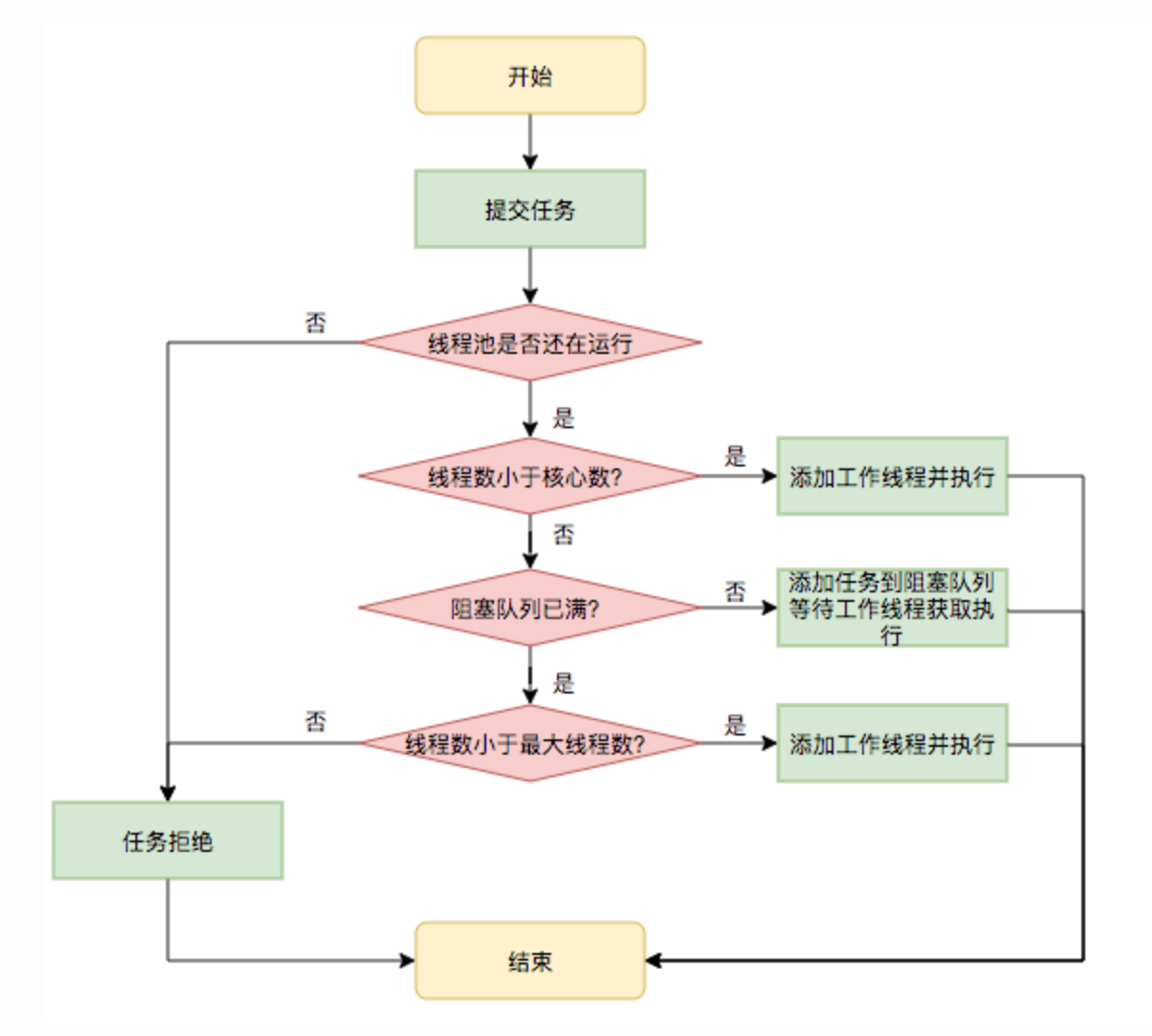
ThreadPoolExecutor执行流程
ThreadPoolExecutor 关键节点的执行流程如下:
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
- 当线程数大于等于核心线程数,且任务队列已满:若线程数小于最大线程数,创建线程;若线程数等于最大线程数,抛出异常,拒绝任务。
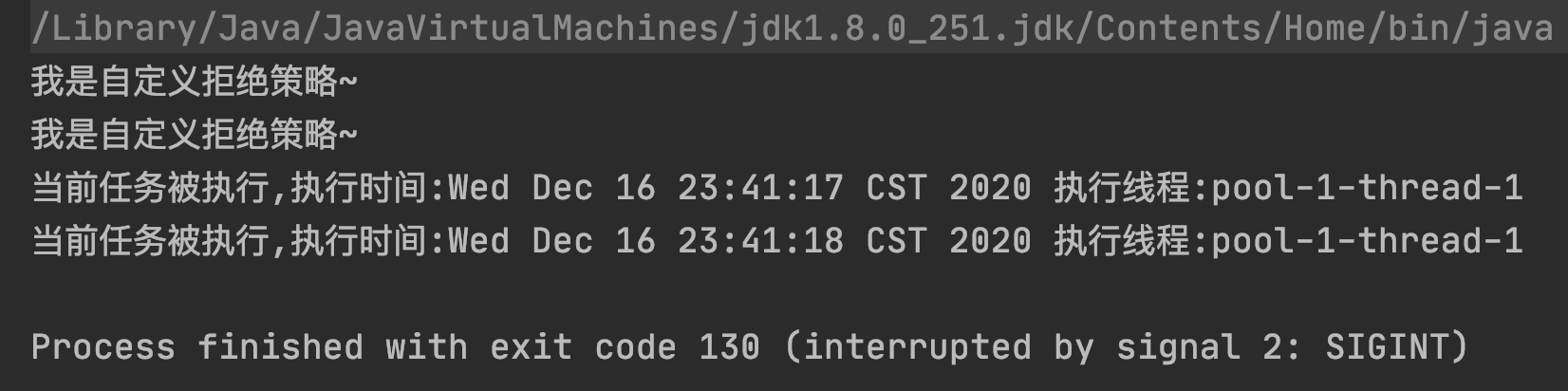
ThreadPoolExecutor自定义拒绝策略
public static void main(String[] args) {
// 任务的具体方法
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("当前任务被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 创建线程,线程的任务队列的长度为 1
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 1,
100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 执行自定义拒绝策略的相关操作
System.out.println("我是自定义拒绝策略~");
}
});
// 添加并执行 4 个任务
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
}
2. Timer与ScheduledExecutorService
Timer
三、时间篇
1. LocalDateTime的使用
// 获取当前时间
LocalDateTime now = LocalDateTime.now();
// 获取指定时间
LocalDateTime localDateTime = LocalDateTime.of(2021, 6, 16, 16, 37, 20, 814 * 1000 * 1000);
LocalDateTime ldt = LocalDateTime.now().withYear(2021).withMonth(6).withDayOfMonth(16).withHour(10).withMinute(10).withSecond(59).withNano(999 * 1000 * 1000);
// 获取指定时区时间
LocalDateTime datetime = LocalDateTime.now(ZoneId.of("Asia/Shanghai"));
LocalDateTime datetime2 = LocalDateTime.now(ZoneId.of("+8"));
// 获取年月日信息
LocalDateTime now = LocalDateTime.now();
int year = now.getYear();
int month = now.getMonthValue();
int dayOfYear = now.getDayOfYear();
int dayOfMonth = now.getDayOfMonth();
int hour = now.getHour();
int minute = now.getMinute();
int second = now.getSecond();
int nano = now.getNano();
// 日期计算
LocalDateTime now = LocalDateTime.now();
LocalDateTime tomorrow = now.plusDays(1L);
