【论文简述】High-frequency Stereo Matching Network(CVPR 2023)
一、论文简述
1. 第一作者:Haoliang Zhao
2. 发表年份:2023
3. 发表期刊:CVPR
4. 关键词:立体匹配、MVS、深度学习、高频信息、LSTM
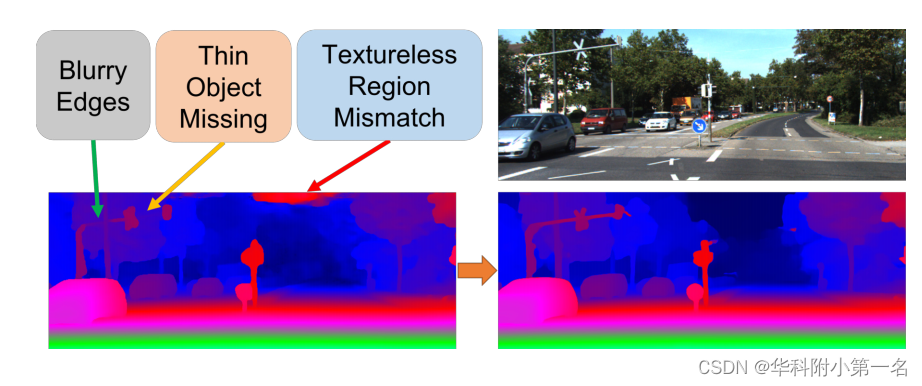
5. 探索动机:(1)当涉及到估计的视差图的更精细的特征时,大多数当前的方法都是不足的。特别是对于物体的边缘性能。在散景和渲染应用程序中,视差图的边缘性能对最终结果至关重要。(2)无纹理区域的失配和薄物体的缺失也是导致视差图显著恶化的重要因素。例如,弱纹理墙的不匹配和细电线的缺失是避障应用的致命缺陷。
(1)Most current approaches fall short when it comes to the finer features of the estimated disparity map. Especially for the edge performance of the objects. In bokeh and rendering applications, the edge performance of the disparity map is critical to the final result. For example, technologies that require pixellevel rendering, such as VR and AR, have high requirements for fitting between the scene model and the image mapping, which means we need a tight fit between the edges in the disparity map and the original RGB image.
(2)The mismatch of textureless regions and the missing of thin objects are also important factors that significantly deteriorate the disparity map. For example, the mismatch of weak texture walls and the missing of thin electrical wires are fatal flaws for obstacle avoidance applications.
6. 工作目标:目标是解决边缘模糊、薄物体缺失和无纹理区域不匹配的问题。
7. 核心思想:提出了一种新的端到端数据驱动的立体匹配方法DLNR (Stereo Matching Network with decoupling LSTM and Normalization Refinement)。
- Most of the current iterative methods usually apply the original GRU structure as their iterative cell. While the problem is that in the original GRU structure, the information used to generate the update matrix of the disparity map is coupled with the value of the hidden state transfer between iterations, making it hard to keep subtle details in the hidden state. Therefore, we designed the Decouple LSTM module to decouple the hidden state from the update matrix of the disparity map.Decouple LSTM keeps more high-frequency information in the iterative stage through data decoupling, however, in order to balance performance and computational speed, the resolution of the iterative stage is only 1/4 of the original resolution at most.
- However, due to the large differences in disparity ranges between different images and different datasets, the Refinement module often has poor generalization performance when encountering images with different disparity ranges. In particular, when performing finetune, the module may even fail when encountering disparity ranges that differ greatly. To address this problem, we propose the Disparity Normalization strategy. Experiments and visualizations proved that the module improves performance as well as alleviates the problem of domain difference.
- most learning-based methods still use ResNet-like feature extractors which fall short when providing information for well-designed poststage structures. To alleviate the problem, we propose the Channel-Attention Transformer feature extractor aims to capture long-range pixel dependencies and preserve highfrequency information.
8. 实验结果:
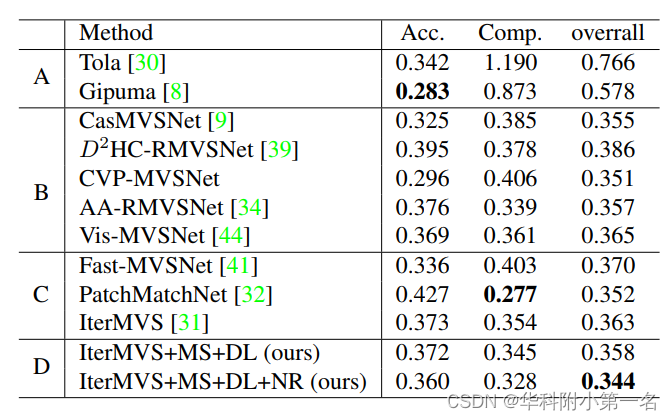
Our method (DLNR) ranks 1st on the Middlebury leaderboard, significantly outperforming the next best method by 13.04%. Our method also achieves SOTA performance on the KITTI-2015 benchmark for D1-fg.
9.论文&代码下载:
https://github.com/StereoResearcher/DLNR
二、实现过程
1. 网络结构
校正后的图像对被传递到具有远程像素建模能力的通道-注意力转换器特征提取器中,然后由后续的多尺度解耦LSTM网络进行特征处理,该网络可以跨迭代携带更多的语义信息,在采用前馈结构处理之前,细化模块对视差图进行上采样并执行视差归一化,可以缓解域差异问题。

