【Java基础篇 | 面向对象】—— 聊聊什么是接口(下篇)
个人主页:兜里有颗棉花糖
欢迎 点赞👍 收藏? 留言? 加关注💓本文由 兜里有颗棉花糖 原创
收录于专栏【JavaSE_primary】
本专栏旨在分享学习JavaSE的一点学习心得,欢迎大家在评论区交流讨论💌

上篇(【Java基础篇 | 面向对象】—— 聊聊什么是接口(上篇))中我们已经对Java接口中有了一定的了解。本篇中我们将对Java接口进行更进一步的学习。加油吧!!!
一、接口使用实例
首先我们要使用记住一句话,对象与对象之间进行比较的话一定要实现对应的接口。只有我们实现了对应的接口之后才能证明这两个对象是可比较的。
现在有一个整数数组,我们当然可以使用sort()方法来对这个整数数组进行升序或者降序排序。但是如果我们现在有一个学生类对象呢?我们是无法直接拿两个学生类对象进行直接排序的。此时我们应该参照学生类中的某个属性来对这个学生类对象进行排序以达到我们想要的排序效果。
现在我们就以学生类中的年龄属性来进行排序吧:
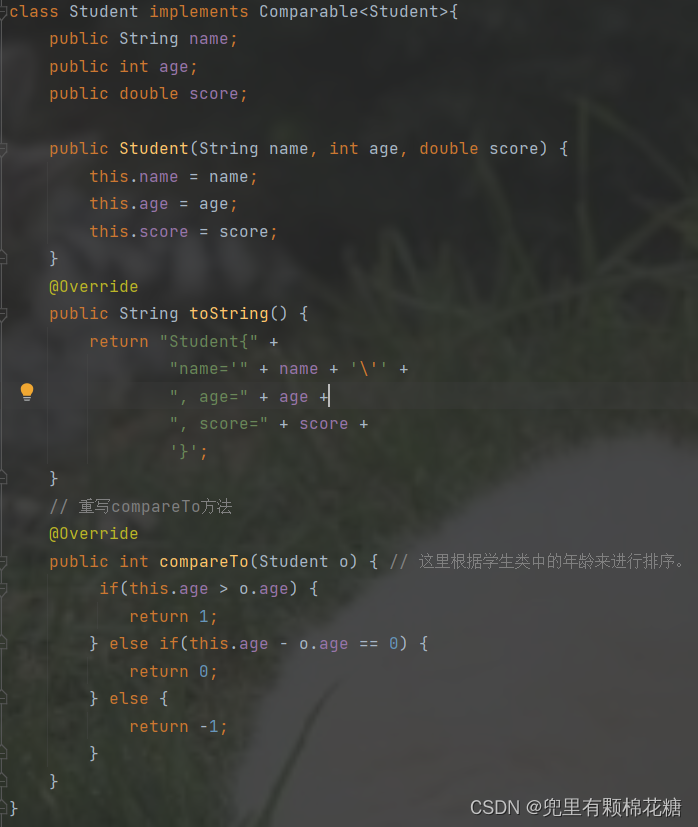
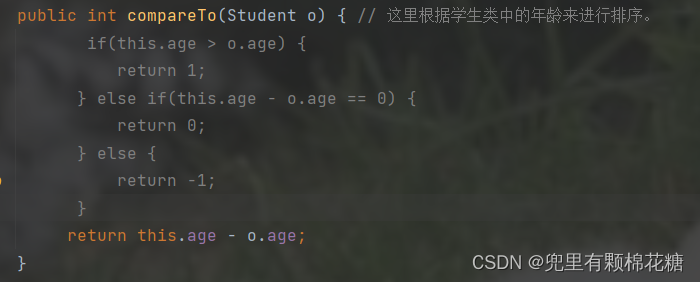
我们在进行自定义类型的对象比较的时候,一定要实现可以比较的接口。比如如果我们的Student类实现Comparable接口, 并实现其中的compareTo方法。否则的话自定义类型的对象是无法进行比较的。
如下图就是我们实现的
Comparable接口中的compareTo方法。
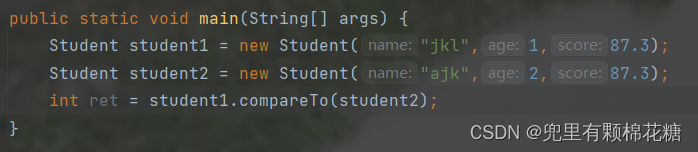
如果我们要比较两个对象的引用的话(两个学生类对象按照年龄来进行排序),我们可以这样来写,请看:
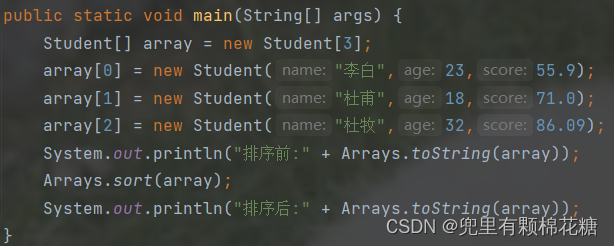
如果我们要比较的是一个学生类对象数组的话(按照年龄来进行比较),我们可以这样,请看:
运行结果如下:

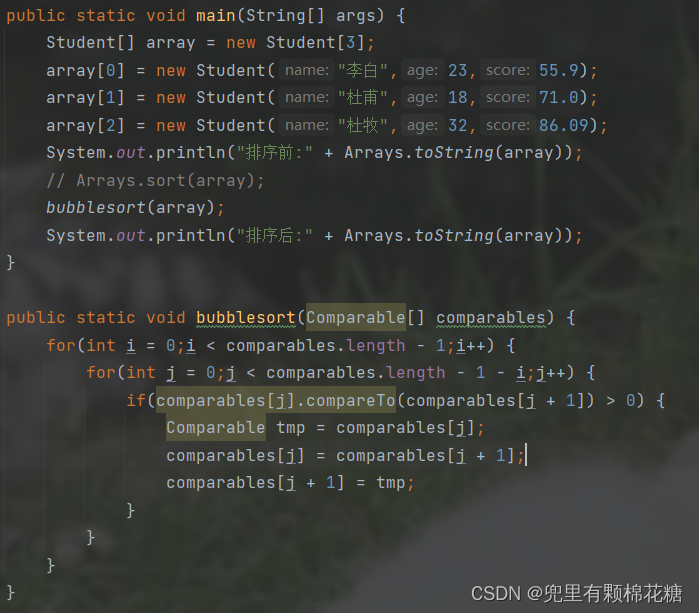
