Linux之grep、sed、awk
目录
1.grep
grep 擅长过滤查找,按行进行过滤
例:
当有用户对我们的主机进行爆破攻击时,我们可以使用grep将 ip 查找出来,进行封锁等处理
在 /var/log?目录下的 secure 文件中存放在用户登录连接信息,我们可以从当中获取 ip
查看失败的登录
cat secure |grep 'Failed password'?或
grep 'Failed password' secure?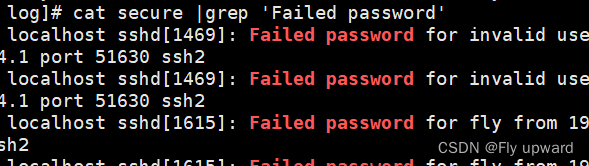
?可以配合正则表达式将 IP 过滤出来
grep 'Failed password' secure |grep -Po (25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)?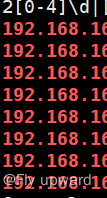
?如果要查看登录了几次,可以现将 IP 地址进行排序,再去重
grep 'Failed password' secure |grep -Po (25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d) |sort -n |uniq -c?-n 显示行号
grep -n 'tcp' a.txt
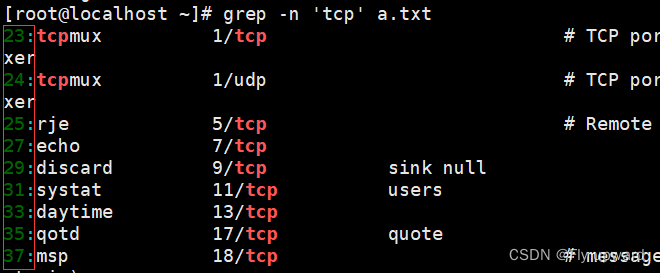
?-c 对结果行计数
grep -c 'tcp' a.txt
?
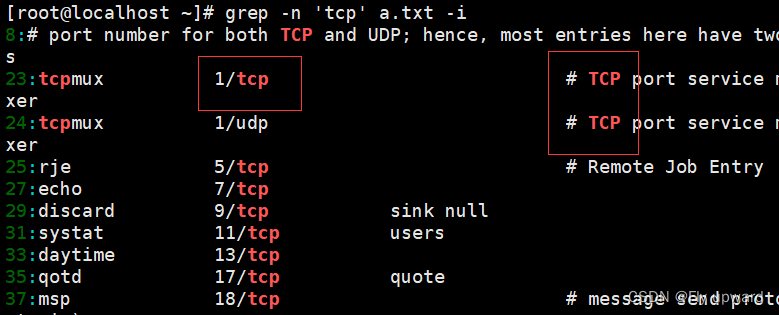
? -i 不区分大小写
grep -n 'tcp' a.txt -i
?
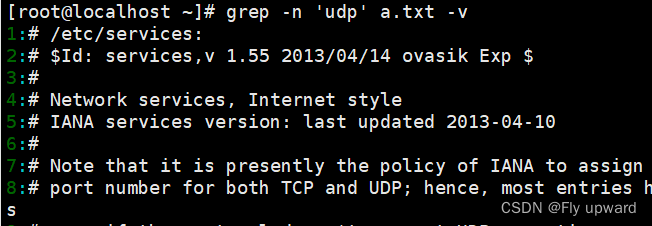
?-v 反向搜索,取反
grep -n 'udp' a.txt -v #将不含有 udp 的行过滤出来
?
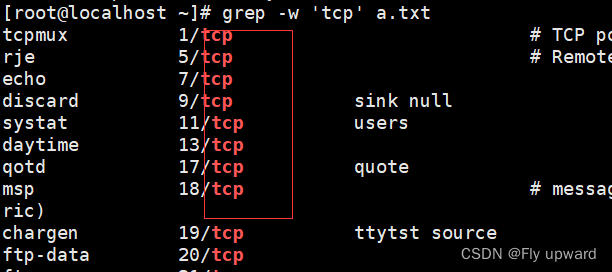
?-w 精准匹配
grep -w 'tcp' a.txt
?
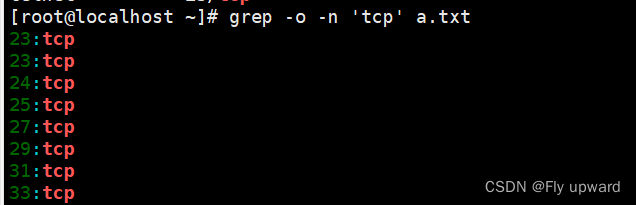
?-o 只显示匹配的结果
grep -o -n 'tcp' a.txt
?
-A2 同时打印搜索结果行的 后两行 ,A是after 的缩写
grep -A2 'ftp' a.txt
?
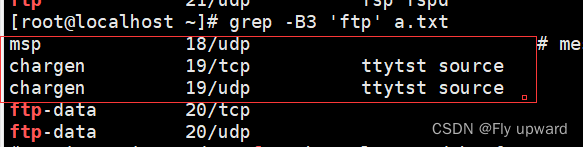
?-B3 同时打印搜索结果的前三行,B是before 的缩写
grep -B3 'ftp' a.txt
?