2. Channel-Attention Transformer extractor
近年来,Transformer和自注意力算法由于其远程像素依赖性建模能力在许多视觉任务中被证明是有效的。而其计算量随着图像分辨率的提高呈二次增长。受Restormer的启发,设计了一个多级、多尺度的通道注意力Transformer作为特征提取器。详细结构如图所示。目标是设计一个特征提取器,不仅可以捕获远程像素依赖关系,还可以保留尽可能多的高频信息。

2.1.?保留高频信息
为了达到锐利边缘和更好地处理弱纹理区域的目的,在处理过程中保持高频是至关重要的。最直观的方法是在整个结构中保持高分辨率,但这会导致极高的计算成本。而采用带有步长的卷积或池化机制进行下采样将不可避免地导致信息丢失和性能下降。为了缓解这个问题,用Pixel Unshuffle将图像降采样到原始大小的1/4,并在不丢失任何高频信息的情况下扩展通道。具体地说,原图像的形状为[C, H?r, W?r],经过Pixel Unshuffle后被重塑为[C?r2, H, W]。
2.2. 通道注意力机制
传统的自注意力管理着一个注意力图HW ×HW,这导致二次复杂度,使得它不适合需要高分辨率的视觉任务。因此,采用的CWSA模块来源于MDTA[42]模块首先由Restromer[42]提出,它以线性复杂度计算通道维度上的自注意力。
3. Multiscale Decouple LSTM Regularization
该方法使用迭代单元进行正则化。在每次迭代中,迭代单元结合来自特征提取器的多尺度多阶段信息Fl、Fm和Fh,以及上一次迭代hi?1、Ci?1生成的隐藏状态和上一次视差图Di?1,预测一个新的视差图更新矩阵?Di。单元的设计目的是尽可能高效地使用特征信息,并在迭代之间高效地传递有效信息。
3.1. 多尺度设计
在立体匹配任务中,由于无纹理区域的图案较弱,很难找到相应的像素。因此,捕获空间相邻像素的模式成为问题的关键部分。我们通过迭代模块的多尺度设计来解决这个问题。具体来说,迭代模块由三个不同尺度的子模块组成,分别为图像分辨率大小的1/4、1/8和1/16。每一个都与相邻的分辨率相互作用。低分辨率分支具有更大的等效感知场,可以更好地处理无纹理的区域,而高分辨率分支捕获更多的高频细节,可以为视差图的边缘和拐角添加更多的细节。
3.2. 解耦机制
在大多数迭代视觉网络使用的原始GRU结构中,隐藏状态h用于生成视差的更新矩阵(GRU Cell的输出),同时h也是GRU网络的隐藏状态(向下一次迭代传递信息)。在消融实验中,这种耦合问题被证明对网络性能有重大影响。
本文通过引入一个额外的隐藏状态C来解决这个问题。如图所示,上面提到的隐藏状态h用于通过视差头生成更新矩阵,而新引入的隐藏状态C仅用于跨迭代传递信息。该设计解耦了更新矩阵和隐藏状态,可以跨迭代保留更有效的语义信息。

迭代单元以隐藏状态和代价体的信息作为输入,输出视差图的更新矩阵(图中?Di),该矩阵与视差图(图中Di)相加。由于视差图越来越精细,更新矩阵?Di逐渐趋近于0。L表示Lookup操作符。?
?4. Disparity Normalization Refinement
由于模型对下采样分辨率进行了正则化处理,导致高频信息不能完全保留。为此,设计了一个细化模块,旨在以全分辨率捕获更细微的细节。
在微调中相对独立的模块中,由于域的差异,特征图的输出可能都是负的,并且在ReLU激活函数之后,特征图的输出都是0值,从而导致网络无法对这部分参数进行微调,只能通过跳跃连接将特征信息传递给后续模块。这就导致了网络预训练后,一些模块不能很好地调优,甚至会遇到模块失败当在其他数据集中执行微调时。

如图所示,首先通过学习上采样对1/4分辨率视差图进行上采样。然后使用扭曲函数将右图像转换为左图像并计算误差图。

式中Dfr为全分辨率的视差图,Dlr表示上采样前的视差图。
上采样的视差缩放到0和1之间。注意,min(Dfr)通常等于0。文中使用左图像的宽度作为分母将所有像素点的视差值归一化,这是最大可能的视差值。

然后在归一化视差图中的信息Dfr,误差图El与左侧图像Il将进行组合并通过沙漏网络处理,得到归一化精细视差图Dfr '。
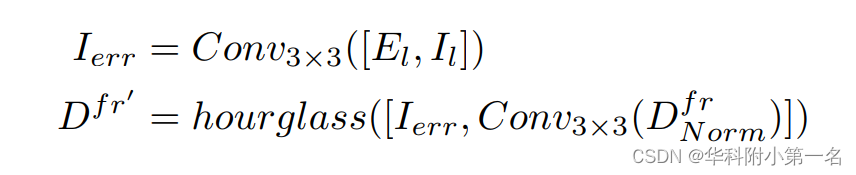
最后,执行视差非归一化,生成最终的视差图。?

5. Loss Function
用下面的等式来监督网络:

7. 实验
7.1. 与先进技术的比较



7.2. 消融实验

隐藏状态h和新引入的隐藏状态c的可视化。具体来说,使用PCA将通道数从128减少到1。隐藏状态C保留了更多的边缘特征(见红框)和更多的薄对象特征(见蓝框和黄框)。放大以获得更好的视野。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!