现在我们来试着使用自己写一个排序方法(冒泡排序)来对学生类对象进行排序。
请看下面我们自己实现的冒泡排序来对学生类对象按照年龄进行排序。代码如下:
运行结果如下:
现在我们来对上述冒泡排序中的代码进行解释:
排序的时候我们排序的是一个学生数组(按照年龄来进行排序),所以我们在进行排序的时候底层一定会去调用compareTo方法,所以冒泡排序中的参数一定为Comparable[] comparables,即接口数组。另外array数组(即学生类对象数组)中的每个元素都是一个学生类对象,而且每个学生类对象都实现了compareTo方法。

比较器(Comparator)
好了,现在我们换一种排序的写法。上述学生类中有年龄也有分数,如果我们一会想依据年龄进行排序,一会又想用分数进行排序的话,如果按照
compareTo()方法完成上述排序的话,那么根据我们比较依据的不同那么compareTo()方法中的内容也是不一样的(即我们需要修改compareTo方法中的内容)。
请看上图,上图中的compareTo()只能对学生类对象中的年龄进行排序而无法对学生类中的成绩进行排序,所以排序的内容就比较单一。此时我们就需要Comparator接口。
好了,现在我们利用
Comparator接口来实现学生类对象的排序工作,代码如下图,请看:
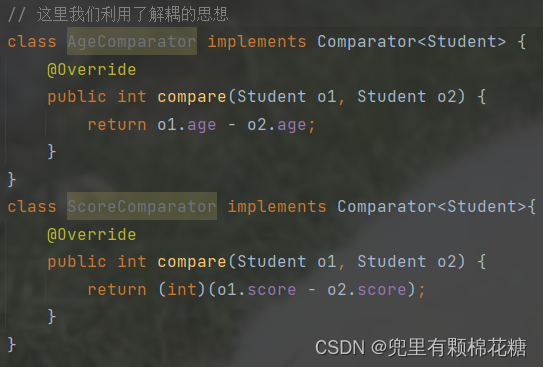
具体代码如下,请看:
import com.sun.javaws.IconUtil;
import java.util.Comparator;
class Student{
public String name;
public int age;
public double score;
public Student(String name, int age, double score) {
this.name = name;
this.age = age;
