Apache Doris 聚合函数源码阅读与解析|源码解读系列
笔者最近由于工作需要开始调研 Apache Doris,通过阅读聚合函数代码切入 Apache Doris 内核,同时也秉承着开源的精神,开发了 array_agg 函数并贡献给社区。笔者通过这篇文章记录下对源码的一些理解,同时也方便后面的新人更快速地上手源码开发。
聚合函数,顾名思义,即对一组数据执行聚合计算并返回结果的函数,在统计分析过程中属于最常见的函数之一,最典型的聚合函数包括 count、min、max、sum 等。基于聚合函数可以实现对大量数据的汇总计算,以更简洁的形式呈现数据并支持数据可视化。
相较于单机数据库,由于所有数据都存储在同一台机器上、无需跨节点的网络数据传输,往往单机数据库的聚合函数执行效率更高,而分布式数据库由于数据分散存储于多个节点、并行执行计算时需要从多个节点汇集数据,带来了额外的网络传输和本地磁盘 IO 开销,且多副本机制和分片策略也进一步增加了计算的数据量和管理的复杂性。
为避免单点瓶颈同时减少网络 IO,往往需要使用多阶段的方式进行执行,因此 Apache Doris 实现了灵活的多阶段聚合机制,能够根据查询语句的特点为其选择适当的聚合方式,从而在执行时间和执行开销(如内存,IO 等)之间取得有效的平衡。
多阶段聚合
在 Apache Doris 中,主要聚合机制有如下几种:
-
一阶段聚合:Group By 仅包含分桶列,不同 Tablet 的数据在不同的分组中,因此不同 BE 可以独立并行计算;
-
两阶段聚合:Group By 包含非分桶列,同一个分组中的数据可能分布在多个 BE 上;
-
三阶段聚合:Count Distinct 包含 Group By(即 2 个两阶段聚合的组合);
-
四阶段聚合:Count Distinct 不包含 Group by,通常采用 4 阶段聚合(1 个一阶段聚合和 1 个二阶段聚合的组合)
一阶段聚合
以如下查询为例,c1 是分桶列:
SELECT ?count(c1) FROM t1 GROUP BY c1由于每个 BE 存储了若干个 Tablet ,每台 BE 只需要对当前节点上的 Tablet Set,分别进行 Hash Aggregate 即可,也称为 Final Hash Aggregate,随后对各个 BE 结果进行汇总。
同一个 BE 可以使用多个线程来同时进行 Final Hash Aggregate 以提高效率,这里为了便于更简单理解仅讨论单线程。
两阶段聚合
以如下查询为例,c2 不是分桶列:
SELECT c2, count(c1) FROM t1 GROUP BY c2对于上述查询,可以生成如下两阶段查询:
-
对 scan 分区按照 group by 字段(即 c2)进行分组聚合;
-
将聚合后的结果按照 group by 字段进行重分区,然后对新的分区按照 group by 字段进行分组聚合。
具体流程如下:
-
BE 对本节点上的 Tablet Set 进行第一次 Hash Aggregate,也称为 Pre Hash Aggregate;
-
BE 将 Pre Hash Aggregate 产生的结果按照完全相同的规则进行 Shuffle,其目的是将相同分组中的数据分发到同一台机器上;
-
BE 收到 Shuffle 数据后,再次进行 Hash Aggregate,也称为 Final Hash Aggregate;
-
对各个 BE 结果进行汇总

三阶段聚合
以如下查询为例:
SELECT count(distinct c1) FROM t1 GROUP BY c2对于上述查询,可以生成如下三阶段查询:
-
对 scan 分区按照 group by 和 distinct 字段(即 c2, c1)进行分组聚合;
-
将聚合后的结果按照 group by 和 distinct 字段进行重分区,然后对新的分区按照 group by 和 distinct 字段进行分组聚合;
-
对新的分区按照 group by 字段(即 c2)进行分组聚合。

四阶段聚合
以如下查询为例:
SELECT count(distinct c1), sum(c2) FROM t1对于上述查询,可以生成如下四阶段查询:
-
对 scan 分区按照 distinct 字段进行分组聚合;
-
将聚合后的结果按照 distinct 字段进行重分区,然后对新的分区按照 distinct 字段进行分组聚合;
-
将 count distinct 转换为 count,对新的分区进行聚合;
-
对各分区的结果进行汇总聚合。

流式预聚合
对于上述多阶段聚合中的第一阶段,其主要作用是通过预聚合减少重分区产生的网络 IO。如果在聚合时使用了高基数的维度作为分组维度(如 group by ID),则预聚合的效果可能会大打折扣。为此,Apache Doris 支持为此聚合阶段启用流式预聚合,在此模式下如果 Aggregate Pipeline 发现聚合操作产生的行数减少效果不及预期,则不再对新的 Block 进行聚合而是将其转换后放到队列中。而 Read Pipeline 也无需等待前者聚合完毕才开始执行,而是读取队列中 Block 进行处理,直到 Aggregate Pipeline 执行完毕后才读取 Hash 表中的聚合结果。 简单而言,聚合过程中如果 Hash Table 需要扩容但发现聚合效果不好(比如输入 1w 条数据,经聚合后还有 1w 个分组)就会跳过聚合,直接把每一行输入当作一个分组。即在第一阶段,对不同的数据分布,采用不同的处理方式能够进一步提高效率:
-
若数据聚合度高,那么在该阶段进行聚合,可以有效减少数据量,降低 Shuffle 时的网络开销;
-
若数据聚合度低,在该阶段进行聚合无法起到很好的聚合效果,同时伴随着额外的开销,例如哈希计算、额外的 Map、Set 存储空间,此时我们可以将该算子退化成一个简单的流式传输的算子,数据进入该算子后,不做处理直接输出。
Merge & Finalize
由于聚合计算的执行过程和最终结果的生成方式不同,聚合函数可以分为需要 Finalize 的和不需要 Finalize 的这两类。需要 Finalize 的聚合函数(在计算过程中会产生中间结果,这些中间结果可能需要进一步的处理或合并才能得到最终的聚合结果)包括:
-
AVG:计算平均值时需要将所有值相加再除以总数,因此需要 Finalize 操作来完成这个过程;
-
STDDEV:计算标准差时需要先计算方差再开方得到标准差,这个过程需要多次遍历数据集,因此需要 Finalize 操作来完成;
-
VAR_POP、VAR_SAMP:计算方差时需要用到所有数据的平方和,这个过程需要多次遍历数据集,因此需要 Finalize 操作来完成。
