【代数学作业1-python实现GNFS一般数域筛】构造特定的整系数不可约多项式:涉及素数、模运算和优化问题
代数学作业1-完整版:python实现GNFS一般数域筛
- 写在最前面
- 背景
- 在GNFS算法中选择互质多项式时,需要考虑哪些关键因素,它们对算法的整体运行时间有何影响?
- 练习1题目
- 题目分析
- Kleinjung方法简介
- 通用数域筛法(GNFS)中的多项式选择:筛选及其根属性
- 步骤规划
- 解决
- 1. 构造满足条件的多项式 g ( x ) g(x) g(x) 和 f ( x ) f(x) f(x)
- 实现+代码优化
- 2.计算m
- 构造多项式 g ( x ) g(x) g(x)
- 得到解集
- 求解m
- 3. 计算多项式系数 a 3 a_3 a3?, a 2 a_2 a2?, a 1 a_1 a1?和 a 0 a_0 a0?,生成多项式
- 构造多项式 f ( x ) f(x) f(x)
- 代码实现
- 如果报错:`ValueError: base is not invertible for the given modulus`
- 4. 计算 COUNT 并选择最优的 A/B
- 代码实现
- 最大化收益率
- 计算 COUNT 和优化 A/B
写在最前面

这门课有点意思,作业更有意思
在这篇博客中,我们将探讨如何使用 Python 与数论知识来解决一个有趣的数学问题,目标是构造两个整系数不可约多项式 g ( x ) g(x) g(x) 和 f ( x ) f(x) f(x),满足特定的模 n n n 条件。
完整版包含全部过程(算法复杂度优化)
大整数分解是公钥密码学中一个非常重要的计算问题。用数域筛法(GNFS) 是对大整数进行因式分解的渐近最快算法。
它的运行时间取决于多项式对的良好选择。多项式选择是GNFS的第一步,也是非常关键的一步。
这个方向的未来工作包括对更大的N进行实验,并测试其他基于启发式的技术来选择好的多项式。
参考:
【论文】
用于整数分解的数场筛中的多项式选择
Polynomial selection in number field sieve for integer factorization
一般数域筛选的多项式选择
ON POLYNOMIAL SELECTION FOR THE GENERAL NUMBER FIELD SIEVE
【github】
MSIEVE:用于分解大整数的库
MSIEVE: A Library for Factoring Large Integers
背景
公钥密码学在现代通信网络中起着重要作用。许多公钥密码系统的安全性取决于某些数论问题的棘手性。对大整数进行因式分解和在高阶循环群中求离散对数是最受欢迎的数论问题。
RSA(Rivest et al., 1978)是一种广泛使用的公钥密码系统,其安全性依赖于大整数分解的难度。RSA 由两个密钥组成:公钥 ( N , e ) (N, e) (N,e) 和私钥 d d d,其中 N N N 是两个不同大小的大素数 p 、 q p、q p、q 的乘积, e e e 是加密密钥, d d d 是解密密钥。 要解密加密消息,我们需要找到私钥 d d d,它等价于对模数 N N N 进行因式分解。
一般数域筛(GNFS)(Lenstra和Lenstra,1993)是已知最有效的确定因子的算法 p , q p,q p,q 这样的整数 N N N。GNFS方法包括五个主要步骤:多项式选择、因子基生成、筛分、矩阵步长和平方根计算。
在GNFS算法中选择互质多项式时,需要考虑哪些关键因素,它们对算法的整体运行时间有何影响?

