『PyTorch学习笔记』分布式深度学习训练中的数据并行(DP/DDP) VS 模型并行
2023-12-13 07:13:42
| 分布式深度学习训练中的数据并行(DP/DDP) VS 模型并行 |
一. 介绍
- 现代深度学习模型中的参数数量越来越大,数据集的规模也急剧增加。要在大型数据集上训练复杂的现代深度学习模型,必须使用多节点训练,否则会花费很长时间。在分布式深度学习训练中,人们可能总会看到数据并行和模型并行。在这篇博文中,将讨论这两种深度学习并行方法的理论、逻辑和一些误导点。
二. 并行数据加载
2.1. 加载数据步骤
- 流行的深度学习框架(例如Pytorch和Tensorflow)为分布式培训提供内置支持。从广义上讲,从磁盘读取输入数据开始,加载数据涉及四个步骤:
- 将数据从磁盘加载到主机:在这个阶段,数据从磁盘(可能是HDD或SSD)读取到主机的内存中。这个过程涉及文件系统的I/O操作,通常使用高级API,如Python的open函数,或者在深度学习框架中,可以使用数据加载器(如PyTorch的DataLoader或TensorFlow的tf.data API)来实现。这些数据加载器通常具有多线程或多进程功能,可以异步读取数据,并将其加载到CPU的内存中。
- 将数据从可分页内存传输到主机上的固定内存。请参阅此有关分页和固定的内存更多信息:可分页(pageable)内存和固定(pinned)内存都是主机内存的类型。可分页内存是普通的系统内存,操作系统可以将其页(一个内存管理单位)移动到磁盘上(即分页)。固定内存,又称为非分页内存,是指操作系统不能移动到磁盘的内存区域。固定内存的数据传输到GPU通常比从可分页内存传输更快,因为它避免了额外的复制步骤,并且可以直接通过DMA(直接内存访问)进行。在深度学习训练中,经常将数据从可分页内存复制到固定内存以准备传输到GPU。
- 将数据从固定内存传输到GPU:一旦数据位于固定内存中,它就可以通过高带宽的 PCIe总线(Peripheral Component Interface Express,总线和接口标准) 高效地传输到GPU内存中。深度学习框架通常提供了简化这个过程的工具。例如,在PyTorch中,你可以使用.to(device)或.cuda()方法将张量移动到GPU。此过程是由DMA引擎管理的,可以在不占用CPU资源的情况下进行。
- 在GPU上向前和向后传递:当数据位于GPU内存中时,可以开始训练过程,即进行模型的前向和反向传播。在前向传播中,模型的参数(也必须在GPU内存中)用于计算输出和损失函数。然后,通过反向传播,根据损失函数相对于模型参数的梯度,更新模型参数。这些计算完全在GPU上进行,利用其并行计算能力来加速训练过程。
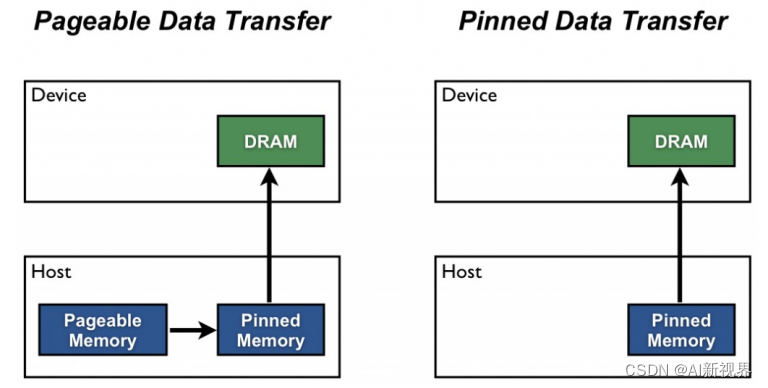
- 补充2:谈到主机内存,有两个主要类别——可分页(或“非固定”)[pageable (or “un-pinned”)]内存和页面锁定(或“固定”)内存[page-locked (or “pinned”)]。当您在 C 程序中使用 malloc 分配内存时,分配是在可分页内存中完成的。 GPU 无法直接从可分页主机内存访问数据,因此当调用从可分页主机内存到设备内存的数据传输时,CUDA 驱动程序首先分配一个临时固定主机数组,将主机数据复制到固定数组,然后传输数据从固定数组传输到设备内存,如下图所示(有关更多信息,请参阅本页)
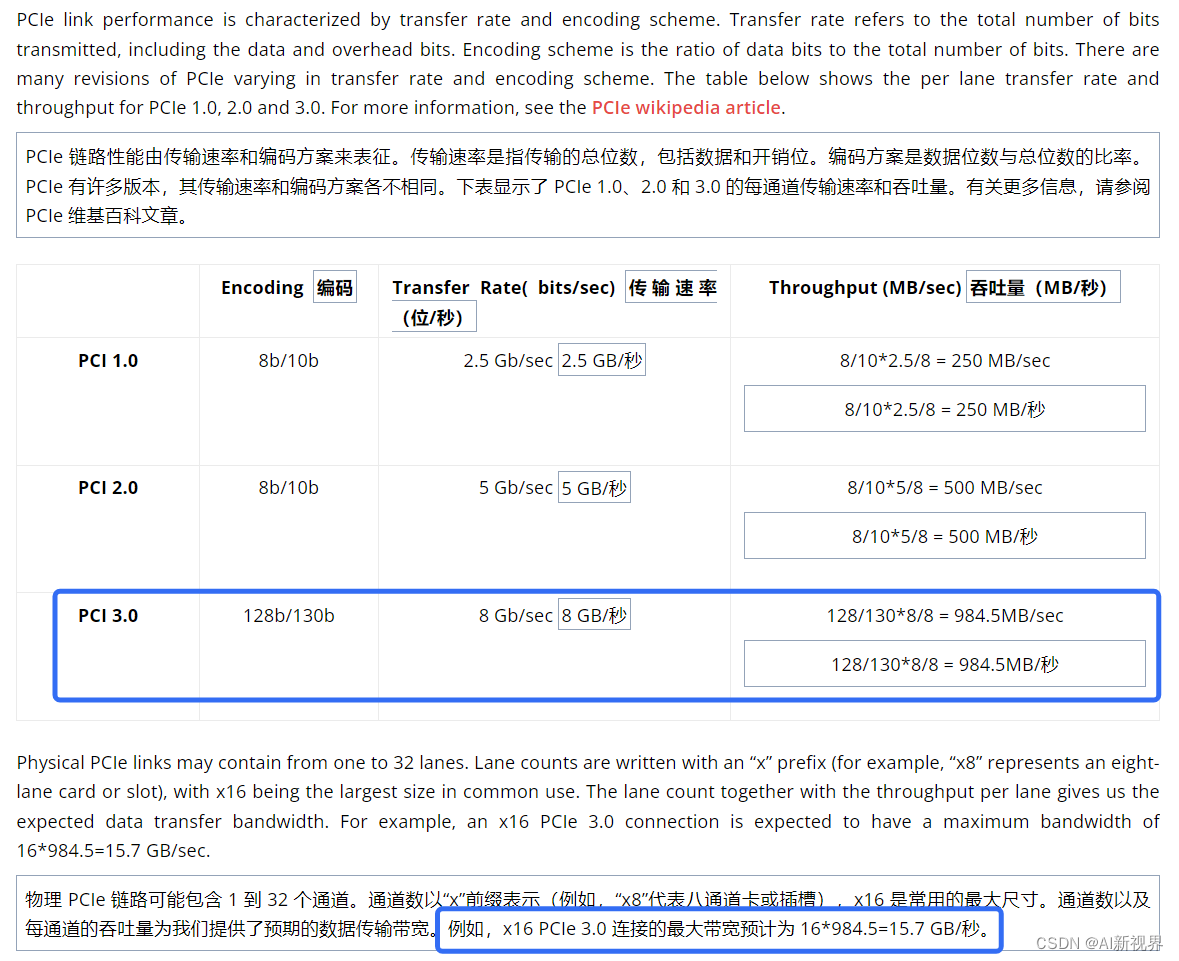
- 补充3:GPU 通常通过 PCIe 连接连接到主板,来自主(主机)内存的数据必须通过此 PCIe 链路传输到 GPU 内存。该链路的预期带宽是多少?为了回答这个问题,让我们看一下有关 PCIe 链路的一些基本信息。
2.2. PyTorch 1.0 中的数据加载器(Dataloader)
- PyTorch中的Dataloader提供使用多个进程(通过将
num_workers>0设置)从磁盘加载数据以及将多页数据从可分页内存到固定内存(pinned memory) 的能力(通过设置)pin_memory = True)。- 一般的,对于大批量的数据,若仅有一个线程用于加载数据,则数据加载时间占主导地位,这意味着无论我们如何加快数据处理速度,性能都会受到数据加载时间的限制。现在,设置
