多序列图像拼接
2023-12-19 00:43:10
总的来说,步骤如下:
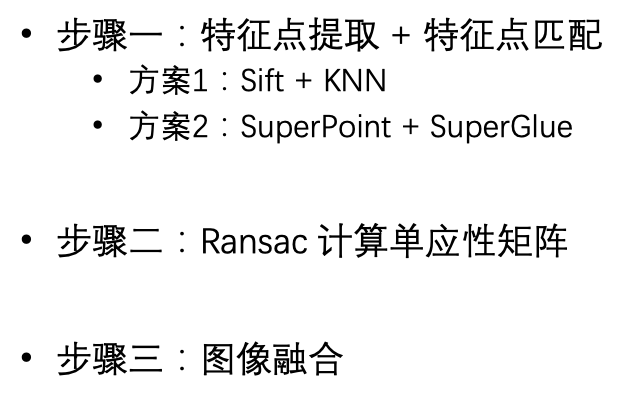
效果如下:

拼接好的图如下:

图像匹配
依次为 特征点提取,特征点筛选,图像变换。
常见的图像匹配算法有:

图像匹配代码
基于opencv的sift以及SuperNet的特征点提取、特征点筛选的图像变换,注释部分为SuperNet特征点提取。
文件目录
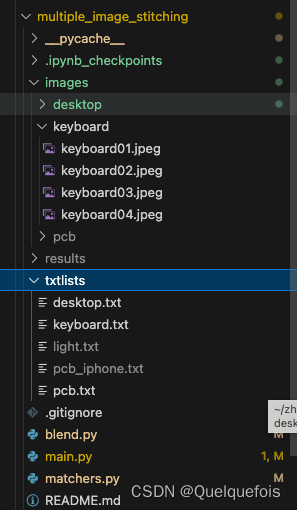
保存在matchers.py
import cv2
import numpy as np
import time
import matplotlib.pyplot as plt
import torch
# traditional sift using opencv API
class SIFTMatcher():
def __init__(self):
#### get keypionts
# Initiate SIFT detector
self.sift = cv2.SIFT_create() # self.sift = cv2.xfeatures2d_SIFT().create() # for older version of opencv
# find the keypoints and descriptors with SIFT
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
self.flann = cv2.FlannBasedMatcher(index_params, search_params)
def match(self,dstImg,srcImg,direction,overlap=0.5,scale=4): # add overlap
# # RETURN M TO transfer srcImg onto dstImg
# print("Direction : ", direction)
imgDstGray = cv2.cvtColor(dstImg, cv2.COLOR_BGR2GRAY)
imgSrcGray = cv2.cvtColor(srcImg, cv2.COLOR_BGR2GRAY)
# crop iamge to calculate feature matching to boost
srcOffset = int(overlap*imgSrcGray.shape[1])
# print("SrcOFFSET :",srcOffset)
imgSrcCrop = imgSrcGray[:,:srcOffset] # oops all inverse
# right Img/ Dst img default 1.2 size of left
dstOffset = max(0,int(imgDstGray.shape[1]-srcOffset*1.2)) # ori 1.2
imgDstCrop = imgDstGray[:,dstOffset:]
# resize image before matching to accelerate
# scale = scale
resized_imgDstCrop = cv2.resize(imgDstCrop,(int(imgDstCrop.shape[1]/scale),int((imgDstCrop.shape[0]/scale))),interpolation=cv2.INTER_AREA)
resized_imgSrcCrop = cv2.resize(imgSrcCrop,(int(imgSrcCrop.shape[1]/scale),int((imgSrcCrop.shape[0]/scale))),interpolation=cv2.INTER_AREA)
# find the keypoints and descriptors with SIFT
# kp1, des1 = self.sift.detectAndCompute(imgDstCrop, None) # dst
# kp2, des2 = self.sift.detectAndCompute(imgSrcCrop, None)
kp1, des1 = self.sift.detectAndCompute(resized_imgDstCrop, None) # dst
kp2, des2 = self.sift.detectAndCompute(resized_imgSrcCrop, None)
# cv2.imwrite("results/"+str(imgSrcCrop[0][100])+"imgSrcCrop.jpg",imgSrcCrop)
# print(imgSrcCrop.shape,imgDstCrop.shape)
# cv2.imwrite("results/tmp/"+str(time.time())+"resized_SrcCrop.jpg",resized_imgSrcCrop)
# cv2.imwrite("results/tmp/"+str(time.time())+"resized_DstCrop.jpg",resized_imgDstCrop)
matches = self.flann.knnMatch(des1, des2, k=2)
# # Need to draw only good matches, so create a mask
# matchesMask = [[0, 0] for i in range(len(matches))]
good = []
pts1 = []
pts2 = []
# ratio test as per Lowe's paper
for i, (m, n) in enumerate(matches):
if m.distance < 0.9 * n.distance: # default 0.7
good.append(m)
rows, cols = dstImg.shape[:2]
MIN_MATCH_COUNT = 10
if len(good) > MIN_MATCH_COUNT:
print(f"GOOD匹配点数量为:{len(good)}")
dst_pts = np.float32([kp1[m.queryIdx].pt for m in good])#.reshape(-1, 1, 2) # dst
src_pts = np.float32([kp2[m.trainIdx].pt for m in good])#.reshape(-1, 1, 2)
