AQI分析与预测
背景信息
AQI(Air Quality Index),指空气质量指数,用来衡量空气清洁或污染的程度。值越小,表示空气质量越好。近年来,因为环境问题,空气质量也越来越受到人们的重视。
任务说明
我们期望能够对全国城市空气质量进行研究与分析,希望能够解决如下疑问:
- 哪些城市的空气质量较好/较差?
- 临海城市是否空气质量优于内陆城市?
- 空气质量主要受哪些因素影响?
- 是否可以预测城市的空气质量?
- 是否可以预测城市是否临海?
数据集描述
我们现在获取了2015年空气质量指数集。该数据集包含全国主要城市的相关数据以及空气质量指数。
| 列名 | 含义 |
|---|---|
| City | 城市名 |
| AQI | 空气质量指数 |
| Precipitation | 降雨量 |
| GDP | 城市生产总值 |
| Temperature | 温度 |
| Longitude | 经度 |
| Latitude | 纬度 |
| Altitude | 海拔高度 |
| PopulationDensity | 人口密度 |
| Coastal | 是否沿海 |
| GreenCoverageRate | 绿化覆盖率 |
| Incineration(10,000ton) | 焚烧量(10000吨) |
下载数据集 CompletedDataset.csv,
链接:https://pan.baidu.com/s/1liv0ew268cy4JMutdAgpFQ?pwd=ssmi
提取码:ssmi
导入相关的库
导入需要的库,同时,进行一些初始化的设置。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import warnings
import seaborn as sns
sns.set(style="darkgrid", font="SimHei", rc={
"axes.unicode_minus":False})
warnings.filterwarnings("ignore")
加载数据集
加载相关的数据集。
可以使用head / tail / sample查看数据的大致情况。
data = pd.read_csv("CompletedDataset.csv")
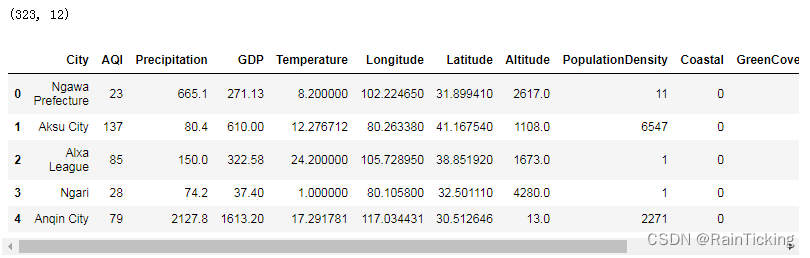
print(data.shape)
data.head()
数据清洗
缺失值处理
data.info()
# data.isnull().sum(axis=0)

异常值处理
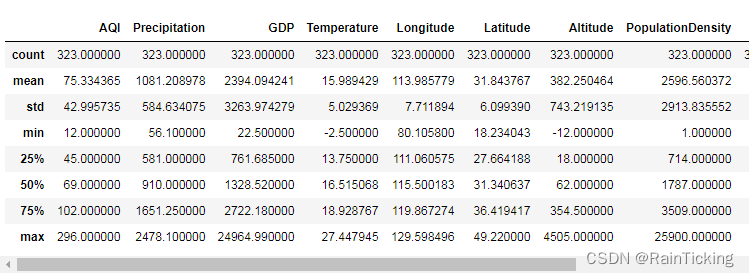
data.describe()
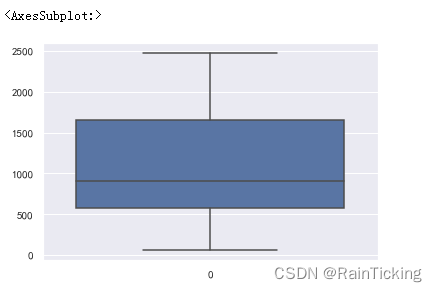
sns.boxplot(data=data['Precipitation'])
重复值处理
- 使用duplicate检查重复值。可配合keep参数进行调整。
- 使用drop_duplicate删除重复值
data.duplicated().sum()
0
空气质量最好 / 最差的5个城市。
空气质量的好坏可以为我们以后选择工作,旅游等地提供参考。
最好的5个城市
t = data[["City", "AQI"]].sort_values("AQI")
display(t.iloc[:5])
sns.barplot(x="City", y="AQI", data=t.iloc[:5])
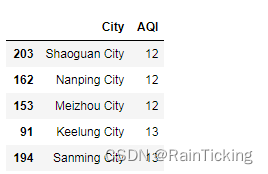
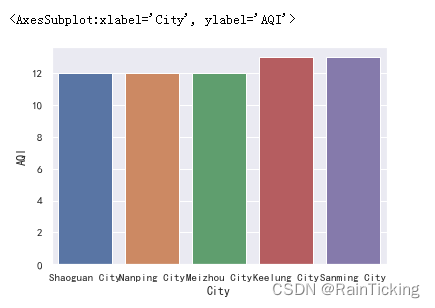
我们发现,空气质量最好的5个城市为:
1.韶关市
2.南平市
3.梅州市
4.基隆市
5.三明市
最差的5个城市
display(t.iloc[-5:])
sns.barplot(x="City", y="AQI", data=t.iloc[-5:])
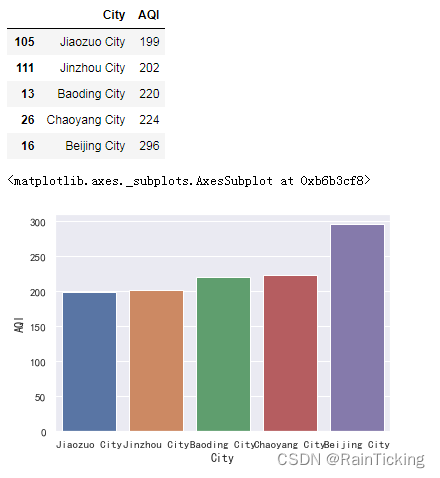
我们得出空气质量最差的5个城市为:
1.北京市
2.朝阳市
3.保定市
4.锦州市
5.焦作市
临海城市是否空气质量优于内陆城市?