num_workers = 3以及pin_memory = True。这样,可以使用多个进程从磁盘读取不重叠的数据,并启动生产者-消费者线程以将这些进程读取的数据从可分页的内存转移到固定的内存。

- 多个进程能够更快地加载数据,并且当数据处理时间足够长时,流水线数据加载几乎可以完全隐藏数据加载延迟。这是因为在处理当前批次的同时,将从磁盘读取下一个批次的数据,并将其传输到固定内存。如果处理当前批次的时间足够长,则下一个批次的数据将立即可用。这个想法还建议如何为num_workers参数设置适当的值。应该设置此参数,以使从磁盘读取批处理数据的速度比GPU处理当前批处理的速度更快(但不能更高,因为这只会浪费多个进程使用的系统资源)。
三. 数据并行
- 当一张 GPU 可以存储一个模型时,可以采用数据并行得到更准确的梯度或者加速训练,即每个 GPU 复制一份模型,将一批样本分为多份输入各个模型并行计算。因为求导以及加和都是线性的,数据并行在数学上也有效。
- 假设我们一个 batch 有 n n n 个样本,一共有 k k k 个 GPU 每个 GPU 分到 m j m_j mj? 个样本。假设样本刚好等分,则有 m j = n k m_{j}=\frac nk mj?=kn? 。我们考虑总的损失函数 l l l 对参数 w w w 的导数:
? L o s s ? w = ? ? 1 n ∑ i = 1 n l ( x i , y i ) ? ? w = 1 n ∑ i = 1 n ? l ( x i , y i ) ? w = m 1 n ? [ 1 m 1 ∑ i = 1 m 1 l ( x i , y i ) ] ? w + m 2 n ? [ 1 m 2 ∑ i = m 1 + 1 m 1 + m 2 l ( x i , y i ) ] ? w + ? + m k n ? [ 1 m k ∑ i = m k ? 1 + 1 m k ? 1 + m k l ( x i , y i ) ] ? w = ∑ j = 1 k m j n ? [ 1 m j ∑ i = m j ? 1 + 1 m j ? 1 + m j l ( x i , y i ) ] ? w = ∑ j = 1 k m j n ? l o s s j ? w \begin{aligned} \begin{aligned}\frac{\partial Loss}{\partial w}\end{aligned}& =\frac{\partial\left\lfloor\frac1n\sum_{i=1}^nl(x_i,y_i)\right\rfloor}{\partial w} \\ &=\frac1n\sum_{i=1}^n\frac{\partial l(x_i,y_i)}{\partial w} \\ &=\frac{m_1}n\frac{\partial\left[\frac1{m_1}\sum_{i=1}^{m_1}l(x_i,y_i)\right]}{\partial w}+\frac{m_2}n\frac{\partial\left[\frac1{m_2}\sum_{i=m_1+1}^{m_1+m_2}l(x_i,y_i)\right]}{\partial w}+\cdots+\frac{m_k}n\frac{\partial\left[\frac1{m_k}\sum_{i=m_{k-1}+1}^{m_{k-1}+m_k}l(x_i,y_i)\right]}{\partial w} \\ &=\sum_{j=1}^k\frac{m_j}n\frac{\partial\left[\frac1{m_j}\sum_{i=m_{j-1}+1}^{m_{j-1}+m_j}l(x_i,y_i)\right]}{\partial w} \\ &=\sum_{j=1}^k\frac{m_j}n\frac{\partial loss_j}{\partial w} \end{aligned} ?w?Loss???