在为GNFS算法选择互质多项式时,需要考虑几个关键因素,因为它们直接影响算法的整体运行时间。
-
根属性:多项式的选择应以最大化小素数模多项式的根属性为目标。这涉及到考虑前导系数及其对可用前导系数数量的影响,以及多项式中质因数的数量,这些因素会影响算法某些步骤的速度。
-
初始化时间:对于小度数来说,在某些步骤的初始化上花费了大量的时间。考虑 p = p 0 ∏ i = 1 l p i p = p_0 \prod_{i=1}^{l} p_i p=p0?∏i=1l?pi?形式的公式,其中 p 0 p_0 p0? 是一个数字(不一定是质数),可以帮助减少初始化成本的百分比并优化过程。
-
可接受的值:对于非常大的整数,多项式的前导系数可接受的值的数量可能非常大。重要的是要考虑减小超范数界的方法,从而缩小可容许区间,同时仍然保证存在合适的多项式。这涉及到选择特定的可接受值,并可能限制搜索区间。
-
Sieve报告:筛选过程的效率对算法的整体运行时间至关重要。筛分报告的数量受多项式的选择影响,筛分报告是一对互质整数,其齐次多项式的两个值都是低于一定光滑界的素数的乘积。筛选时间主要取决于筛选区域的大小,多项式对的选择应以最小化筛选时间为目标。
-
偏度和偏上范数:多项式的偏度和偏上范数对算法的效率有很大的影响。多项式的选择应满足偏度、斜上范数和根属性等条件,这些条件是算法成功的关键。
练习1题目

练习一
给定如下 3 个已知条件:
- n = 1234268228312430759578090015472355712114804731217710966738223 ; n=1234268228312430759578090015472355712114804731217710966738223; n=1234268228312430759578090015472355712114804731217710966738223;
- 正整数 A、B 的乘积 A B = 1 0 6 ; AB=10^6; AB=106;
- 素数基 S S S 为 1 0 5 10^5 105 以内的所有素数。
试构造整系数不可约多项式
g
(
x
)
g(x)
g(x) 和
f
(
x
)
f(x)
f(x) ,其中
{
g
(
x
)
=
m
1
x
?
m
0
f
(
x
)
=
c
4
x
4
+
c
3
x
3
+
c
2
x
2
+
c
1
x
+
c
0
\left\{ \begin{matrix} g(x)=m_1x-m_0\\ f(x)=c_4x^4+c_3x^3+c_2x^2+c_1x+c_0 \end{matrix} \right.
{g(x)=m1?x?m0?f(x)=c4?x4+c3?x3+c2?x2+c1?x+c0??
满足
m
1
4
f
(
m
0
m
1
)
≡
0
(
m
o
d
n
)
.
m_1^4f\left(\frac{m_0}{m_1}\right) \equiv 0 \pmod{n} .
m14?f(m1?m0??)≡0(modn).
记 ( a , b ) ∈ [ ? A , A ] × [ 1 , B ] ∣ b 4 f ( a b ) (a,b) \in [-A,A] \times [1, B] | b^4f\left(\frac{a}{b}\right) (a,b)∈[?A,A]×[1,B]∣b4f(ba?), b g ( a b ) bg\left(\frac{a}{b}\right) bg(ba?) 均在 S S S 上平滑 为实验过程中找到的可使 b 4 f ( a b ) b^4f\left(\frac{a}{b}\right) b4f(ba?), b g ( a b ) bg\left(\frac{a}{b}\right) bg(ba?) 均在 S S S 上平滑的点对 ( a , b ) (a,b) (a,b) 的集合,总数为 C O U N T COUNT COUNT,通过调整 A A A、 B B B、 m 1 m_1 m1?、 m 0 m_0 m0?、 c 4 c_4 c4?、 c 3 c_3 c3?、 c 2 c_2 c2?、 c 1 c_1 c1?、 c 0 c_0 c0?,使 C O U N T COUNT COUNT 尽可能大,观察并简要分析:
- 设 s k e w = A B skew =\frac{A}{B} skew=BA?, s k e w skew skew 是否对 C O U N T COUNT COUNT 产生影响。
- 系数 c 4 c_4 c4? 的选取方式是否对 C O U N T COUNT COUNT 产生影响。
要求给出所设计的多项式 g ( x ) g(x) g(x)、 f ( x ) f(x) f(x) 以及 A A A、 B B B、 C O U N T COUNT COUNT 的值。
题目分析
给定一个大整数 n n n,需要构造两个多项式 g ( x ) g(x) g(x) 和 f ( x ) f(x) f(x),使得它们在模 n n n 意义下的计算结果能够在素数基 S S S 上平滑。平滑性意味着计算结果可以被 S S S 中的素数完全分解。
Kleinjung方法简介
Kleinjung方法是一种用于大整数分解的高效算法。它基于数域筛选算法(Number Field Sieve, NFS),是当前解决大整数分解问题最快的已知方法之一。
Kleinjung方法的核心思想是:在两个不同的数域中寻找平滑数(即只含有小素因子的数),并利用这些数构建线性方程组,从而分解大整数。
通用数域筛法(GNFS)中的多项式选择:筛选及其根属性
在通用数域筛法(GNFS)的算法实现中,多项式选择方法是一个核心环节。这个过程涉及到识别具有良好根属性的多项式对,是整个因数分解流程中不可或缺的一部分。下面展开说明,论文中关于这一过程中的关键概念和步骤。
- 筛选具有良好根属性的多项式
GNFS 算法中的一个关键步骤是筛选出形式为 f 1 + c f 2 f1 + cf2 f1+cf2 的多项式对,这些多项式对应具有良好的根属性。在这里, f 1 f1 f1 和 f 2 f2 f2 是代数多项式,而 c c c 是一个具有有界系数的小度数多项式。目标是找到当这样组合时,具有有利根属性的多项式对。这些根的特性对于后续的分解步骤至关重要。
- 非首一线性多项式的考虑
论文探讨了非首一线性多项式,特别是形式为
f
2
(
x
)
=
p
x
?