不需要 Finalize 的聚合函数(在计算过程中可以直接得到最终结果)包括:
-
COUNT:只需要统计数据集中的行数,不需要进行其他操作;
-
SUM、MIN、MAX:对数据集进行聚合时,这些函数只需要遍历一次数据集,因此不需要进行 Finalize 操作。
对于非第一阶段的聚合算子来说,由于其读取到的是经过聚合后的数据,因此在执行时需要将聚合状态进行合并。而对于最后阶段的聚合算子,则需要在聚合计算后计算出最终的聚合结果。
聚合函数核心接口
IAggregateFunction接口
在 Apache Doris 之中,定义了一个统一的聚合函数接口 IAggregateFunction。上文笔者提到的聚合函数,则都是作为抽象类 IAggregateFunction 的子类来实现的。该类中所有函数都是纯虚函数,需要子类自己实现,其中该接口最为核心的方法如下:
-
add函数:最为核心的调用接口,将对应 AggregateDataPtr 指针之中数据取出,与列 columns 中的第 row_num 的数据进行对应的聚合计算。(这里可以看到Doris是一个纯粹的列式存储数据库,所有的操作都是基于列的数据结构。)
-
merge函数:将两个聚合结果进行合并的函数,通常用在并发执行聚合函数的过程之中,需要将对应的聚合结果进行合并。
-
serialize 函数与 deserialize 函数:序列化与反序列化的函数,通常用于 Spill-to-Disk 或 BE 节点之间传输中间结果的。
-
add_batch 函数:虽然它仅仅实现了一个 for 循环调用 add 函数,但通过这样的方式来减少虚函数的调用次数,并且增加了编译器内联的概率。(虚函数的调用需要一次访存指令,一次查表,最终才能定位到需要调用的函数上,这在传统的火山模型的实现上会带来极大的CPU开销。)
首先看聚合节点 Aggregetor 是如何调用 add_batch 函数:
for (int i = 0; i < _aggregate_evaluators.size(); ++i) {
RETURN_IF_ERROR(_aggregate_evaluators[i]->execute_batch_add(
block, _offsets_of_aggregate_states[i], _places.data(),
_agg_arena_pool.get()));
}这里依次遍历 AggFnEvaluator 并调用 execute_batch_add-->add_batch,而 add_batch 接口就是一行行的遍历列进行聚合计算:
void add_batch(size_t batch_size, AggregateDataPtr* places, size_t place_offset,
const IColumn** columns, Arena* arena, bool agg_many) const override{
for (size_t i = 0; i < batch_size; ++i) {
assert_cast<const Derived*>(this)->add(places[i] + place_offset, columns, i, arena);
}
}构造函数:
IAggregateFunction(const DataTypes& argument_types_) :
argument_types(argument_types_) {}argument_types_ 指的是函数的参数类型,比如函数 select avg(a), avg(b), c from test group by c, 这里 a, b 分别是 UInt16 类型与 Decimal 类型,那么这个 avg(a) 与 avg(b) 的参数就不同。
聚合函数结果输出接口 将聚合计算的结果重新组织为列存:
/// Inserts results into a column.
virtual void insert_result_into(ConstAggregateDataPtr __restrict place, IColumn& to) const = 0;首先看聚合节点 AggregationNode 是如何调用 insert_result_into 函数的:
for (size_t i = 0; i < _aggregate_evaluators.size(); ++i) {
_aggregate_evaluators[i]->insert_result_info(
mapped + _offsets_of_aggregate_states[i],
value_columns[i].get());
}
void AggFnEvaluator::insert_result_info(AggregateDataPtr place, IColumn* column) {
_function->insert_result_into(place, *column);
}AggregationNode 同样是遍历 Hash表之中的结果,将 Key 列先组织成列存,然后调用 insert_result_info 函数将聚合计算的结果也转换为列存。以 avg 的实现为例:
void insert_result_into(ConstAggregateDataPtr __restrict place, IColumn& to) const override {
auto& column = assert_cast<ColVecResult&>(to);
column.get_data().push_back(this->data(place).template result<ResultType>());
}
template <typename ResultT>
AggregateFunctionAvgData::ResultT result() const {
if constexpr (std::is_floating_point_v<ResultT>) {
if constexpr (std::numeric_limits<ResultT>::is_iec559) {
return static_cast<ResultT>(sum) / count; /// allow division by zero
}
}
// https://github.com/apache/doris/blob/master/be/src/vec/aggregate_functions/aggregate_function_avg.h这里就是调用 ConstAggregateDataPtr ,即 AggregateFunctionAvgData 的 result() 函数获取 avg 计算的结果添加到内存中。