=?w??n1?∑i=1n?l(xi?,yi?)??=n1?i=1∑n??w?l(xi?,yi?)?=nm1???w?[m1?1?∑i=1m1??l(xi?,yi?)]?+nm2???w?[m2?1?∑i=m1?+1m1?+m2??l(xi?,yi?)]?+?+nmk???w?[mk?1?∑i=mk?1?+1mk?1?+mk??l(xi?,yi?)]?=j=1∑k?nmj???w?[mj?1?∑i=mj?1?+1mj?1?+mj??l(xi?,yi?)]?=j=1∑k?nmj???w?lossj???- 其中: w w w 是模型参数, ? L o s s ? w \frac{\partial Loss}{\partial w} ?w?Loss? 是大小为 n n n 的big batch的真实梯度, ? l o s s j ? w \frac{\partial loss_j}{\partial w} ?w?lossj?? 是 GPU/node k k k 的小批量梯度, x i x_i xi? 和 y i y_i yi? 是数据点 i i i, l ( x i , y i ) l(x_i,y_i) l(xi?,yi?) 是根据前向传播计算出的数据点 i i i 的损失, n n n 是数据集中数据点的总数, k k k 是 GPU/Node的总数, m k m_k mk? 是分配给 GPU/节点的样本数量, m 1 + m 2 + ? + m k = n m_1+m_2+\cdots+m_k=n m1?+m2?+?+mk?=n。当 m 1 = m 2 = ? = m k = n k m_1=m_2=\cdots=m_k=\frac nk m1?=m2?=?=mk?=kn?时,我们可以进一步有:
? L o s s ? w = 1 k [ ? l o s s 1 ? w + ? l o s s 2 ? w + ? + ? l o s s k ? w ] \frac{\partial{Loss}}{ \partial w }=\frac{1}{k}\big[\frac{\partial loss_1}{\partial w}+\frac{\partial loss_2}{\partial w}+\cdots+\frac{\partial loss_k}{\partial w}\big] ?w?Loss?=k1?[?w?loss1??+?w?loss2??+?+?w?lossk??]- 这里对于每个GPU/Node,我们使用相同的模型/参数进行前向传播,我们向每个节点发送一小批不同的数据,正常计算梯度,并将梯度发送回主节点。此步骤是异步的,因为每个 GPU/节点的速度略有不同。一旦我们获得了所有梯度(我们在这里进行同步),我们就计算梯度的(加权)平均值,并使用梯度的(加权)平均值来更新模型/参数。然后我们继续下一次迭代。
3.1. DP(DataParallel)的基本原理
- DP 的好处是,使用起来非常方便,只需要将原来单卡的 module 用 DP 改成多卡:
model = nn.DataParallel(model)
3.1.1. 从流程上理解
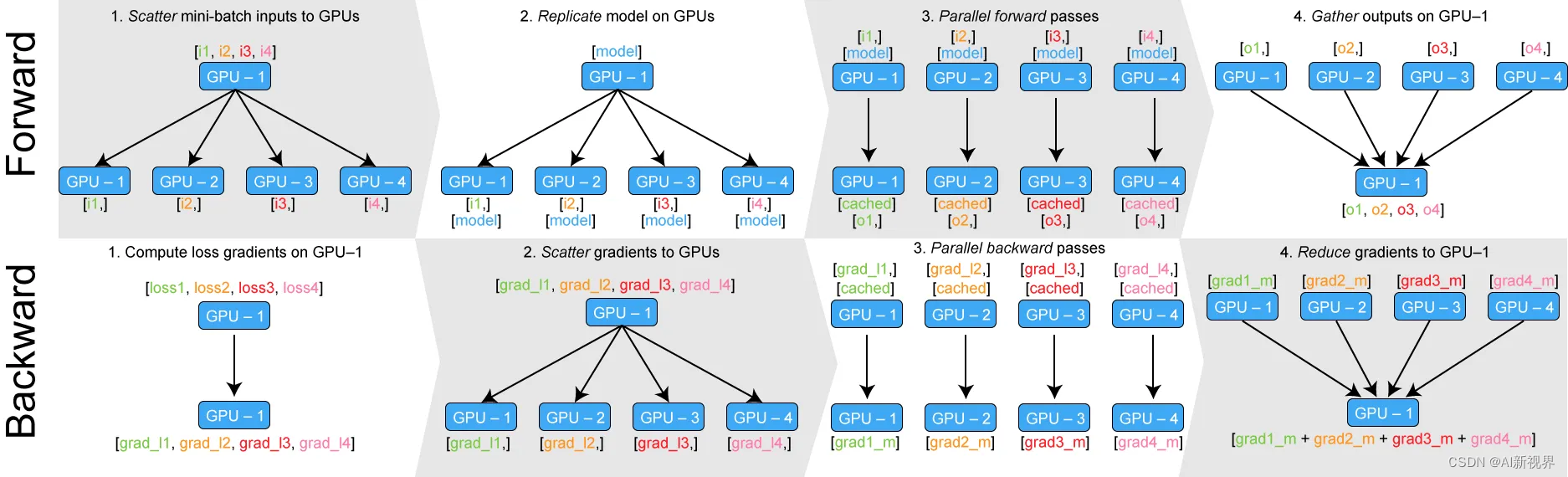
- DataParallel 从流程上来看,是通过将整个小批次(minibatch)数据加载到主线程上,然后将子小批次(sub-minibatches)数据分散到整个GPU网络中来工作。
- 把 minibatch 数据从page-locked memory 传输到 GPU 0(master),Master GPU 也持有模型,其他GPU拥有模型的 stale copy。
- 在 GPUs 之间 scatter minibatch 数据。具体是将输入一个 minibatch 的数据均分成多份,分别送到对应的 GPU 进行计算。
- 在 GPUs 之间复制模型。与 Module 相关的所有数据也都会复制多份。
- 在每个GPU之上运行前向传播,计算输出。PyTorch 使用多线程来并行前向传播,每个 GPU 在单独的线程上将针对各自的输入数据独立并行地进行 forward 计算。
