【没有哪个港口是永远的停留~论文简读】Panoptic SegFormer
Panoptic SegFormer
原文:https://arxiv.org/pdf/2109.03814.pdf
代码:GitHub - zhiqi-li/Panoptic-SegFormer: This is the official repo of Panoptic SegFormer [CVPR'22]
在全景分割中,图像内容可分为things和stuff两类。
- things是可计数的实例(例如,人、汽车和自行车),每个实例都有一个唯一的id来区别于其他实例。
- stuff是指非定形和不可数的区域(例如,天空,草原和雪),没有实例id。
Panoptic SegFormer包含三个关键的设计:
(1)统一表示things和stuff的query集 ,其中stuff被视为只有单一实例id的特殊类型;
(2)利用things和stuff的位置信息来提高分割质量的位置解码器 ;
(3)Mask后处理策略 ,合并things和stuff的分割结果。
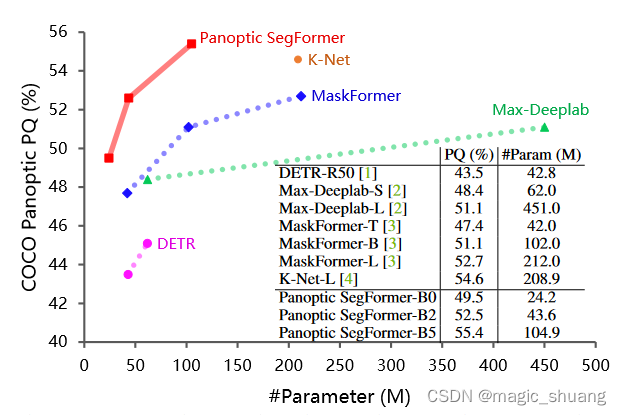
受益于这三种设计,Panoptic SegFormer高效地实现了SOTA的全精分割任务的性能。(性能对比如下图所示)
?
网络结构

?
模型的整体架构如上图所示,Panoptic SegFormer由三个关键模块组成:
- Transformer Encoder:对主干提取的多尺度特征图进行细化;
- Location Decoder 位置解码器:利用位置解码器捕捉物体的位置线索;
- Mask Decoder:Mask解码器用于最终的分类和分割
在前向阶段,我们首先将图像输入到主干网络,从最后三个阶段获得特征图C3、C4、C5,与输入图像相比,其分辨率分别为1/8、1/16和1/32。
然后,通过全连接(FC)层将这三个特征投影到具有256个通道的特征中,并将它们flatten为特征token C3`、C4`、C5`。维度分别为L1x256、L2x256、L3x256。
接下来,concat这些token作为Transformer编码器的输入,Transformer编码器输出的细化特征大小为。然后使用N个初始化的query来描述things和stuff,获取position信息。最后使用mask-wise strategy来融合预测的mask,得到最终的分割结果。
Transformer编码器
高分辨率和多尺度特征图对于分割任务具有重要意义。由于多头注意层的计算成本高,以往基于Transformer的方法只能在其编码器中处理低分辨率的特征图(如ResNet的C5),这限制了分割性能。与这些方法不同,作者使用可变形的注意层(deformable attention)来实现Transformer编码器。由于可变形注意层的计算复杂度较低,本文的编码器可以拓展到高分辨率和多尺度特征图F。
位置解码器
在全景分割任务中,位置信息在区分具有不同实例id的things方面起着重要的作用。受此启发,作者设计了一个位置解码器,将things的位置信息(即中心位置和尺度)引入到可学习的query中。
具体来说,给定N个随机初始化的query和由Transformer编码器生成的细化的特征token,解码器将输出N个具有位置感知性的query。在训练阶段,作者在位置感知query的基础上应用一个辅助的MLP头来预测目标对象的尺度和中心位置,并使用位置损失来监督预测。MLP头是一个辅助分支,可以在推理阶段被丢弃。由于位置解码器不需要预测分割mask,因此作者用计算和内存更高效的可变形注意(deformable attention)来实现。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!