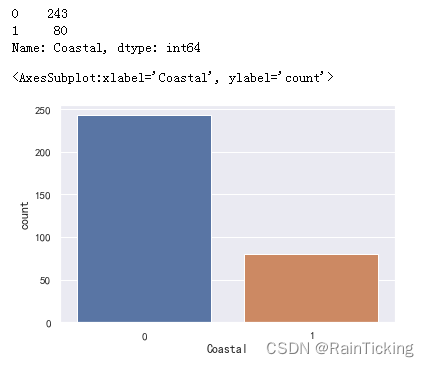
我们首先来统计下临海城市与内陆城市的数量。
display(data["Coastal"].value_counts())
sns.countplot(x="Coastal", data=data)
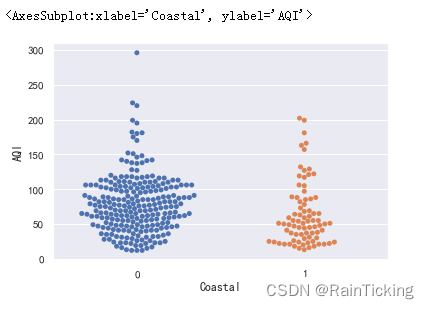
然后,我们来观察一下临海城市与内陆城市的散点分布。
sns.swarmplot(x="Coastal", y="AQI", data=data)
然后,我们再来分组计算空气质量的均值。
display(data.groupby("Coastal")["AQI"].mean())
sns.barplot(x="Coastal", y="AQI", data=data)
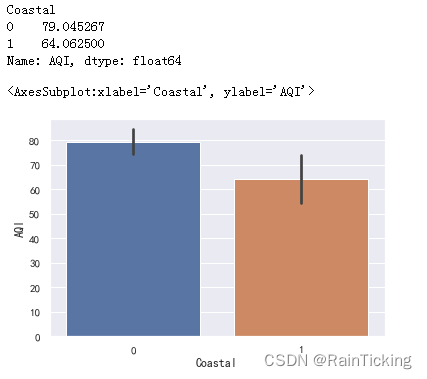
柱形图仅能进行均值对比,我们可以使用箱线图来显示更多的信息。
sns.boxplot(x="Coastal", y="AQI", data=data)
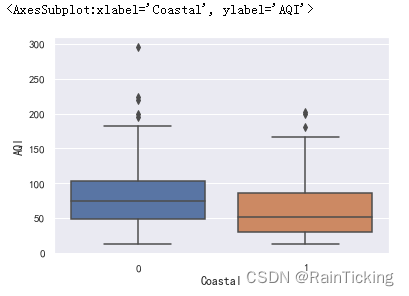
我们也可以绘制小提琴图,除了能够展示箱线图的信息外,还能呈现出分布的密度。
sns.violinplot(x="Coastal", y="AQI", data=data)
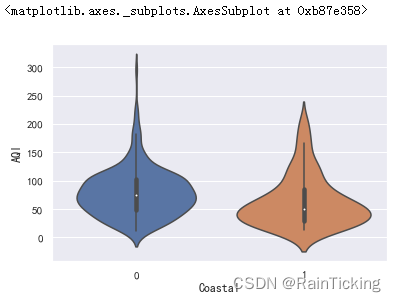
我们可以将散点与箱线图或小提琴图结合在一起进行绘制,下面以小提琴图为例。
sns.violinplot(x="Coastal", y="AQI", data=data, inner=None)
sns.swarmplot(x="Coastal", y="AQI", data=data, color="g")
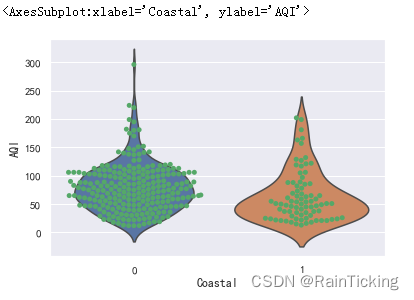
空气质量主要受哪些因素影响?