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", score=" + score +
'}';
}
}
// 这里我们利用了解耦的思想
class AgeComparator implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
return o1.age - o2.age;
}
}
class ScoreComparator implements Comparator<Student>{
@Override
public int compare(Student o1,Student o2) {
return (int)(o1.score - o2.score);
}
}
public class Test {
public static void main(String[] args) {
Student student1 = new Student("jkl",1,87.3);
Student student2 = new Student("ajk",2,87.3);
// 依据年龄进行比较
AgeComparator ageComparator = new AgeComparator();
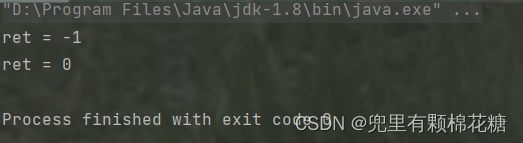
int ret = ageComparator.compare(student1,student2);
System.out.println("ret = " + ret);
// 依据成绩进行比较
ScoreComparator scoreComparator = new ScoreComparator();
int ret2 = scoreComparator.compare(student1,student2);
System.out.println("ret = " + ret2);
}
}
运行结果如下:
对比一下这两种接口(Comparator接口和Comparable接口):经过上述的演示,我们不难发现Comparator接口更加的灵活。
二、Clonable接口和深拷贝
浅拷贝
浅拷贝概念:浅拷贝是指在对一个对象进行拷贝时,只拷贝对象本身和其中的基本数据类型,而不拷贝对象内部的引用类型。因此,在浅拷贝的对象中,引用类型的变量指向的依旧是原始对象中的引用。
下面来进行举例。
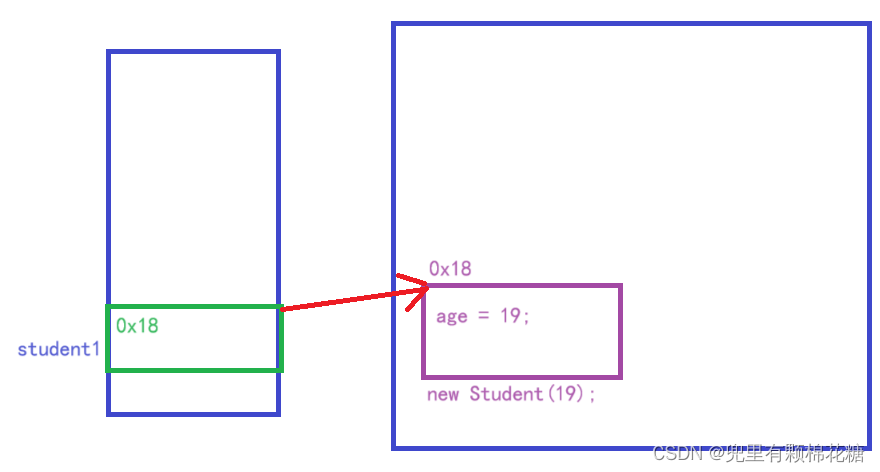
现在我们有一个
Student学生类,如下图:
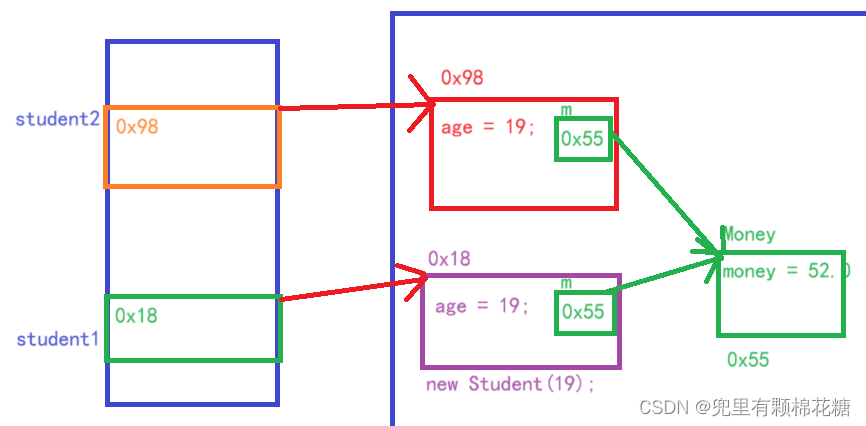
同时新创建了一个学生类对象student1,该对象对应的内存结构图如下:
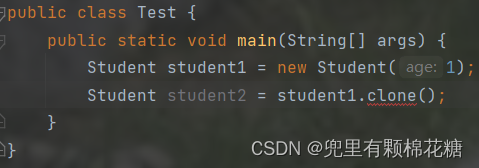
现在我们想要把student引用所指向的对象克隆出来一份,如下图的克隆方式是错误的:
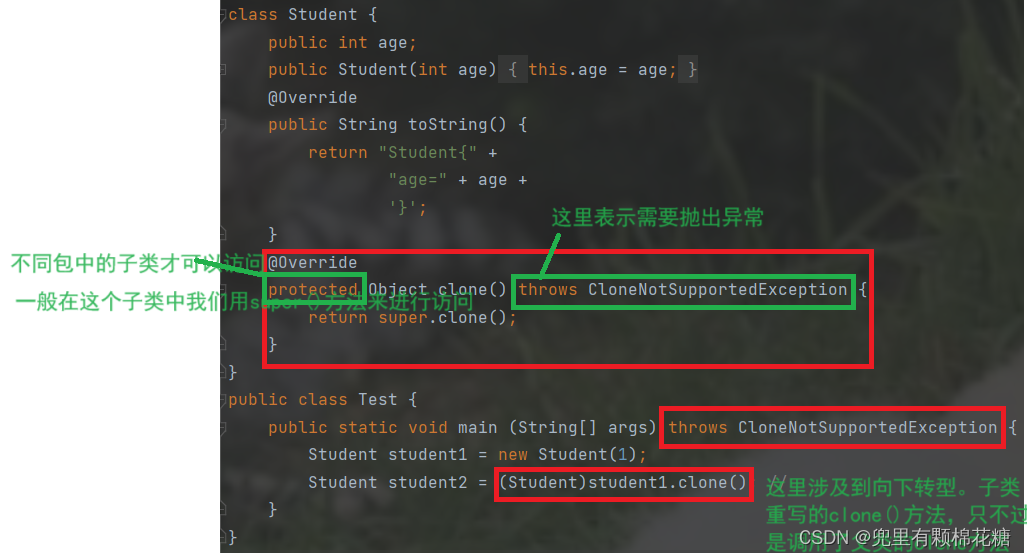
要解决上述错误的话,我们需要修改三个地方。如下图:
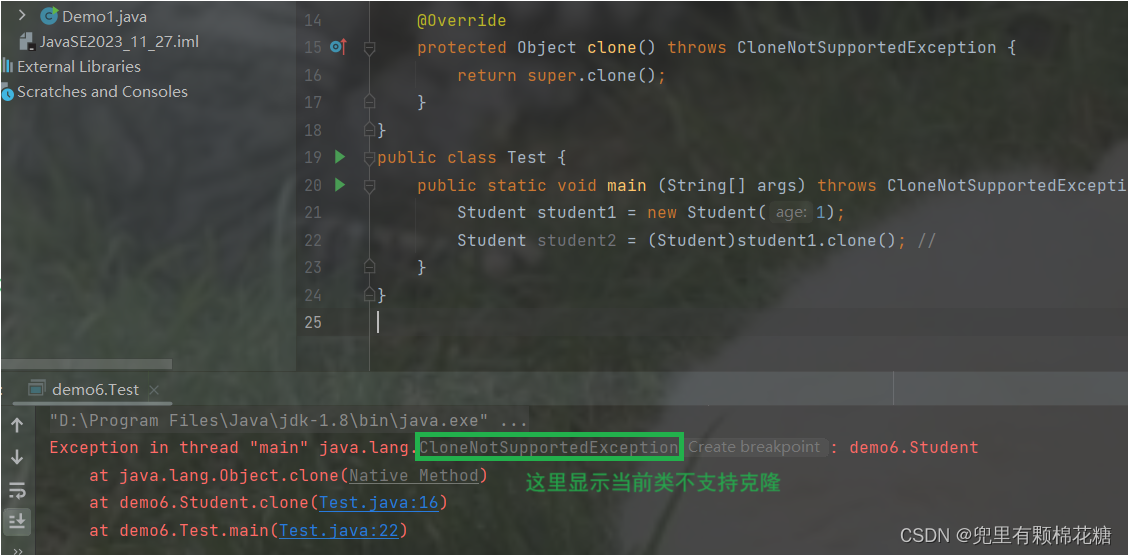
好了,现在重新运行一下程序,发现还是会报错,请看:
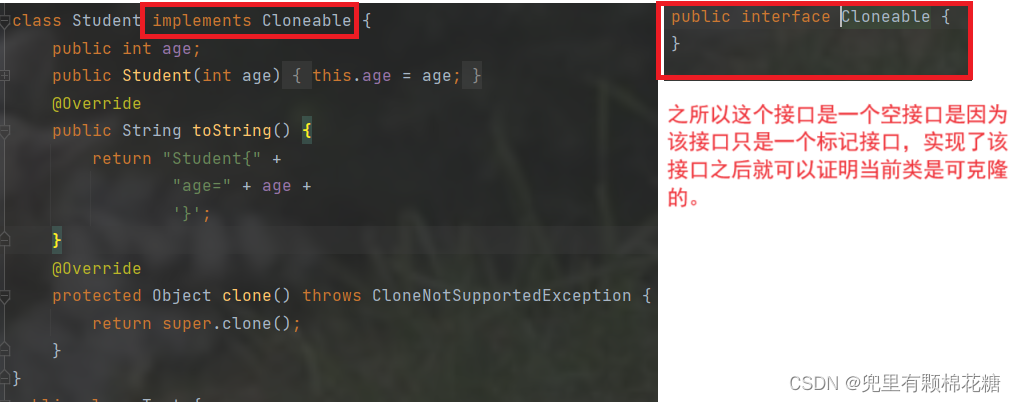
我们需要实现一个接口以证明当前的类是可以进行克隆的。
运行结果如下:

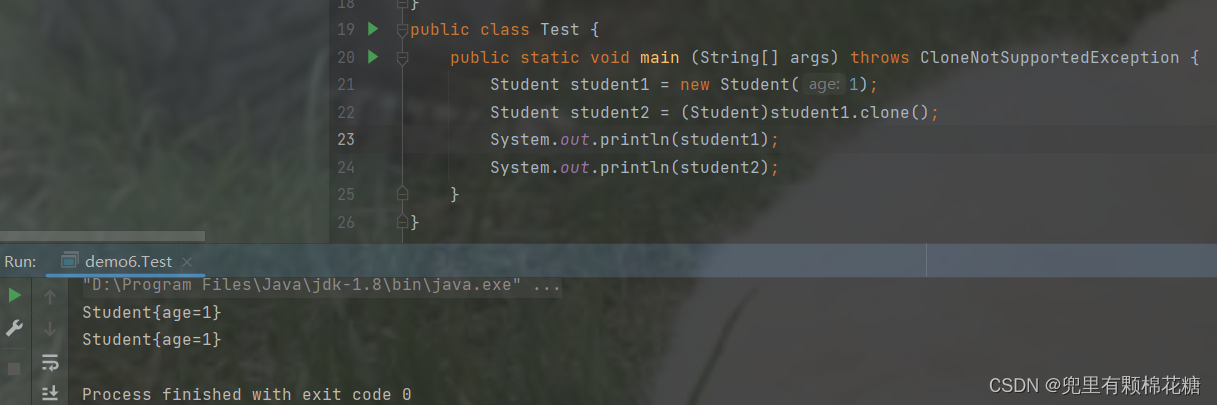
浅拷贝的对象中,引用类型的变量指向的依旧是原始对象中的引用。请看举例:
运行结果如下:
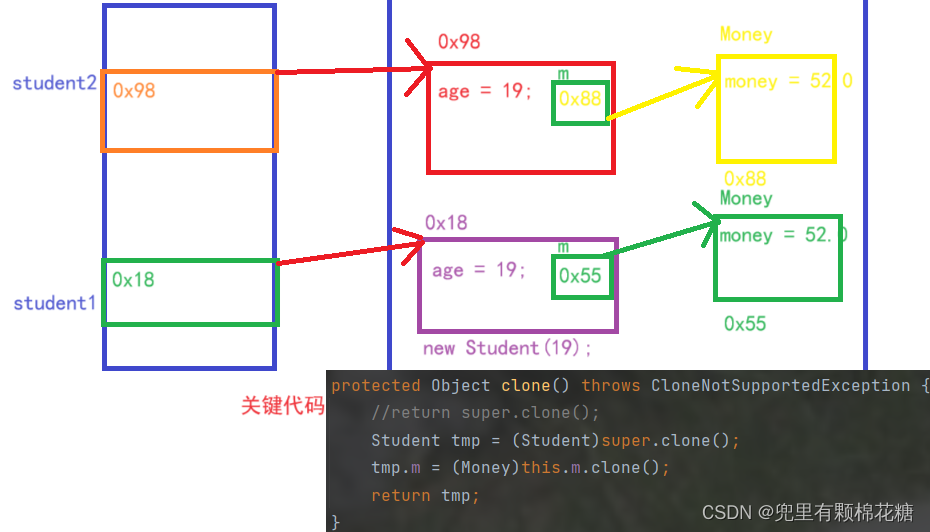
解释:通过调用clone()方法,创建了student1的一个克隆对象student2。克隆的实现是通过调用Object类的clone()方法来完成的。
输出结果显示了两次student1.m.money和student2.m.money的值,分别为52.0。这是因为浅拷贝只是简单地复制字段的值,而对于引用类型的字段,只复制了引用地址,并没有复制该引用指向的实际对象。因此,student1和student2的m字段引用同一个Money对象。
