分布式【Zookeeper】
1.1 ZooKeeper 是什么
ZooKeeper 是 Apache 的顶级项目。ZooKeeper 为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如统一命名服务、配置管理和分布式锁等分布式的基础服务。在解决分布式数据一致性方面,ZooKeeper 并没有直接采用 Paxos 算法,而是采用了名为 ZAB 的一致性协议。
ZooKeeper 主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储。但是 ZooKeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控存储数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。
很多大名鼎鼎的框架都基于 ZooKeeper 来实现分布式高可用,如:Dubbo、Kafka 等。
1.2 ZooKeeper 的特性
ZooKeeper 具有以下特性:
- **顺序一致性:**所有客户端看到的服务端数据模型都是一致的;从一个客户端发起的事务请求,最终都会严格按照其发起顺序被应用到 ZooKeeper 中。具体的实现可见下文:原子广播。
- **原子性:**所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,即整个集群要么都成功应用了某个事务,要么都没有应用。实现方式可见下文:事务。
- **单一视图:**无论客户端连接的是哪个 Zookeeper 服务器,其看到的服务端数据模型都是一致的。
- **高性能:**ZooKeeper 将数据全量存储在内存中,所以其性能很高。需要注意的是:由于 ZooKeeper 的所有更新和删除都是基于事务的,因此 ZooKeeper在读多写少的应用场景中有性能表现较好,如果写操作频繁,性能会大大下滑。
- **高可用:**ZooKeeper 的高可用是基于副本机制实现的,此外 ZooKeeper 支持故障恢复,可见下文:选举 Leader。
1.3 ZooKeeper 的设计目标
- 简单的数据模型
- 可以构建集群
- 顺序访问
- 高性能
二、ZooKeeper 核心概念
2.1 数据模型
ZooKeeper 的数据模型是一个树形结构的文件系统。
树中的节点被称为 znode,其中根节点为 /,每个节点上都会保存自己的数据和节点信息。znode 可以用于存储数据,并且有一个与之相关联的 ACL(详情可见 ACL)。ZooKeeper 的设计目标是实现协调服务,而不是真的作为一个文件存储,因此 znode 存储数据的大小被限制在 1MB 以内。
**ZooKeeper 的数据访问具有原子性。**其读写操作都是要么全部成功,要么全部失败。
znode 通过路径被引用。znode 节点路径必须是绝对路径。
znode 有两种类型:
- **临时的( EPHEMERAL ):**户端会话结束时,ZooKeeper 就会删除临时的 znode。
- **持久的(PERSISTENT ):**除非客户端主动执行删除操作,否则 ZooKeeper 不会删除持久的 znode。
2.2 节点信息
znode 上有一个顺序标志( SEQUENTIAL )。如果在创建 znode 时,设置了顺序标志( SEQUENTIAL ),那么 ZooKeeper 会使用计数器为 znode 添加一个单调递增的数值,即 zxid。ZooKeeper 正是利用 zxid 实现了严格的顺序访问控制能力。
