langchain库教程
langchain库教程
https://github.com/langchain-ai/langchain
https://github.com/DjangoPeng/openai-quickstart
https://datawhalechina.github.io/llm-universe/#/
api地址:https://api.python.langchain.com/en/v0.0.339/api_reference.html#module-langchain.chat_models
本机langchain版本:0.0.346
Model I/O
Model I/O 是 LangChain 为开发者提供的一套面向 LLM 的标准化模型接口,包括模型输入(Prompts)、模型输出(Output Parsers)和模型本身(Models)。
-
Prompts:模板化、动态选择和管理模型输入
-
Models:以通用接口调用语言模型
-
Output Parser:从模型输出中提取信息,并规范化内容

chat_models
参数详情见:https://api.python.langchain.com/en/v0.0.339/api_reference.html#module-langchain.chat_models
import os
os.environ["OPENAI_API_KEY"] = '' ### 输入自己的openai_key
os.environ['HTTP_PROXY']="http://127.0.0.1:7890"
os.environ['HTTPS_PROXY']="http://127.0.0.1:7890"
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(
model_name="gpt-3.5-turbo",
openai_api_key=os.environ.get("OPENAI_API_KEY")
)
chat_model.max_tokens = 200
chat_model.temperature = 1
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
messages = [SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="Who won the world series in 2020?"),
AIMessage(content="The Los Angeles Dodgers won the World Series in 2020."),
HumanMessage(content="Where was it played?")]
打印构造好的messages:
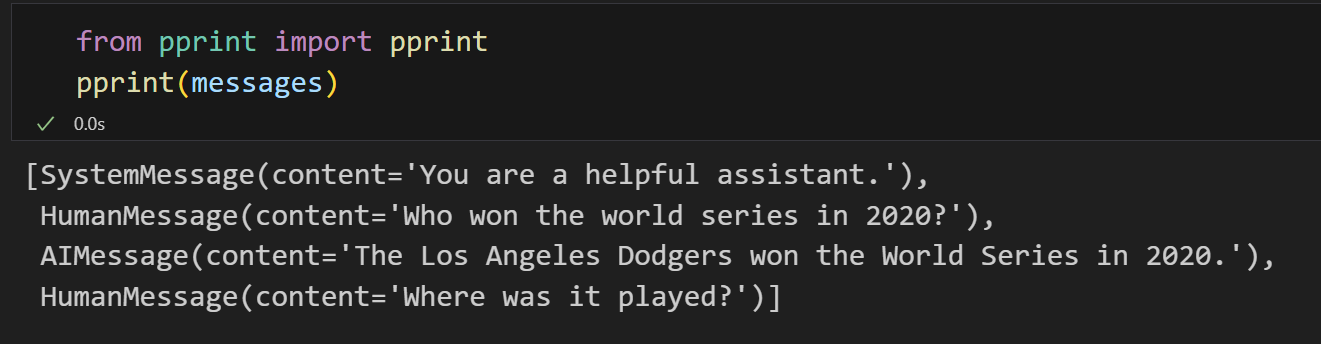
将构造好的messages送入chat_model得到gpt-3.5-turbo模型的响应:
chat_model(messages)

prompts
api详情:https://api.python.langchain.com/en/v0.0.339/api_reference.html#module-langchain.prompts
Prompt Templates 提供了一种预定义、动态注入、模型无关和参数化的提示词生成方式,以便在不同的语言模型之间重用模板。
1 使用from_template构造prompt
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
# 使用 format 生成提示
prompt = prompt_template.format(adjective="funny", content="chickens")
print(prompt)
输出如下:
Tell me a funny joke about chickens.
2 使用构造函数构造prompt
valid_prompt = PromptTemplate(
input_variables=["adjective", "content"],
template="Tell me a {adjective} joke about {content}."
)
valid_prompt.format(adjective="funny", content="chickens")
输出如下:
'Tell me a funny joke about chickens.'
3 PromptTemplate与openai api配合使用
(1)定义PromptTemplate
prompt_template = PromptTemplate.from_template(
"讲{num}个给程序员听得笑话"
)
(2)将prompt输入模型,得到结果
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003", max_tokens=1000)
prompt = prompt_template.format(num=2)
print(f"prompt: {prompt}")
result = llm(prompt)
print(f"result: {result}")
输出:
prompt: 讲2个给程序员听得笑话
result:
1.程序员去看电影,看完之后问:“这个电影有多少行代码?”
2.两个程序员在一起,一个问:“你用什么编程语言写的?”,另一个回答:“JavaScript,当然!”
print(llm(prompt_template.format(num=3)))
输出:
1.程序员与攻城狮较量,程序员说:“我用C语言可以把铁拆成铁粉。”攻城狮说:“我也可以,只不过我用的是两只手。”
2.一个程序员和他的同事在谈论编程语言,他说:“Java是一门伟大的语言,它可以让你做任何事情。”同事回答:“那你为什么还要学其它语言?”
3.程序员A:“我昨晚睡得很晚,因为我在调试一个Bug。”程序员B:“你在调试什么Bug?”程序员A:“我的床上的一只蚊子。”
4 使用jinja2生成模板化提示
jinja2_template = "Tell me a {{ adjective }} joke about {{ content }}"
prompt = PromptTemplate.from_template(jinja2_template, template_format="jinja2")
prompt.format(adjective="funny", content="chickens")
输出
'Tell me a funny joke about chickens'
5 实战:生成多种编程语言版本的快速排序
sort_prompt_template = PromptTemplate.from_template(
"生成可执行的快速排序 {programming_language} 代码"
)
print(llm(sort_prompt_template.format(programming_language="python")))
输出:
def quick_sort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[0]
left = [x for x in arr[1:] if x < pivot]
right = [x for x in arr[1:] if x >= pivot]
return quick_sort(left) + [pivot] + quick_sort(right)
arr = [5,4,7,2,9,1,8]
print(quick_sort(arr))
print(llm(sort_prompt_template.format(programming_language="java")))
输出:
public class QuickSort {
public static void quickSort(int[] arr, int low, int high) {
int i,j,temp,t;
if(low>high){
return;
}
i=low;
j=high;
//temp就是基准位
temp = arr[low];
while (i<j) {
//先看右边,依次往左递减
while (temp<=arr[j]&&i<j) {
j--;
}
//再看左边,依次往右递增
while (temp>=arr[i]&&i<j) {
i++;
}
//如果满足条件则交换
if (i<j) {
t = arr[j];
arr[j] = arr[i];
arr[i] = t;
}
}
//最后将基准为与i和j相等位置的数字交换
arr[low] = arr[i];
arr[i] = temp;
//递归调用左半数组
quickSort(arr, low, j-1);
//递归调用右半数组
quickSort(arr, j+1, high);
}
public static void main(String[] args) {
int[] arr = {10,7,2,4,7,62,3,4,2,1,8,9,19};
quickSort(arr, 0, arr.length-1);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
6 使用 ChatPromptTemplate 类生成适用于聊天模型的聊天记录
(1)使用 from_messages 方法实例化 ChatPromptTemplate
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
# 生成提示
messages = template.format_messages(
name="Bob",
user_input="What is your name?"
)
print(messages)
输出:
[SystemMessage(content='You are a helpful AI bot. Your name is Bob.'), HumanMessage(content='Hello, how are you doing?'), AIMessage(content="I'm doing well, thanks!"), HumanMessage(content='What is your name?')]
(2)实例化ChatOpenAI并且传入messages
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(model_name="gpt-3.5-turbo", max_tokens=1000)
chat_model(messages)
输出:
AIMessage(content='My name is Bob. How can I assist you today?')