m
f2(x) = px - m
f2(x)=px?m 的多项式,其中
p
p
p 和
m
m
m 是互质整数。这里的目标是找到另一个多项式
f
1
=
∑
i
=
0
d
a
i
x
i
f1 = \sum_{i=0}^{d} a_ix^i
f1=∑i=0d?ai?xi,其次数为
d
d
d,使得
f
1
(
m
p
)
?
p
d
=
N
f1\left( \frac{m}{p} \right) \cdot p^d = N
f1(pm?)?pd=N,其中
N
N
N 是待分解的整数。在满足给定的同余条件
a
d
m
d
≡
N
m
o
d
??
p
admd \equiv N \mod p
admd≡Nmodp 的同时,需要最小化
f
1
f1
f1 的系数。如果这个条件不满足,则不存在合适的多项式
f
1
f1
f1 来满足这些标准。
- 引理 2.1:为满足 GNFS 算法中分解过程要求的多项式的存在性和属性
论文中提出的引理 2.1 提供了关于满足特定条件的多项式 f 1 ( x ) f1(x) f1(x) 存在性的重要结果。它指出,在满足条件 N ≡ a d m d m o d ?? p N \equiv admd \mod p N≡admdmodp且 m ≥ m ~ m \geq \widetilde{m} m≥m 的情况下,存在一个多项式 f 1 ( x ) = ∑ i = 0 d a i x i f1(x) = \sum_{i=0}^{d} a_ix^i f1(x)=∑i=0d?ai?xi 满足以下标准:
- f 1 ( m p ) ? p d = N f1\left( \frac{m}{p} \right) \cdot p^d = N f1(pm?)?pd=N
- ∣ a d ? 1 ∣ < p + d a d m ? m ~ |a_{d-1}| < p + \frac{dad}{m - \widetilde{m}} ∣ad?1?∣<p+m?m dad?
- ∣ a i ∣ < p + m |a_i| < p + m ∣ai?∣<p+m 对于 0 ≤ i ≤ d ? 2 0 \leq i \leq d - 2 0≤i≤d?2
步骤规划
这个问题是关于构造特定的整系数不可约多项式,并且涉及到素数、模运算和优化问题。
如果完全解决这个问题,需要找到所有的点对 ( a , b ) (a,b) (a,b) 的集合,这在计算上非常复杂的,需要借助相关编程软件,如python,segamath。以下是解决问题的一般步骤:
- 生成素数基: 需要生成所有小于 1 0 5 10^5 105 的素数。
- 定义多项式:需要构造满足给定条件的 g ( x ) g(x) g(x) 和 f ( x ) f(x) f(x),使得 m 1 4 f ( m 0 m 1 ) m_1^4f\left(\frac{m_0}{m_1}\right) m14?f(m1?m0??) 在模 n n n 下等于 0。由于是不可约多项式,且系数为整数,需要使用启发式方法或者数学知识来确定合适的系数。
- 寻找平滑数:对于一系列的 ( a , b ) (a, b) (a,b) 值,计算 b 4 f ( a b ) b^4f\left(\frac{a}{b}\right) b4f(ba?) 和 b g ( a b ) bg\left(\frac{a}{b}\right) bg(ba?),检查它们是否在素数基 S S S 上平滑。
- 调整参数:通过调整 A A A、 B B B 以及多项式的系数,寻找使得平滑点对 ( a , b ) (a, b) (a,b) 的总数 C O U N T COUNT COUNT 最大化的情况,从而找到最优的多项式。
- 观察和分析:分析 s k e w skew skew 和 c 4 c_4 c4? 的选取对 C O U N T COUNT COUNT 的影响。
解决
1. 构造满足条件的多项式 g ( x ) g(x) g(x) 和 f ( x ) f(x) f(x)
首先让我们设置数论问题中的基本参数,并筛选出小于 1 0 5 10^5 105 的特定类型(4k+1型)的所有素数。
下一步是构造满足条件的多项式 g ( x ) g(x) g(x) 和 f ( x ) f(x) f(x)。
- 构造两个多项式。根据问题,多项式
g
(
x
)
g(x)
g(x) 和
f
(
x
)
f(x)
f(x) 的形式分别是:
- 线性多项式
g ( x ) = p x ? m g(x) = px - m g(x)=px?m - 四次多项式
f ( x ) = a 4 x 4 + a 3 x 3 + a 2 x 2 + a 1 x + a 0 f(x) = a_4x^4 + a_3x^3 + a_2x^2 + a_1x + a_0 f(x)=a4?x4+a3?x3+a2?x2+a1?x+a0?