每个 znode 节点在存储数据的同时,都会维护一个叫做 Stat 的数据结构,里面存储了关于该节点的全部状态信息。如下:
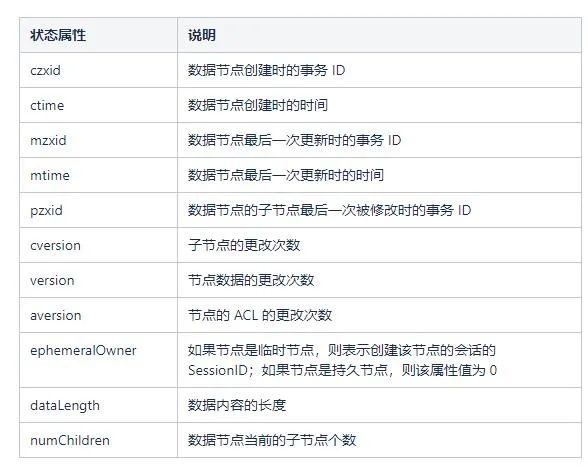
2.3 集群角色
Zookeeper 集群是一个基于主从复制的高可用集群,每个服务器承担如下三种角色中的一种。
- **Leader:**它负责 发起并维护与各 Follwer 及 Observer 间的心跳。所有的写操作必须要通过 Leader 完成再由 Leader 将写操作广播给其它服务器。一个 Zookeeper 集群同一时间只会有一个实际工作的 Leader。
- **Follower:**它会响应 Leader 的心跳。Follower 可直接处理并返回客户端的读请求,同时会将写请求转发给 Leader 处理,并且负责在 Leader 处理写请求时对请求进行投票。一个 Zookeeper 集群可能同时存在多个 Follower。
- **Observer:**角色与 Follower 类似,但是无投票权。
2.4 ACL
ZooKeeper 采用 ACL(Access Control Lists)策略来进行权限控制。
每个 znode 创建时都会带有一个 ACL 列表,用于决定谁可以对它执行何种操作。
ACL 依赖于 ZooKeeper 的客户端认证机制。ZooKeeper 提供了以下几种认证方式:
- digest: 用户名和密码 来识别客户端
- **sasl:**通过 kerberos 来识别客户端
- **ip:**通过 IP 来识别客户端
ZooKeeper 定义了如下五种权限:
- **CREATE:**允许创建子节点;
- **READ:**允许从节点获取数据并列出其子节点;
- WRITE: 允许为节点设置数据;
- **DELETE:**允许删除子节点;
- ADMIN: 允许为节点设置权限。
三、ZooKeeper 工作原理
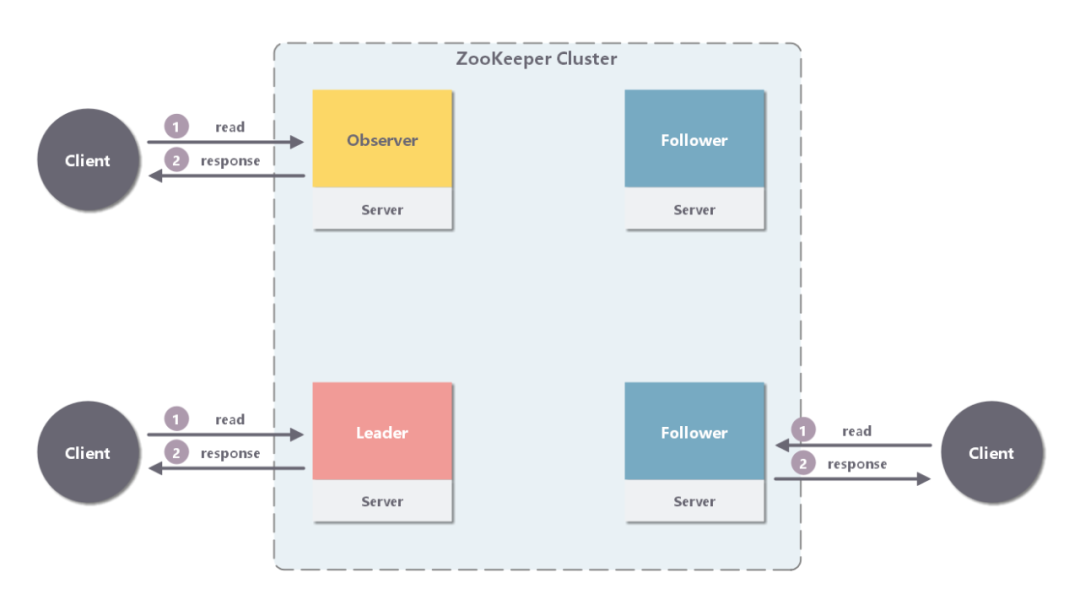
3.1 读操作
Leader/Follower/Observer 都可直接处理读请求,从本地内存中读取数据并返回给客户端即可。
由于处理读请求不需要服务器之间的交互,Follower/Observer 越多,整体系统的读请求吞吐量越大,也即读性能越好。
3.2 写操作
所有的写请求实际上都要交给 Leader 处理。Leader 将写请求以事务形式发给所有 Follower 并等待 ACK,一旦收到半数以上 Follower 的 ACK,即认为写操作成功。
3.2.1 写 Leader
通过 Leader 进行写操作,主要分为五步:
- 客户端向 Leader 发起写请求。
- Leader 将写请求以事务 Proposal 的形式发给所有 Follower 并等待 ACK。
- Follower 收到 Leader 的事务 Proposal 后返回 ACK。
- Leader 得到过半数的 ACK(Leader 对自己默认有一个 ACK)后向所有的 Follower 和 Observer 发送 Commmit。
- Leader 将处理结果返回给客户端。
注意
- Leader 不需要得到 Observer 的 ACK,即 Observer 无投票权。
- Leader 不需要得到所有 Follower 的 ACK,只要收到过半的 ACK 即可,同时 Leader 本身对自己有一个 ACK。上图中有 4 个 Follower,只需其中两个返回 ACK 即可,因为 ( 2 + 1 ) / ( 4 + 1 ) > 1 / 2 (2+1) / (4+1) > 1/2 (2+1)/(4+1)>1/2 。