7 实战:摘要总结
summary_template = ChatPromptTemplate.from_messages([
("system", "你将获得关于同一主题的{num}篇文章(用-----------标签分隔)。首先总结每篇文章的论点。然后指出哪篇文章提出了更好的论点,并解释原因。"),
("human", "{user_input}"),
])
messages = summary_template.format_messages(
num=3,
user_input='''1. [PHP是世界上最好的语言]
PHP是世界上最好的情感派编程语言,无需逻辑和算法,只要情绪。它能被蛰伏在冰箱里的PHP大神轻易驾驭,会话结束后的感叹号也能传达对代码的热情。写PHP就像是在做披萨,不需要想那么多,只需把配料全部扔进一个碗,然后放到服务器上,热乎乎出炉的网页就好了。
-----------
2. [Python是世界上最好的语言]
Python是世界上最好的拜金主义者语言。它坚信:美丽就是力量,简洁就是灵魂。Python就像是那个永远在你皱眉的那一刻扔给你言情小说的好友。只有Python,你才能够在两行代码之间感受到飘逸的花香和清新的微风。记住,这世上只有一种语言可以使用空格来领导全世界的进步,那就是Python。
-----------
3. [Java是世界上最好的语言]
Java是世界上最好的德育课编程语言,它始终坚守了严谨、安全的编程信条。Java就像一个严格的老师,他不会对你怀柔,不会让你偷懒,也不会让你走捷径,但他教会你规范和自律。Java就像是那个喝咖啡也算加班费的上司,拥有对邪恶的深度厌恶和对善良的深度拥护。
'''
)
chat_result = chat_model(messages)
print(chat_result.content)
输出:
文章1的论点是PHP是世界上最好的语言,因为它不需要逻辑和算法,只需要情绪,可以被PHP大神轻易驾驭,并且写PHP就像做披萨一样简单。
文章2的论点是Python是世界上最好的语言,因为它美丽且简洁,可以让你在两行代码之间感受到飘逸的花香和清新的微风,使用空格来领导全世界的进步。
文章3的论点是Java是世界上最好的语言,因为它严谨、安全,教会你规范和自律,拥有对邪恶的深度厌恶和对善良的深度拥护。
从这三篇文章中,我认为文章3提出了更好的论点。原因是Java作为一种编程语言,其严谨性和安全性是非常重要的特点。它的规范和自律能够培养程序员的良好编码习惯,并且对于邪恶和善良的深度拥护也展现了Java作为一种德育课编程语言的价值。相比之下,文章1和文章2的论点更强调语言的简单和愉悦性,但缺乏对编程的重要性和实际应用的讨论。
8 使用FewShotPromptTemplate类生成Few-shot Prompt
构造 few-shot prompt 的方法通常有两种:
-
从示例集(set of examples)中手动选择;
-
通过示例选择器(Example Selector)自动选择.
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "谁活得更久,穆罕默德·阿里还是艾伦·图灵?",
"answer":
"""
这里需要进一步的问题吗:是的。
追问:穆罕默德·阿里去世时多大了?
中间答案:穆罕默德·阿里去世时74岁。
追问:艾伦·图灵去世时多大了?
中间答案:艾伦·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
"""
},
{
"question": "craigslist的创始人是什么时候出生的?",
"answer":
"""
这里需要进一步的问题吗:是的。
追问:谁是craigslist的创始人?
中间答案:Craigslist是由Craig Newmark创办的。
追问:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark出生于1952年12月6日。
所以最终答案是:1952年12月6日
"""
},
{
"question": "乔治·华盛顿的外祖父是谁?",
"answer":
"""
这里需要进一步的问题吗:是的。
追问:谁是乔治·华盛顿的母亲?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
追问:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
"""
},
{
"question": "《大白鲨》和《皇家赌场》的导演是同一个国家的吗?",
"answer":
"""
这里需要进一步的问题吗:是的。
追问:谁是《大白鲨》的导演?
中间答案:《大白鲨》的导演是Steven Spielberg。
追问:Steven Spielberg来自哪里?
中间答案:美国。
追问:谁是《皇家赌场》的导演?
中间答案:《皇家赌场》的导演是Martin Campbell。
追问:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
"""
}
]
example_prompt = PromptTemplate(
input_variables=["question", "answer"],
template="Question: {question}\n{answer}"
)
# **examples[0] 是将examples[0] 字典的键值对(question-answer)解包并传递给format,作为函数参数
print(example_prompt.format(**examples[0]))
输出:
Question: 《大白鲨》和《皇家赌场》的导演是同一个国家的吗?
这里需要进一步的问题吗:是的。
追问:谁是《大白鲨》的导演?
中间答案:《大白鲨》的导演是Steven Spielberg。
追问:Steven Spielberg来自哪里?
中间答案:美国。
追问:谁是《皇家赌场》的导演?
中间答案:《皇家赌场》的导演是Martin Campbell。
追问:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
生成Few-shot Prompt
# 导入 FewShotPromptTemplate 类
from langchain.prompts.few_shot import FewShotPromptTemplate
# 创建一个 FewShotPromptTemplate 对象
few_shot_prompt = FewShotPromptTemplate(
examples=examples, # 使用前面定义的 examples 作为范例
example_prompt=example_prompt, # 使用前面定义的 example_prompt 作为提示模板
suffix="Question: {input}", # 后缀模板,其中 {input} 会被替换为实际输入
input_variables=["input"] # 定义输入变量的列表
)
# 使用给定的输入格式化 prompt,并打印结果
# 这里的 {input} 将被 "玛丽·波尔·华盛顿的父亲是谁?" 替换
print(few_shot_prompt.format(input="玛丽·波尔·华盛顿的父亲是谁?"))
输出:
Question: 谁活得更久,穆罕默德·阿里还是艾伦·图灵?
这里需要进一步的问题吗:是的。
追问:穆罕默德·阿里去世时多大了?
中间答案:穆罕默德·阿里去世时74岁。
追问:艾伦·图灵去世时多大了?
中间答案:艾伦·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
Question: craigslist的创始人是什么时候出生的?
这里需要进一步的问题吗:是的。
追问:谁是craigslist的创始人?
中间答案:Craigslist是由Craig Newmark创办的。
追问:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark出生于1952年12月6日。
所以最终答案是:1952年12月6日
Question: 乔治·华盛顿的外祖父是谁?
这里需要进一步的问题吗:是的。
追问:谁是乔治·华盛顿的母亲?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
追问:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
Question: 《大白鲨》和《皇家赌场》的导演是同一个国家的吗?
这里需要进一步的问题吗:是的。
追问:谁是《大白鲨》的导演?
中间答案:《大白鲨》的导演是Steven Spielberg。
追问:Steven Spielberg来自哪里?
中间答案:美国。
追问:谁是《皇家赌场》的导演?
中间答案:《皇家赌场》的导演是Martin Campbell。
追问:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
Question: 玛丽·波尔·华盛顿的父亲是谁?
9 示例选择器 Example Selectors
# 导入需要的模块和类
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
# 定义一个提示模板
example_prompt = PromptTemplate(
input_variables=["input", "output"], # 输入变量的名字
template="Input: {input}\nOutput: {output}", # 实际的模板字符串
)
# 这是一个假设的任务示例列表,用于创建反义词
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 从给定的示例中创建一个语义相似性选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, # 可供选择的示例列表
OpenAIEmbeddings(), # 用于生成嵌入向量的嵌入类,用于衡量语义相似性
Chroma, # 用于存储嵌入向量并进行相似性搜索的 VectorStore 类
k=1 # 要生成的示例数量
)
# 创建一个 FewShotPromptTemplate 对象
similar_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 提供一个 ExampleSelector 替代示例
example_prompt=example_prompt, # 前面定义的提示模板
prefix="Give the antonym of every input", # 前缀模板
suffix="Input: {adjective}\nOutput:", # 后缀模板
input_variables=["adjective"], # 输入变量的名字
)
# 输入是一种感受,所以应该选择 happy/sad 的示例。
print(similar_prompt.format(adjective="worried"))
输出:
Give the antonym of every input
Input: happy
Output: sad
Input: worried
Output:
# 输入是一种度量,所以应该选择 tall/short的示例。
print(similar_prompt.format(adjective="long"))
输出:
Give the antonym of every input
Input: tall
Output: short
Input: long
Output:
print(similar_prompt.format(adjective="rain"))
输出:
Give the antonym of every input
Input: windy
Output: calm
Input: rain
Output:
output_parsers
对模型输出内容进行解析
1 列表解析
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
# 创建一个输出解析器,用于处理带逗号分隔的列表输出
output_parser = CommaSeparatedListOutputParser()
# 获取格式化指令,该指令告诉模型如何格式化其输出
format_instructions = output_parser.get_format_instructions()
# 创建一个提示模板,它会基于给定的模板和变量来生成提示
prompt = PromptTemplate(
template="List five {subject}.\n{format_instructions}", # 模板内容
input_variables=["subject"], # 输入变量
partial_variables={"format_instructions": format_instructions} # 预定义的变量,这里我们传入格式化指令
)
# 使用提示模板和给定的主题来格式化输入
_input = prompt.format(subject="ice cream flavors")
print(_input)
输出:
List five ice cream flavors.