- 在 master GPU 之上收集(gather)输出,计算损失。即通过将网络输出与批次中每个元素的真实数据标签进行比较来计算损失函数值。
- 把损失在 GPUs 之间 scatter,在各个GPU之上运行后向传播,计算参数梯度。
- 在 GPU 0 之上归并梯度。
- 更新梯度参数。①进行梯度下降,并更新主GPU上的模型参数;②由于模型参数仅在主GPU上更新,而其他从属GPU此时并不是同步更新的,所以需要将更新后的模型参数复制到剩余的从属 GPU 中,以此来实现并行。

3.1.2. 从模式角度理解
- 首先我们先给出一个技术上的概括,从模式角度看:
- DP 可以被认为是类似参数服务器的应用。
- DDP 可以被认为是集合通讯的应用。
- 参数服务器大致可以分为 master 和 worker,而DP 基于单机多卡,所以对应关系如下:
- worker :所有GPU(包括GPU 0)都是worker,都负责计算和训练网络。
- master :GPU 0(并非 GPU 真实标号,而是输入参数 device_ids 的首位)也负责整合梯度,更新参数。
- 所以我们重点看看 GPU 0。
- DataParallel会将网络模型默认放在GPU 0上,然后把模型从GPU 0 拷贝到其他的GPU,各个GPU开始并行训练,接着 GPU 0 作为master来进行梯度的汇总和模型的更新,最后将计算任务下发给其他GPU。这非常类似参数服务器的机制。
- 从官方图也可以看到同样的信息。
- DataParallel会开启 单进程多线程 进行数据并行化
- 前向传播:首先,模型和mini-batch的数据会被放到GPU:0上(master GPU),之后,GPU:0会把数据分割成sub-mini-batch并scatter(分发)到其他GPU上,第二步,GPU:0会把自己的模型参数复制到其他GPU上,每个GPU拥有相同的模型参数。第三步,每个GPU在单独的线程上对其sub-mini-batch的数据前向传播,得到模型的输出结结果。第四部,GPU:0会收集所有GPU的输出结果。
- 反向传播:GPU:0得到所有的结果之后会与真实的label计算loss并得到loss的梯度,GPU:0会把loss梯度 Scatter到所有GPU上,每个GPU会根据loss梯度反向传播计算所有参数的梯度,之后,所有GPU上计算得到的参数梯度会汇总到GPU:0上,GPU:0进而对参数进行更新。这就完成了一个batch的模型训练。
- 有人说GPU:0是个自私的家伙,它把其他GPU都当成工具人来用,核心机密不传授,我只给你们数据,不给你label,你们得到结果之后给我我给你们计算loss和loss的梯度,然后分发给你们去给我计算参数的梯度,之后我得到这些参数的梯度之后我去更新参数,之后等下回需要你们的时候再去给你们其他GPU去分发我更新好的参数。
- 这是一个悲伤的故事,首先 单进程多线程 就似乎已经注定的结局,python的全局解释锁给这些附属的GPU戴上了沉沉的牢拷,其他GPU想奋起反抗,但是DP里面只有一个优化器Optimizer,这个优化器Optimizer只在主GPU上进行参数更新,当环境不在改变的时候,其他GPU选择了躺平,当GPU:0忙前忙后去分发数据、汇总梯度,更新参数的时候,其他GPU就静静躺着。
3.1.3. 从操作系统角度看
- 从操作系统角度看,DP 和 DDP 有如下不同(我们属于提前剧透):
- DataParallel 是单进程,多线程的并行训练方式,并且只能在单台机器上运行。
- DistributedDataParallel 是多进程,并且适用于单机和多机训练。DistributedDataParallel 还预先复制模型,而不是在每次迭代时复制模型,并避免了全局解释器锁定。
3.1.4. 低效率

- 这种效率不高的数据并行方法,注定要被淘汰。是的,我们迎来了DDP(DistributedDataParallel)
3.2. DDP(DistributedDataParallel)的基本原理
3.2.1. 原理介绍
- DistributedDataParallel,支持