- Observer 虽然无投票权,但仍须同步 Leader 的数据从而在处理读请求时可以返回尽可能新的数据。
3.2.2 写 Follower/Observer
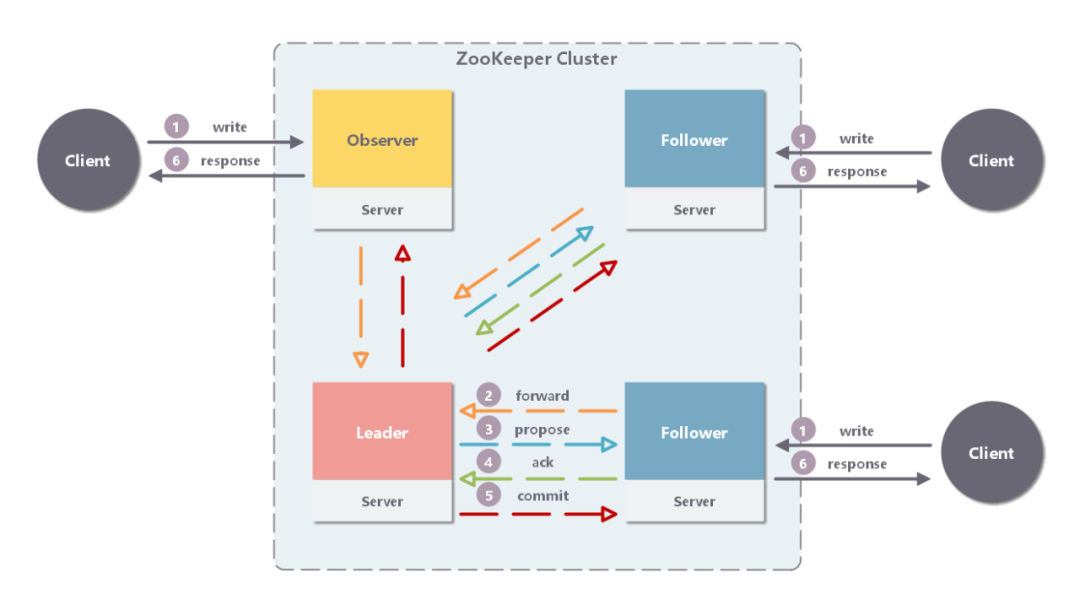
Follower/Observer 均可接受写请求,但不能直接处理,而需要将写请求转发给 Leader 处理。
除了多了一步请求转发,其它流程与直接写 Leader 无任何区别。
3.3 事务
对于来自客户端的每个更新请求,ZooKeeper 具备严格的顺序访问控制能力。
为了保证事务的顺序一致性,ZooKeeper 采用了递增的事务 id 号(zxid)来标识事务。
**Leader 服务会为每一个 Follower 服务器分配一个单独的队列,然后将事务 Proposal 依次放入队列中,并根据 FIFO(先进先出) 的策略进行消息发送。**Follower 服务在接收到 Proposal 后,会将其以事务日志的形式写入本地磁盘中,并在写入成功后反馈给 Leader 一个 Ack 响应。**当 Leader 接收到超过半数 Follower 的 Ack 响应后,就会广播一个 Commit 消息给所有的 Follower 以通知其进行事务提交,**之后 Leader 自身也会完成对事务的提交。而每一个 Follower 则在接收到 Commit 消息后,完成事务的提交。
所有的提议(proposal)都在被提出的时候加上了 zxid。zxid 是一个 64 位的数字,它的高 32 位是 epoch 用来标识 Leader 关系是否改变,每次一个 Leader 被选出来,它都会有一个新的 epoch,标识当前属于那个 leader 的统治时期。低 32 位用于递增计数。
详细过程如下:
- Leader 等待 Server 连接;
- Follower 连接 Leader,将最大的 zxid 发送给 Leader;
- Leader 根据 Follower 的 zxid 确定同步点;
- 完成同步后通知 follower 已经成为 uptodate 状态;
- Follower 收到 uptodate 消息后,又可以重新接受 client 的请求进行服务了。
3.4 观察
客户端注册监听它关心的 znode,当 znode 状态发生变化(数据变化、子节点增减变化)时,ZooKeeper 服务会通知客户端。
客户端和服务端保持连接一般有两种形式:
- 客户端向服务端不断轮询
- 服务端向客户端推送状态
Zookeeper 的选择是服务端主动推送状态,也就是观察机制( Watch )。
ZooKeeper 的观察机制允许用户在指定节点上针对感兴趣的事件注册监听,当事件发生时,监听器会被触发,并将事件信息推送到客户端。
客户端使用 getData 等接口获取 znode 状态时传入了一个用于处理节点变更的回调,那么服务端就会主动向客户端推送节点的变更:
从这个方法中传入的 Watcher 对象实现了相应的 process 方法,每次对应节点出现了状态的改变,WatchManager 都会通过以下的方式调用传入 Watcher 的方法:
Set<Watcher> triggerWatch(String path, EventType type, Set<Watcher> supress) {
WatchedEvent e = new WatchedEvent(type, KeeperState.SyncConnected, path);
Set<Watcher> watchers;
synchronized (this) {
watchers = watchTable.remove(path);