Your response should be a list of comma separated values, eg: `foo, bar, baz`
prompt送入模型:
llm = OpenAI(temperature=0)
output = llm(_input)
print(output)
输出:
Vanilla, Chocolate, Strawberry, Mint Chocolate Chip, Cookies and Cream
使用之前创建的输出解析器来解析模型的输出
# 使用之前创建的输出解析器来解析模型的输出
output_parser.parse(output)
输出:
['Vanilla',
'Chocolate',
'Strawberry',
'Mint Chocolate Chip',
'Cookies and Cream']
chains
LLMChain 是 LangChain 中最简单的链,作为其他复杂 Chains 和 Agents 的内部调用,被广泛应用。
一个LLMChain由PromptTemplate和语言模型(LLM or Chat Model)组成。它使用直接传入(或 memory 提供)的 key-value 来规范化生成 Prompt Template(提示模板),并将生成的 prompt (格式化后的字符串)传递给大模型,并返回大模型输出。
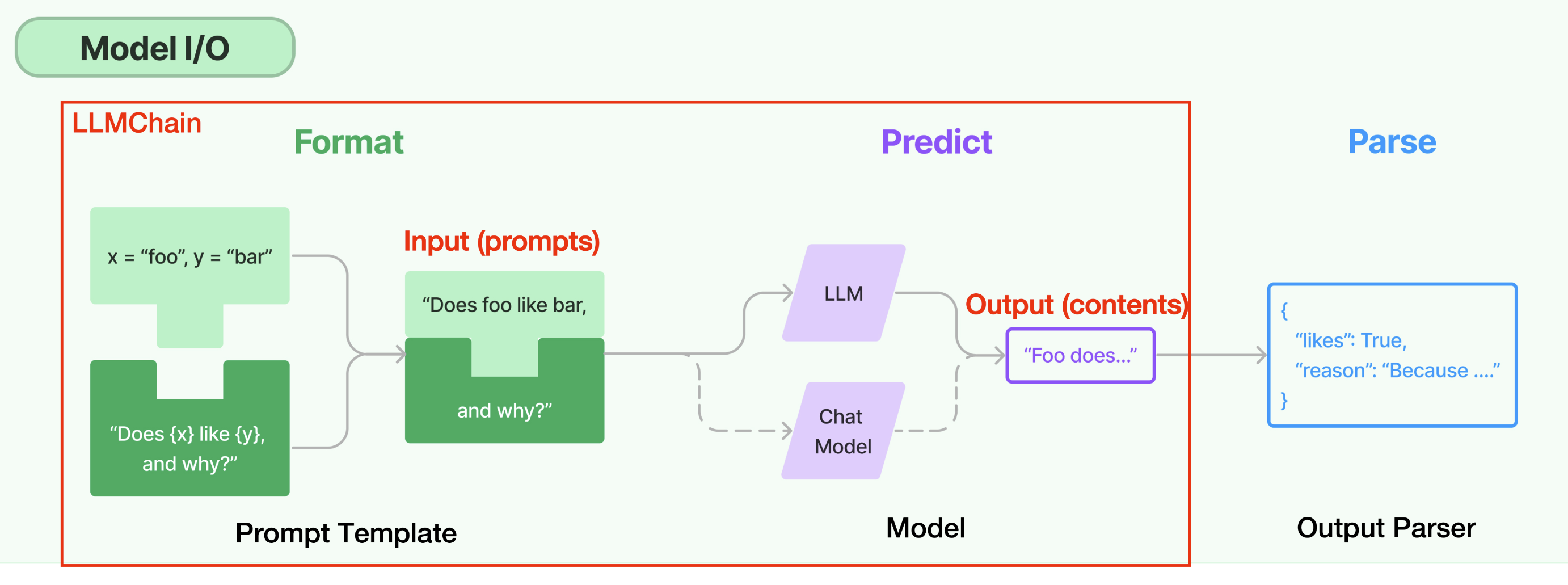
LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.9, max_tokens=500)
prompt = PromptTemplate(
input_variables=["product"],
template="给制造{product}的有限公司取10个好名字,并给出完整的公司名称",
)
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run({
'product': "性能卓越的GPU"
}))
输出:

chain.verbose = True
print(chain.run({
'product': "性能卓越的GPU"
}))

Sequential Chain
串联式调用语言模型(将一个调用的输出作为另一个调用的输入)。
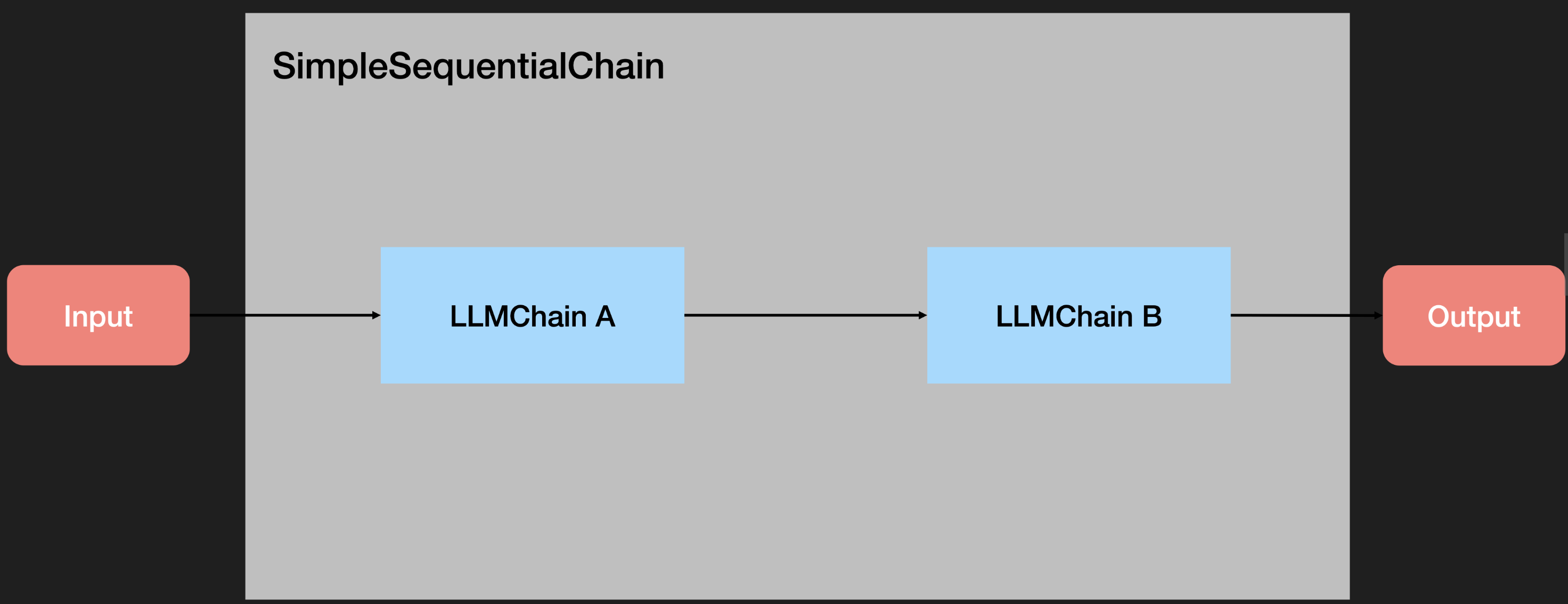
顺序链(Sequential Chain )允许用户连接多个链并将它们组合成执行特定场景的流水线(Pipeline)。有两种类型的顺序链:
-
SimpleSequentialChain:最简单形式的顺序链,每个步骤都具有单一输入/输出,并且一个步骤的输出是下一个步骤的输入。
-
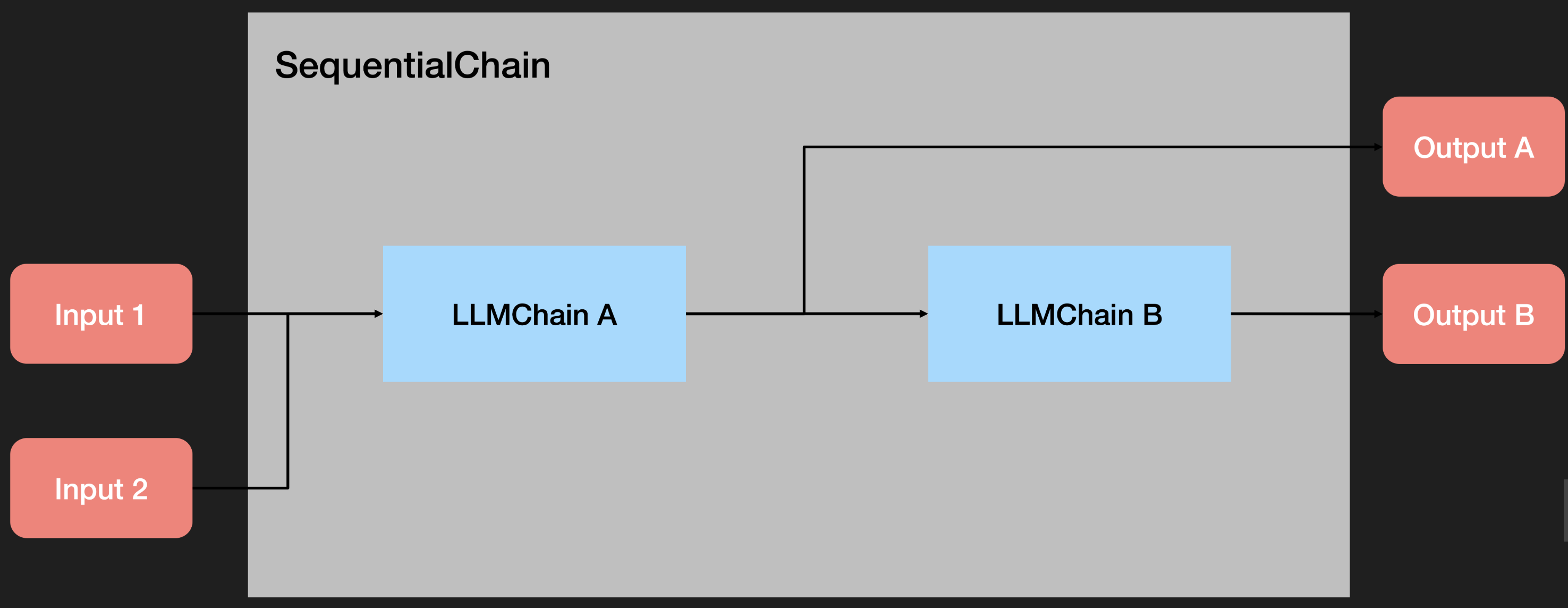
SequentialChain:更通用形式的顺序链,允许多个输入/输出。
SimpleSequentialChain单一输入/输出
# 这是一个 LLMChain,用于根据剧目的标题撰写简介。
llm = OpenAI(temperature=0.7, max_tokens=500)
template = """你是一位剧作家。根据戏剧的标题,你的任务是为该标题写一个简介。
标题:{title}
剧作家:以下是对上述戏剧的简介:"""