# print(src_pts, dst_pts)
# scale back
src_pts, dst_pts = scale*src_pts, scale*dst_pts
# xz
dst_pts[:] +=[dstOffset,0]
# print("after",src_pts)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
# save matched pics
matchesMask = mask.ravel().tolist()
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255, 0, 0),
matchesMask = matchesMask, # draw only inliers
flags = 2)
img4 = cv2.drawMatches(dstImg,kp1,srcImg,kp2,good,None,**draw_params)
# need mathces sub-folder under results folder
cv2.imwrite("results/matches/"+str(time.time())+"matches_ransac.jpg",img4)
# # plt.imshow(img4,), plt.show()
# # print('M', M)
return M
else:
print("Not enough matches are found - {}/{}".format(len(good), MIN_MATCH_COUNT))
matchesMask = None
return None
# # Neural Networked based matching method
# # 2020 CVPR SuperGlue Net for matching
# import sys
# sys.path.append('../SuperGluePretrainedNetwork-master/')
# from models.matching import Matching
# from models.utils import frame2tensor
# class SuperGlueMatcher():
# def __init__(self):
# self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
# self.config = {
# 'superpoint': {
# 'nms_radius': 4,
# 'keypoint_threshold': 0.005,
# 'max_keypoints': -1
# },
# 'superglue': {
# 'weights': 'indoor',
# 'sinkhorn_iterations': 20,
# 'match_threshold': 0.25,
# }
# }
# self.model = Matching(self.config).eval().to(self.device)
# def match(self,dstImg,srcImg,direction,overlap=0.5):
# data = {}
# data['image0'] = cv2.cvtColor(srcImg, cv2.COLOR_BGR2GRAY)
# data['image1'] = cv2.cvtColor(dstImg, cv2.COLOR_BGR2GRAY)
# # size = (800,600)
# # size = image0.shape
# # data['image0'] = cv2.resize(imgSrcGray,size)
# # data['image1'] = cv2.resize(imgDstGray,size)
# # crop iamge to calculate feature matching to boost
# srcOffset = int(overlap*data['image0'].shape[1])
# # print("SrcOFFSET :",srcOffset)
# data['image0'] = data['image0'][:,:srcOffset] # oops all inverse
# # right Img/ Dst img default 1.2 size of left
# dstOffset = max(0,int(data['image1'].shape[1]-srcOffset*1.2))
# data['image1'] = data['image1'][:,dstOffset:]
# cv2.imwrite("results/tmp/"+str(time.time())+"SrcCrop.jpg",data['image0'])
# cv2.imwrite("results/tmp/"+str(time.time())+"DstCrop.jpg",data['image1'] )
# # img to tensor
# imgToTensor0 = frame2tensor(data['image0'],self.device)
# last_data = self.model.superpoint({'image': imgToTensor0})
# keys = ['keypoints', 'scores', 'descriptors']
# last_data = {k+'0': last_data[k] for k in keys}
# last_data['image0'] = imgToTensor0
# imgToTensor1 = frame2tensor(data['image1'],self.device)
# # pred2 = matching({'image0':imgToTensor0,'image1':imgToTensor1})
# pred = self.model({**last_data,'image1':imgToTensor1})
# kpts0 = last_data['keypoints0'][0].cpu().numpy()
# kpts1 = pred['keypoints1'][0].cpu().numpy()
# matches = pred['matches0'][0].cpu().numpy() # 图一上的匹配点,如果非匹配点则 -1
# confidence = pred['matching_scores0'][0].cpu().detach().numpy() # it has grad
# # timer.update('forward')
# valid = matches > -1
# mkpts0 = kpts0[valid] # 图s0上的匹配点
# mkpts1 = kpts1[matches[valid]] # 图s1上的匹配点
# mkpts0, mkpts1 = np.round(mkpts0).astype(int), np.round(mkpts1).astype(int)
# mkpts1[:] +=[dstOffset,0]
# if len(matches) >= 4:
# M, mask = cv2.findHomography(mkpts0, mkpts1, cv2.RANSAC,5.0)
# else:
# M = None
# print(f"Warning! Only {len(matches)} searched!!!")
# return M
图像融合