- 线性多项式
- 自行选择一个
a
4
a_4
a4?,这个是四次多项式
f
(
x
)
f(x)
f(x) 的最高次项系数。小于
N ^ (1/5)就行,最好小点,不然怕后面跑不动(这里我选择的是1)。 - 生成特定素数 p p p。 p p p 是几个4k+1型小素数的乘积。
- 根据前面 a 4 a_4 a4?的选择,满足条件的小素数 q q q有变化,需要满足下面方程有解: a 4 x 4 ≡ n ( m o d q ) a_4 x^4 \equiv n \pmod{q} a4?x4≡n(modq)
- 最后打印满足条件的素数 q q q ,其乘积形成 m ? 1 m-1 m?1。注意,3到4个 q q q 相乘得到 m ? 1 m-1 m?1 , m ? 1 m-1 m?1 大概7/8/9位数就行。
实现+代码优化
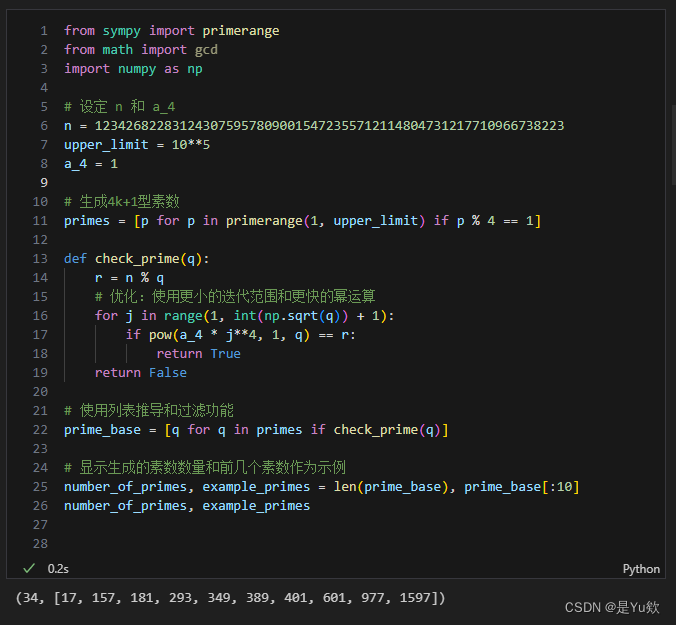
2.计算m
接下来计算 m m m。这个过程的本质是,求解同余式方程 a 4 ? x 4 ≡ N ? m o d ? p a_4 * x^4 ≡ N\ mod\ p a4??x4≡N?mod?p 并由此构建 m 的值。 m m m 分为两部分:
- 第一部分
m
0
m_0
m0?:
- 根据 Kleinjung 算法的要求,先计算 ( N / a 4 ) 1 / 4 (N/a_4)^{1/4} (N/a4?)1/4,接近于 m m m 的理论值。
- 找到最接近此值且能被 p p p 整除的数作为 m 0 m_0 m0?。
- 第二部分: 满足同余方程解的部分。
- 对于组成 p p p 的每个素数 p i p_i pi?,使用之前从同余方程解集中挑选的解,这些解是为了确保 m m m 满足特定的同余条件 a 4 ? x 4 ≡ N ( m o d p i ) a_4 \cdot x^4 \equiv N \pmod{p_i} a4??x4≡N(modpi?)。
- 将这些解相加得到第二部分的值。
- 计算
m
m
m:
- 将第一部分和第二部分的值相加得到最终的 m m m。
构造多项式 g ( x ) g(x) g(x)
这一步骤是为了构造出多项式
g
(
x
)
=
p
x
?