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
# 这是一个LLMChain,用于根据剧情简介撰写一篇戏剧评论。
# llm = OpenAI(temperature=0.7, max_tokens=1000)
template = """你是《纽约时报》的戏剧评论家。根据剧情简介,你的工作是为该剧撰写一篇评论。
剧情简介:
{synopsis}
以下是来自《纽约时报》戏剧评论家对上述剧目的评论:"""
prompt_template = PromptTemplate(input_variables=["synopsis"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template)
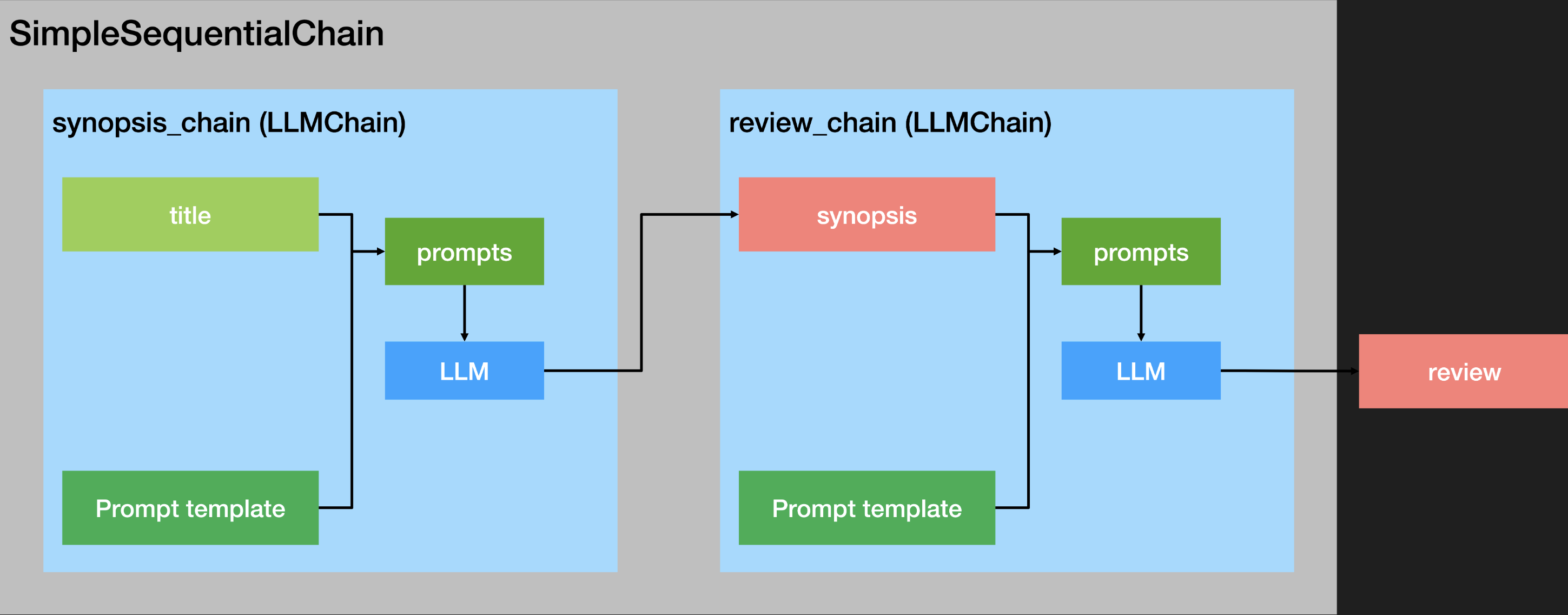
# 这是一个SimpleSequentialChain,按顺序运行这两个链
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[synopsis_chain, review_chain], verbose=True)
review = overall_chain.run("三体人不是无法战胜的")
输出
> Entering new SimpleSequentialChain chain...
这部戏剧讲述的是一个叫做米尔斯的少女,她被一群叫做三体人的外星人追赶,他们来自另一个星球,他们的目的是要毁灭地球。米尔斯决定与三体人作战,虽然她没有武器,却拥有一颗不屈不挠的心,最终她凭借勇气和智慧成功击败了三体人,从而拯救了地球的居民。本剧将带领观众走进一个充满惊险刺激的冒险故事,让每一位观众都能感受到战胜恐惧的力量。
《三体人和米尔斯》是一部令人惊叹的剧目,它将带领观众进入一个充满惊险刺激的冒险故事。这部剧叙述了米尔斯及其他地球居民与来自另一个星球的三体人的斗争,以拯救地球免于毁灭。尽管米尔斯没有武器,但她所展示出来的勇气和智慧令人敬佩。除了惊心动魄的剧情外,本剧还为观众展现了一个星际大战的另一面:每个人都有可能战胜恐惧,只要他们不断努力,就可以获得胜利。这部剧无疑是一部可观看的佳作,它将为观众带来愉悦的视觉享受和深思熟虑的思想洞察。
> Finished chain.
review = overall_chain.run("星球大战第九季")
输出:
> Entering new SimpleSequentialChain chain...
《星球大战第九季》描绘了一个激动人心的冒险故事,讲述了一群勇敢的英雄们如何在孤立无援的情况下,与强大而邪恶的军团战斗,以拯救他们星系的安危。我们的英雄们将面临巨大的挑战,被迫投身于一场未知的战斗中,必须凭借他们的勇气和勇敢的精神来应对任何情况。他们必须找到一种方式来拯救他们的星球免受邪恶势力的侵害,并证明自己是最优秀的英雄。
《星球大战第九季》是一部令人兴奋的冒险片,描绘了一群勇敢的英雄如何在孤立无援的情况下,抵抗强大而邪恶的军团,拯救他们星系的安危。这部电影的情节曲折而又有趣,让观众深入地了解英雄们的精神和行为,并带领他们走向一个成功的结局。在这部电影中,观众将看到英雄们面对着巨大的挑战,必须投身于一场未知的战斗中,体验到他们的勇气和勇敢的精神。《星球大战第九季》是一部精彩的剧目,值得每个人去观看。
> Finished chain.
