程序媛的mac修炼手册-- Python微信公众号爬虫脚本
大伙儿新年好呀!最近因为写论文,需要采集某微信公众号发布的历史文章数据,研究了三天,今天终于搞定了。现在把详细操作分享给大家~
注:本文仅供学习交流,严禁用于商业用途。
当然,本文所涉项目需要读文档+源码+动手实践,参考示例代码进行改写,无法实现开箱即用。
目录
一、项目需求
某某微信公众号发布的全部历史文章
二、需求分析
已有的类似项目,主要有两种方法实现需求,一是使用微信公众号后台进行爬取,二是在电脑上使用Fiddler进行抓包分析。然而,现在是2024年了,由于微信反爬机制升级,上述两种方法仅用一种,根本无法实现需求。因此本文方法是:通过微信公众号后台获取Fiddler抓包分析的目标链接。
三、前期准备
1、微信公众号(抓包获取指定公众号所有文章、标题、链接数据)
个人注册微信公众号平台教程 :(个人)注册公众平台步骤
2、安装抓包工具Fiddler Everywhere
详细教程可参考:【Fiddler】mac m1 机器上使用 fiddler 抓取接口_fiddler mac-CSDN博客
3、Chrome浏览器安装插件SwitchyOmega
详细教程可参考,注意整个操作过程中最好把VPN关闭,使用本地网络即可。谷歌浏览器代理扩展程序插件SwitchyOmega安装使用教程_谷歌扩展程序 代理上网-CSDN博客
4、Python 3.11 和 PyCharm CE
四、详细步骤
(一)打开 Fiddler记录Chrome浏览器的通信
1、首先将Chrome浏览器设为Mac的系统默认浏览器