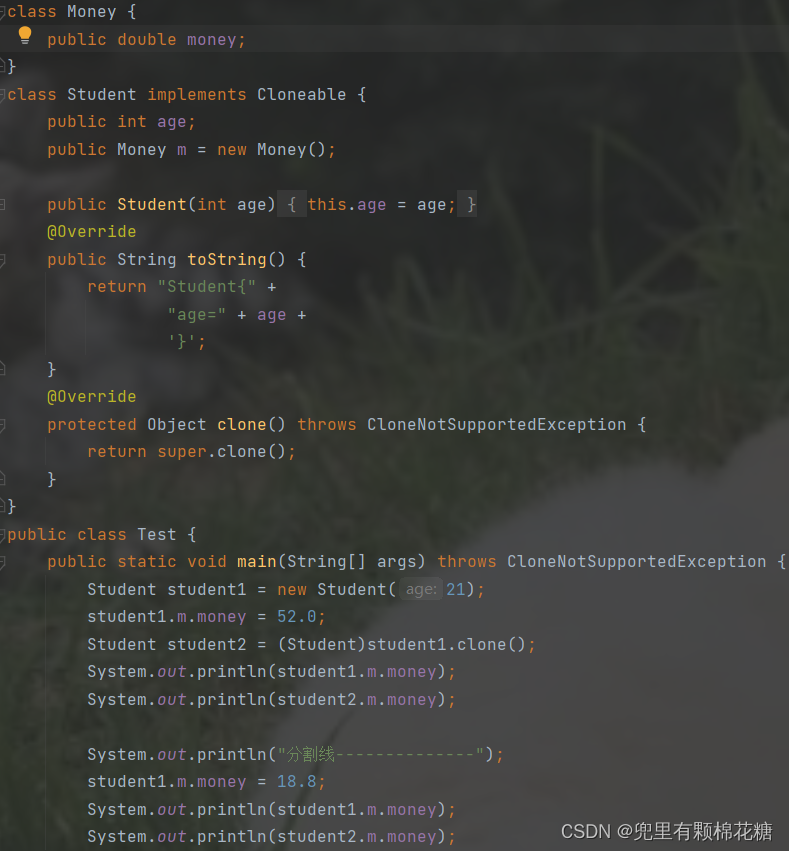
深拷贝
深拷贝是指在对一个对象进行拷贝时,不仅拷贝对象本身和其中的基本数据类型,同时也拷贝对象内部的引用类型。因此,在深拷贝的对象中,引用类型的变量指向的是全新的对象。
好了,现在来总结一下:clone方法是Object类中的一个方法,调用这个方法可以创建一个对象的 “拷贝”. 但是要想合法调用 clone 方法,必须要先实现Clonable接口, 否则就会抛出CloneNotSupportedException异常.
下面是深拷贝的代码举例:
class Money implements Cloneable {
public double money;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
class Student implements Cloneable {
public int age;
public Money m = new Money();
public Student(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
//return super.clone();
Student tmp = (Student)super.clone();
tmp.m = (Money)this.m.clone();
return tmp;
}
}
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
Student student1 = new Student(21);
student1.m.money = 52.0;
Student student2 = (Student)student1.clone();
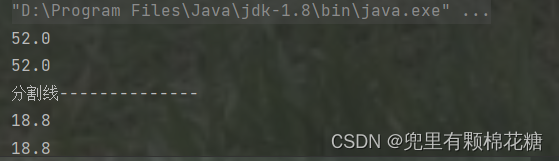