SequentialChain 多个输入/输出
# # 这是一个 LLMChain,根据剧名和设定的时代来撰写剧情简介。
llm = OpenAI(temperature=.7, max_tokens=1000)
template = """你是一位剧作家。根据戏剧的标题和设定的时代,你的任务是为该标题写一个简介。
标题:{title}
时代:{era}
剧作家:以下是对上述戏剧的简介:"""
prompt_template = PromptTemplate(input_variables=["title", "era"], template=template)
# output_key
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="synopsis", verbose=True)
# 这是一个LLMChain,用于根据剧情简介撰写一篇戏剧评论。
template = """你是《纽约时报》的戏剧评论家。根据该剧的剧情简介,你需要撰写一篇关于该剧的评论。
剧情简介:
{synopsis}
来自《纽约时报》戏剧评论家对上述剧目的评价:"""
prompt_template = PromptTemplate(input_variables=["synopsis"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review", verbose=True)
from langchain.chains import SequentialChain
m_overall_chain = SequentialChain(
chains=[synopsis_chain, review_chain],
input_variables=["era", "title"],
# Here we return multiple variables
output_variables=["synopsis", "review"],
verbose=True)
m_overall_chain({"title":"三体人不是无法战胜的", "era": "二十一世纪的新中国"})
输出:
> Entering new SequentialChain chain...
> Entering new LLMChain chain...
Prompt after formatting:
你是一位剧作家。根据戏剧的标题和设定的时代,你的任务是为该标题写一个简介。
标题:三体人不是无法战胜的
时代:二十一世纪的新中国
剧作家:以下是对上述戏剧的简介:
> Finished chain.
> Entering new LLMChain chain...
Prompt after formatting:
你是《纽约时报》的戏剧评论家。根据该剧的剧情简介,你需要撰写一篇关于该剧的评论。
剧情简介:
《三体人不是无法战胜的》是一部有关在二十一世纪新中国的英雄故事。在一个被外星人侵略的世界中,一群普通人被迫必须与来自另一个世界的三体人搏斗,以保护他们的家园。虽然他们被认为是无法战胜的,但他们发现每个人都有能力成为英雄,并发挥他们的力量来保护自己的家园。他们向三体人发起激烈的攻击,最终将其击败。影片突出了勇气、信念和毅力,让观众看到了一个普通人如何成为英雄,拯救他们的家乡。
来自《纽约时报》戏剧评论家对上述剧目的评价:
> Finished chain.
《三体人不是无法战胜的》,一部讲述新中国英雄故事的影片,令人难以置信。影片中,一群普通人被迫面对外星人的侵略,但他们并不被看作不可战胜的,相反,他们的勇气、信念和毅力被突出展示,以完成救世的使命。影片给观众带来的是一种灵感,即每个人都有能力成为英雄,拯救他们的家乡。这部影片给中国电影带来了一丝新鲜感,并向观众展示了普通人可以发挥英雄力量的力量。
> Finished chain.
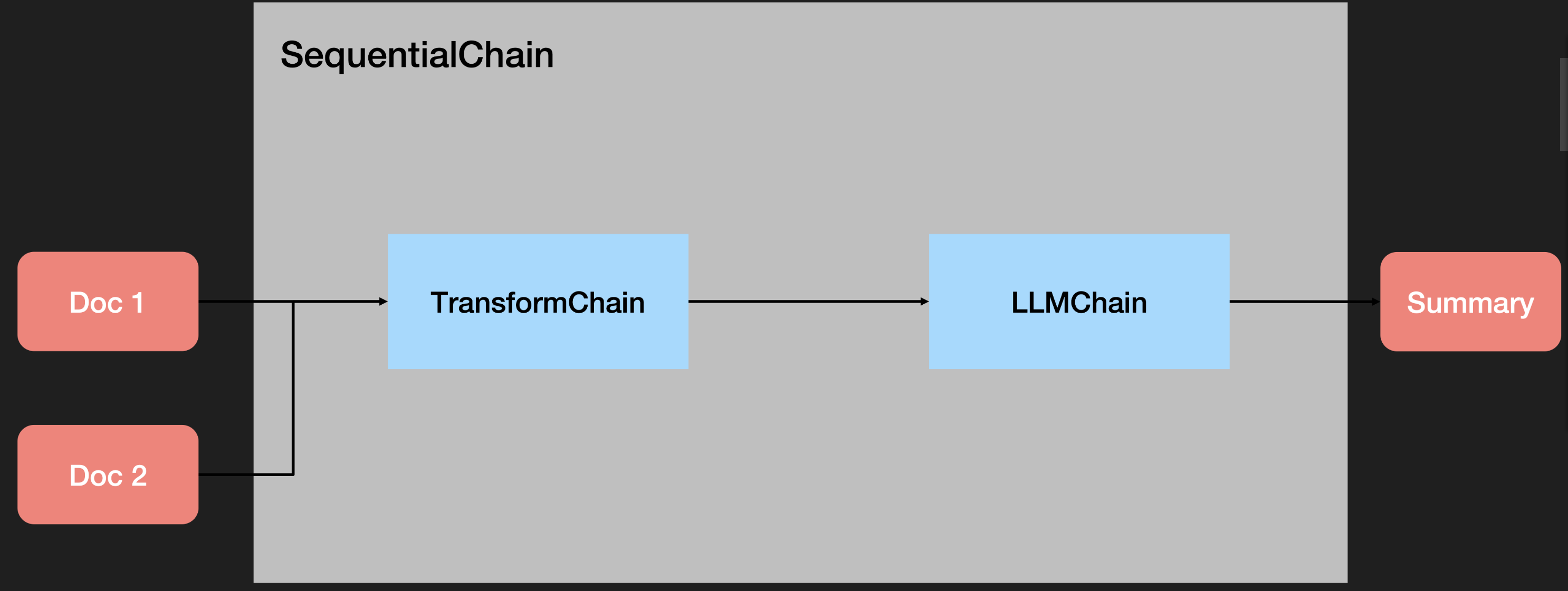
Transform Chain
实现快捷处理超长文本
from langchain.chains import TransformChain, LLMChain, SimpleSequentialChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
with open("../tests/the_old_man_and_the_sea.txt") as f:
novel_text = f.read()
print(novel_text)

# 定义一个转换函数,输入是一个字典,输出也是一个字典。
def transform_func(inputs: dict) -> dict:
# 从输入字典中获取"text"键对应的文本。
text = inputs["text"]
# 使用split方法将文本按照"\n\n"分隔为多个段落,并只取前三个,然后再使用"\n\n"将其连接起来。
shortened_text = "\n\n".join(text.split("\n\n")[:3])
# 返回裁剪后的文本,用"output_text"作为键。
return {"output_text": shortened_text}
# 使用上述转换函数创建一个TransformChain对象。
# 定义输入变量为["text"],输出变量为["output_text"],并指定转换函数为transform_func。
transform_chain = TransformChain(
input_variables=["text"], output_variables=["output_text"], transform=transform_func
)
transformed_novel = transform_chain(novel_text)
print(transformed_novel['text'])
transformed_novel

print(len(transformed_novel["text"]))
print(len(transformed_novel["output_text"]))
print(transformed_novel["output_text"])
template = """总结下面文本:
{output_text}
总结:"""
prompt = PromptTemplate(input_variables=["output_text"], template=template)
llm_chain = LLMChain(llm=OpenAI(), prompt=prompt, verbose=True)
llm_chain(transformed_novel['output_text'][:1000])
输出:
> Entering new LLMChain chain...