m
g(x) = px - m
g(x)=px?m。
其中,
p
p
p 是选定的素数乘积,
m
m
m 是通过上述方法计算得到的,确保多项式
g
(
x
)
g(x)
g(x) 满足特定的数学和同余条件。
得到解集
我们首先可以构造出多项式 g ( x ) = p x ? m g(x) = px - m g(x)=px?m,其中 p p p 是选定素数的乘积,而 m m m 是通过以上描述的方法计算得到的。
代码逻辑
- 定义变量:设置 n、p(选定的素数集合)、a_4。
- 计算 P P P: P P P 是选定素数的乘积。
- 解集计算:
- 对每个素数 p i p_i pi?,求解同余方程 a 4 ? x 4 ≡ N ( m o d p i ) a_4 \cdot x^4 \equiv N \pmod{p_i} a4??x4≡N(modpi?)。
- 生成每个 p i p_i pi? 的解集。
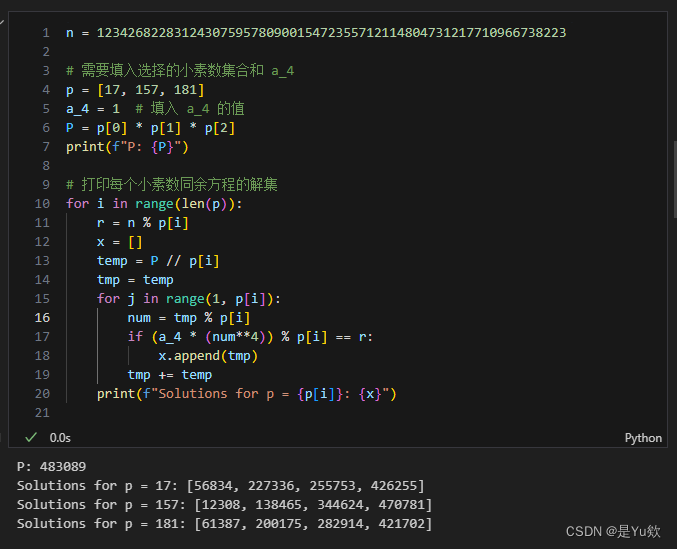
在选择解集中的解时,不同的选择会影响后续多项式低次项系数的确定,特别是 a 3 a_3 a3? 的大小。可以尝试不同的搭配,以使后面的系数尽可能小。
求解m
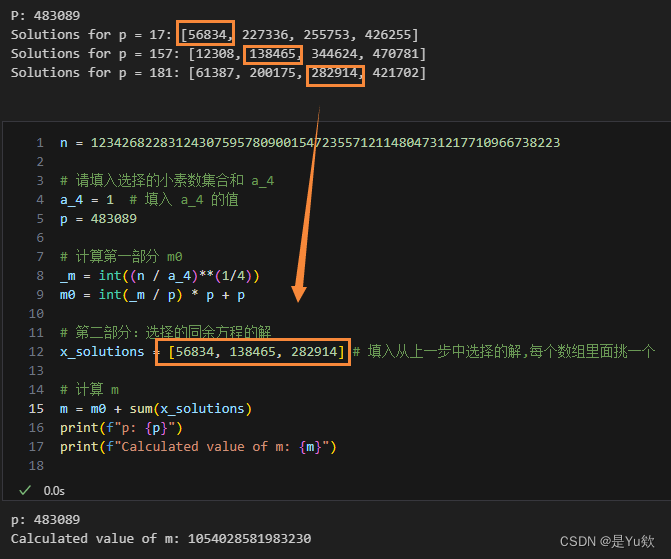
代码逻辑
- 定义变量:设置 n、p(素数的乘积)、a_4。
- 计算 m 0 m_0 m0?:基于 ( N / a 4 ) 1 / 4 (N/a_4)^{1/4} (N/a4?)1/4 计算 m 0 m_0 m0?。
- 确定 x s o l u t i o n s x_{solutions} xsolutions?:这些选择的解是,从上一步中每个数组里面挑一个。
- 最终计算 m m m:将 m 0 m_0 m0? 和 x s o l u t i o n s x_solutions xs?olutions 的和计算出 m m m 的最终值。
3. 计算多项式系数 a 3 a_3 a3?, a 2 a_2 a2?, a 1 a_1 a1?和 a 0 a_0 a0?,生成多项式
确定完a_4,p,m后,生成并验证多项式。