System.out.println(student1.m.money);
System.out.println(student2.m.money);
System.out.println("分割线--------------");
student1.m.money = 18.8;
System.out.println(student1.m.money);
System.out.println(student2.m.money);
}
}
运行结果如下:
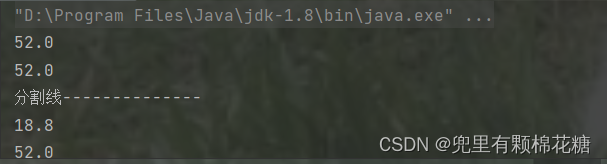
好了,现在我们再来回顾一下什么是深拷贝:深拷贝就是在拷贝对象的同时创建一个新的对象,并将原对象中的所有数据逐个拷贝到新对象中去,包括成员变量引用的其他对象。这样可以确保原对象和拷贝对象之间的数据相互独立,互不影响。
三、Object类
在Java中,所有的类都直接或间接地继承自java.lang.Object类。Object类是Java类层次结构中的根类,它提供了一些通用的方法和功能,可以在所有类中使用。可以这么认为,Object类是所有类的父类。所以在Java中,即使我们不显式地在类声明中使用extends关键字继承Object类,所有的类仍然会隐式地继承Object类。这是因为Object类是Java类层次结构中的根类,所有的类都直接或间接继承自它。
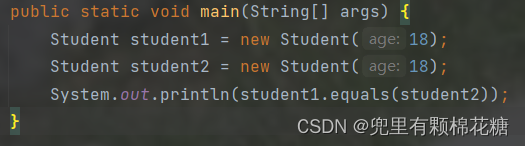
对象比较equals()方法
如上图:使用equals()方法来比较两个对象是否相等。
如果在Student类中没有重写equals()方法,则默认会使用Object类中的equals()方法,它执行的是比较对象引用的相等性(即比较两个对象在内存中的地址是否相同)。
因此,上图中的代码的最终结果就是False。但是,如果我想要按照我们自己的方式来比较这两个对象是否相等的话我们就需要自己去重写equals()方法。