2、打开Chrome浏览器,点击浏览器地址栏后的“扩展程序”图标,在弹出的下拉框中单击“Proxy SwitchyOmega“,然后点击配置好的fiddler代理,如下图所示: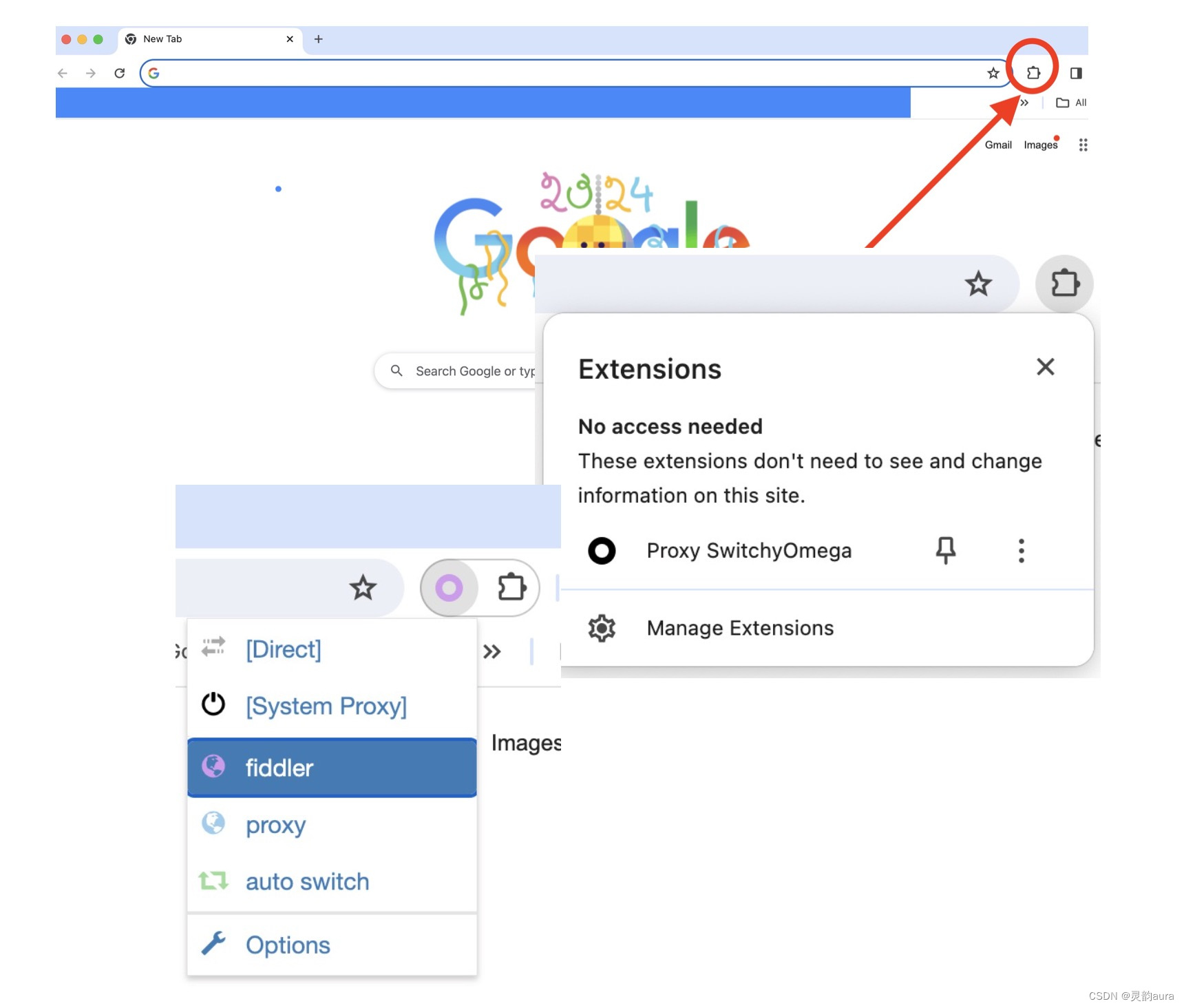
3、在Mac的启动台双击打开Fiddler Everywhere,打开后的页面如下图所示,之后在Chrome浏览器浏览的任何网页,都会被记录在图示红框处的URL栏:

(二)在Chrome浏览器登录微信公众号后台获取目标链接
详细操作如下图所示

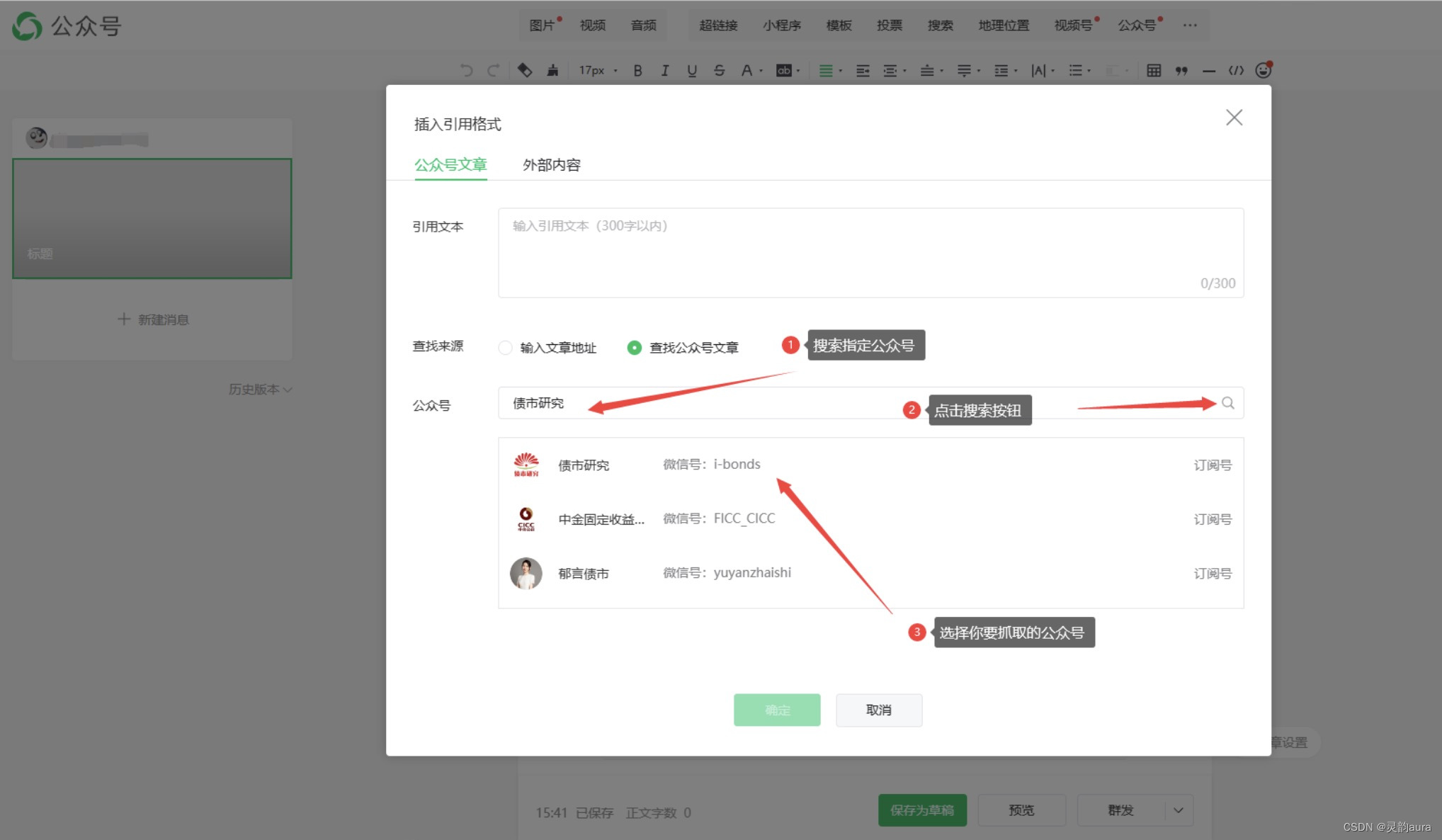

此时,登录微信公众号后台的一系列操作都被记录在Fiddler中,点开Fiddler窗口如下图所示:
(蓝条框用于遮挡打码,请自动忽略)

1、在Fiddler记录的URL栏中找到前缀如下的URL,正如上图红框标出的那样
https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&fakeid
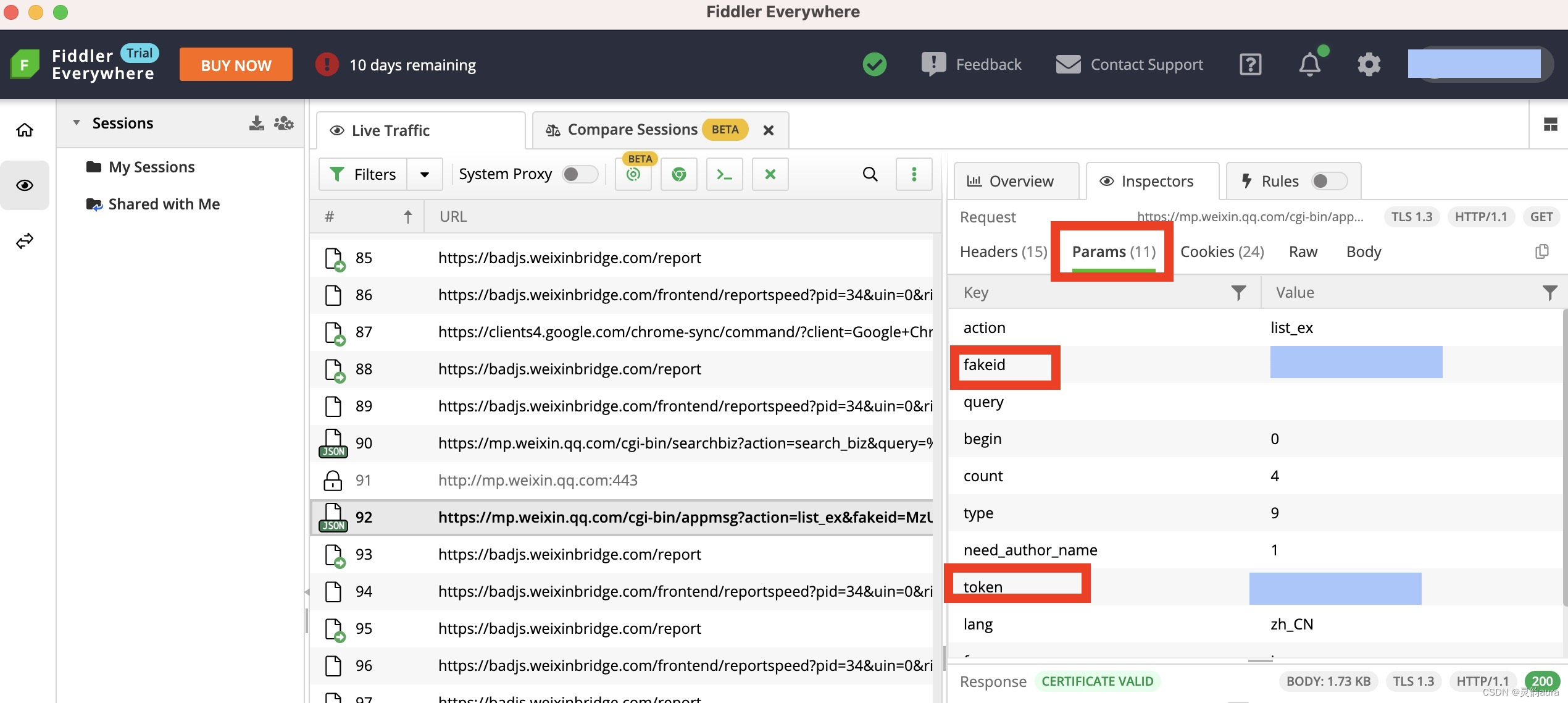
2、单击目标网址,Fiddler页面的右上的边栏会显示该网址的参数,找到该网址的fakeid、token、cookie 。如下图红框所示:
Params选项获取fakeid、token
Raw选项获取cookie

可以将fakeid、token、cookie的值直接复制粘贴到文本文件中备用,也可以待会需要的时候直接来Fiddler页面复制。
(三)PyCharm创建项目运行爬虫脚本
1、创建Python微信公众号爬虫脚本
在PyCharm中创建一个新项目名为”训练项目“,在该项目目录下新建python文件”weixin.py",