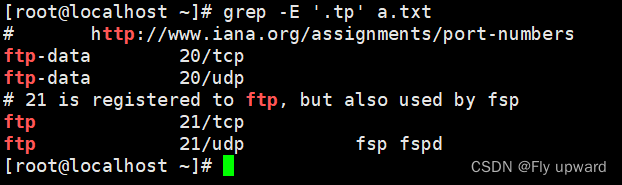
?-E 扩展正则表达式
grep -E '.tp' a.txt # .表示任一字符grep -E 'ftp|ssh' a.txt #查找ftp 或者ssh , | 是或者的意思,可以写多个或者进行查找
?
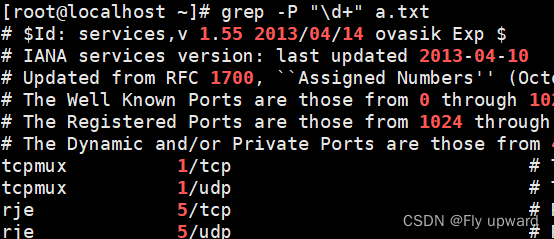
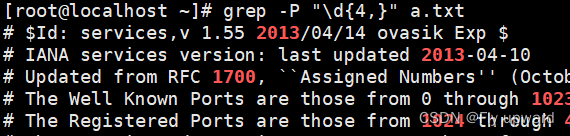
-P 使用 perl 正则
grep -P "\d+" a.txt #匹配所有的数字grep -P "\d{4,}" a.txt #匹配四位数的数字
?
?
2.sed
sed 主要用于取行或者修改替换
用法:sed [-nri] [动作] 目标文件
选项与参数:
-n :使用安静(silent)模式
-r :sed 的动作支持的是延伸正则表示法的语法
-i :直接修改读取的文件内容,而不是输出到终端
动作说明:[n1][,n2]function
n1, n2 一般表示为行号,[,n2] 表示这个参数可选,可有可无
function:
a:指定行后面插入一行
d:删除
i:指定行前面插入一行
p:打印,? #一般和前面的 -n 参数以前用
s:替换 需要忽略大小写,全局替换需要g
例 :p 打印
含有 a 的行
sed '/a/p' b.txt #默认打印所有行,并且匹配到的a所在行重新打印一遍??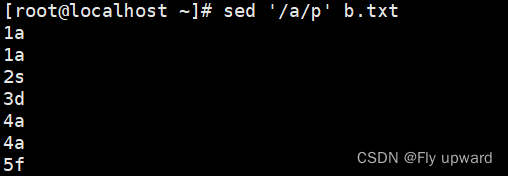
sed -n '/a/p' b.txt # 加上 -n 进入安静(silent)模式,就只打印含有 a 的行
?打印含有 ‘tcp’ 的行
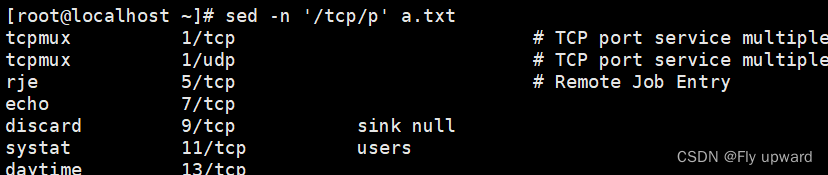
sed -n '3p' b.txt #打印第三行
sed -n '1,3p' b.txt #打印1-3行
?例: d 删除
删除含有 a 的行(并不是删除源文件的a,只是将结果删除显示在终端)

?例:使用 -i 删除文件内容
删除原文件中含有 a 的行

?例:指定行号进行删除
sed '1,3d' b.txt # 显示在终端的删除前三行
sed -i '1,3d' b.txt #删除原文件前三行
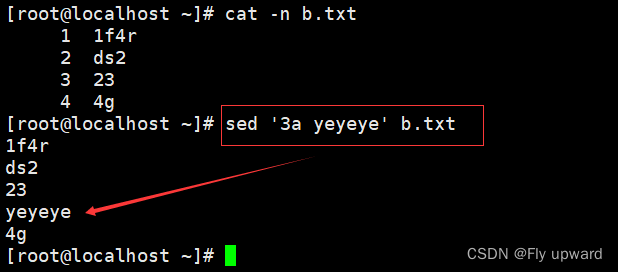
?例:-a? 插入数据
在第三行后面插入数据
sed '3a yeyeye' b.txt
?在第二行前面插入一行数据