现在,如果以两个对象的年龄是否相等为依据来判断两个对象是否相等的话,重写的equals()方法如下:
如果我们相比较对象中的内容是否相等的话,我们需要根据自己的判断依据来重写Object类中的equals()方法。

hashcode()方法
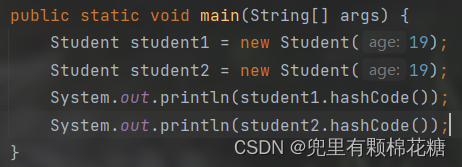
hashcode()方法用于返回对象的hash码,相当于对象的标识符,它可以将对象转换为整数以便更好的比较、存储对象。
好了,现在来举个栗子,假设当两个对象的年龄是一样的话,那么我们认为这两个对象存储的位置是相同的,请看代码:
运行结果如下:
如上图中的运行结果,虽然两个对象的年龄是不同的,但是这两个对象存储的位置确实相同的,这与我们判断两个对象是否相同的判断依据发生了冲突。
此时我们就需要自己重写hashcode()方法。

最终代码如下,请看:
import java.util.Objects;
class Money implements Cloneable {
public double money;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Money money1 = (Money) o;
return Double.compare(money1.money, money) == 0;
}
@Override
public int hashCode() {
return Objects.hash(money);
}
}
class Student implements Cloneable {
public int age;
public Money m = new Money();
public Student(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
//return super.clone();
Student tmp = (Student)super.clone();