在这一部分,我们将集中于计算多项式 f ( x ) = a 4 x 4 + a 3 x 3 + a 2 x 2 + a 1 x + a 0 f(x) = a_4x^4 + a_3x^3 + a_2x^2 + a_1x + a_0 f(x)=a4?x4+a3?x3+a2?x2+a1?x+a0? 的系数,并验证所得到的多项式是否正确。
构造多项式 f ( x ) f(x) f(x)
以上步骤允许我们计算出多项式 f ( x ) f(x) f(x) 的所有系数,这个多项式将满足题目中所提出的模 n n n 条件。
代码实现
关键逻辑步骤
- 定义变量:设置
n、p、m以及a_4的值。 - 计算中间变量:为了简化系数的计算,首先计算出若干中间变量,如 p 2 p^2 p2、 p 3 p^3 p3、 p 4 p^4 p4、 m 2 m^2 m2、 m 3 m^3 m3、 m 4 m^4 m4。
- 系数的计算:
- 使用模运算和模逆函数(modular inverse)来逐步计算 a 3 a_3 a3?、 a 2 a_2 a2?、 a 1 a_1 a1? 和 a 0 a_0 a0?。
在 Python 中,可以通过使用 pow 函数来计算模逆,其语法为
pow(a, -1, mod),其中 a 是要求逆的数,mod 是模数。
- 每个系数的计算都基于前一步的结果,以及对应的中间变量。
- 计算 a_3:通过模逆和模运算计算 a 3 a_3 a3?。
- 计算 a_2:进一步利用前面的计算结果和模运算计算 a 2 a_2 a2?。
- 计算 a_1:同样基于之前的结果,计算 a 1 a_1 a1?。
- 计算 a_0:最后计算 a 0 a_0 a0?。
- 验证:通过计算 a 4 m 4 + a 3 m 3 p + a 2 m 2 p 2 + a 1 m p 3 + a 0 p 4 a_4m^4 + a_3m^3p + a_2m^2p^2 + a_1mp^3 + a_0p^4 a4?m4+a3?m3p+a2?m2p2+a1?mp3+a0?p4 并与 n n n 对比来验证结果。
- 验证结果:计算多项式 f ( x ) f(x) f(x) 在 x = m x=m x=m 时的值,并与原始的 n n n 进行对比,以验证多项式的正确性。
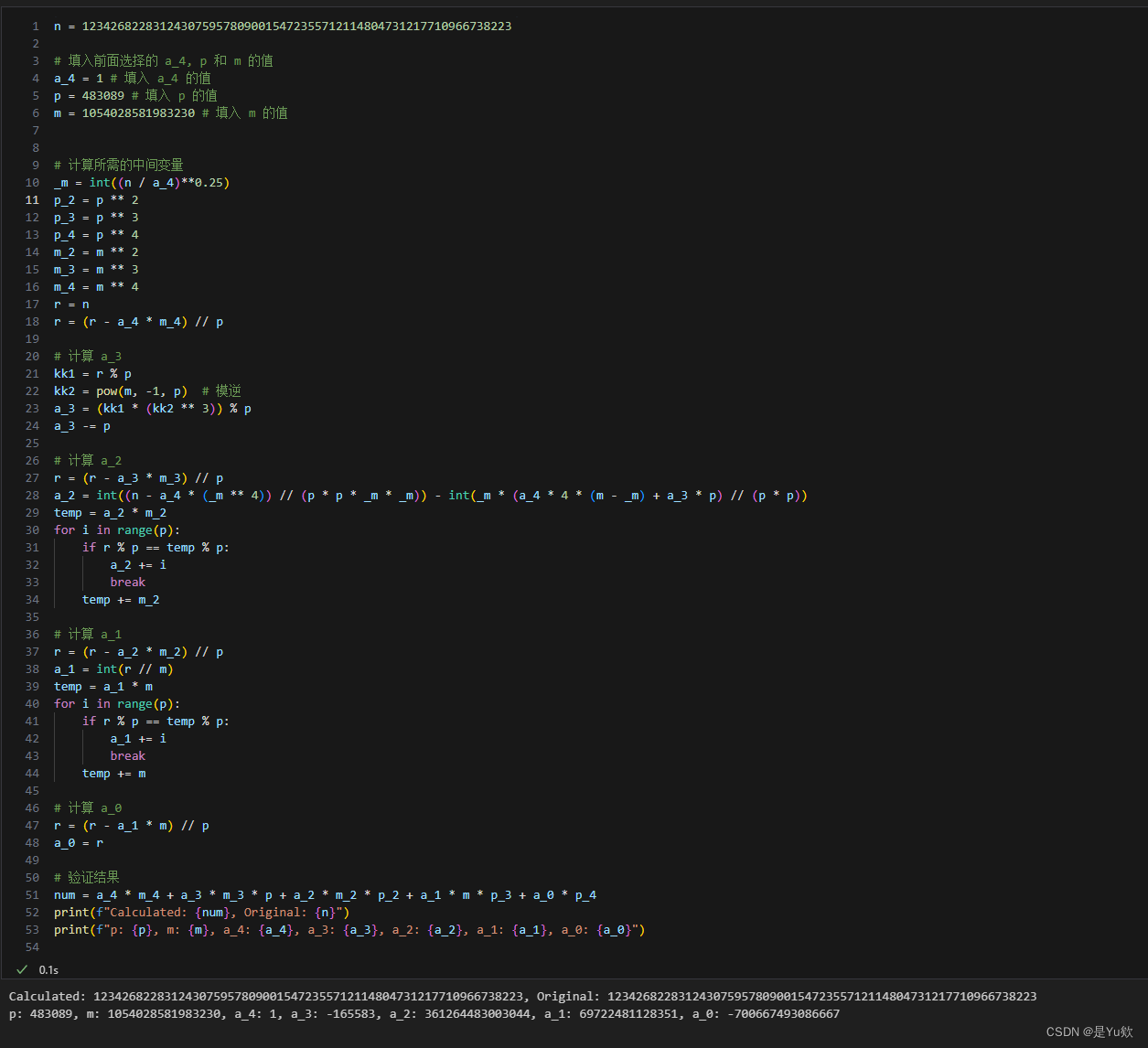
注意验证检查时重点看一下最后几位数,我前面输入有问题时,最后5位数字对不上,说明整数分解错误。