IAggregateFunctionDataHelper 接口
这个接口是上面提到 IAggregateFunction 的辅助子类接口,主要实现获取 add/serialize/deserialize 函数地址的方法。
抽象类 IColumn
聚合函数需要大量使用 Doris 的核心接口 IColumn 类。IColumn 接口是所有数据存储类型的基类,其表达了所有数据的内存结构,其他带有具体数据类型的如:ColumnNullable、ColumnUInt8、ColumnString、ColumnVector、ColumnArray 等,都实现了对应的列接口,并且在子类之中具象实现了不同的内存布局。
在此以 avg 的实现为例(这里简化了对 Decimal 类型的处理):
void add(AggregateDataPtr __restrict place, const IColumn** columns, size_t row_num,
Arena*) const override {
const auto& column = assert_cast<const ColVecType&>(*columns[0]);
this->data(place).sum += column.get_data()[row_num].value;
++this->data(place).count;
}
// https://github.com/apache/doris/blob/master/be/src/vec/aggregate_functions/aggregate_function_avg.h这里 columns 是一个二维数组,通过 columns[0] 可以取到第一列。这里只有涉及到一列,为什么 columns 是二维数组呢?因为处理多列的时候,也是通过对应的接口,而 array 就需要应用二维数组了。 注意这里有一个强制的类型转换,column 已经转换为 ColVecType 类型了,这是模板派生出 IColumn 的子类。
然后通过 IColumn 子类实现的 get_data() 方法获取对应 row_num 行的数据,进行 add 函数调用就完成了一次聚合函数的计算了。由于这里是计算平均值,我们可以看到不仅仅累加了 value 还计算 count。
聚合函数主体流程
在执行时,对应的 Fragment 会被转换为如下 Pipeline:
![]()
在上述 Pipeline 中,Aggregate Pipeline 负责使用 Hash 表(有 group by 的情况下)对输入数据进行聚合,Read Pipeline 负责读取聚合后的数据并发送至父算子,因此两者存在依赖关系,后者需要等待前者执行完成后才能开始执行。
在此仅以 BE 节点收到来自 FE 节点的 Execution Fragment 来分析。Aggregate 逻辑的入口位于 AggregationNode,处理流程根据是否启用流式预聚合而有所不同。但是不论哪种,都依赖于 AggregationNode 的实现。在介绍具体实现之前,我们先介绍下 AggregationNode。
结构体介绍
AggregationNode 的一些重要成员如下,其中中文部分是笔者添加的注释:
class AggregationNode : public ::doris::ExecNode{
Status init(const TPlanNode& tnode, RuntimeState* state = nullptr) override;
Status prepare_profile(RuntimeState* state);
Status prepare(RuntimeState* state) override;
//SQL中包含的聚合函数的数组
std::vector<AggFnEvaluator*> _aggregate_evaluators;
//是否需要finalize,前文有提到判断准则
bool _needs_finalize;
//是否需要merge
bool _is_merge;
//是否是第一阶段聚合
bool _is_first_phase;
//用来bind执行阶段需要用到的函数
executor _executor;
//存放聚合过程中的数据
AggregatedDataVariantsUPtr _agg_data;
//取出聚合结果,发送至父算子进行处理
//进行读取操作,会使用get_result函数进行处理
Status pull(doris::RuntimeState* state, vectorized::Block* output_block, bool* eos) override;
//对输入block进行聚合,该步骤会使用前面分配的execute函数进行处理。
Status sink(doris::RuntimeState* state, vectorized::Block* input_block, bool eos) override;
//读取聚合结果,该函数最终会调用AggregationNode::pull函数进行读取操作
Status get_next(RuntimeState* state, Block* block, bool* eos) override;
//执行阶段需要用到的函数
Status _get_without_key_result(RuntimeState* state, Block* block, bool* eos);
Status _serialize_without_key(RuntimeState* state, Block* block, bool* eos);
Status _execute_without_key(Block* block);
Status _merge_without_key(Block* block);
Status _get_with_serialized_key_result(RuntimeState* state, Block* block, bool* eos);
Status _get_result_with_serialized_key_non_spill(RuntimeState* state, Block* block, bool* eos);
Status _execute_with_serialized_key(Block* block);
Status _merge_with_serialized_key(Block* block);
}