然后把以下完整代码复制粘贴到”weixin.py"中。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@file:GzhSpider.py
@time:2022/12/28
"""
import time
from time import sleep
import requests
import pandas as pd
import json
class GzhSpider(object):
def __init__(self):
self.token = "25351****"
self.fakeid = "MzA4MzYwNTA0Mg=="
self.cookie = ""
def get_html(self, page):
"""
通过微信公众号后台获取数据
:param page: 页码
:return:
"""
params = {
"action": "list_ex",
"fakeid": self.fakeid,
"query": "",
"begin": str(page * 4),
"count": "4",
"type": "9",
"need_author_name": "1",
"token": self.token,
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54',
"cookie": self.cookie
}
response = requests.get(url, headers=headers, params=params)
return response.text
def parse_data(self, items):
results = []
items = json.loads(items)
if "app_msg_list" not in items:
return None
for item in items["app_msg_list"]:
create_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(item["create_time"]))
readNum, likeNum, old_like_num = (0, 0, 0)
results.append({
"title": item['title'],
"url": item['link'],
"create_time": create_time,
"author_name": item["author_name"],
"readNum": readNum,
"likeNum": likeNum,
"old_like_num": old_like_num
})
print(json.dumps(results, indent=4))
return results
def save(self, results):
data = pd.DataFrame(results)
data.to_csv("data.csv")
def run(self):
results = []
for i in range(25): # 采集25页
html = self.get_html(i)
result = self.parse_data(html)
results.extend(result)
sleep(5)
self.save(results)
if __name__ == '__main__':