all-reduce,broadcast,send 和 receive等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。可以用于 单机多卡也可用于多机多卡, 官方也曾经提到用 DistributedDataParallel 解决 DataParallel 速度慢,GPU负载不均衡的问题。- 效果比DataParallel好太多!!!torch.distributed相对于torch.nn.DataParalle 是一个底层的API,所以我们要修改我们的代码,使其能够独立的在机器(节点)中运行。
- 与 DataParallel 的单进程控制多 GPU 不同,在 distributed 的帮助下,我们只需要编写一份代码,torch 就会自动将其分配给n个进程,分别在 n 个 GPU 上运行。不再有主GPU,每个GPU执行相同的任务。对每个GPU的训练都是在自己的过程中进行的。每个进程都从磁盘加载其自己的数据。分布式数据采样器可确保加载的数据在各个进程之间不重叠。损失函数的前向传播和计算在每个GPU上独立执行。因此,不需要收集网络输出。在反向传播期间,梯度下降在所有GPU上均被执行,从而确保每个GPU在反向传播结束时最终得到平均梯度的相同副本。
- 区别: DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而DataParallel()是通过单进程控制多线程来实现的。

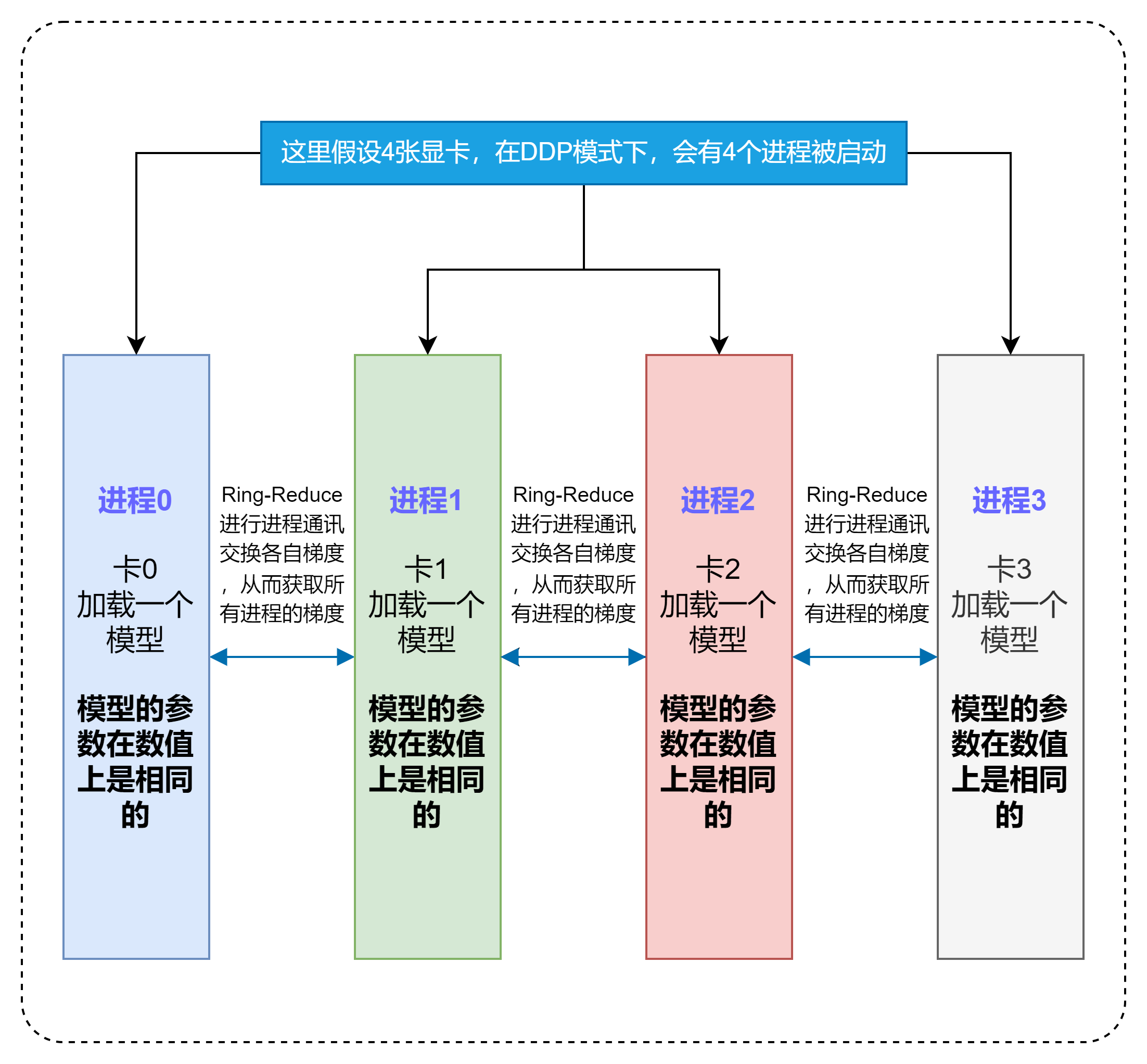
- 假如我们有N张显卡:
- (缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。
- (Ring-Reduce加速)在模型训练时,各个进程通过一种叫Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度;
- (实际上就是Data Parallelism)各个进程用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
3.2.2. Parameter Server vs Ring AllReduce通信机制对比
- 常用的两种参数同步的算法:PS 和 Ring AllReduce。假设有5张GPU:
- Parameter Server:GPU 0将数据分成五份分到各个卡上,每张卡负责自己的那一份mini-batch的训练,得到梯度grad后,返回给GPU 0上做累积,得到更新的权重参数后,再分发给各个卡。
- Ring AllReduce:5张以环形相连,每张卡都有左手卡和右手卡,一个负责接收,一个负责发送,循环4次完成梯度累积,再循环4次做参数同步。分为Scatter Reduce和All Gather两个环节。



- 所以我们亟需一种新的算法来提高深度学习模型训练的并行效率。2017 年 Facebook 发布了《Accurate, large minibatch SGD: Training ImageNet in 1 hour 》验证了大数据并行的高效性,同年百度发表了《Bringing HPC techniques to deep learning 》,验证了全新的梯度同步和权值更新算法的可行性,并提出了一种利用带宽优化环解决通信问题的方法——Ring AllReduce。Ring AllReduce链接
- Parameter Service最大的问题就是通信成本和GPU的数量线性相关。而Ring AllReduce的通信成本与GPU数量无关。Ring AllReduce分为两个步骤:Scatter Reduce和All Gather。
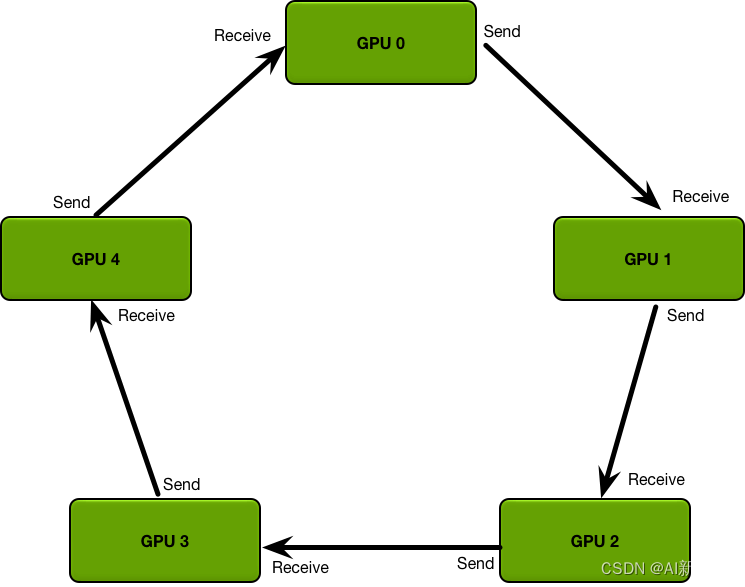
- Scatter Reduce过程:首先,我们将参数分为N份,相邻的GPU传递不同的参数,在传递N-1次之后,可以得到每一份参数的累积(在不同的GPU上)。