}
for (Watcher w : watchers) {
w.process(e);
}
return
Zookeeper 中的所有数据其实都是由一个名为 DataTree 的数据结构管理的,所有的读写数据的请求最终都会改变这颗树的内容,在发出读请求时可能会传入 Watcher 注册一个回调函数,而写请求就可能会触发相应的回调,由 WatchManager 通知客户端数据的变化。
通知机制的实现其实还是比较简单的,通过读请求设置 Watcher 监听事件,写请求在触发事件时就能将通知发送给指定的客户端。
3.5 会话
ZooKeeper 客户端通过 TCP 长连接连接到 ZooKeeper 服务集群。会话 (Session) 从第一次连接开始就已经建立,之后通过心跳检测机制来保持有效的会话状态。通过这个连接,客户端可以发送请求并接收响应,同时也可以接收到 Watch 事件的通知。
每个 ZooKeeper 客户端配置中都配置了 ZooKeeper 服务器集群列表。启动时,客户端会遍历列表去尝试建立连接。如果失败,它会尝试连接下一个服务器,依次类推。
一旦一台客户端与一台服务器建立连接,这台服务器会为这个客户端创建一个新的会话。**每个会话都会有一个超时时间,若服务器在超时时间内没有收到任何请求,则相应会话被视为过期。**一旦会话过期,就无法再重新打开,且任何与该会话相关的临时 znode 都会被删除。
通常来说,会话应该长期存在,而这需要由客户端来保证。客户端可以通过心跳方式(ping)来保持会话不过期。
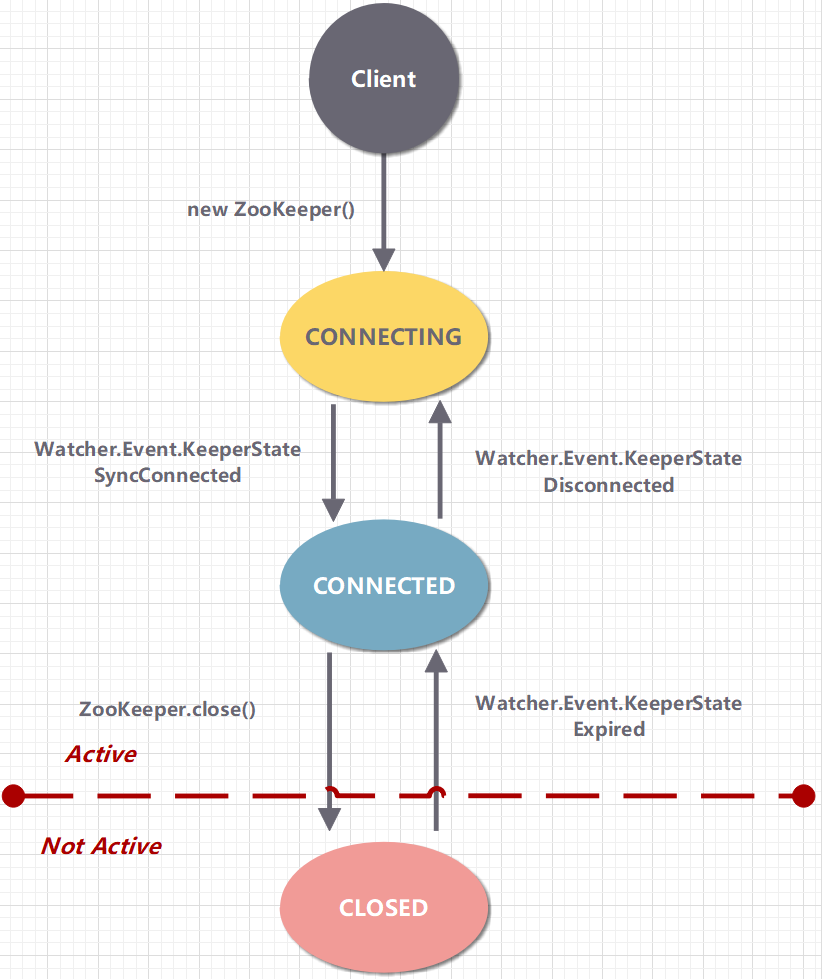
ZooKeeper 的会话具有四个属性:
- **sessionID:**会话 ID,唯一标识一个会话,每次客户端创建新的会话时,Zookeeper 都会为其分配一个全局唯一的 sessionID。
- **TimeOut:**会话超时时间,客户端在构造 Zookeeper 实例时,会配置 sessionTimeout 参数用于指定会话的超时时间,Zookeeper 客户端向服务端发送这个超时时间后,服务端会根据自己的超时时间限制最终确定会话的超时时间。
- **TickTime:**下次会话超时时间点,为了便于 Zookeeper 对会话实行”分桶策略”管理,同时为了高效低耗地实现会话的超时检查与清理,Zookeeper 会为每个会话标记一个下次会话超时时间点,其值大致等于当前时间加上 TimeOut。
- **isClosing:**标记一个会话是否已经被关闭,当服务端检测到会话已经超时失效时,会将该会话的 isClosing 标记为”已关闭”,这样就能确保不再处理来自该会话的新请求了。
Zookeeper 的会话管理主要是通过 SessionTracker 来负责,其采用了分桶策略(将类似的会话放在同一区块中进行管理)进行管理,以便 Zookeeper 对会话进行不同区块的隔离处理以及同一区块的统一处理。
四、ZAB 协议
ZooKeeper 并没有直接采用 Paxos 算法,而是采用了名为 ZAB 的一致性协议。ZAB 协议不是 Paxos 算法,只是比较类似,二者在操作上并不相同。
ZAB 协议是 Zookeeper 专门设计的一种支持崩溃恢复的原子广播协议。
ZAB 协议是 ZooKeeper 的数据一致性和高可用解决方案。
ZAB 协议定义了两个可以无限循环的流程:
- **选举 Leader:**用于故障恢复,从而保证高可用。
- **原子广播:**用于主从同步,从而保证数据一致性。
4.1 选举 Leader
ZooKeeper 的故障恢复