Apache Doris 在聚合计算过程中使用了一种比较灵活的方式,在 AggregationNode 中事先声明了一个executor 结构体,其中封装了多个 std::function,分别代表执行阶段可能需要调用到的函数。在 Prepare 阶段会使用 std::bind 将函数绑定到具体的实现上,根据是否开启 streaming pre-agg、是否存在 group by、是否存在 distinct 等条件来确定具体绑定什么函数。
struct AggregationNode::executor {
vectorized_execute execute;
vectorized_pre_agg pre_agg;
vectorized_get_result get_result;
vectorized_closer close;
vectorized_update_memusage update_memusage;
};这几个函数的大致调用关系过程可如下所示:
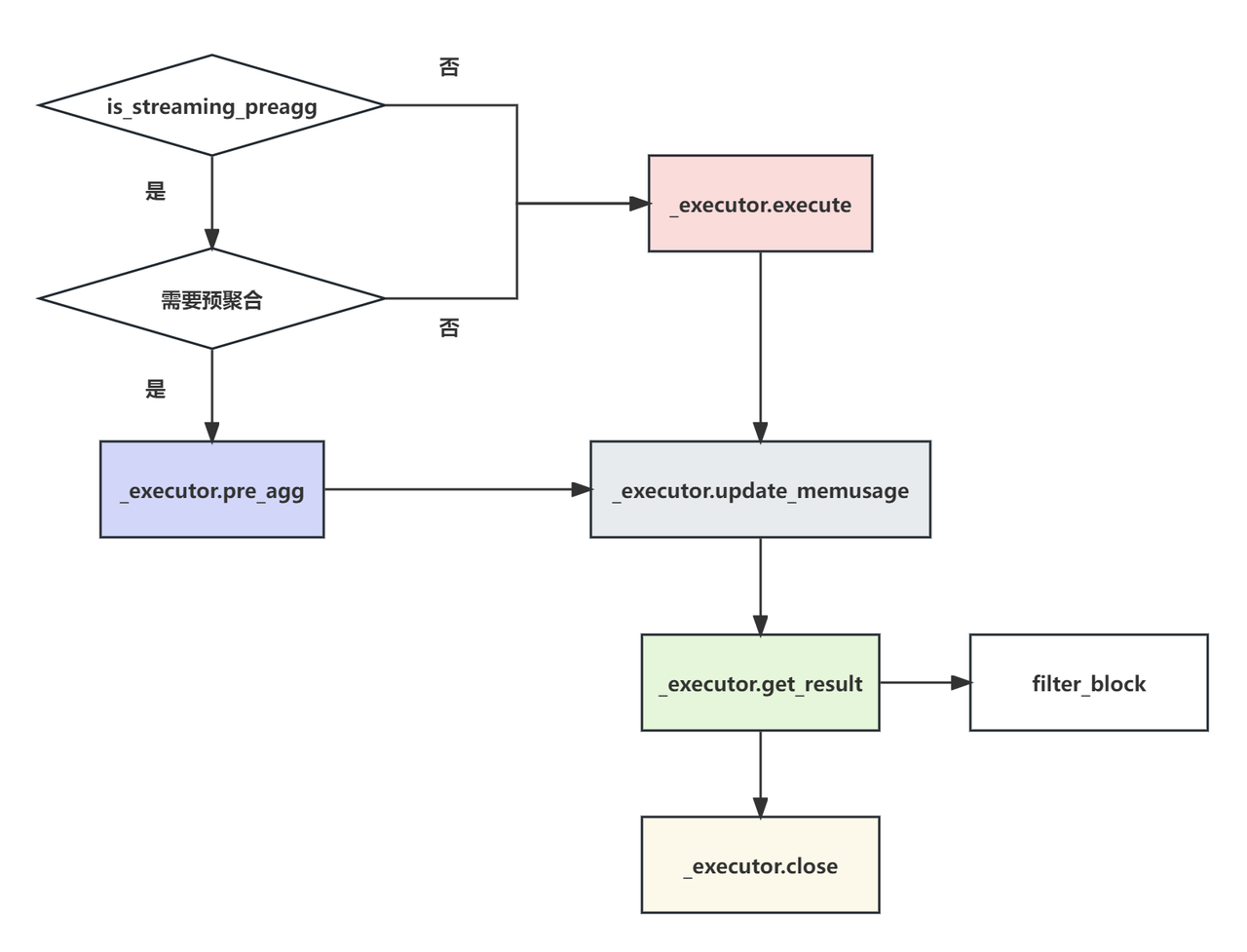
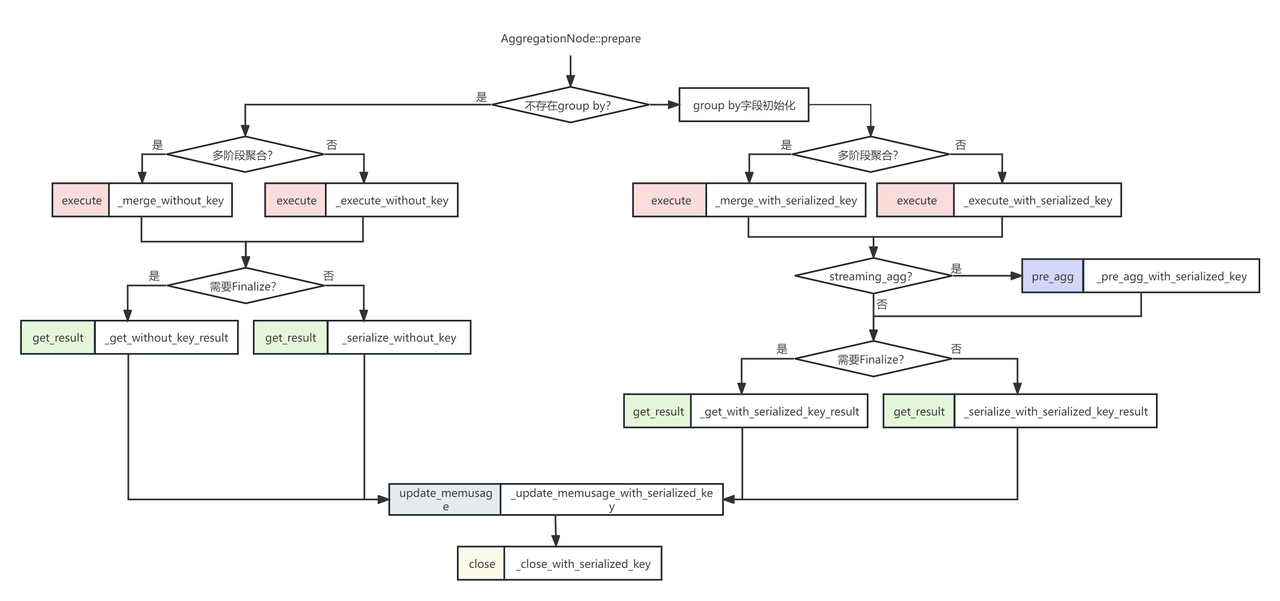
对应的相关绑定过程:
普通聚合
在没有启用流式预聚合的情况下,处理流程如下:
-
调用 AggregationNode::init 函数进行初始化,包含如下处理逻辑:
-
调用 VExpr::create_expr_trees 函数创建 group by 相关的信息;
-
调用 AggFnEvaluator::create 函数创建聚合函数。在代码中,这里是一个 for 循环,即如果 SQL 中包含多个聚合函数,需要创建多次。
-
-
调用 AggregationNode::prepare 函数执行运行前的准备,包含如下处理逻辑:
-
调用 ExecNode::prepare 函数为父类成员执行运行前的准备;
-
对 group by 表达式调用 VExpr::prepare 函数执行运行前的准备;
-
计算聚合函数需要的状态空间大小及各聚合函数的偏移,这些偏移量后续取地址的时候会用到
-
AggregationNode::prepare_profile 根据当前聚合类型及是否涉及 group by 参数 bind 对应的处理函数,分配逻辑如下:
-
如果当前聚合包含 group by 参数:
-
如果当前聚合需要 merge 聚合状态(多阶段聚合),则使用 AggregationNode::merge_with_serialized_key 函数用于处理输入 block(下称 execute 函数),否则使用 AggregationNode::execute_with_serialized_key 函数。如果是多阶段聚合多个 AggregationNode 会分别绑定_merge_with_serialized_key 和 _execute_with_serialized_key。
-
如果当前聚合需要对聚合结果执行 finalize,则使用 AggregationNode::get_with_serialized_key_result 函数用于读取聚合结果(下称 get_result 函数),否则使用AggregationNode::serialize_with_serialized_key_result 函数。
-
-
如果当前聚合不包含 group by 参数:
-
如果当前聚合需要 merge 聚合状态,则使用 AggregationNode::merge_without_key 函数用于处理输入 block(下称execute函数),否则使用 AggregationNode::execute_without_key 函数。
-
如果当前聚合需要对聚合结果执行 finalize,则使用 AggregationNode::get_with_serialized_key_result 函数用于读取聚合结果(下称 get_result 函数),否则使用 AggregationNode::serialize_with_serialized_key_result 函数。
-
-
如果当前聚合包含 group by 参数,则需要根据参数类型分配对应的 hash 方法:_init_hash_method
-
-
-
调用 AggregationNode::sink 函数对输入 Block 进行聚合,该步骤会使用前面分配的 execute 函数进行处理。
-
调用 AggregationNode::get_next 函数读取聚合结果,该函数最终会调用 AggregationNode::pull 函数进行读取操作,后者会使用前面分配的 get_result 函数进行处理。
-
调用 AggregationNode::release_resource 函数释放资源,该函数会调用 _executor.close()。
对 block 数据的聚合逻辑较为简单,以包含 group by 参数的情况为例,聚合流程如下:
-
调用 AggregationNode::_emplace_into_hash_table 函数创建具体的聚合方法类,并获取 Hash 表中对应行的聚合状态。
-
如果当前聚合处理的是原始的行数据,则调用 AggFnEvaluator::execute_batch_add 函数进行聚合处理。
-
如果当前聚合需要 merge 聚合状态,则首先需要对聚合状态中的结果进行反序列化,然后调用 IAggregateFunctionHelper::merge_vec 函数对当前聚合状态进行合并。
流式聚合
对于 hash 分组效果不佳的场景,会启用流式预聚合,处理流程如下:
-
调用 AggregationNode::init 函数进行初始化;
-
调用AggregationNode::prepare函数执行运行前的准备;
-
调用 AggregationNode::do_pre_agg 函数对输入 block 进行聚合,该函数会调用 _pre_agg_with_serialized_key 函数进行实际的聚合操作。如果在处理过程中 hash 扩容达到阈值,则跳过聚合,直接把每一行输入当作一个分组,即调用 streaming_agg_serialize_to_column,否则还是使用朴素的方法 AggFnEvaluator::execute_batch_add;
-
调用 AggregationNode::pull 函数取出聚合结果,发送至父算子进行处理;
-
调用 AggregationNode::release_resource 函数释放资源。
感兴趣的读者可以自行阅读流式聚合相关的源码,可以给 streaming_agg_serialize_to_column 加断点进行 debug,触发方法如下:
-
TPC-H 准备 3G 数据,方法见 https://doris.apache.org/zh-CN/docs/1.2/benchmark/tpch/?