相关系数
# data.corr()
plt.figure(figsize=(10,10))
sns.heatmap(data.corr(), cmap=plt.cm.RdYlGn, annot=True, fmt=".2f")
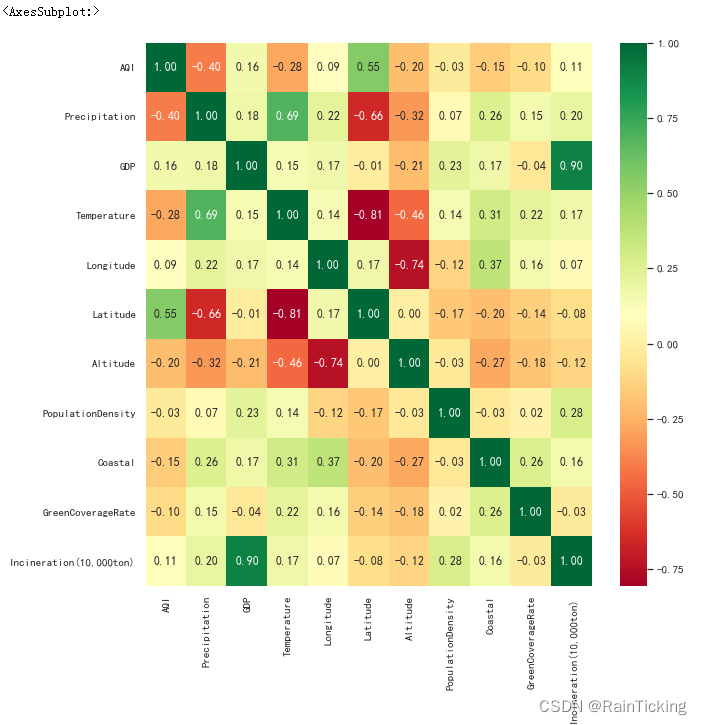
从结果中可知,空气质量指数主要受降雨量(-0.40)与纬度(0.55)影响。
- 降雨量越多,空气质量越好。
- 纬度越低,空气质量越好。
此外,我们还能够发现其他一些明显的细节:
- GDP(城市生产总值)与Incineration(焚烧量)正相关(0.90)。
- Temperature(温度)与Precipitation(降雨量)正相关(0.69)。
- Temperature(温度)与Latitude(纬度)负相关(-0.81)。
- Longitude(经度)与Altitude(海拔)负相关(-0.74)。
- Latitude(纬度)与Precipitation(降雨量)负相关(-0.66)。
- Temperature(温度)与Altitude(海拔)负相关(-0.46)。
- Altitude(海拔)与Precipitation(降雨量)负相关(-0.32)。
绘制全国城市的空气质量。
我们来绘制一下全国各城市的空气质量指数。
sns.scatterplot(x="Longitude", y="Latitude", hue="AQI", palette=plt.cm.RdYlGn_r, data=data)
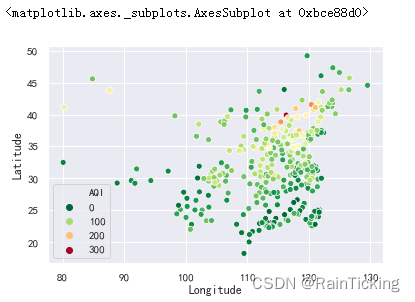
从结果我们可以发现,从大致的地理位置上看,西部城市好于东部城市,南部城市好于北部城市。
关于空气质量的假设检验
江湖传闻,全国所有城市的空气质量指数均值在71左右,请问,这个消息可靠吗?
问题下的探索
城市平均空气质量指数,我们可以很容易的进行计算
data["AQI"].mean()
75.3343653250774
首先,我们要清楚,江湖传闻的,是全国所有城市的平均空气质量指数,而我们统计的,只是所有城市中的一部分抽样而已。因此,我们一次抽样统计的均值,并不能代表总体(所有城市)的均值。
要弄清江湖传闻是否可靠,最直接有效的方式,就是将全国所有的城市的空气质量指数都测量一下,然后进行求均值。然而,这是非常繁重且不现实的任务。因此,可行的方案是,我们从全国所有城市中进行抽样,使用抽样的均值来估计总体的均值
总体与样本的分布
在数学上,我们有如下的定理:
如果总体(分布不重要)均值为 μ \mu μ,方差为 σ 2 \sigma^2 σ2,则样本均值服从正态分布: X ˉ \bar{X} Xˉ ~ N ( μ , σ 2 / n ) N(\mu, \sigma^2 / n) N(μ,σ
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!