tomorrow = tomorrow.plusHours(2L);
tomorrow = tomorrow.plusMinutes(10L);
LocalDateTime yesterday = now.minus(Duration.ofDays(1));
yesterday = yesterday.plusHours(2L);
yesterday = yesterday.plusMinutes(10L);
// 时间格式化,DateTimeFormatter是线程安全的类。
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
String format = LocalDateTime.now().format(df);
2. String、Date、LocalDateTime转换
// LocalDateTime转Date
public static Date localDateTime2Date(LocalDateTime localDateTime) {
return Date.from(localDateTime.atZone(ZoneId.systemDefault()).toInstant());
}
// LocalDateTime转String
private static final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static String localDateTime2String(LocalDateTime localDateTime) {
return localDateTime.format(DATE_TIME_FORMATTER);
}
// String 转 LocalDateTime,DateTimeFormatter是线程安全的类,可以将此类放到常量中。
private static final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static LocalDateTime string2LocalDateTime(String str) {
return LocalDateTime.parse(str, DATE_TIME_FORMATTER);
}
// String 转 Date,SimpleDateFormat是非线程安全的类,在多线程操作时会报错。
public static Date string2Date(String str) throws ParseException {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return simpleDateFormat.parse(str);
}
// Date 转 LocalDateTime
public static LocalDateTime date2LocalDateTime(Date date) {
return date.toInstant()
.atZone(ZoneId.systemDefault())
.toLocalDateTime();
}
// Date 转 String
public static String date2String(Date date) {
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return formatter.format(date);
}
文章来源:https://blog.csdn.net/m0_46638350/article/details/134963694
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!