-
执行 SQL
select count() from (select map_agg(o_orderstatus,o_clerk) from orders group by o_custkey, o_orderdate) a;
如何新增一个聚合函数
下面以 map_agg 为例介绍添加聚合函数的流程。以下内容仅为笔者个人的思考,感兴趣的读者可以具体参考:[feature](agg) add the aggregation function 'mag_agg' by mrhhsg · Pull Request #22043 · apache/doris · GitHub[feature](agg) add the aggregation function 'mag_agg' by mrhhsg · Pull Request #22043 · apache/doris · GitHub
map_agg 使用介绍
语法:MAP_AGG(expr1, expr2)
功能:返回一个 map,由 expr1 作为键、expr2 作为对应的值。
在 FE 创建函数签名
Step 1: 维护 FunctionSet.java
FE 通过 initAggregateBuiltins 来描述聚合函数,所有的聚合函数都会注册在 FunctionSet 中。初始化阶段在 FunctionSet.java?的 initAggregateBuiltins 中增加对应的 AggregateFunction.createBuiltin 函数即可。
if (!Type.JSONB.equals(t)) {
for (Type valueType : Type.getMapSubTypes()) {
addBuiltin(AggregateFunction.createBuiltin(MAP_AGG, Lists.newArrayList(t, valueType),
new MapType(t, valueType),
Type.VARCHAR,
"", "", "", "", "", null, "",
true, true, false, true));
}
for (Type v : Type.getArraySubTypes()) {
addBuiltin(AggregateFunction.createBuiltin(MAP_AGG, Lists.newArrayList(t, new ArrayType(v)),
new MapType(t, new ArrayType(v)),
new MapType(t, new ArrayType(v)),
"", "", "", "", "", null, "",
true, true, false, true));
}
}以上代码的理解思路如下:
-
如果 map_agg 的 key 不是 josn blob 字段( if (!Type.JSONB.equals(t)) ),则先找到 map_agg 相关函数 ( for (Type valueType : Type.getMapSubTypes())) 。
-
通过 addBuiltin 初始化对应 MAP_AGG 函数,value 类型是传进来的 valueType,中间状态变量是 Type.VARCHAR。
-
找到 array 相关函数( for (Type v : Type.getArraySubTypes())),通过 addBuiltin 初始化对应 MAP_AGG 函数, value 类型是 ArrayType,中间状态变量是 MapType。
Step 2:维护 AggregateFunction.java
在 AggregateFunction.java?文件中,注册 FunctionSet.MAP_AGG,具体如下:
public static ImmutableSet<String> NOT_NULLABLE_AGGREGATE_FUNCTION_NAME_SET = ImmutableSet.of("row_number", "rank",
"dense_rank", "multi_distinct_count", "multi_distinct_sum", FunctionSet.HLL_UNION_AGG,
FunctionSet.HLL_UNION, FunctionSet.HLL_RAW_AGG, FunctionSet.BITMAP_UNION, FunctionSet.BITMAP_INTERSECT,
FunctionSet.ORTHOGONAL_BITMAP_INTERSECT, FunctionSet.ORTHOGONAL_BITMAP_INTERSECT_COUNT,
FunctionSet.ORTHOGONAL_BITMAP_EXPR_CALCULATE_COUNT, FunctionSet.ORTHOGONAL_BITMAP_EXPR_CALCULATE,
FunctionSet.INTERSECT_COUNT, FunctionSet.ORTHOGONAL_BITMAP_UNION_COUNT,
FunctionSet.COUNT, "approx_count_distinct", "ndv", FunctionSet.BITMAP_UNION_INT,
FunctionSet.BITMAP_UNION_COUNT, "ndv_no_finalize", FunctionSet.WINDOW_FUNNEL, FunctionSet.RETENTION,
FunctionSet.SEQUENCE_MATCH, FunctionSet.SEQUENCE_COUNT, FunctionSet.MAP_AGG);Step 3: 维护 FunctionCallExpr.java?
在 FunctionCallExpr.java 中根据 argumentt 强制设置类型,防止丢失 decimal 类型的 scale。
if (fnName.getFunction().equalsIgnoreCase("map_agg")) {
fn.setReturnType(new MapType(getChild(0).type, getChild(1).type));
} 在 BE 中注册函数
这一步是为了让 AggregateFunctionSimpleFactory 可以根据函数名找到对应的函数,函数的创建通过 factory.register_function_both 实现,相关的改动可以在 aggregate_function_map.cc 中 grep register_aggregate_function_map_agg 看到,比较简单,在此不再赘述。
在 BE 实现函数的计算逻辑
重点是如何描述中间结果以及 AggregateFunctionMapAgg 如何实现 IAggregateFunction的核心接口。
Step 1:转换类型
由于我们最终结果需要返回一系列 map,所以输出类型为 DataTypeMap:
DataTypePtr get_return_type() const override {
/// keys and values column of `ColumnMap` are always nullable.