保存在 blend.py文件中。
import numpy as np
def blend_linear(warp_img1, warp_img2):
img1 = warp_img1
img2 = warp_img2
img1mask = ((img1[:,:,0] | img1[:,:,1] | img1[:,:,2]) >0)
img2mask = ((img2[:,:,0] | img2[:,:,1] | img2[:,:,2]) >0)
r,c = np.nonzero(img1mask)
out_1_center = [np.mean(r),np.mean(c)]
r,c = np.nonzero(img2mask)
out_2_center = [np.mean(r),np.mean(c)]
vec = np.array(out_2_center) - np.array(out_1_center)
intsct_mask = img1mask & img2mask
# row col index of nonzero element
r,c = np.nonzero(intsct_mask)
out_wmask = np.zeros(img2mask.shape[:2])
# dot product of spherical coordinate and vec: measuring how much the vectors align or overlap in their directions
proj_val = (r - out_1_center[0])*vec[0] + (c- out_1_center[1])*vec[1]
# min-max normalization of proj_val xz
out_wmask[r,c] = (proj_val - (min(proj_val)+(1e-3))) / \
((max(proj_val)-(1e-3)) - (min(proj_val)+(1e-3)))
# blending
mask1 = img1mask & (out_wmask==0)
mask2 = out_wmask
mask3 = img2mask & (out_wmask==0)
out = np.zeros(img1.shape)
for c in range(3):
out[:,:,c] = img1[:,:,c]*(mask1+(1-mask2)*(mask2!=0)) + \
img2[:,:,c]*(mask2+mask3)
return np.uint8(out)
def blend_max(img1,img2):
# get max value for each pixel
out = np.zeros(img1.shape)
mask = img1 > img2
return np.uint8(img1*mask + img2*(1-mask))
# if __name__=="__main__":
# import cv2
# img1 = cv2.imread("warped_img1.jpg")
# img2 = cv2.imread("warped_img2.jpg")
# out = blend_linear(img1, img2)
# # cv2.imwrite("result.jpg",out)
main.py
import numpy as np
import cv2
import sys
from matchers import SIFTMatcher,SuperGlueMatcher
import time
import blend
import torch
torch.set_grad_enabled(False)
class Stitch:
def __init__(self, args):
self.path = args
fp = open(self.path, 'r')
filenames = [each.rstrip('\r\n') for each in fp.readlines()] # remove tails
# filenames = args
print(filenames)
# self.images = [cv2.resize(cv2.imread(each), (480, 320)) for each in filenames]
self.images = [cv2.imread(each) for each in filenames]
self.count = len(self.images)
self.left_list, self.right_list, self.center_im = [], [], None
self.matcher_sift = SIFTMatcher()
self.matcher_nn = SuperGlueMatcher()
self.prepare_lists()
def prepare_lists(self):
'''Group images, suitable for single sequence, divide by left and right'''
print("Number of images : %d" % self.count)
self.centerIdx = self.count / 2
# self.centerIdx = self.count - 1
print("Center index image : %d" % self.centerIdx)
self.center_im = self.images[int(self.centerIdx)]
for i in range(self.count):
if (i <= self.centerIdx):