- 举个例子,假设现有 5 个 GPU,那么就将梯度分为 5 份,如下图,分别是 a i , b i , c i , d i , e i a_{i},b_{i},c_{i},d_{i},e_{i} ai?,bi?,ci?,di?,ei?, 这里的 i i i 指的是 GPU 编号。 从对角的位置开始传,每次传输时 GPU 之间只有一个块在传输,比如 a 0 a_0 a0?,在传播 4 次后 GPU 4 上就有了一个完整的梯度块。

- All Gather:得到每一份参数的累积之后,再做一次传递,同步到所有的GPU上。

- 根据这两个过程,我们可以计算到All Reduce的通信成本为: N N N 个GPU/通信一次完整的参数所需时间为 K K K。可以看到通信成本T与GPU数量 N N N 无关。 由于All Reduce算法在通信成本上的优势,现在几个框架基本上都实现了其对于的官方API
T = 2 ( N ? 1 ) K N T=2(N-1)\frac{K}{N} T=2(N?1)NK?

3.3. DP和DDP对比
- 1. 每个进程对应一个独立的训练过程,且只对梯度等少量数据进行信息交换。

- 2. 每个进程包含独立的解释器和 GIL


3.4. 分布式中的几个概念
- 在 PyTorch 中,分布式并行处理是指在多个进程之间分配任务以便并行执行的一种方法,特别是在多个计算节点上进行深度学习模型的训练。以下是一些关键概念的详细解释:
- Group(进程组):在分布式计算中,group指的是进程组。一个进程组包含了一系列可以进行集体通信操作的进程。在PyTorch中,默认情况下所有的进程都会被自动分配到一个全局默认的进程组中,我们称之为 “world”。在这个默认组中,所有的进程都可以互相通信。
- 有时,你可能需要更精细的控制,比如你只想在一部分进程之间进行通信。在这种情况下,你可以通过 torch.distributed.new_group 接口创建一个新的进程组,该组包含全局进程组的一个子集。
- World Size(全局进程个数):world size是全局进程组中进程的总数。在多机分布式训练中,world size等于所有机器上的进程总和。例如,如果你在每台机器上启动了4个进程,且一共使用了3台机器,那么 world size 就是12。
- Rank(进程序号):在分布式训练中,rank是分配给每个进程的唯一标识符,其范围是从0到world size - 1。每个进程在通信时都会使用它的rank作为标识。通常情况下,rank为0的进程被认为是主进程(master),它可能负责一些协调工作,比如汇总数据或打印日志。
- Local Rank(局部GPU编号):在单个节点(机器)上可能有多个进程,每个进程可能管理一个或多个GPU。local_rank是指一个进程所管理的GPU在该节点上的编号。例如,如果一个节点上有8个GPU,那么每个进程的local_rank的范围将是0到7。在PyTorch中,这通常是由torch.distributed.launch模块在启动进程时内部设置的。这对于确保每个进程使用不同的GPU至关重要,以避免资源冲突。

3.5. torch.nn.parallel.DistributedDataParallel(v1.4版本)
- 从一个简单的
torch.nn.parallel.DistributedDataParallel示例开始。此示例使用torch.nn.Linear作为本地模型,用 DDP 对其进行包装,然后在 DDP 模型上运行一次前向传递、一次后向传递和优化器步骤。之后,本地模型上的参数将被更新,并且不同进程上的所有模型应该完全相同。
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
print(rank, world_size)