return std::make_shared<DataTypeMap>(make_nullable(argument_types[0]),
make_nullable(argument_types[1]));
}由于默认的中间状态是 string 类型,如果是 string,需要处理比较复杂的序列化/反序列化操作。
IAggregateFunction::get_serialized_type(){return std::make_shared<DataTypeString>();}所以在 AggregateFunctionMapAgg 重新了序列化/反序列化的中间类型:
[[nodiscard]] MutableColumnPtr create_serialize_column() const override {
return get_return_type()->create_column();
}
[[nodiscard]] DataTypePtr get_serialized_type() const override { return get_return_type(); }Step 2:聚合操作
代码中需要将每行的数据取出来进行对应的聚合计算,具体是通重写 add 函数来实现的:
-
这里表示将第 row_num 行的数据丢给 AggregateFunctionMapAggData 来执行,这里可以看出来需要对 nullable 和非 nullable 的分开处理。
-
在 AggregateFunctionMapAggData 中,将 key 以及 value 分别存储在 _key_column 和 _value_column。由于 key 不为 NULL,所以执行了 remove_nullable;由于 value 允许为 NULL,这里执行了 make_nullable,并通过 _map 来过滤了重复的 key。
具体的代码实现如下:
void AggregateFunctionMapAgg::add(AggregateDataPtr __restrict place, const IColumn columns, size_t row_num,
Arena* arena) const override {
if (columns[0]->is_nullable()) {
auto& nullable_col = assert_cast<const ColumnNullable&>(*columns[0]);
auto& nullable_map = nullable_col.get_null_map_data();
if (nullable_map[row_num]) {
return;
}
Field value;
columns[1]->get(row_num, value);
this->data(place).add(
assert_cast<const KeyColumnType&>(nullable_col.get_nested_column())
.get_data_at(row_num),
value);
} else {
Field value;
columns[1]->get(row_num, value);
this->data(place).add(
assert_cast<const KeyColumnType&>(*columns[0]).get_data_at(row_num), value);
}
}
AggregateFunctionMapAggData::add(const StringRef& key, const Field& value){
DCHECK(key.data != nullptr);
if (UNLIKELY(_map.find(key) != _map.end())) {
return;
}
ArenaKeyHolder key_holder {key, _arena};
if (key.size > 0) {
key_holder_persist_key(key_holder);
}
_map.emplace(key_holder.key, _key_column->size());
_key_column->insert_data(key_holder.key.data, key_holder.key.size);
_value_column->insert(value);
}Step 3:序列化/反序列化
由于中间传输的是 ColumnMap 类型,所以只需进行数据拷贝即可
void deserialize_from_column(AggregateDataPtr places, const IColumn& column, Arena* arena,
size_t num_rows) const override {
auto& col = assert_cast<const ColumnMap&>(column);
auto* data = &(this->data(places));
for (size_t i = 0; i != num_rows; ++i) {
auto map = doris::vectorized::get<Map>(col[i]);
data->add(map[0], map[1]);
}
}
void serialize_to_column(const std::vector<AggregateDataPtr>& places, size_t offset,
MutableColumnPtr& dst, const size_t num_rows) const override {
for (size_t i = 0; i != num_rows; ++i) {
Data& data_ = this->data(places[i] + offset);
data_.insert_result_into(*dst);
}
}Step 4:输出结果
insert_result_into 表示最终的返回,所以里面转换的类型要跟 return_type 里面的一致,所以可以看到我们将类型转换为 ColumnMap 进行处理。
void AggregateFunctionMapAgg::insert_result_into(ConstAggregateDataPtr __restrict place, IColumn& to) const override {
this->data(place).insert_result_into(to);
}
void AggregateFunctionMapAggData::insert_result_into(IColumn& to) const {
auto& dst = assert_cast<ColumnMap&>(to);
size_t num_rows = _key_column->size();
auto& offsets = dst.get_offsets();
auto& dst_key_column = assert_cast<ColumnNullable&>(dst.get_keys());
dst_key_column.get_null_map_data().resize_fill(dst_key_column.get_null_map_data().size() +
num_rows);
dst_key_column.get_nested_column().insert_range_from(*_key_column, 0, num_rows);
dst.get_values().insert_range_from(*_value_column, 0, num_rows);
if (offsets.size() == 0) {
offsets.push_back(num_rows);
} else {
offsets.push_back(offsets.back() + num_rows);
}
}Step 5:维护测试用例及文档
这块比较简单,可以参考官方文档 回归测试 - Apache Doris
array_agg 源码解析
笔者通过阅读 mag_agg? 源码以及社区大佬 @mrhhsg 的答疑解惑,为 Apache Doris 增加了 array_agg 函数支持。下文笔者将从 SQL 执行的角度阐述上文提到的函数执行流程及调用栈,具体代码可以阅读:?[feature](agg) add the aggregation function 'array_agg' by xingyingone · Pull Request #23474 · apache/doris · GitHub
array_agg 使用介绍
语法:ARRAY_AGG(col)
功能:将一列中的值(包括空值 null)串联成一个数组,可以用于多行转一行(行转列)。
需要注意点:
-
数组中元素不保证顺序;
-
返回转换生成的数组,数组中的元素类型与 col类型一致;
-
需要显示NULL
实验 SQL 如下:
CREATE TABLE `test_array_agg` (
`id` int(11) NOT NULL,
`label_name` varchar(32) default null,
`value_field` string default null,
) ENGINE=OLAP
DUPLICATE KEY(`id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"storage_format" = "V2",
"light_schema_change" = "true",
"disable_auto_compaction" = "false",
"enable_single_replica_compaction" = "false"
);
insert into `test_array_agg` values
(1, "alex",NULL),
(1, "LB", "V1_2"),