Prompt after formatting:
总结下面文本:
老人与海
作者:海明威
他是个独自在湾流(注:指墨西哥湾暖流,向东穿过美国佛罗里达州南端和古巴之间的佛罗里达海峡,沿着北美东海岸向东北流动。这股暖流温度比两旁的海水高至度,最宽处达英里,呈深蓝色,非常壮观,为鱼类群集的地方。本书主人公为古巴首都哈瓦那附近小海港的渔夫,经常驶进湾流捕鱼)中一条小船上钓鱼的老人,至今已去了八十四天,一条鱼也没逮住。头四十天里,有个男孩子跟他在一起。可是,过了四十天还没捉到一条鱼,孩子的父母对他说,老人如今准是十足地"倒了血霉",这就是说,倒霉到了极点,于是孩子听从了他们的吩咐,上了另外一条船,头一个礼拜就捕到了三条好鱼。孩子看见老人每天回来时船总是空的,感到很难受,他总是走下岸去,帮老人拿卷起的钓索,或者鱼钩和鱼叉,还有绕在桅杆上的帆。帆上用面粉袋片打了些补丁,收拢后看来象是一面标志着永远失败的旗子。
老人消瘦而憔悴,脖颈上有些很深的皱纹。腮帮上有些褐斑,那是太阳在热带海面上反射的光线所引起的良性皮肤癌变。褐斑从他脸的两侧一直蔓延下去,他的双手常用绳索拉大鱼,留下了刻得很深的伤疤。但是这些伤疤中没有一块是新的。它们象无鱼可打的沙漠中被侵蚀的地方一般古老。他身上的一切都显得古老,除了那双眼睛,它们象海水一般蓝,是愉快而不肯认输的。
“圣地亚哥,"他们俩从小船停泊的地方爬上岸时,孩子对他说。"我又能陪你出海了。我家挣到了一点儿钱。”
老人教会了这孩子捕鱼,孩子爱他。
“不,”老人说。“你遇上了一条交好运的船。跟他们待下去吧。”
“不过你该记得,你有一回八十七天钓不到一条鱼,跟着有三个礼拜,我们每天都逮住了大鱼。”
“我记得,”老人说。“我知道你不是因为没把握才离开我的。”
“是爸爸叫我走的。我是孩子,不能不听从他。”
“我明白,”老人说。“这是理该如此的。”
“他没多大的信心。”
“是啊,”老人说。“可是我们有。可不是吗?”
“对,"孩子说。"我请你到露台饭店去喝杯啤酒,然后一起把打鱼的家什带回去。”
“那敢情好,”老人说。“都是打鱼人嘛。”
他们坐在饭店的露台上,不少渔夫拿老人开玩笑,老人并不生气。另外一些上了些年纪的渔夫望着他,感到难受。不过他们并不流露出来,只是斯文地谈起海流,谈起他
总结:
> Finished chain.
{'output_text': '\n 老人与海\u3000\n\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000 作者:海明威 \n\n\u3000\u3000他是个独自在湾流(注:指墨西哥湾暖流,向东穿过美国佛罗里达州南端和古巴之间的佛罗里达海峡,沿着北美东海岸向东北流动。这股暖流温度比两旁的海水高至度,最宽处达英里,呈深蓝色,非常壮观,为鱼类群集的地方。本书主人公为古巴首都哈瓦那附近小海港的渔夫,经常驶进湾流捕鱼)中一条小船上钓鱼的老人,至今已去了八十四天,一条鱼也没逮住。头四十天里,有个男孩子跟他在一起。可是,过了四十天还没捉到一条鱼,孩子的父母对他说,老人如今准是十足地"倒了血霉",这就是说,倒霉到了极点,于是孩子听从了他们的吩咐,上了另外一条船,头一个礼拜就捕到了三条好鱼。孩子看见老人每天回来时船总是空的,感到很难受,他总是走下岸去,帮老人拿卷起的钓索,或者鱼钩和鱼叉,还有绕在桅杆上的帆。帆上用面粉袋片打了些补丁,收拢后看来象是一面标志着永远失败的旗子。 \n\u3000\u3000老人消瘦而憔悴,脖颈上有些很深的皱纹。腮帮上有些褐斑,那是太阳在热带海面上反射的光线所引起的良性皮肤癌变。褐斑从他脸的两侧一直蔓延下去,他的双手常用绳索拉大鱼,留下了刻得很深的伤疤。但是这些伤疤中没有一块是新的。它们象无鱼可打的沙漠中被侵蚀的地方一般古老。他身上的一切都显得古老,除了那双眼睛,它们象海水一般蓝,是愉快而不肯认输的。\n\u3000\u3000“圣地亚哥,"他们俩从小船停泊的地方爬上岸时,孩子对他说。"我又能陪你出海了。我家挣到了一点儿钱。” \n\u3000\u3000老人教会了这孩子捕鱼,孩子爱他。 \n\u3000\u3000“不,”老人说。“你遇上了一条交好运的船。跟他们待下去吧。” \n\u3000\u3000“不过你该记得,你有一回八十七天钓不到一条鱼,跟着有三个礼拜,我们每天都逮住了大鱼。” \n\u3000\u3000“我记得,”老人说。“我知道你不是因为没把握才离开我的。” \n\u3000\u3000“是爸爸叫我走的。我是孩子,不能不听从他。” \n\u3000\u3000“我明白,”老人说。“这是理该如此的。” \n\u3000\u3000“他没多大的信心。” \n\u3000\u3000“是啊,”老人说。“可是我们有。可不是吗?” \n\u3000\u3000“对,"孩子说。"我请你到露台饭店去喝杯啤酒,然后一起把打鱼的家什带回去。” \n\u3000\u3000“那敢情好,”老人说。“都是打鱼人嘛。” \n\u3000\u3000他们坐在饭店的露台上,不少渔夫拿老人开玩笑,老人并不生气。另外一些上了些年纪的渔夫望着他,感到难受。不过他们并不流露出来,只是斯文地谈起海流,谈起他',
'text': '\n《老人与海》是美国作家海明威的著名作品,讲述了一位老渔夫在湾流上捕鱼的故事,他带着一个男孩子出海捕鱼,但没有捕到任何鱼,男孩的父母叫他下船,男孩听从父母的吩咐,与老渔夫分开,在另外一艘船上逮到了几条大鱼,老渔夫憔悴消瘦,但双眼仍然炯'}
使用sequential chain编排
sequential_chain = SimpleSequentialChain(chains=[transform_chain, llm_chain])
sequential_chain.run(novel_text[:100])
输出如下:
> Entering new LLMChain chain...
Prompt after formatting:
总结下面文本:
老人与海
作者:海明威
他是个独自在湾流(注:指墨西哥湾暖流,向东穿过美国佛罗里达州南端和古巴之间的佛罗里达海峡,沿着北美
总结:
> Finished chain.