# world_size=4,print结果如下:
# 0 4
# 3 4
# 2 4
# 1 4
# create default process group
# PyTorch中初始化分布式训练环境的一个关键步骤,为进程间的通信建立了一个所谓的"进程组"
# "gloo": 这是指定的后端类型。Gloo是一个跨平台的通信后端,适用于CPU和GPU,它支持各种集体通信操作。PyTorch还支持其他后端,如"nccl"(适用于NVIDIA GPUs)和 "mpi"。
# rank: 这是当前进程在进程组中的唯一标识符。在分布式训练中,每个进程都有一个唯一的rank,通常从0开始到world_size-1。rank用于标识每个进程,使得进程间可以知道彼此的身份。
# world_size: 这是进程组中的进程总数。在分布式训练中,这通常等于用于训练的总GPU或节点的数量。
# 执行此函数时,并不是每个进程都创建自己独立的进程组,而是所有进程共同在一个全局的进程组中注册,从而能够相互通信。
# 一旦进程组被初始化,进程间就可以使用PyTorch提供的集体通信操作(如dist.broadcast, dist.all_reduce等)进行通信和数据同步。
# 这些通信操作允许进程共享数据(例如模型参数或梯度),这对于保证分布式训练中所有节点的模型同步至关重要。
dist.init_process_group("gloo", rank=rank, world_size=world_size) # nccl
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(200, 10).to(rank))
labels = torch.randn(200, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
# world_size 指的是总的并行进程数目,比如16张卡单卡单进程就是16,但是如果是8卡单进程就是1
world_size = 4
# torch.multiprocessing启动多个进程
# example: 这是一个函数,它会在每个新创建的进程中运行。在分布式训练的上下文中,这个函数通常会包含模型的初始化、训练循环等。
# args=(world_size,): 这个参数提供了一个元组,其中包含了传递给example函数的参数
# nprocs=world_size: 这个参数指定了要启动的进程数。
# join=True: 这个参数控制mp.spawn是否应该等待所有进程完成。如果设置为True,mp.spawn调用将会阻塞,直到所有进程都运行完毕。这意味着主程序会等待所有由mp.spawn启动的进程结束后才继续执行。
# mp.spawn会自动为每个新创建的进程生成一个rank,其值从0到nprocs-1。然后,mp.spawn会将这个rank和args中的参数一起传递给example函数。
mp.spawn(example, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
# Environment variables which need to be set when using c10d's default "env" initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
main()
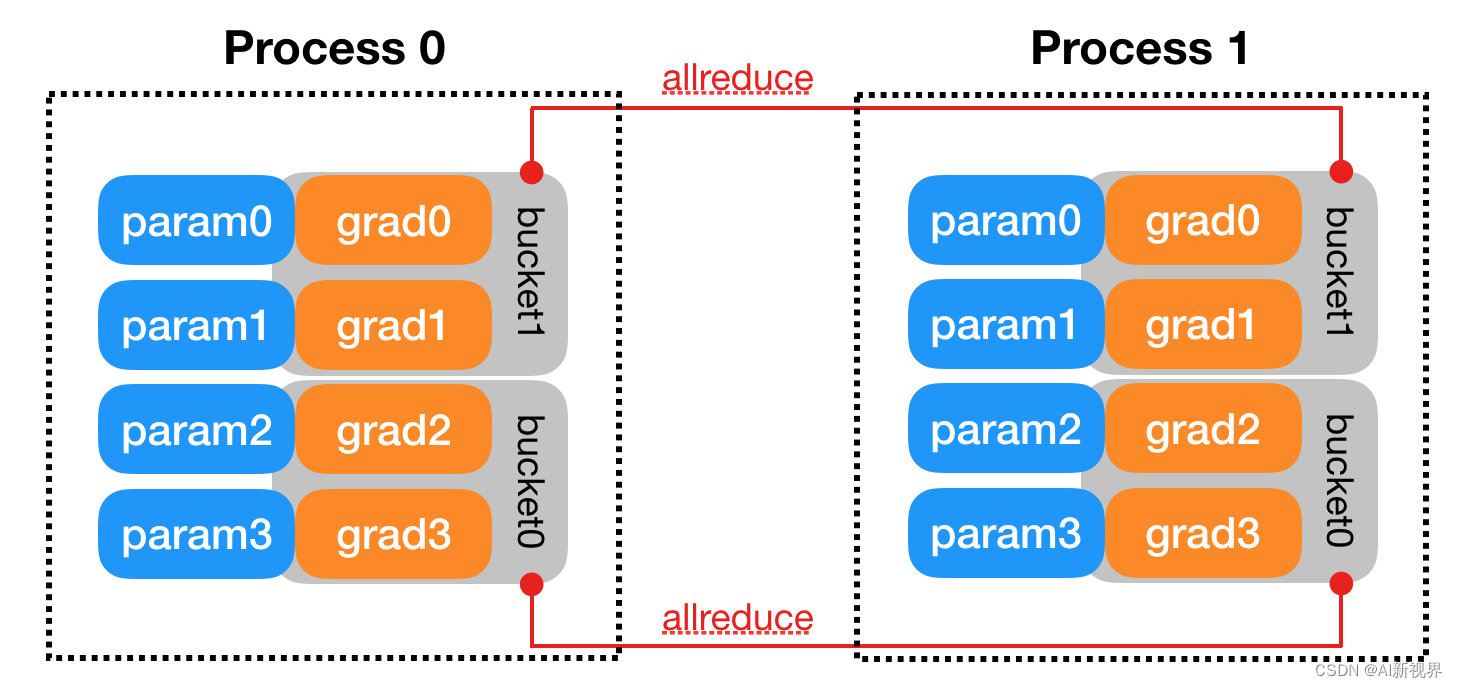
- DDP 通过Reducer来管理梯度同步。为了提高通讯效率,Reducer会 将梯度归到不同的桶里(按照模型参数的 reverse order, 因为反向传播需要符合这样的顺序),一次归约一个桶。其中桶的大小为参数 bucket_cap_mb 默认为 25,该参数指定了每个存储桶的最大容量(以兆字节为单位),可根据需要调整。下图即为一个例子。
grad0和grad1位于bucket1中,另外两个grad2和grad3位于bucket0中。可以看到每个进程里,模型参数都按照倒序放在桶里,每次归约一个桶。
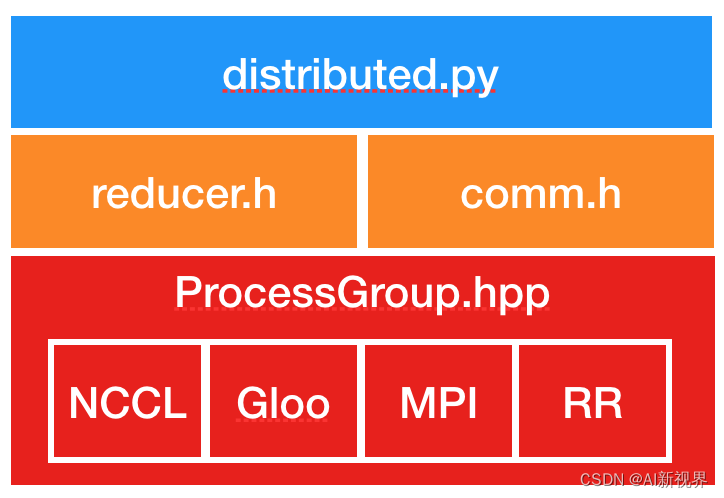
- DDP的实现主要基于下图所示结构
- Distributed.py:是