GzhSpider().run()脚本参考文章:https://www.cnblogs.com/hlikex/p/17026496.html
?2、更改脚本中的配置。
将上述脚本代码中的fakeid、token、cookie更换成自己刚刚获取的目标对象值。
3、运行脚本。
点击PyCharm中的Run按钮就可以运行脚本了,平均2~3秒爬取一篇微信公号文章,有些慢,耐心等一等。程序运行结束后,会在PyCharm”训练项目“文件夹下,自动生成一个记录爬取数据结果的“data.csv"文件。采集数据详情如下图所示: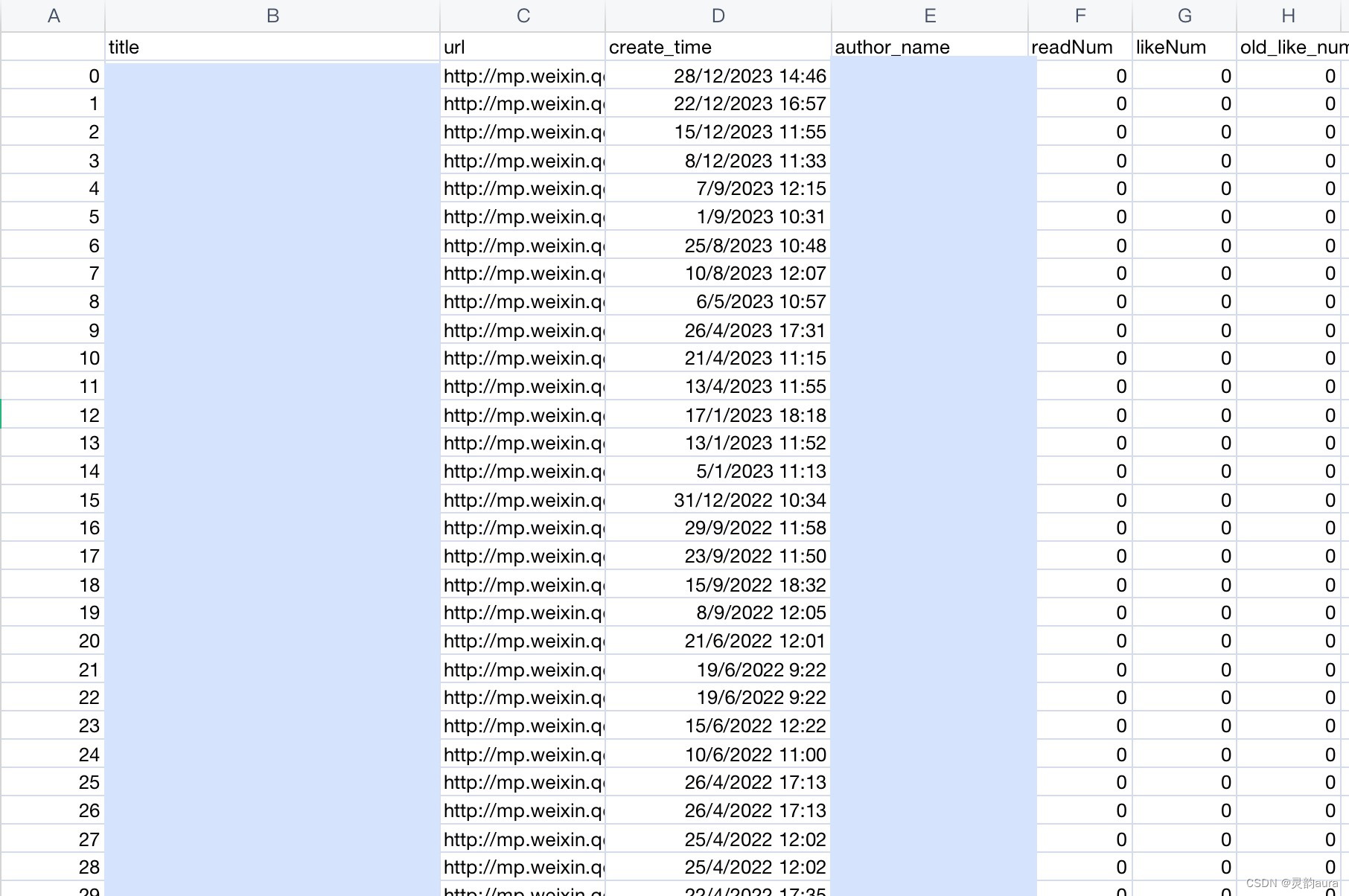
?
4、如果运行脚本一次,没能将目标公众号的全部历史文章爬下来,可以更改上述python脚本中的begin": str(page * 4)的设置,这是开始爬取的网页位置,如下图红框所示。如果一次没能爬完,可以将4改成17、20·····等任意比4大的数字。

5、避免封号
每次运行完上述脚本程序后,最好等一会儿再次运行,过快会导致爬取失败,甚至触动反爬机制被封号,要谨慎!
五、关于微信公众号文章的阅读量和点赞数的爬取
?Github上有个大神一直在更新微信公众号爬虫项目,获得2.4k点亮,项目地址如下:
GitHub - wnma3mz/wechat_articles_spider: 微信公众号文章的爬虫
我尝试过他介绍的“通过Fiddler进行抓包分析阅读点赞数”,但没能成功。不知道是不是因为微信公众号改版,导致微信公号文章的网页不再显示阅读量和点赞数了,抓包工具无从抓起,总之难搞😂😂
要是有小伙伴成功爬到微信公号历史文章的阅读量和点赞数了,记得戳我一下~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!