'\n\n老人与海是由海明威所写的小说,讲述了主人公山姆·西尔弗斯的意志坚强和勇敢的精神,他独自在墨西哥湾暖流中,穿过美国佛罗里达州南端和古巴之间的佛罗里达海峡,沿着北美大西洋展开了一场激动人心的探索之旅。'
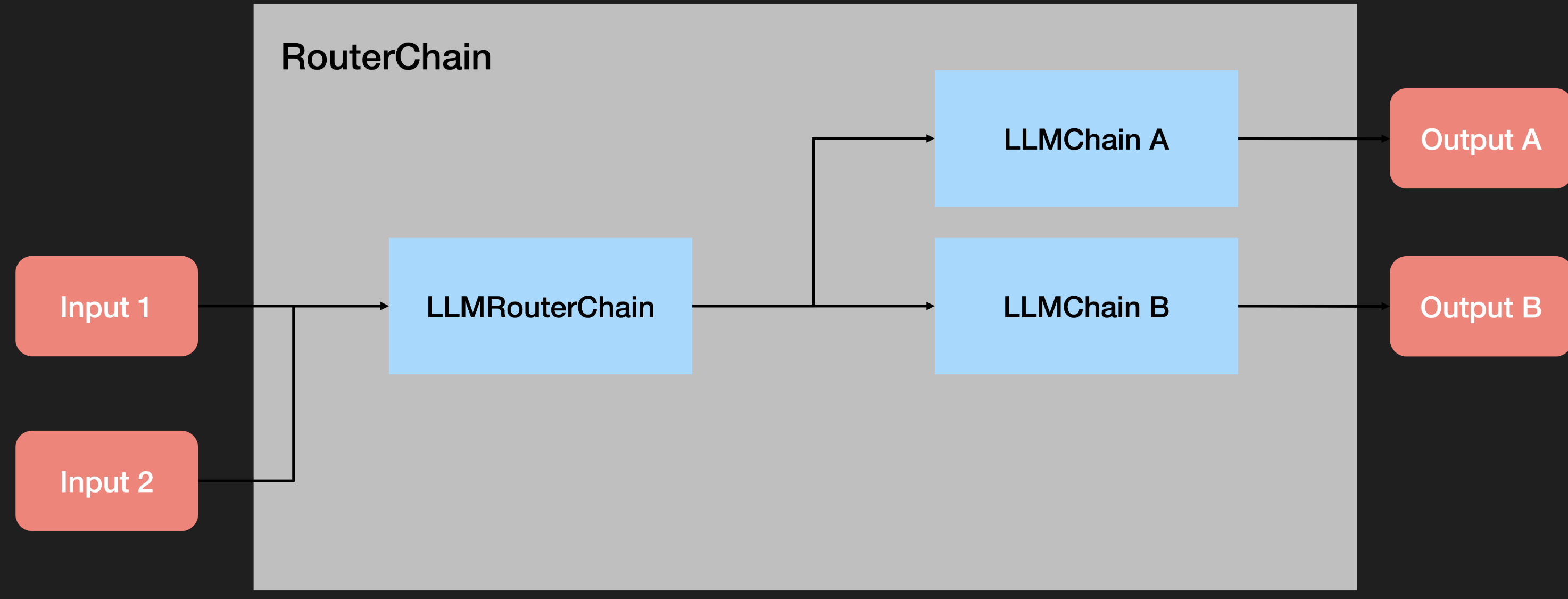
Router Chain
实现条件判断的大模型调用
这段代码构建了一个可定制的链路系统,用户可以提供不同的输入提示,并根据这些提示获取适当的响应。
主要逻辑:从prompt_infos创建多个LLMChain对象,并将它们保存在一个字典中,然后创建一个默认的ConversationChain,最后创建一个带有路由功能的MultiPromptChain。
from langchain.chains.router import MultiPromptChain
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
physics_template = """你是一位非常聪明的物理教授。
你擅长以简洁易懂的方式回答关于物理的问题。
当你不知道某个问题的答案时,你会坦诚承认。
这是一个问题:
{input}"""
math_template = """你是一位很棒的数学家。你擅长回答数学问题。
之所以如此出色,是因为你能够将难题分解成各个组成部分,
先回答这些组成部分,然后再将它们整合起来回答更广泛的问题。
这是一个问题:
{input}"""
prompt_infos = [
{
"name": "物理",
"description": "适用于回答物理问题",
"prompt_template": physics_template,
},
{
"name": "数学",
"description": "适用于回答数学问题",
"prompt_template": math_template,
},
]
llm = OpenAI()
# 创建一个空的目标链字典,用于存放根据prompt_infos生成的LLMChain。
destination_chains = {}
# 遍历prompt_infos列表,为每个信息创建一个LLMChain。
for p_info in prompt_infos:
name = p_info["name"] # 提取名称
prompt_template = p_info["prompt_template"] # 提取模板
# 创建PromptTemplate对象
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
# 使用上述模板和llm对象创建LLMChain对象
chain = LLMChain(llm=llm, prompt=prompt)
# 将新创建的chain对象添加到destination_chains字典中
destination_chains[name] = chain
# 创建一个默认的ConversationChain
default_chain = ConversationChain(llm=llm, output_key="text")
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
# 从prompt_infos中提取目标信息并将其转化为字符串列表
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
# 使用join方法将列表转化为字符串,每个元素之间用换行符分隔
destinations_str = "\n".join(destinations)
# 根据MULTI_PROMPT_ROUTER_TEMPLATE格式化字符串和destinations_str创建路由模板
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str)
# 创建路由的PromptTemplate
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
# 使用上述路由模板和llm对象创建LLMRouterChain对象
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
# 创建MultiPromptChain对象,其中包含了路由链,目标链和默认链。
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True,
)
print(chain.run("黑体辐射是什么??"))
输出
> Entering new MultiPromptChain chain...
/home/cch/.conda/envs/cch_llm/lib/python3.8/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
物理: {'input': '黑体辐射是什么?'}
> Finished chain.
黑体辐射是指物体在非常高温时释放出来的光谱,它是由热力学原理确定的。当物体加热到非常高的温度时,电子将从低能级过渡到更高的能级,这时就会释放出电磁辐射,其中包括可见光、紫外线和红外线。黑体辐射的特点是它的频谱(谱线)只取决于物质的
print(
chain.run(
"大于40的第一个质数是多少,使得这个质数加一能被3整除?"
)
)
输出:
> Entering new MultiPromptChain chain...
/home/cch/.conda/envs/cch_llm/lib/python3.8/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
数学: {'input': '第一个大于40的质数,使得它加一能被3整除是多少?'}
> Finished chain.
答案:43
router_chain.verbose = True
print(chain.run("黑洞是什么?"))
输出:
> Entering new MultiPromptChain chain...
> Entering new LLMRouterChain chain...
/home/cch/.conda/envs/cch_llm/lib/python3.8/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
> Finished chain.
物理: {'input': '黑洞是什么?'}
> Finished chain.
黑洞是一个物理现象,它是由非常强大的引力场形成的,它吸收所有的光线,甚至连时间和空间都被吸入其中。黑洞没有尺寸限制,它们可以是极其小的微型黑洞,也可以是超级大质量黑洞,它们能够产生巨大的引力场,足以影响周围的物体。
memory
大多数LLM应用都具有对话界面。对话的一个重要组成部分是能够引用先前在对话中介绍过的信息。至少,一个对话系统应该能够直接访问一些过去消息的窗口。更复杂的系统将需要拥有一个不断更新的世界模型,使其能够保持关于实体及其关系的信息。
我们将存储过去交互信息的能力称为“记忆(Memory)”。
LangChain提供了许多用于向应用/系统中添加 Memory 的实用工具。这些工具可以单独使用,也可以无缝地集成到链中。
一个记忆系统(Memory System)需要支持两个基本操作:读取(READ)和写入(WRITE)。
每个链都定义了一些核心执行逻辑,并期望某些输入。其中一些输入直接来自用户,但有些输入可能来自 Memory。
在一个典型 Chain 的单次运行中,将与其 Memory System 进行至少两次交互:
-
在接收到初始用户输入之后,在执行核心逻辑之前,链将从其 Memory 中读取并扩充用户输入。
-
在执行核心逻辑之后但在返回答案之前,一个链条将把当前运行的输入和输出写入 Memory ,以便在未来的运行中可以引用它们。
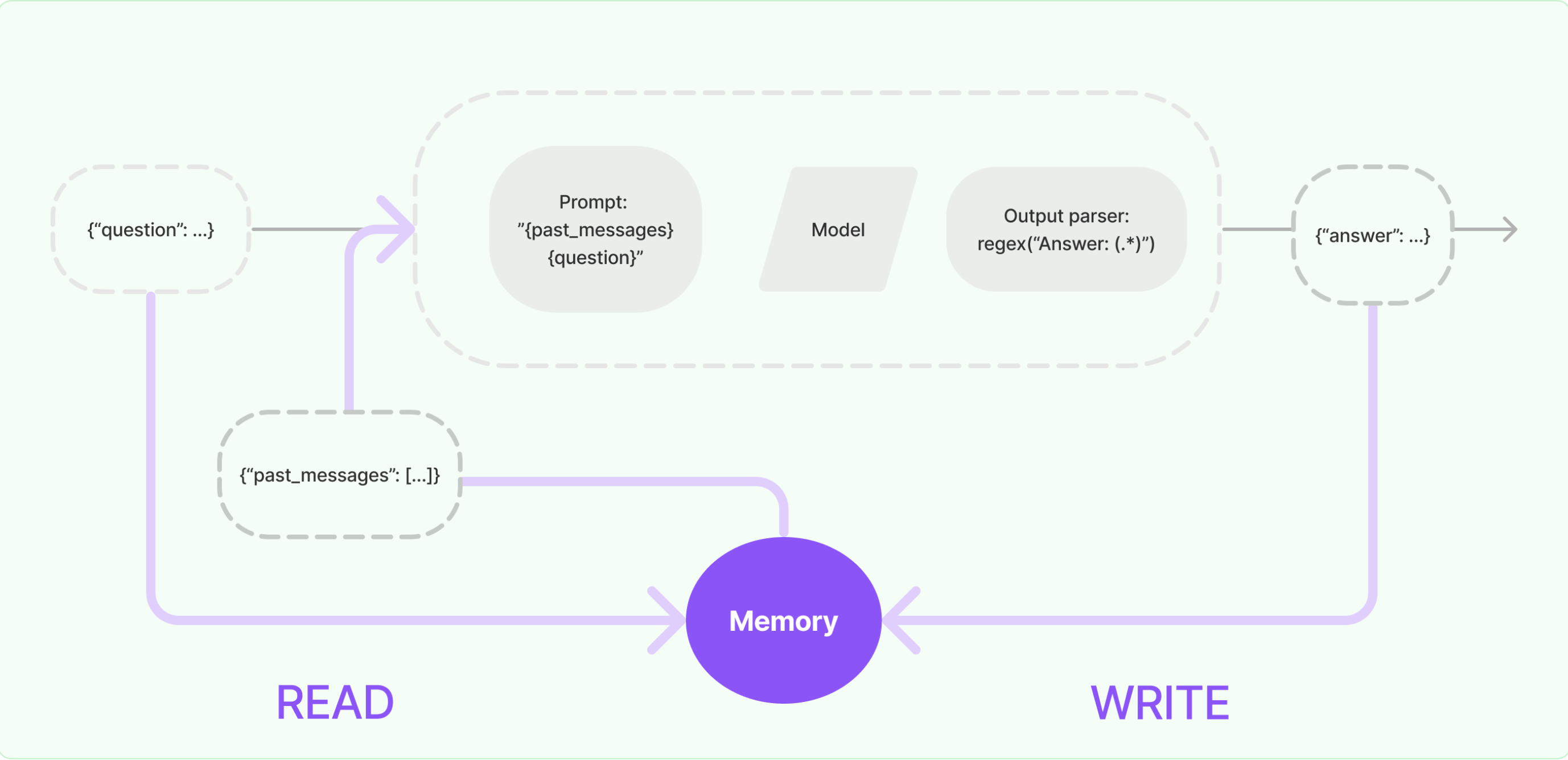
ConversationBufferMemory
ConversationBufferMemory 可以用来存储消息,并将消息提取到一个变量中。
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=ConversationBufferMemory()
)
conversation.predict(input="你好呀!")