tmp.m = (Money)this.m.clone();
return tmp;
}
@Override
public boolean equals(Object obj) {
Student student = (Student)obj;
return age == student.age;
}
@Override
public int hashCode() {
return Objects.hash(age, m);
}
}
public class Test {
public static void main(String[] args) {
Student student1 = new Student(19);
Student student2 = new Student(19);
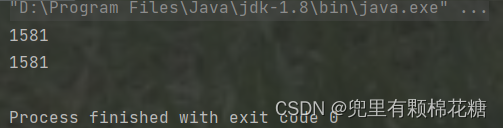
System.out.println(student1.hashCode());
System.out.println(student2.hashCode());
}
}
运行结果如下:
此时就说明这两个对象的位置是相同的。
小总结:
- hashcode()方法用来确定对象在内存中存储的位置是否相同。
- 实际上,hashcode()在散列表中才会用到(在散列表中
hashcode()的作用就是获取对象的散列码,进而确定该对象在散列表中的位置);然而hashcode()在其它情况下没多大用。 - 如果一个类没有重写
hashCode()和equals()方法,那么它将使用从Object类继承而来的默认实现。如果默认实现的hashCode()和equals()方法不符合我们的需求,此时我们就需要自己重写hashCode()和equals()方法。 - 定义一个自定义类型时,应该养成重写
hashCode()和equals()方法的习惯。
好了,本文到这里就结束了,再见啦友友们!!!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!