Calculated: 1234268228312430759578090015472355712114804731217710966738223, Original: 1234268228312430759578090015472355712114804731217710966738223
p: 483089, m: 1054028581983230, a_4: 1, a_3: -165583, a_2: 361264483003044, a_1: 69722481128351, a_0: -700667493086667
如果报错:ValueError: base is not invertible for the given modulus
在尝试计算 m 的模逆时出现了问题,报错ValueError: base is not invertible for the given modulus
原因: m 和 p 不互质,即它们有共同的因子。在这种情况下,模逆并不存在。
因此,为了解决这个问题,我们需要确保 m 和 p 是互质的。
如果它们不是互质的,可能需要重新选择解集,检查 m 的值或 p 的值是否正确。
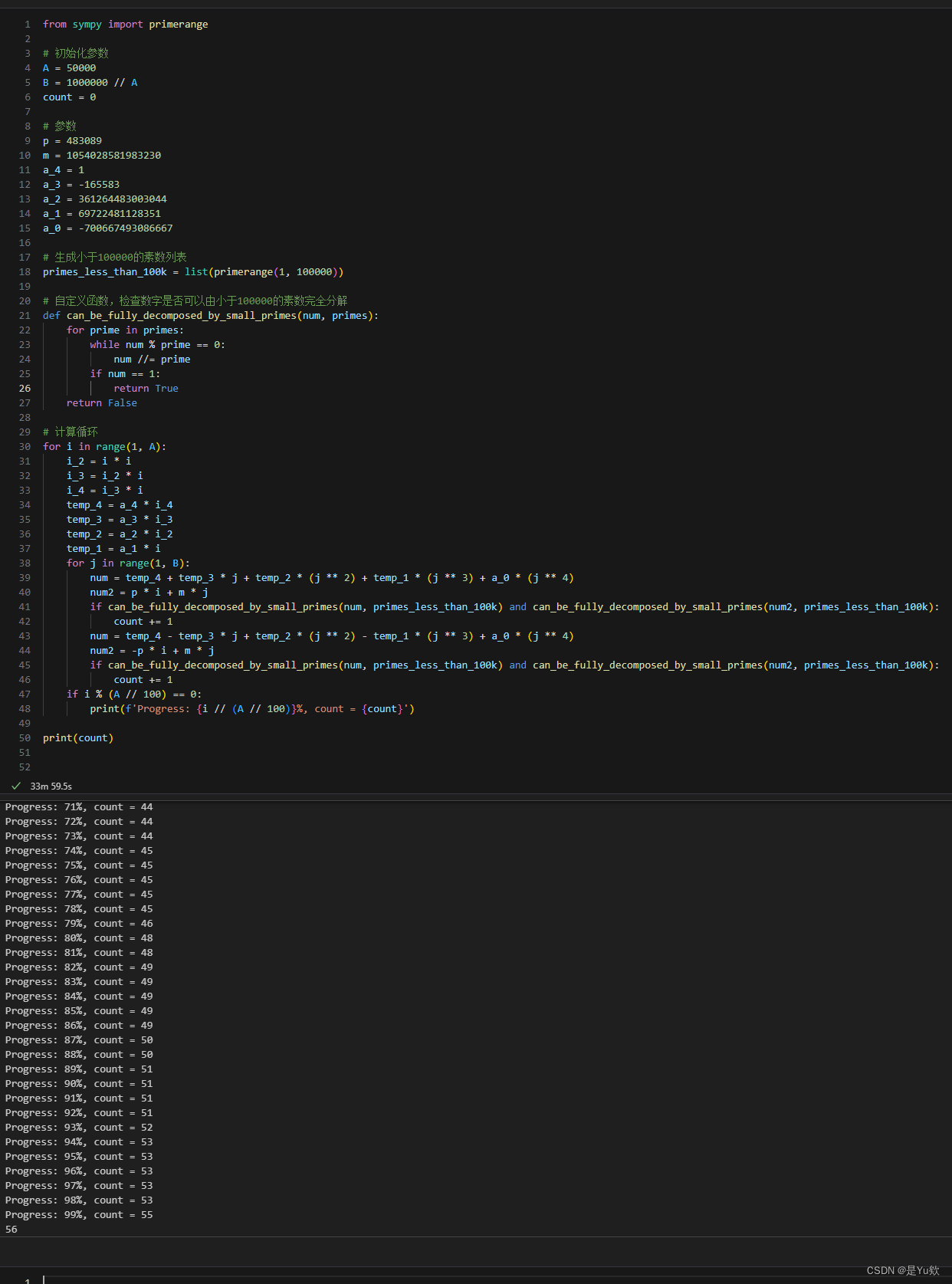
4. 计算 COUNT 并选择最优的 A/B
在这一部分,我们将专注于选择最优的 A / B A/B A/B 比例并计算相应的 C O U N T COUNT COUNT。 C O U N T COUNT COUNT 是满足特定条件的点对 ( a , b ) (a,b) (a,b) 的数量,其中 a ∈ [ ? A , A ] a \in [-A,A] a∈[?A,A], b ∈ [ 1 , B ] b \in [1, B] b∈[1,B]。这一计算涉及到,验证两个表达式是否可以由小于 100000 的素数完全分解。
但请注意,由于代码涉及大量的质因数分解,因此计算复杂度很高,尤其是在较大数值范围内。
代码实现
在 Python 中,我们可以使用 sympy 库来获取一个数的质因数。
关键步骤
- 初始化参数:设置 A A A、 B B B、 p p p、 m m m 以及多项式 f ( x ) f(x) f(x) 的系数。
- 生成素数列表:创建小于 100000 的素数列表。
- 定义分解函数:
can_be_fully_decomposed_by_small_primes函数检查一个数是否可以由小于 100000 的素数完全分解。 - 计算循环:
- 遍历 ( a , b ) (a,b) (a,b) 对,并计算 b 4 f ( a b ) b^4f\left(\frac{a}{b}\right) b4f(ba?) 和 b g ( a b ) bg\left(\frac{a}{b}\right) bg(ba?)。
- 检查这两个值是否都能由小于 100000 的素数完全分解。
- 如果可以,增加 C O U N T COUNT COUNT。
代码逻辑
- 循环遍历:对于每个 a ∈ [ ? A , A ] a \in [-A,A] a∈[?A,A] 和 b ∈ [ 1 , B ] b \in [1, B] b∈[1,B],计算相应的表达式。
- 分解检查:使用自定义的分解函数检查两个表达式是否都能被完全分解。
- 统计 COUNT:记录满足条件的点对的数量。
最大化收益率
收益率百分比衡量的是使用选定的多项式对成功实现因子分解的比例,相对于因子分解尝试的总数。
本质上,较高的收益百分比反映了GNFS算法中选择部署的多项式对的质量。它表示这些多项式有效地促进大整数因子分解的能力,最终影响因子分解过程的整体性能和成功率,反映了所选多项式产生可行因子分解结果的能力。
因此,在GNFS算法的多项式选择中,获得更高的收益率是一个关键目标,因为它直接与算法高效和成功地因子化大整数的能力相关。
计算 COUNT 和优化 A/B
这个代码段将帮助我们确定在给定参数下 C O U N T COUNT COUNT 的值,并且可以通过调整 A A A 和 B B B 的值来寻找最大化 C O U N T COUNT COUNT 的最优比例。
- 实验和分析:通过不同的 A A A 和 B B B 值进行实验,观察 C O U N T COUNT COUNT 的变化。
- 分析影响因素:探索 s k e w = A B skew = \frac{A}{B} skew=BA? 和系数 c 4 c_4 c4? 如何影响 C O U N T COUNT COUNT,以及如何调整这些参数以优化结果。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!