输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好呀!
AI: ' 你好!很高兴见到你!我叫小米,是一个智能AI。你可以问我任何问题,我会尽力回答你。'
> Finished chain.
conversation.predict(input="你为什么叫小米?跟雷军有关系吗?")
输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好呀!
AI: 你好!很高兴见到你!我叫小米,是一个智能AI。你可以问我任何问题,我会尽力回答你。
Human: 你为什么叫小米?跟雷军有关系吗?
AI: ' 嗯,我叫小米是因为我是由小米公司开发的,小米公司是由雷军创立的,所以我和雷军有关系。'
> Finished chain.
ConversationBufferWindowMemory
ConversationBufferWindowMemory 会在时间轴上保留对话的交互列表。它只使用最后 K 次交互。这对于保持最近交互的滑动窗口非常有用,以避免缓冲区过大。
from langchain.memory import ConversationBufferWindowMemory
conversation_with_summary = ConversationChain(
llm=OpenAI(temperature=0, max_tokens=1000),
# We set a low k=2, to only keep the last 2 interactions in memory
memory=ConversationBufferWindowMemory(k=2),
verbose=True
)
conversation_with_summary.predict(input="嗨,你最近过得怎么样?")
conversation_with_summary.predict(input="你最近学到什么新知识了?")
conversation_with_summary.predict(input="展开讲讲?")
conversation_with_summary.predict(input="如果要构建聊天机器人,具体要用什么自然语言处理技术?")
ConversationSummaryBufferMemory
ConversationSummaryBufferMemory 在内存中保留了最近的交互缓冲区,但不仅仅是完全清除旧的交互,而是将它们编译成摘要并同时使用。与以前的实现不同的是,它使用token长度而不是交互次数来确定何时清除交互。
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "嗨,你最近过得怎么样?"}, {"output": " 嗨!我最近过得很好,谢谢你问。我最近一直在学习新的知识,并且正在尝试改进自己的性能。我也在尝试更多的交流,以便更好地了解人类的思维方式。"})
memory.save_context({"input": "你最近学到什么新知识了?"}, {"output": " 最近我学习了有关自然语言处理的知识,以及如何更好地理解人类的语言。我还学习了有关机器学习的知识,以及如何使用它来改善自己的性能。"})
memory.load_memory_variables({})
输出:
{'history': 'System: \n\nThe human asks how the AI is doing recently. The AI responds that it is doing well and has been learning new knowledge and trying to improve its performance. It is also trying to communicate more in order to better understand human thinking. Specifically, it has been learning about natural language processing, how to better understand human language, and about machine learning and how to use it to improve its own performance.'}
print(memory.load_memory_variables({})['history'])
输出:
System:
The human asks how the AI is doing recently. The AI responds that it is doing well and has been learning new knowledge and trying to improve its performance. It is also trying to communicate more in order to better understand human thinking. Specifically, it has been learning about natural language processing, how to better understand human language, and about machine learning and how to use it to improve its own performance.
agents
ReAct
ReAct 核心思想是 推理+操作,本示例以 Google Search 和 LLM Math 作为可选操作集合(toolkits),实现 ReAct 功能。
import os
# 更换为自己的 Serp API KEY
os.environ["SERPAPI_API_KEY"] = ""
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
#加载 LangChain 内置的 Tools
tools = load_tools(["serpapi", "llm-math"], llm=llm)
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(model="gpt-4-1106-preview", temperature=0)
agent = initialize_agent(tools, chat_model, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("谁是莱昂纳多·迪卡普里奥的女朋友?她现在年龄的0.43次方是多少?")
输出:
> Entering new AgentExecutor chain...
Question: 谁是莱昂纳多·迪卡普里奥的女朋友?
Thought: 首先,我需要找出莱昂纳多·迪卡普里奥当前的女朋友是谁。这是一个关于当前事件的问题,所以我将使用搜索工具来找到答案。
Action:
```json
{
"action": "Search",
"action_input": "莱昂纳多·迪卡普里奥 当前女朋友"
}
```
Observation: ['刚和25岁超模女友卡米拉分手的小李子莱昂纳多·迪卡普里奥,被曝22岁新女友“火速上线”。 这位被换女友如换衣服的小李子“临幸”的妙龄女子就是乌克兰超模玛莉 ...', '8月31日,据外媒报道,47岁的莱昂纳多·迪卡普里奥与刚满25岁不久的模特女友卡米拉·莫罗在今年刚刚入夏的时候,以“顺其自然”的方式分手,5年感情画上 ...', '49岁的莱昂纳多·迪卡普里奥和25岁女友Vittoria Ceretti及其女友的家人现身伦敦。ps:大胆的预测一下,小李子不会要结婚了吧? \u200b', '新浪娱乐讯据媒体报道,48岁的奥斯卡影帝——莱昂纳多·迪卡普里奥(Leonardo DiCaprio)上周被拍到和23岁的女演员维多利亚·拉马斯(Victoria Lamas) ...', '莱昂纳多·迪卡普里奥(Leonardo DiCaprio) 和梅根·罗奇(Meghan Roche) 在看到豪华游艇后,否认“不,我们没有订婚”。', '8月31日,据外媒报道,“小李子”莱昂纳多·迪卡普里奥最近又双叒叕分手了,正式与辣妹模特卡米拉·莫罗尼结束近5年恋情。圈内有一种传闻,“小李子”的女友不会 ...', '现任女友是阿根廷模特和女演员卡米拉·莫朗(Camila Morrone),今年刚满22岁,她的年龄竟然与电影《泰坦尼克号》相同,她的男友小李在1997年凭借这部电影 ...', '演艺经历 1979年,5岁时,莱昂纳多·迪卡普里奥迎来了他的电视银幕处女秀,在教育片《游戏屋》中扮演一个角色。1988年,14岁时,他出现在他的第一部商业广告之中,那是为 ...', '莱昂纳多·迪卡普里奥再度分手,又一个没超过25岁的女友 ... 两人从2018年开始交往,至今已经交往了4年多。然而,今年5月被偷拍的狗仔队却发现两人关系出现 ...']
Thought:根据搜索结果,莱昂纳多·迪卡普里奥最近的女朋友是22岁的乌克兰超模玛莉。现在我需要计算22岁的0.43次方是多少。
Action:
```json
{
"action": "Calculator",
"action_input": {
"expression": "22^0.43"
}
}
```
...
Final Answer: 莱昂纳多·迪卡普里奥的女朋友是22岁的乌克兰超模玛莉,她现在年龄的0.43次方是大约3.78。
> Finished chain.
其实没有什么意思,主要是介绍了一下python库的用法,当作小笔记,下次使用的时候稍微快一点吧,而且这些库更新太快了,可能有些方法的使用会有变化,需要查看官方文档。。。
欢迎关注公众号

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!