ZooKeeper 集群采用一主(称为 Leader)多从(称为 Follower)模式,主从节点通过副本机制保证数据一致。
-
如果 Follower 节点挂了 - ZooKeeper 集群中的每个节点都会单独在内存中维护自身的状态,并且各节点之间都保持着通讯,只要集群中有半数机器能够正常工作,那么整个集群就可以正常提供服务。
-
如果 Leader 节点挂了 - 如果 Leader 节点挂了,系统就不能正常工作了。此时,需要通过 ZAB 协议的选举 Leader 机制来进行故障恢复。
ZAB 协议的选举 Leader 机制简单来说,就是:基于过半选举机制产生新的 Leader,之后其他机器将从新的 Leader 上同步状态,当有过半机器完成状态同步后,就退出选举 Leader 模式,进入原子广播模式。
4.1.1 术语
**myid:**每个 Zookeeper 服务器,都需要在数据文件夹下创建一个名为 myid 的文件,该文件包含整个 Zookeeper 集群唯一的 ID(整数)。
**zxid:**类似于 RDBMS 中的事务 ID,用于标识一次更新操作的 Proposal ID。为了保证顺序性,该 zkid 必须单调递增。因此 Zookeeper 使用一个 64 位的数来表示,高 32 位是 Leader 的 epoch,从 1 开始,每次选出新的 Leader,epoch 加一。低 32 位为该 epoch 内的序号,每次 epoch 变化,都将低 32 位的序号重置。这样保证了 zkid 的全局递增性。
4.1.2 服务器状态
- **LOOKING:**不确定 Leader 状态。该状态下的服务器认为当前集群中没有 Leader,会发起 Leader 选举。
- **FOLLOWING:**跟随者状态。表明当前服务器角色是 Follower,并且它知道 Leader 是谁。
- **LEADING:**领导者状态。表明当前服务器角色是 Leader,它会维护与 Follower 间的心跳。
- **OBSERVING:**观察者状态。表明当前服务器角色是 Observer,与 Folower 唯一的不同在于不参与选举,也不参与集群写操作时的投票。
4.1.3 选票数据结构
每个服务器在进行领导选举时,会发送如下关键信息:
- **logicClock:**每个服务器会维护一个自增的整数,名为 logicClock,它表示这是该服务器发起的第多少轮投票。
- **state:**当前服务器的状态。
- **self_id:**当前服务器的 myid。
- **self_zxid:**当前服务器上所保存的数据的最大 zxid。
- **vote_id:**被推举的服务器的 myid。
- **vote_zxid:**被推举的服务器上所保存的数据的最大 zxid。
4.1.4 投票流程
(1)自增选举轮次
Zookeeper 规定所有有效的投票都必须在同一轮次中。每个服务器在开始新一轮投票时,会先对自己维护的 logicClock 进行自增操作。
(2)初始化选票
每个服务器在广播自己的选票前,会将自己的投票箱清空。该投票箱记录了所收到的选票。例:服务器 2 投票给服务器 3,服务器 3 投票给服务器 1,则服务器 1 的投票箱为(2, 3), (3, 1), (1, 1)。票箱中只会记录每一投票者的最后一票,如投票者更新自己的选票,则其它服务器收到该新选票后会在自己票箱中更新该服务器的选票。
(3)发送初始化选票
每个服务器最开始都是通过广播把票投给自己。
(4)接收外部投票
服务器会尝试从其它服务器获取投票,并记入自己的投票箱内。如果无法获取任何外部投票,则会确认自己是否与集群中其它服务器保持着有效连接。如果是,则再次发送自己的投票;如果否,则马上与之建立连接。