self.left_list.append(self.images[i]) # not path, iamges in array
else:
self.right_list.append(self.images[i])
print("Image lists prepared")
def leftshift(self):
# self.left_list = reversed(self.left_list)
a = self.left_list[0]
idx = 0
for b in self.left_list[1:]:
start = time.time()
# return H : tranfer b onto a
siftEnd = time.time()
H = self.matcher_sift.match(a, b, 'left')
# print("Time cost for sift matching this pair is {} s".format(siftEnd -start))
# H_nn = self.matcher_nn.match(a,b,'left')
# H = H_nn
# # print(H-H_nn)
matchEnd = time.time()
print("Time cost for NN matching this pair is {} s".format(matchEnd -siftEnd))
# print("Homography is : ", H)
xh = np.linalg.inv(H) # so as to transfer a onto b, left to corner
# print("Inverse Homography :", xh)
br = np.dot(xh, np.array([a.shape[1], a.shape[0], 1])) # bottom right point is (col, row) while shape is row,col xz
br = br /br[-1] # to guarantee h33 is 1 xz
tl = np.dot(xh, np.array([0, 0, 1])) # top left
tl = tl / tl[-1]
bl = np.dot(xh, np.array([0, a.shape[0], 1])) # bottom left
bl = bl / bl[-1]
tr = np.dot(xh, np.array([a.shape[1], 0, 1])) # top right
tr = tr / tr[-1]
# Second item :original a, add b, cause b stands for rightImg, b usually has a larger border in left-right xz
cx = int(max([0, b.shape[1],tl[0], bl[0], tr[0], br[0]])) # a.shape[1],# only used for determinize size of new_srcImg
cy = int(max([0, b.shape[0],tl[1], bl[1], tr[1], br[1]])) # a.shape[0],
offset = [abs(int(min([0, a.shape[1], tl[0], bl[0], tr[0], br[0]]))), # to avoid negative coordinate
abs(int(min([0, a.shape[0], tl[1], bl[1], tr[1], br[1]])))]
dsize = (cx + offset[0], cy + offset[1]) # iamge size for transformed iamge, large enough
print("image dsize =>", dsize, "offset", offset)
tl[0:2] += offset; bl[0:2] += offset; tr[0:2] += offset; br[0:2] += offset # four tranformed corner points
dstpoints = np.array([tl, bl, tr, br])
srcpoints = np.array([[0, 0], [0, a.shape[0]], [a.shape[1], 0], [a.shape[1], a.shape[0]]])
# print('sp',sp,'dp',dp)
M_off = cv2.findHomography(srcpoints, dstpoints)[0] # Normally, transofrm first onto second zxz
# print('M_off', M_off)
warped_img2 = cv2.warpPerspective(a, M_off, dsize)
# cv2.imshow("warped", warped_img2)
# cv2.waitKey()
warped_img1 = np.zeros([dsize[1], dsize[0], 3], np.uint8)
# beacause of left to right,
warped_img1[offset[1]:b.shape[0] + offset[1], offset[0]:b.shape[1] + offset[0]] = b # offset for dstImag b also
# tmp = blend.blend_linear(warped_img1, warped_img2)
tmp = blend.blend_linear(warped_img1,warped_img2)
a = tmp
stitchEnd = time.time()
print("Time cost for stitch is {} s".format(stitchEnd -matchEnd))
cv2.imwrite("results/tmpLeft_"+str(idx)+".jpg",tmp)
idx +=1
self.leftImage = tmp
def rightshift(self):
if len(self.right_list) > 0: # if only two images, no need for rightshift
idx = 0
for each in self.right_list:
start = time.time()
H = self.matcher_sift.match(self.leftImage, each, 'right') # here, transform each onto leftImage