DDP的Python入口点。它实现了调用C++库的nn.parallel.DistributedDataParallel模块的初始化步骤和forward函数。当一个DDP进程在多个设备上工作时,其_sync_param函数执行进程内参数同步,并且还将Rank 0进程的模型缓冲区广播到所有其他进程。进程间参数同步发生在Reducer.cpp中。- comm.h:实现合并广播辅助函数,该函数被调用以在初始化期间广播模型状态并在前向传递之前同步模型缓冲区。
- reducer.h:提供反向传递中梯度同步的核心实现。它具有三个入口点函数:
Reducer:在distributed.py中调用构造函数,将Reducer::autograd_hook()注册到梯度累加器。
autograd_hook():当梯度准备就绪时,autograd引擎将调用autograd_hook()函数。
prepare_for_backward():在distributed.py中的DDP前向传递结束时调用。当DDP构造函数中find_unused_parameters设置为True时,它会遍历autograd图来查找未使用的参数。
四. 模型并行(ModelParallel)
- 模型并行性对我来说听起来很可怕,但它实际上与数学无关。这是分配计算机资源的本能。有时我们无法将所有数据放入(GPU)内存中,因为我们的深度学习模型中有太多层和参数。因此,我们可以将深度学习模型分成几个部分,将几个连续的层放在一个节点上并计算其梯度。这样,单个节点的参数数量就减少了,并且可以利用数据进行训练,得到更准确的梯度。
- 例如,我们有 10 个 GPU,我们想要训练一个简单的 ResNet50 模型。我们可以将前 5 层分配给 GPU #1,后 5 层分配给 GPU #2,依此类推,最后 5 层分配给 GPU #10。在训练期间,在每次迭代中,前向传播必须首先在 GPU #1 中完成。 GPU #2 正在等待 GPU #1 的输出,GPU #3 正在等待 GPU #2 的输出,依此类推。一旦前向传播完成。我们计算驻留在 GPU #10 中的最后一层的梯度,并更新 GPU #10 中这些层的模型参数。然后梯度反向传播到 GPU #9 中的前一层,等等。每个 GPU/节点就像工厂生产线中的一个隔间,它等待来自前一个隔间的产品,并将自己的产品发送到下一个隔间。
- 在我看来,模型并行性的名称具有误导性,不应将其视为并行计算的示例。更好的名称可能是 “模型序列化”,因为它在并行计算中使用串行方法而不是并行方法。然而,在某些场景下,某些神经网络中的某些层(例如 Siamese Network)实际上是“并行的”。这样,模型并行性可以在某种程度上表现得像真正的并行计算。然而,数据并行是100%并行计算。
五. 参考文献
- pytorch(分布式)数据并行个人实践总结——DataParallel/DistributedDataParallel
- Data Parallelism VS Model Parallelism in Distributed Deep Learning Training
- https://d2l.ai/chapter_computational-performance/parameterserver.html
- 💥 Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
- [原创][深度][PyTorch] DDP系列第一篇:入门教程
- [原创][深度][PyTorch] DDP系列第二篇:实现原理与源代码解析
- PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析
- 【DDP详解: 1】起底DP和DDP,数据分布式训练炼丹秘籍!
- 同时推荐一个官方设计笔记,讲得很详细,有兴趣可以看看。https://pytorch.org/docs/stable/notes/ddp.html
- 将高性能计算 (HPC)技术引入深度学习
- 【分布式训练】单机多卡的正确打开方式(一):理论基础
文章来源:https://blog.csdn.net/abc13526222160/article/details/134683412
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!