(5)判断选举轮次
收到外部投票后,首先会根据投票信息中所包含的 logicClock 来进行不同处理:
- 外部投票的 logicClock 大于自己的 logicClock。说明该服务器的选举轮次落后于其它服务器的选举轮次,立即清空自己的投票箱并将自己的 logicClock 更新为收到的 logicClock,然后再对比自己之前的投票与收到的投票以确定是否需要变更自己的投票,最终再次将自己的投票广播出去。
- 外部投票的 logicClock 小于自己的 logicClock。当前服务器直接忽略该投票,继续处理下一个投票。
- 外部投票的 logickClock 与自己的相等。当时进行选票 PK。
(6)选票 PK
选票 PK 是基于(self_id, self_zxid)与(vote_id, vote_zxid)的对比:
- 外部投票的 logicClock 大于自己的 logicClock,则将自己的 logicClock 及自己的选票的 logicClock 变更为收到的 logicClock。
- 若 logicClock 一致,则对比二者的 vote_zxid,若外部投票的 vote_zxid 比较大,则将自己的票中的 vote_zxid 与 vote_myid 更新为收到的票中的 vote_zxid 与 vote_myid 并广播出去,另外将收到的票及自己更新后的票放入自己的票箱。如果票箱内已存在(self_myid, self_zxid)相同的选票,则直接覆盖。
- 若二者 vote_zxid 一致,则比较二者的 vote_myid,若外部投票的 vote_myid 比较大,则将自己的票中的 vote_myid 更新为收到的票中的 vote_myid 并广播出去,另外将收到的票及自己更新后的票放入自己的票箱。
(7)统计选票
如果已经确定有过半服务器认可了自己的投票(可能是更新后的投票),则终止投票。否则继续接收其它服务器的投票。
(8)更新服务器状态
投票终止后,服务器开始更新自身状态。若过半的票投给了自己,则将自己的服务器状态更新为 LEADING,否则将自己的状态更新为 FOLLOWING。
通过以上流程分析,我们不难看出:要使 Leader 获得多数 Server 的支持,则 ZooKeeper 集群节点数必须是奇数。且存活的节点数目不得少于 N + 1 。
每个 Server 启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的 server 还会从磁盘快照中恢复数据和会话信息,zk 会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。
4.2 原子广播(Atomic Broadcast)
ZooKeeper 通过副本机制来实现高可用。
那么,ZooKeeper 是如何实现副本机制的呢?答案是:ZAB 协议的原子广播。
ZAB 协议的原子广播要求:
**所有的写请求都会被转发给 Leader,Leader 会以原子广播的方式通知 Follow。当半数以上的 Follow 已经更新状态持久化后,Leader 才会提交这个更新,然后客户端才会收到一个更新成功的响应。**这有些类似数据库中的两阶段提交协议。
在整个消息的广播过程中,Leader 服务器会每个事物请求生成对应的 Proposal,并为其分配一个全局唯一的递增的事务 ID(ZXID),之后再对其进行广播。
五、ZooKeeper 应用
ZooKeeper 可以用于发布/订阅、负载均衡、命令服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能 。