# H_nn = self.matcher_nn.match(self.leftImage, each, 'right')
# H = H_nn
matchEnd = time.time()
print("Time cost for matching this pair is {} s".format(matchEnd -start))
# print("Homography :", H)
br = np.dot(H, np.array([each.shape[1], each.shape[0], 1]))
br = br / br[-1]
tl = np.dot(H, np.array([0, 0, 1]))
tl = tl / tl[-1]
bl = np.dot(H, np.array([0, each.shape[0], 1]))
bl = bl / bl[-1]
tr = np.dot(H, np.array([each.shape[1], 0, 1]))
tr = tr / tr[-1]
cx = int(max([0, each.shape[1], tl[0], bl[0], tr[0], br[0]])) #self.leftImage.shape[1],
cy = int(max([0, self.leftImage.shape[0],each.shape[0], tl[1], bl[1], tr[1], br[1]])) #self.leftImage.shape[0],
offset = [abs(int(min([0, each.shape[1], tl[0], bl[0], tr[0], br[0]]))),
abs(int(min([0, each.shape[0], tl[1], bl[1], tr[1], br[1]])))]
dsize = (cx + offset[0], cy + offset[1])
print("image dsize =>", dsize, "offset", offset)
tl[0:2] += offset; bl[0:2] += offset; tr[0:2] += offset; br[0:2] += offset
dstpoints = np.array([tl, bl, tr, br]);
srcpoints = np.array([[0, 0], [0, each.shape[0]], [each.shape[1], 0], [each.shape[1], each.shape[0]]])
M_off = cv2.findHomography(dstpoints, srcpoints)[0]
warped_img2 = cv2.warpPerspective(each, M_off, dsize, flags=cv2.WARP_INVERSE_MAP)
# cv2.imshow("warped", warped_img2)
# cv2.waitKey()
warped_img1 = np.zeros([dsize[1], dsize[0], 3], np.uint8)
warped_img1[offset[1]:self.leftImage.shape[0] + offset[1], offset[0]:self.leftImage.shape[1] + offset[0]] = self.leftImage
tmp = blend.blend_linear(warped_img1, warped_img2)
self.leftImage = tmp
stitchEnd = time.time()
print("Time cost for stitch is {} s".format(stitchEnd -matchEnd))
cv2.imwrite("results/tmpRight_"+str(idx)+".jpg",tmp)
idx +=1
self.rightImage = tmp
def showImage(self, string=None):
if string == 'left':
cv2.imshow("left image", self.leftImage)
elif string == "right":
cv2.imshow("right Image", self.rightImage)
cv2.waitKey()
if __name__ == '__main__':
try:
args = sys.argv[1]
except:
args = "txtlists/keyboard.txt"
finally:
print("Parameters : ", args)
total_start = time.time()
s = Stitch(args)
# pipline for single sequence
s.leftshift()
# cv2.imwrite("results/res_L.jpg", s.leftImage)
s.rightshift()
# # cv2.imwrite("results/res_R.jpg", s.leftImage)
print("done")
# ouput a file in the same name as input txt
res = args.split("/")[-1].split(".txt")[0] + ".jpg"
rotate = False
if rotate:
s.leftImage = cv2.rotate(s.leftImage,cv2.ROTATE_90_COUNTERCLOCKWISE)
cv2.imwrite("results/" + res, s.leftImage)
print("result written")
total_end = time.time()
print("Total time cost is {} s".format(total_end - total_start))
# cv2.destroyAllWindows()
运行代码
python main.py 记录照片文件路径的文本路径
文本内容举例如下:
images/keyboard/keyboard01.jpeg
images/keyboard/keyboard02.jpeg
images/keyboard/keyboard03.jpeg
images/keyboard/keyboard04.jpeg
文章来源:https://blog.csdn.net/zhangxz259/article/details/135056499
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!