sed '2i nonono' b.xtx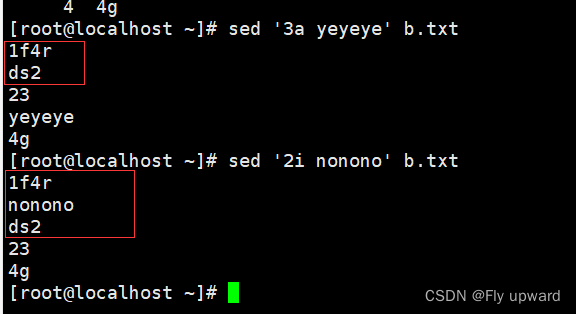
?加上 -i 就可以直接修改原文件
sed -i '2i nonono' b.xtx?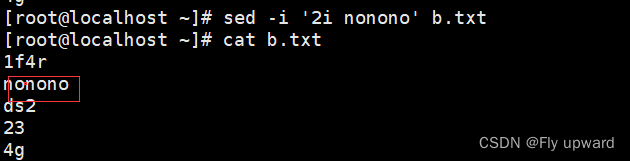
?例: s 替换数据
将23替换成123
sed 's#23#123# b.txt?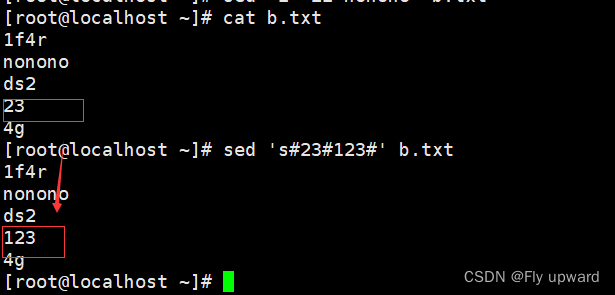
同一行的第一个替换,后面的不替换
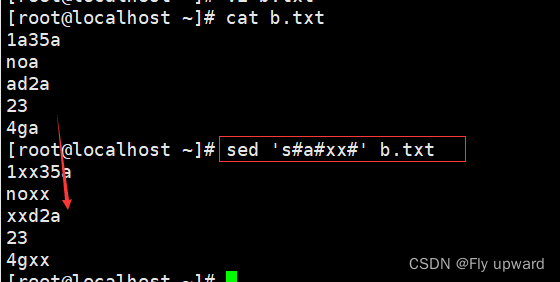
?加上 g 可以进行全部替换
sed 's#a#xx#g' b.txt?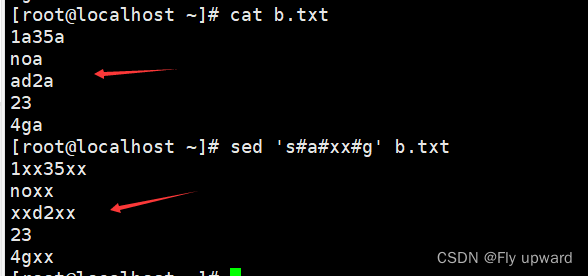
忽略大小写进行替换 可以加gI?
sed 's#a#xx#gI' b.txt3.awk
awk 用于取列
例:默认以空格进行分割列
取列
wak '{print $1}' b.txt #取第一列
wak '{print $2}' b.txt #取第二列
wak '{print $3}' b.txt #取第三列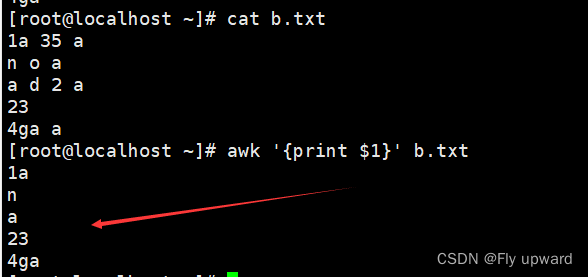
?每一行的最后一列 NF
awk '{print $NF}' b.txt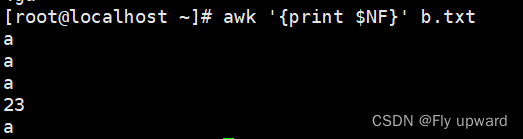
?取第一列和最后一列
awk '{print $1,$NF}' b.txt
例:计算
第二列 乘以 第三列
awk '{print $1,$2*$3}' b.txt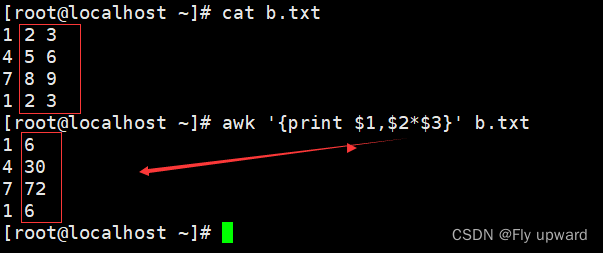
?例:根据行号筛选内容
awk 'NR==1' b.txt #取第一行
awk 'NR>1' b.txt #取行号大于2的内容
awk 'NR<=3' b.txt #取行号小于等于3的内容
?取行的同时取列
awk 'NR>1{print $1,$2*$3}' b.txt取出含有 a 的行数
awk '/a/' b.txt指定分隔符
awk -F ":" '{print $1}' /etc/passwd # 指定以 :进行分割awk -F ':' 'NR==2 || NR==6 {print $1}' etc/passwd # 取出第二
行或第六行的第一列数据,分隔符为:本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!