5.1 命名服务
在分布式系统中,通常需要一个全局唯一的名字,如生成全局唯一的订单号等,ZooKeeper 可以通过顺序节点的特性来生成全局唯一 ID,从而可以对分布式系统提供命名服务。
5.2 配置管理
利用 ZooKeeper 的观察机制,可以将其作为一个高可用的配置存储器,允许分布式应用的参与者检索和更新配置文件。
5.3 分布式锁
可以通过 ZooKeeper 的临时节点和 Watcher 机制来实现分布式锁。
举例来说,有一个分布式系统,有三个节点 A、B、C,试图通过 ZooKeeper 获取分布式锁。
(1)访问 /lock (这个目录路径由程序自己决定),创建 带序列号的临时节点(EPHEMERAL) 。
(2)每个节点尝试获取锁时,拿到 /locks节点下的所有子节点(id_0000,id_0001,id_0002),判断自己创建的节点是不是最小的。
-
如果是,则拿到锁。
释放锁:执行完操作后,把创建的节点给删掉。
-
如果不是,则监听比自己要小 1 的节点变化。
(3)释放锁,即删除自己创建的节点。
NodeA 删除自己创建的节点 id_0000,NodeB 监听到变化,发现自己的节点已经是最小节点,即可获取到锁。
5.4 集群管理
ZooKeeper 还能解决大多数分布式系统中的问题:
-
如可以通过创建临时节点来建立心跳检测机制。如果分布式系统的某个服务节点宕机了,则其持有的会话会超时,此时该临时节点会被删除,相应的监听事件就会被触发。
-
分布式系统的每个服务节点还可以将自己的节点状态写入临时节点,从而完成状态报告或节点工作进度汇报。
-
通过数据的订阅和发布功能,ZooKeeper 还能对分布式系统进行模块的解耦和任务的调度。
-
通过监听机制,还能对分布式系统的服务节点进行动态上下线,从而实现服务的动态扩容。
5.5 选举 Leader 节点
分布式系统一个重要的模式就是主从模式 (Master/Salves),ZooKeeper 可以用于该模式下的 Matser 选举。可以让所有服务节点去竞争性地创建同一个 ZNode,由于 ZooKeeper 不能有路径相同的 ZNode,必然只有一个服务节点能够创建成功,这样该服务节点就可以成为 Master 节点。
5.6 队列管理
ZooKeeper 可以处理两种类型的队列:
- 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
- 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
同步队列用 ZooKeeper 实现的实现思路如下:
线,从而实现服务的动态扩容。
5.5 选举 Leader 节点
分布式系统一个重要的模式就是主从模式 (Master/Salves),ZooKeeper 可以用于该模式下的 Matser 选举。可以让所有服务节点去竞争性地创建同一个 ZNode,由于 ZooKeeper 不能有路径相同的 ZNode,必然只有一个服务节点能够创建成功,这样该服务节点就可以成为 Master 节点。
5.6 队列管理
ZooKeeper 可以处理两种类型的队列:
- 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
- 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
同步队列用 ZooKeeper 实现的实现思路如下:
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!