(1, "LC", "V1_3"),
(2, "LA", "V2_1"),
(2, "LB", "V2_2"),
(2, "LC", "V2_3"),
(3, "LA", "V3_1"),
(3, NULL, NULL),
(3, "LC", "V3_3"),
(4, "LA", "V4_1"),
(4, "LB", "V4_2"),
(4, "LC", "V4_3"),
(5, "LA", "V5_1"),
(5, "LB", "V5_2"),
(5, "LC", "V5_3");执行流程
group by + 多阶段聚合
mysql> SELECT label_name, array_agg(label_name) FROM test_array_agg GROUP BY label_name;
+------------+--------------------------------+
| label_name | array_agg(`label_name`) |
+------------+--------------------------------+
| LC | ["LC", "LC", "LC", "LC", "LC"] |
| NULL | [NULL] |
| alex | ["alex"] |
| LB | ["LB", "LB", "LB", "LB"] |
| LA | ["LA", "LA", "LA", "LA"] |
+------------+--------------------------------+
5 rows in set (11.55 sec)
#执行
AggregationNode::_pre_agg_with_serialized_key-->add(执行15次,每次处理一行)
+
AggregationNode::_merge_with_serialized_key->deserialize_and_merge_vec(执行5次,每次merge一个分组)
#取结果
_serialize_with_serialized_key_result-->serialize_to_column 执行一次,处理5个分组
_get_with_serialized_key_result-->insert_result_info 5次,每次处理一个分组group by + 一阶段聚合
mysql> SELECT id, array_agg(label_name) FROM test_array_agg GROUP BY id;
+------+-------------------------+
| id | array_agg(`label_name`) |
+------+-------------------------+
| 1 | ["LC", "LB", "alex"] |
| 2 | ["LC", "LB", "LA"] |
| 3 | ["LC", NULL, "LA"] |
| 4 | ["LC", "LB", "LA"] |
| 5 | ["LC", "LB", "LA"] |
+------+-------------------------+
5 rows in set (20.12 sec)
#执行
AggregationNode::_execute_with_serialized_key-->add(执行15次,每次处理一行)
#取结果
_get_with_serialized_key_result-->insert_result_info 一次循环,遍历处理5个分组
无group by + 多阶段聚合
mysql> SELECT array_agg(label_name) FROM test_array_agg;
+----------------------------------------------------------------------------------------------+
| array_agg(`label_name`) |
+----------------------------------------------------------------------------------------------+
| ["LC", "LB", "alex", "LC", "LB", "LA", "LC", NULL, "LA", "LC", "LB", "LA", "LC", "LB", "LA"] |
+----------------------------------------------------------------------------------------------+
1 row in set (1 min 21.01 sec)
#执行
AggregationNode::_execute_without_key-->add(执行15次,每次处理一行)
AggregationNode::_merge_without_key-->deserialize_and_merge_from_column(执行一次,只有一个分组,这个分组有15个元素)
#取结果
AggregationNode::_serialize_without_key-->serialize_without_key_to_column
AggregationNode::_get_without_key_result-->AggregateFunctionCollect::insert_result_into (执行一次,只有一个分组,这个分组有15个元素)函数调用栈
AggregationNode::init
|--> //初始化_aggregate_evaluators
|--> _aggregate_evaluators.reserve(tnode.agg_node.aggregate_functions.size());
|--> //begin loop
|--> for (int i = 0; i < tnode.agg_node.aggregate_functions.size(); ++i)
|--> //为每个聚合函数生成一个evaluator
|--> AggFnEvaluator::create(&evaluator)
| |--> agg_fn_evaluator->_input_exprs_ctxs.push_back(ctx);
|--> //将每个聚合函数的evaluator加到vector
|--> _aggregate_evaluators.push_back(evaluator);
|--> //end loop
AggregationNode::prepare
|--> ExecNode::prepare
|--> AggregationNode::prepare_profile
| |--> //begin loop
| |--> for (int i = 0; i < _aggregate_evaluators.size(); ++i, ++j)
| |--> //具体到某一个聚合函数
| |--> _aggregate_evaluators[i]->prepare()
| | |--> //初始化group by信息
| | |--> VExpr::prepare()
| | |--> //初始化
| | |--> AggFnEvaluator::prepare
| | | |--> //经过一些工厂函数的处理,最终调用到具体的聚合函数的创建
| | | |--> create_aggregate_function_collect
| | | | |--> create_agg_function_map_agg<String>(argument_types, result_is_nullable)
| | | | | |--> //构造函数
| | | | | |--> AggregateFunctionCollect(const DataTypes& argument_types_)
| |--> //end loop
| |--> //bind各种函数
//调用AggregationNode::sink函数对输入block进行聚合,该步骤会使用前面分配的execute函数进行处理。
AggregationNode::sink
|--> //in_block->rows()=15,就是数据的行数
|--> _executor.execute(in_block)
| |--> //group by+分桶id(一阶段聚合))即可触发
| |--> //SELECT id, array_agg(label_name) FROM test_array_agg GROUP BY id;
| |--> AggregationNode::_execute_with_serialized_key
| | |--> AggregationNode::_execute_with_serialized_key_helper
| | | |--> //这个时候num_rows就是所有记录的行数
| | | |--> //但是这里循环了5次,因为有5个分组需要创建5个AggregateFunctionArrayAggData对象
| | | |--> AggregationNode::_emplace_into_hash_table
| | | | |--> PHHashMap<unsigned int, char*, HashCRC32<unsigned int>, false>::lazy_emplace_keys
| | | | | |--> //开始遍历所有的数据(keys.size()=15行)
| | | | | |--> for (size_t i = 0; i < keys.size(); i++)
| | | | | |--> _hash_map.lazy_emplace_with_hash(keys[i], hash_values[i]..)
| | | | | | |--> //key不重复才会往下走,所以一共执行了5次AggregateFunctionMapAggData
| | | | | | |--> creator-->AggregationNode::_create_agg_status
| | | | | | | |--> AggregationNode::_create_agg_status
| | | | | | | | |--> AggFnEvaluator::create
| | | | | | | | | |--> AggregateFunctionCollect::create
| | | | | | | | | | |--> //调用构造函数
| | | | | | | | | | |--> AggregateFunctionArrayAggData()
| | | | | |--> //结束遍历
| | | |--> //begin loop
| | | |--> for (int i = 0; i < _aggregate_evaluators.size(); ++i)
| | | |--> //传入block,此时block有15行
| | | |--> _aggregate_evaluators[i]->execute_batch_add | AggFnEvaluator::execute_batch_add
| | | | |--> //block->rows()=17 offset=0 _agg_columns.data()有两列
| | | | |--> IAggregateFunctionHelper::add_batch
| | | | |--> //begin loop
| | | | |--> //batch_size=15,执行15次add
| | | | |--> for (size_t i = 0; i < batch_size; ++i)
| | | | |--> AggregateFunctionCollect::add()
| | | | |--> //end loop
| | | |--> //end loop
| |
| |--> //不带group by+一阶段聚合
| |--> AggregationNode::_execute_without_key
| | |--> AggFnEvaluator::execute_single_add
| | | |--> IAggregateFunctionHelper::add_batch_single_place
| | | |--> /*begin loop*/
| | | |--> //执行15次
| | | |--> for (size_t i = 0; i < batch_size; ++i)
| | | |--> AggregateFunctionCollect::add()
| | | |--> //end loop
| |--> //group by+多阶段聚合
| |--> AggregationNode::_merge_with_serialized_key
| | |--> AggregateFunctionCollect::deserialize_and_merge_vec
| |-->//无group by + 多阶段聚合
| |-->//SELECT array_agg(label_name) FROM test_array_agg ;
| |--> AggregationNode::_merge_without_key
| | |--> AggregateFunctionCollect::deserialize_and_merge_from_column
| |--> AggregationNode::_pre_agg_with_serialized_key
| | |--> //如果聚合效果不佳,hash扩容达到阈值,则跳过聚合,直接把每一行输入当作一个分组
| | |--> AggregateFunctionCollect::streaming_agg_serialize_to_column
| | |--> //如果hash扩容没到阈值,还是采用朴素的方法
| | |--> AggFnEvaluator::execute_batch_add
| | | |--> //执行15次
| | | |--> for (size_t i = 0; i < batch_size; ++i)
| | | |--> AggregateFunctionCollect::add()
| | | |--> //end loop
AggregationNode::pull
|--> //group by + 且需要finalize
|--> //SELECT id, array_agg(label_name) FROM test_array_agg GROUP BY id;
|--> AggregationNode::_get_with_serialized_key_result
| |--> AggregationNode::_get_result_with_serialized_key_non_spill
| | |--> //从block里面拿key的列,也就是group by的列
| | |--> key_columns.emplace_back
| | |--> //从block里面拿value的列
| | |--> value_columns.emplace_back
| | |--> //如果是一阶段聚合:这个时候num_rows=5,代表有5个分组
| | |--> //SELECT id, array_agg(label_name) FROM test_array_agg GROUP BY id;
| | |--> //如果是多阶段聚合:这个时候num_rows=1,需要在上层调用5次
| | |--> //SELECT label_name, array_agg(label_name) FROM test_array_agg GROUP BY label_name;
| | |--> AggFnEvaluator::insert_result_info(num_rows)
| | | |--> for (size_t i = 0; i != num_rows; ++i)
| | | |--> IAggregateFunctionHelper::insert_result_into
| | | | |--> AggregateFunctionCollect::insert_result_into
| | | | | |--> AggregateFunctionArrayAggData::insert_result_into
| | | |--> //循环结束
|--> //没有group by 且不需要finalize
|--> AggregationNode::_serialize_without_key
| |--> AggregateFunctionCollect::create_serialize_column
| |--> AggregateFunctionCollect::serialize_without_key_to_column
| | |--> AggregateFunctionArrayAggData::insert_result_into
|--> //没有group by 且需要finalize
|--> AggregationNode::_get_without_key_result
| |--> AggregateFunctionCollect::insert_result_into
| | |--> AggregateFunctionArrayAggData::insert_result_into
|--> //group by + 且不需要finalize
|--> AggregationNode::_serialize_with_serialized_key_result
| |--> AggregationNode::_serialize_with_serialized_key_result_non_spill
| | |--> //num_rows=5, 处理5个分组
| | |--> AggregateFunctionCollect::serialize_to_column(num_rows)
| | | |--> AggregateFunctionArrayAggData::insert_result_into注意点:
-
如果是两阶段聚合,在 execute 阶段必然会执行 execute+merge,即在会分别绑定 _merge_with 和 _execute_with,但是一阶段聚合只会绑定 _execute_with;
-
如果是两阶段聚合,在 get_result 阶段会有多个 AggregationNode,会根据具体的情况判断是否 _needs_finalize;一阶段聚合只有一个 AggregationNode,会绑定 _needs_finalize。
总结
最近由于工作需要笔者开始调研和使用 Apache Doris,通过阅读聚合函数代码切入 Apache Doris 内核。秉承着开源的精神,开发了 array_agg 函数并贡献给社区。希望通过这篇文章记录下对源码的一些理解,同时也方便后面的新人更快速地上手源码开发。
在学习和掌握 Apache Doris 的过程中,作为 OLAP 新人的笔者遇到了很多疑惑点。好在 Apache Doris 不仅功能强大,社区更是十分活跃,社区技术大佬们对于新人的问题也特别热心,不厌其烦帮我们新人们答疑解惑,这无疑为笔者在调研过程中增加了不少信心,在此由衷地感谢社区大佬 @yiguolei @mrhhsg。也期待未来有更多的小伙伴可以参与到社区当中来,一同学习与成长。
作者介绍
隐形(邢颖) 网易资深数据库内核工程师,毕业至今一直从事数据库内核开发工作,目前主要参与 MySQL 与 Apache Doris 的开发维护和业务支持工作。
作为 MySQL 内核贡献者,为 MySQL 上报了 50 多个 Bug 及优化项,多个提交被合入 MySQL 8.0 版本。从 2023 年起加入 Apache Doris 社区,Apache Doris Active Contributor,已为社区提交并合入数十个 Commits。
参考链接:
[1]https://zhuanlan.zhihu.com/p/614555403
[2]https://www.slidestalk.com/doris.apache/Doris22141
[3]https://github.com/apache/doris/blob/master/be/src/vec/aggregate_functions/aggregate_function_avg.h
[4]https://doris.apache.org/zh-CN/docs/1.2/benchmark/tpch/
[5]https://github.com/apache/doris/pull/22043
[6]https://github.com/apache/doris/blob/master/fe/fe-core/src/main/java/org/apache/doris/catalog/FunctionSet.java
[7]https://github.com/apache/doris/blob/master/fe/fe-core/src/main/java/org/apache/doris/catalog/AggregateFunction.java
[8]https://github.com/apache/doris/blob/master/fe/fe-core/src/main/java/org/apache/doris/analysis/FunctionCallExpr.java
[9]https://github.com/xingyingone/doris/blob/b41fcbb7834bf89f9744d351b1cfb9ac2485008b/be/src/vec/aggregate_functions/aggregate_function_map.cpp
[10]https://doris.apache.org/zh-CN/community/developer-guide/regression-testing/
[11]https://github.com/apache/doris/pull/22043/files
[12]https://github.com/apache/doris/pull/23474/files
[13]https://bugs.mysql.com/search.php?cmd=display&status=All&severity=all&reporter=15843759
[14]https://github.com/apache/doris/commits/master/?author=xingyingone
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!